

Приймак А.В. Технология CUDA
1 Обзор CUDA ..........................................................................................................
1.1 GPGPU .................................................................................................................
1.2 Введение в CUDA ...............................................................................................
1.3 Терминология CUDA .........................................................................................
1.4 Модель программирования CUDA ...................................................................
1.5 Версии вычислительных возможностей CUDA и программного обеспечения CUDA Toolkit .....................................................................................
1.6 CUDA Toolkit версии 5 и версия вычислительных возможностей 3 .............
1.7 Полезные ссылки ................................................................................................
2 Технология JCUDA ...............................................................................................
2.1 Введение в JCUDA .............................................................................................
2.2 Требования к техническому и программному обеспечению для JCUDA-программ ...................................................................................................................
2.3 Настройка JCUDA для среды разработки Eclipse ...........................................
2.4 Решение возможных проблем при работе с CUDA и JCUDA .......................
2.5 Определение параметров CUDA-устройства и системных параметров в Java-программе .........................................................................................................
2.6 Подключение CUDA модулей и выполнение их на CUDA-устройстве из Java-программы ........................................................................................................
2.7 Создание ‘.cu‘ файла ..........................................................................................
2.8 Сборка программы .............................................................................................
3 Изучение особенностей JCUDA на примере ......................................................
3.1 Пример JCUDA-программы ..............................................................................
3.2 Скорость выполнения программы ....................................................................
3.3 Размер блока ........................................................................................................
3.4 Отклонения в результатах вычислений и двойная точность ..........................
Перечень ссылок .......................................................................................................
1 Обзор cuda
1.1 GPGPU
В отличии от центральных процессоров (central processing unit, CPU), графические процессоры (graphics processing unit, GPU) имеют производительность параллельной архитектуры - большое количество ядер небольшой частоты, что означает выполнение многих параллельных потоков медленно, а не выполнение одного потока быстро (рисунок 1.1) [1]. Такой подход вычислений общего назначения на GPU известен как general-purpose computing on graphics processing units (GPGPU) [2].
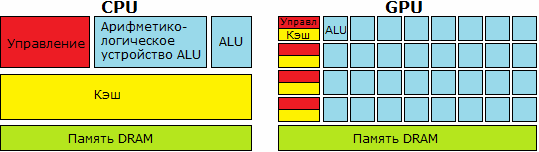
Рисунок 1.1 – Архитектура CPU и GPU
Основные GPGPU технологии: CUDA, AMD FireStream, DirectCompute, OpenCL.
1.2 Введение в cuda
Compute unified device architecture (CUDA) - архитектура параллельных вычислений, разработанная компанией NVIDIA. CUDA обеспечивает возможность вычислений общего назначения на GPU от NVIDIA, которые обычно производит CPU [3].
CUDA появилась в 2007 году с выходом чипа NVIDIA восьмого поколения G80 и присутствует в последующих сериях графических чипов, которые используются в семействах ускорителей GeForce, Quadro и Tesla [4]. Благодаря ожидаемым в будущем операционным системам (ОС), GPU предстанет универсальным процессором для параллельных вычислений, работающим с любым приложением [5].
Наиболее важные параметры устройств CUDA: вычислительная мощность - число операций с плавающей точкой в секунду (FLOPS), число ядер, размер памяти, версия вычислительных возможностей CUDA.
Программисты используют язык программирования "С для CUDA" (язык C с расширениями и некоторыми ограничениями) для написания алгоритмов, выполняемых на GPU. Также CUDA предоставляет вычислительные интерфейсы для Python, Perl, Fortran, Java, Ruby, Lua, Mathematica, MATLAB и других языков программирования и прикладных программ.
Основными достоинствами CUDA являются высокая скорость вычислений (на GPU по сравнению с CPU в десятки раз), наличие интерфейсов для разных языков программирования, бесплатность, постоянное развитие, распространенность по сравнению с другими GPGPU.
Недостатки CUDA:
- дополнительная сложность написания программ для GPU по сравнению с CPU;
- не поддерживаются некоторые алгоритмы, которые не поддаются распараллеливанию;
- архитектуру CUDA поддерживает только производитель NVIDIA;
- часть GPU не поддерживает вычисления в двойной точности (double), в то время как вычисления в одинарной точности (float) не всегда обеспечивают необходимую точность вычислений;
- скорость вычислений в двойной точности меньше, чем в одинарной точности, в отличии от CPU, которые оптимизированы под вычисления в двойной точности (на CPU скорость вычислений в двойной точности и в одинарной совпадают). На CUDA для одних и тех же функций существует по несколько реализаций двойной и одинарной точности, которые дают различную точность и скорость вычислений;
- высокая стоимость т.н. «профессиональных GPU» - семейств GPU Quadro и Tesla, оптимизированных для вычислений общего назначения и имеющих высокую скорость вычислений в двойной точности.
1.3 Терминология cuda
NVIDIA оперирует определениями для CUDA API, которые отличаются от определений, применяемых для работы с CPU [6].
Поток (thread) - набор данных, который необходимо обработать (не требует больших ресурсов при обработке).
Варп (warp) - группа из 32 потоков. Данные обрабатываются только варпами, следовательно варп - это минимальный объем данных.
Блок (block) - совокупность потоков.
Сетка (grid) - совокупность блоков. Такое разделение данных применяется для повышения производительности. Если число мультипроцессоров в GPU велико, то блоки будут выполняться параллельно, если мало - блоки данных обработаются последовательно.
Ядро (kernel) - программа, выполняемая одной сеткой блоков. Одновременно выполняется только одна сетка.
Хост (host) - CPU.
Девайс (device) - GPU.