

1.7 Вокодеры типа celp
В вокодерах типа CELP (Code Excited Linear Prediction) используют основную схему вокодеров с обратной связью (рис 1.21).
Рис. 1.21
При передаче (в кодере) в кратковременном анализаторе производят удаление формант, в долговременном анализаторе удаление основного тона, и алгоритмы этих двух этапов обработки речи принципиально не отличаются оттого, что было в вокодере RPE-LTP. Оба эти этапа основаны на использование алгоритмов линейного предсказания.
Принципиальное отличие вокодеров типа
CELP от вокодеров RPE-LTP
состоит в аппроксимации второго
остаточного сигнала
![]() .
Здесь просто отбрасывают получающийся
на выходе долговременного анализатора
остаточный сигнал
.
Здесь просто отбрасывают получающийся
на выходе долговременного анализатора
остаточный сигнал
![]() ,
и вместо его аппроксимации в специальной
базе данных, называемой фиксированной
кодовой книгой, генерируют сигнал
.
Возможны различные алгоритмы генерации
.
В сетях GSM/UMTS
используют алгебраическую кодовую
книгу, отчего соответствующий вокодер
получил название ACELP
(Algebraic Code
Excited Linear
Prediction). Оптимизацию второго
остаточного сигнала в соответствии с
рис. 1.21 осуществляют по минимуму
среднеквадратичной ошибки:
,
и вместо его аппроксимации в специальной
базе данных, называемой фиксированной
кодовой книгой, генерируют сигнал
.
Возможны различные алгоритмы генерации
.
В сетях GSM/UMTS
используют алгебраическую кодовую
книгу, отчего соответствующий вокодер
получил название ACELP
(Algebraic Code
Excited Linear
Prediction). Оптимизацию второго
остаточного сигнала в соответствии с
рис. 1.21 осуществляют по минимуму
среднеквадратичной ошибки:
![]() ,
(1.32)
,
(1.32)
где
![]() - отсчеты речевого сигнала на выходе
вокодера,
- отсчеты речевого сигнала на выходе
вокодера,
![]() - восстановленное значение отсчета на
выходе декодера вокодера.
- восстановленное значение отсчета на
выходе декодера вокодера.
В вокодерах, однако, минимизируют не просто функцию Е (1.32), а фильтрованный сигнал ошибки, для чего используют специальный взвешивающий фильтр. Его назначение состоит в регулировке обратной связи на разных частотах, а именно усилении обратной связи на частотах между формантами. На частотах формант ошибки менее ощутимы, поскольку они маскированы мощными формантами.
Характеристики взвешивающего фильтра
выбирают на основе характеристик
синтезирующего фильтра кратковременного
предсказателя с дополнительными
коэффициентами
![]() и
и
![]() :
:
 ,
(1.33)
,
(1.33)
где
![]() .
В полноскоростном ACELP
вокодере с максимальной скоростью В =
12,2 кбит/с
.
В полноскоростном ACELP
вокодере с максимальной скоростью В =
12,2 кбит/с
![]() и
и
![]() .
Передаточная функция фильтра (1.33)
определяет его характеристики. Если
.
Передаточная функция фильтра (1.33)
определяет его характеристики. Если
![]() ,
то коэффициент передачи
,
то коэффициент передачи
![]() и взвешивания сигнала ошибки нет. Если
же
и взвешивания сигнала ошибки нет. Если
же
![]() ,
то взвешивающий фильтр подавляет ошибки
на частотах формант почти, как
фильтр-анализатор в кратковременном
предсказателе.
,
то взвешивающий фильтр подавляет ошибки
на частотах формант почти, как
фильтр-анализатор в кратковременном
предсказателе.
Так как процессы в схеме вокодера линейны, то взвешивающий фильтр можно поставить до вычитающего устройства в обеих ветвях. В результате получим схему рис 1.22

