

Лабораторная работа 3.
Тема: Построение диаграммы декомпозиции в нотации DFD для автоматизированной банковской системы «Клиент-банк»
Цель работы: закрепить знания и навыки построения диаграмм декомпозиции в нотации DFD автоматизированной банковской системы «Клиент-банк».
Краткие теоретические сведения:
Диаграммы потоков данных (DFD- Data Flow Diagram) являются основным средством моделирования функциональных требований к проектируемой системе. С их помощью эти требования представляются в виде иерархии функциональных компонентов (процессов), связанных потоками данных. Главная цель такого представления - продемонстрировать, как каждый процесс преобразует свои входные данные в выходные, а также выявить отношения между этими процессами.
Для построения DFD традиционно используются две различные нотации, соответствующие методам Йордана и Гейна–Сэрсона. Эти нотации незначительно отличаются друг от друга графическим изображением символов. Далее при построении примеров будет использоваться нотация Гейна — Сэрсона.
В соответствии с данными методами модель системы определяется как иерархия диаграмм потоков данных, описывающих асинхронный процесс преобразования информации от ее ввода в систему до выдачи пользователю. Диаграммы верхних уровней иерархии (контекстные диаграммы) определяют основные процессы или подсистемы с внешними входами и выходами. Они детализируются при помощи диаграмм нижнего уровня. Такая декомпозиция продолжается, создавая многоуровневую иерархию диаграмм, до тех пор, пока не будет достигнут уровень декомпозиции, на котором процессы становятся элементарными и детализировать их далее невозможно.
Основным различием между реляционной и концептуальной моделями, является представление связи. В концептуальной модели связь может соединять любое количество сущностей, а в реляционной модели связь является либо унарной, либо бинарной (она не может связывать больше двух различных таблиц).
Основными компонентами диаграмм потоков данных являются:
• внешние сущности;
• системы и подсистемы;
• процессы;
• накопители данных;
• потоки данных.
Внешняя сущность представляет собой материальный объект или физическое лицо, представляющие собой источник или приемник информации, например заказчики, персонал, поставщики, клиенты, склад. Определение некоторого объекта или системы в качестве внешней сущности указывает на то, что они находятся за пределами границ анализируемой системы. В процессе анализа некоторые внешние сущности могут быть перенесены внутрь диаграммы анализируемой системы, если это необходимо, или, наоборот, часть процессов может быть вынесена за пределы диаграммы и представлена как внешняя сущность.
Внешняя сущность обозначается квадратом, расположенным как бы над диаграммой и бросающим на нее тень для того, чтобы можно было выделить этот символ среди других обозначений.
Номер процесса служит для его идентификации. В поле имени вводится наименование процесса в виде предложения с активным недвусмысленным глаголом в неопределенной форме (вычислить, рассчитать, проверить, определить, создать, получить), за которым следуют существительные в винительном падеже, например: "Ввести сведения о налогоплательщиках", "Выдать информацию о текущих расходах", "Проверить поступление денег".
Использование таких глаголов, как "обработать", "модернизировать" или "отредактировать", означает недостаточно глубокое понимание данного процесса и требует дальнейшего анализа.
Информация в поле физической реализации показывает, какое подразделение организации, программа или аппаратное устройство выполняет данный процесс.
Накопитель данных - это абстрактное устройство для хранения информации, которую можно в любой момент поместить в накопитель и через некоторое время извлечь, причем способы помещения и извлечения могут быть любыми.
Накопитель данных может быть реализован физически в виде микрофиши, ящика в картотеке, таблицы в оперативной памяти, файла на магнитном носителе и т. д. Накопитель данных на диаграмме потоков данных идентифицируется буквой "D" и произвольным числом. Имя накопителя выбирается из соображения наибольшей информативности для проектировщика.
Накопитель данных в общем случае является прообразом будущей базы данных, и описание хранящихся в нем данных должно быть увязано с информационной моделью (ERD).
Поток данных определяет информацию, передаваемую через некоторое соединение от источника к приемнику. Реальный поток данных может быть информацией, передаваемой по кабелю между двумя устройствами, пересылаемыми по почте письмами, магнитными лентами или дискетами, переносимыми с одного компьютера на другой, и т. д.
Первым шагом при построении иерархии DFD является построение контекстных диаграмм. Обычно при проектировании относительно простых систем строится единственная контекстная диаграмма со звездообразной топологией, в центре которой находится так называемый главный процесс, соединенный с приемниками и источниками информации, посредством которых с системой взаимодействуют пользователи и другие внешние системы. Перед построением контекстной DFD необходимо проанализировать внешние события (внешние сущности), оказывающие влияние на функционирование системы. Количество потоков на контекстной диаграмме должно быть по возможности небольшим, поскольку каждый из них может быть в дальнейшем разбит на несколько потоков, на следующих уровнях диаграммы.
Для проверки контекстной диаграммы можно составить список событий. Список событий должен состоять из описаний действий внешних сущностей (событий) и соответствующих реакций системы на события. Каждое событие должно соответствовать одному (или более) потоку данных: входные потоки интерпретируются как воздействия, а выходные потоки - как реакции системы на входные потоки.
Если для сложной системы ограничиться единственной контекстной диаграммой, то она будет содержать слишком большое количество источников и приемников информации, которые трудно расположить на листе бумаги нормального формата, и, кроме того, единственный главный процесс, не раскрывает структуры такой системы. Признаками сложности (в смысле контекста) могут быть: наличие большого количества внешних сущностей (десять и более), распределенная природа системы, многофункциональность системы с уже сложившейся или выявленной группировкой функций в отдельные подсистемы.
Для сложных систем строится иерархия контекстных диаграмм. При этом контекстная диаграмма верхнего уровня содержит не единственный (главный) процесс, а набор подсистем, соединенных потоками данных. Контекстные диаграммы следующего уровня детализируют контекст и структуру подсистем.
Иерархия контекстных диаграмм определяет взаимодействие основных функциональных подсистем, как между собой, так и с внешними входными и выходными потоками данных и внешними объектами (источниками и приемниками информации), с которыми взаимодействует система, характеризуемая следующими признаками:
• наличием у процесса относительно небольшого количества входных и выходных потоков данных (2-3 потока);
• возможностью описания преобразования данных процессом в виде последовательного алгоритма;
• единственной логической функцией преобразования входной информации в выходную;
• возможностью описания логики процесса при помощи спецификации небольшого объема (не более 20 - 30 строк).
Спецификации должны удовлетворять следующим требованиям:
• для каждого процесса нижнего уровня должна существовать одна только одна спецификация;
• спецификация должна определять способ преобразования входных потоков в выходные;
• нет необходимости (по крайней мере, на стадии формирования требований) определять метод реализации этого преобразования;
• спецификация должна стремиться к ограничению избыточности - не следует переопределять то, что уже было определено на диаграмме;
• набор конструкций для построения спецификации должен быть простым и понятным.
Фактически спецификации представляют собой описания алгоритмов задач, выполняемых процессами. Спецификации содержат номер или имя процесса, списки входных и выходных данных и тело (описание) процесса, являющееся спецификацией алгоритма или операции, трансформирующей входные потоки данных в выходные. Известно большое количество разнообразных методов, позволяющих описать тело процесса. Соответствующие этим методам языки могут варьироваться от структурированного естественного языка или псевдокода до визуальных языков проектирования.
Структурированный естественный язык применяется для читабельного, достаточно строгого описания спецификаций процессов. Он представляет собой разумное сочетание строгости языка программирования и читабельности естественного языка и состоит из подмножества слов, организованных в определенные логические структуры, арифметических выражений и диаграмм.
После построения законченной модели системы ее необходимо верифицировать (проверить на полноту и согласованность). В полной модели все ее объекты (подсистемы, процессы, потоки данных) должны быть подробно описаны и детализированы. Выявленные не детализированные объекты следует детализировать, вернувшись на предыдущие шаги разработки. В согласованной модели для всех потоков данных и накопителей данных должно выполняться правило сохранения информации: все поступающие куда-либо данные должны быть считаны, а все считываемые данные должны быть записаны.