Рис. 1.22
В схеме 1.22 характеристики фильтра кратковременного анализатора
![]() ,
(1.34)
,
(1.34)
а взвешивающего синтезирующего фильтра
 ,
(1.35)
,
(1.35)
Взвешенный входной сигнал
![]() ,
(1.36)
,
(1.36)
а минимизируемая среднеквадратичная ошибка.
![]() (1.32')
(1.32')
Введем для описания петли обратной связи на рис. 1.22 специфическую терминологию. Как и в вокодере RPE-LTP,
![]() ,
(1.37)
,
(1.37)
где для генерации
используют кодовую стохастическую
книгу, а
![]() получают из кодовой адаптивной книги.
получают из кодовой адаптивной книги.
Процесс синтеза сигнала вокодера иллюстрирует рис. 1.23:
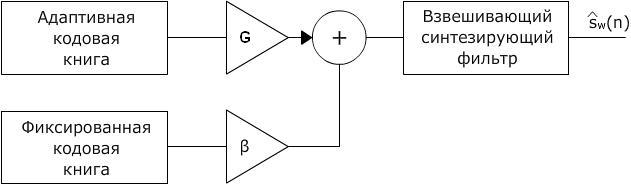
Рис 1.23
С помощью кодовой адаптивной книги
идет восстановление основного тона. В
качестве стохастической книги в вокодере
ACELP используют фиксированную
алгебраическую кодовую книгу, на основе
которой генерируют оптимальный сигнал
возбуждения. Временной сдвиг
![]() и коэффициент усиления G
получают в долговременном анализаторе
(рис. 1.22). Что же касается сигнала
и коэффициент усиления G
получают в долговременном анализаторе
(рис. 1.22). Что же касается сигнала
![]() ,
то вектор возбуждения
,
то вектор возбуждения
![]() и его амплитуду (коэффициент усиления)
и его амплитуду (коэффициент усиления)
![]() следует искать, минимизируя взвешенную
ошибку Ew
(1.32').
следует искать, минимизируя взвешенную
ошибку Ew
(1.32').
Рассмотрим, как работает вокодер ACELP при сжатии речевого сигнала до скорости 12,2 кбит/с. Этот вариант был разработан для стандарта GSM и получил название EFR (Enhanced Full Rate) улучшенного полноскоростного вокодера.
Далее на его базе был создан AMR (Adaptive Multi-Rate) – адаптивный многоскоростной вокодер со скоростями 12,2 4,75 кбит/c. В конце параграфа будут приведены характеристики AMR вокодера, а сейчас обратимся к варианту EFR или AMR со скоростью 12,2 кбит/с.
Как в любом вокодере, процесс обработки
речи состоит из трех этапов: удаление
формант, удаление основного тока,
аппроксимации второго остаточного
сигнала. Первые два этапа принципиально
не отличаются от процессов в вокодере
RPE-LTP. Однако
более высокая производительность
процессоров позволила существенно
улучшить характеристики параметров
линейного предсказания. Поступающий
на вход вокодера цифровой сигнала
разбивает на сегменты длиной 20 мс (160
отсчетов ТФ сигнала). Кратковременный
анализатор построен на основе фильтра
с характеристикой A(z)
(1.34). В отличие от вокодера RPE-LTP,
где для линейного предсказания отсчета
s(n) использовали
8 предыдущих отсчетов (p=8),
в вокодере EFR их 10 (p=10).
Коэффициенты фильтра
![]() вычисляют по тому же алгоритму что и в
RPE-LTP (алгоритм
Левинсона-Дарбина). Для передачи значений
по радиоканалу с целью уменьшения объема
информации использует преобразование
массива
в ансамбль линейных спектральных пар.
В результате для передачи коэффициентов
вычисляют по тому же алгоритму что и в
RPE-LTP (алгоритм
Левинсона-Дарбина). Для передачи значений
по радиоканалу с целью уменьшения объема
информации использует преобразование
массива
в ансамбль линейных спектральных пар.
В результате для передачи коэффициентов
![]() требуется
38 бит.
требуется
38 бит.
Второй этап обработки речевого сегмента:
удаление основного тона и определение
G и
для долговременного предсказателя,
частично изменен в сравнении с алгоритмом
RPE-LTP вокодера.
Обработка первого остаточного сигнала
![]() начинается с анализа его корреляционных
свойств в открытой петле на временном