Для завершения анализа функционального аспекта системы строится полная контекстная диаграмма, включающая диаграмму нулевого уровня. При этом подсистема учета и регистрации декомпозируется на четыре процесса. Существующие "абстрактные" потоки данных между терминаторами и процессами трансформируются в потоки, представляющие обмен данными на более конкретном уровне.
Концептуальная модель данных в виде ERD (сущность - связь) строится исходя из следующих соображений: DFD - сущности могут быть распознаны как структуры данных в DFD. Чтобы рассматривать объект в качестве сущности, он должен обладать более чем одним атрибутом;
• связи должны отражать наличие взаимодействия между сущностями, причем в системе должна сохраняться информация об этом взаимодействии.
С использованием построенных структур данных определяются атрибуты каждой сущности и изображаются на диаграмме. Внешние ключи можно не показывать, поскольку они определяются связями между сущностями. Выделяются (при необходимости) зависимые от идентификатора сущности и связи "супертип - подтип".
Проверяется соответствие между описанием структур данных и концептуальной моделью (все элементы данных должны быть использованы в качестве атрибутов).
На стадии проектирования выполняются детальное описание функционирования системы, дальнейший анализ используемых данных и построение реляционной модели для последующего проектирования базы данных. Определяется структура пользовательского интерфейса. Результатами проектирования являются:
• модель системных процессов;
• архитектура ЭИС;
• модели данных приложений;
• модель пользовательского интерфейса.
На стадии реализации выполняются генерация SQL-предложений, определяющих структуру целевой БД (таблицы, индексы, ограничения целостности), и генерация кода приложений.
Получаемая в результате БД является основой для последующих камеральных проверок и ведения лицевых карточек предприятий.
Сущность структурного подхода к разработке ПО ЭИС заключается в его декомпозиции (разбиении) на автоматизируемые функции. В структурном анализе используются в основном две группы средств, иллюстрирующих функции, выполняемые системой, и отношения между данными.
Функциональная модель представляет собой набор диаграмм потоков данных (далее - ДПД), которые описывают смысл операций и ограничений. ДПД отражает функциональные зависимости значений, вычисляемых в системе, включая входные значения, выходные значения и внутренние хранилища данных. ДПД - это граф, на котором показано движение значений данных от их источников через преобразующие их процессы к их потребителям в других объектах.
ДПД содержит процессы, которые преобразуют данные, потоки данных, которые переносят данные, активные объекты, которые производят и потребляют данные, и хранилища данных, которые пассивно хранят данные.
Процессы
Процесс преобразует значения данных. Процессы самого нижнего уровня представляют собой функции без побочных эффектов (примерами таких функций являются вычисление суммы двух чисел, вычисление комиссионного сбора за выполнение проводки с помощью банковской карточки и т.п.). Весь граф потока данных тоже представляет собой процесс (высокого уровня). Процесс может иметь побочные эффекты, если он содержит нефункциональные компоненты, такие как хранилища данных или внешние объекты.
На ДПД процесс изображается в виде эллипса, внутри которого помещается имя процесса; каждый процесс имеет фиксированное число входных и выходных данных, изображаемых стрелками (см. рисунок 1).
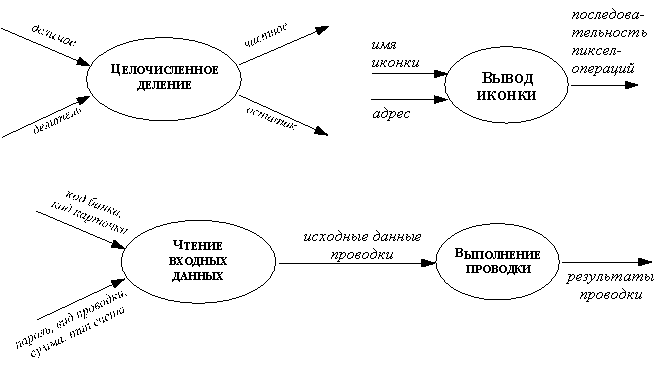
Рис.3. Примеры процессов
Процессы реализуются в виде методов (или их частей) и соответствуют операциям конкретных классов.