интервале 10 мс (половина подсегмента
20 мс). Таким образом, для каждой 20-мс
сегмента речи определяют приближенное
значение параметра (задержки
долговременного предсказания).
начинается с анализа его корреляционных
свойств в открытой петле на временном
интервале 10 мс (половина подсегмента
20 мс). Таким образом, для каждой 20-мс
сегмента речи определяют приближенное
значение параметра (задержки
долговременного предсказания).
После этого для каждого подсегмента длительностью 5мс рассчитывают параметры G и α по тем же формулам, что были использованы и в вокодерах RPE-LTP:
 (1.39)
(1.39)
Задержку
![]() определяют по минимуму функции
определяют по минимуму функции
 (1.40)
(1.40)
Как следует из (1.39) и (1.40), в качестве
буфера (адаптивной кодовой книги)
используют восстановленные значения
сигнала
![]() в предыдущих 5мс подсегментах.
в предыдущих 5мс подсегментах.
По сравнению с вокодерами RPE-LTP
в ACELP существенно увеличена
точность определения
и G. Поиск производят
вблизи приближенного найденного
значения![]() .
Для первого и третьего 5 мс подсегментов
в диапазоне
.
Для первого и третьего 5 мс подсегментов
в диапазоне
![]() (1.41)
(1.41)
точность определения составляет , что
требует интерполяции между отсчетами
сигналов
![]() в
(1.39) и (1.40). В диапазоне точность
составляет . Найденную задержку кодируют
9-разрядным двоичным числом (всего 512
позиций). Для четных 5мс подсегментов
определяют смещение α
относительно задержки в нечетных
подсегментах. Это смещение кодируют
6-разрядным двоичным числом.
в
(1.39) и (1.40). В диапазоне точность
составляет . Найденную задержку кодируют
9-разрядным двоичным числом (всего 512
позиций). Для четных 5мс подсегментов
определяют смещение α
относительно задержки в нечетных
подсегментах. Это смещение кодируют
6-разрядным двоичным числом.
Коэффициент усиления G определяют в диапазоне и кодируют 4-разрядным двоичным числом.
Последний, 3-й, этап синтез сигнала возбуждения в вокодере ACELP принципиально отличается от соответствующего этапа в вокодере RPE-LTP. Алгебраическая кодовая книга (рис. 1.23) генерирует в каждом подсегменте из 40 выборок 10 отсчетов одинаковой амплитуды и любого знака. Остальные 30 отсчетов равны нулю. Таким образом, кодовая книга является троичной: 1, -1, 0. Необходимо найти коэффициент усиления β и позиции отсчетов.
Восстановленный сигнал:
![]() (1.42)
(1.42)
В (1.42) знаком
![]() обозначена операция свертки во
взвешивающем синтезирующем фильтре, а
‒ начальный выходной сигнал от
прохождения предыдущего подсегмента.
обозначена операция свертки во
взвешивающем синтезирующем фильтре, а
‒ начальный выходной сигнал от
прохождения предыдущего подсегмента.
Ошибка
![]() (1.43)
(1.43)
Величина для каждого отсчета определена (фиксирована). Неизвестен вектор , который надо выбрать.
Целевая функция (среднеквадратичная ошибка):
![]() (1.44)
(1.44)
Найдем оптимальный коэффициент усиления
β, приравнивая
![]() :.
:.
 (1.45)
(1.45)
Числитель β представляет собой кросскорреляционную функцию, а знаменатель —взвешенную энергию сигнала возбуждения.
Подставим (1.45) в (1.44):
 (1.46)
(1.46)
Минимизация E означает минимизацию второго слагаемого в (1.46). Обратим внимание на то, что если бы , то ошибка была бы равна нулю.
Вычисление второго слагаемого в 1.46 можно упростить. Для этого вспомним, как осуществляется операция свертки в цифровых фильтрах. На рис. 1.24а представлен некий входной сигнал u(n), а на рис. 1.24б — импульсная характеристика фильтра .