Потоки данных
Поток данных соединяет выход объекта (или процесса) со входом другого объекта (или процесса). Он представляет промежуточные данные вычислений. Поток данных изображается в виде стрелки между производителем и потребителем данных, помеченной именами соответствующих данных; примеры стрелок, изображающих потоки данных, представлены на рисунке 2. На первом примере изображено копирование данных при передаче одних и тех же значений двум объектам, на втором - расщепление структуры на ее поля при передаче разных полей структуры разным объектам.

Рис. 4. Потоки данных
Активные объекты
Активным называется объект, который обеспечивает движение данных, поставляя или потребляя их. Активные объекты обычно бывают присоединены к входам и выходам ДПД. Примеры активных объектов показаны на рисунке 3. На ДПД активные объекты обозначаются прямоугольниками.
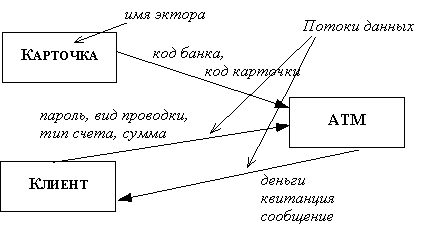
Рис. 5. Активные объекты (экторы)
Хранилища данных
Хранилище данных - это пассивный объект в составе ДПД, в котором данные сохраняются для последующего доступа. Хранилище данных допускает доступ к хранимым в нем данным в порядке, отличном от того, в котором они были туда помещены. Агрегатные хранилища данных, как например, списки и таблицы, обеспечивают доступ к данным в порядке их поступления, либо по ключам. Примеры хранилищ данных приведены на рисунке 4.
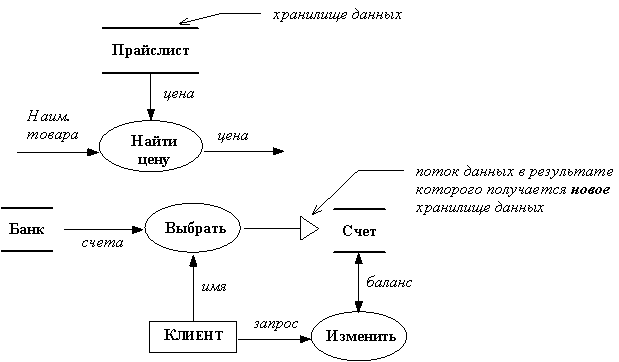
Рис. 6. Хранилища данных
Потоки управления
ДПД показывает все пути вычисления значений, но не показывает в каком порядке значения вычисляются. Решения о порядке вычислений связаны с управлением программой, которое отражается в динамической модели. Эти решения, вырабатываемые специальными функциями, или предикатами, определяют, будет ли выполнен тот или иной процесс, но при этом не передают процессу никаких данных, так что их включение в функциональную модель необязательно. Тем не менее, иногда бывает полезно включать указанные предикаты в функциональную модель, чтобы в ней были отражены условия выполнения соответствующего процесса. Функция, принимающая решение о запуске процесса, будучи включенной в ДПД, порождает в ДПД поток управления (он изображается пунктирной стрелкой).

Рис. 7. Поток управления
На рисунке 5 изображен пример потока управления: клиент, желающий снять часть своих денег со счета в банке, вводит в ATM пароль и требуемую сумму, однако фактическое снятие и выдача денег происходит только в том случае, когда введенный пароль совпадает с его образцом.
Несмотря на то, что потоки управления иногда оказываются весьма полезными, следует иметь в виду, что включение их в ДПД приводит к дублированию информации, входящей в динамическую модель.
Задание на работу:
построить диаграмму потоков данных для всей информационной системы в целом и для отдельных подсистем.
Отчет должен содержать:
Название и цель работы.
Ход работы с детальным описанием выполненных действий с рисунками.
Выводы о проделанной работе.