Рис. 1.24
Если
![]() ,
то
,
то
![]()
![]()
![]() и т.д.
и т.д.
Представим операцию свертки в векторном виде:
 вектор столбец, а свертка
умножение вектора столбца на матрицу
вида:
вектор столбец, а свертка
умножение вектора столбца на матрицу
вида:

Следовательно, матрица
![]()
треугольная матрица Теплица размерностью
[40, 40], где по главной диагонали стоят
h(0), а в левом нижнем углу
hw(39).
Тогда второе слагаемое в (1.46) можно
записать так:
треугольная матрица Теплица размерностью
[40, 40], где по главной диагонали стоят
h(0), а в левом нижнем углу
hw(39).
Тогда второе слагаемое в (1.46) можно
записать так:
![]() (1.47) Так как операции свертки и
умножения коммутативны, то
(1.47) Так как операции свертки и
умножения коммутативны, то
![]() (1.48)
(1.48)
В числителе (1.48) выражение в квадратных
скобках фиксировано, так что вычисление
числителя сводится к перемножению двух
векторов. Вычисление знаменателя
сложнее, но матрицу
![]() также вычисляют один раз, а вектор V(n)
содержит большое число нулей. Существуют
алгоритмы, упрощающие вычисление
также вычисляют один раз, а вектор V(n)
содержит большое число нулей. Существуют
алгоритмы, упрощающие вычисление
![]() .
.
Итак, надо найти максимум R(n), изменяя V(n). Для этого в кодере ACELP используют следующий алгоритм. 40 отсчетов вектора V(n) разбиты на 5 групп, по 8 отсчетов в каждой (табл. 1.2).
Таблица 1.2
-
Группа
Отсчеты
Номера отсчетов
1

0, 5, 10, 15, 20, 25, 30, 35
2

1, 6, 11, 16, 21, 26, 31, 36
3
2, 7, 12, 17, 22, 27, 32, 37
4

3, 8, 13, 18, 23, 28, 33, 38
5

4, 9, 14, 19, 24, 29, 34, 39
В результирующий вектор V(n)
попадут по два отсчета из каждой группы.
Алгоритм поиска начинается с того, что
для каждой группы, перебирая все 8,
находят один отсчет, при котором R(n)
максимально. Из 5 возможных вариантов
определяют глобальный максимум. Неважно,
из какой группы будет отсчет, его теперь
обозначают как
![]() .
.
На следующем этапе берут один из
оставшихся локальных максимумов (этот
отсчет обозначают, как
![]() )
и выполняют последовательно 4 итерации.
Поменяв номера групп в табл. 1.2 в
соответствии с выбранными
и
,
далее добавляют пары
)
и выполняют последовательно 4 итерации.
Поменяв номера групп в табл. 1.2 в
соответствии с выбранными
и
,
далее добавляют пары
![]() ,
вычисляя все возможные варианты R(n).
Так как каждый отсчет имеет 8 возможных
позиций, то всего будет 8×8 комбинаций
для каждой пары, и, следовательно, 256
различных комбинаций положения импульсов
для каждой итерации. Так как каждый
значащий отсчет может принимать значения
,
вычисляя все возможные варианты R(n).
Так как каждый отсчет имеет 8 возможных
позиций, то всего будет 8×8 комбинаций
для каждой пары, и, следовательно, 256
различных комбинаций положения импульсов
для каждой итерации. Так как каждый
значащий отсчет может принимать значения
![]() ,
то требуется 1024 вычислений R(n)
для каждой итерации.
,
то требуется 1024 вычислений R(n)
для каждой итерации.
После того, как определен максимум R(n) по всем итерациям, фиксируются значения отсчетов в каждой группе и знак. Если оба отсчета в группе имеют одинаковый знак, то их кодируют в порядке возрастания номера. Если знаки разные, то вначале кодируют старший отсчет. Таким образом, для передачи строки отсчетов требуется 7 бит, а 5 строк 35 бит. Коэффициент усиления кодируют 5 битами. В результате для передачи параметров одного речевого 20мс сегмента требуется:
38 бит коэффициенты фильтра кратковременного предсказания,
![]() бит характеристики
долговременного предсказателя,
бит характеристики
долговременного предсказателя,
![]() бит
параметры сигнала
возбуждения.
бит
параметры сигнала
возбуждения.
Всего:
![]() бита,
что соответствует скорости передачи
бита,
что соответствует скорости передачи
![]()