

1.6 Вокодер rpe-ltp
Начнем последовательно рассматривать обработку сигнала в кодере вокодера RPE-LTP. На первом этапе происходит удаление формант в кратковременном анализаторе (предсказателе).
Прежде всего, следует выбрать порядок предсказателя р. Минимальную величину р можно найти, изучив процесс формирования звуков в речевом тракте. Для адекватного представления речевого тракта необходимо учитывать выборки на временном интервале Δt, по крайней мере, в 2 раза большем, чем время распространения звуковой волны от голосовых связок до губ. Если принять это расстояние равным 17 см, а скорость звуковой волны 340 м/с, получим Δt=1мс. При частоте выборок fT = 8 кГц получим min{p}= 8. Для более качественного предсказания следует увеличивать p до 10 - 12, однако при этом возрастает объем вычислений при определении {ак} и число бит, необходимых для их передачи. Поэтому во многих кодерах, как, например, в RPE-LTP берут р = 8.
Процесс вычисления коэффициентов аk основан на минимизации среднеквадратичной ошибки
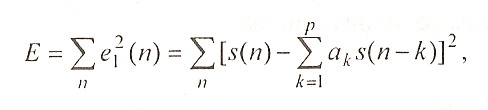 (1.18)
(1.18)
где п - число выборок в сегменте. Для этого находят производные дЕ/даk и приравнивают их нулю. В результате получаем систему из р уравнений
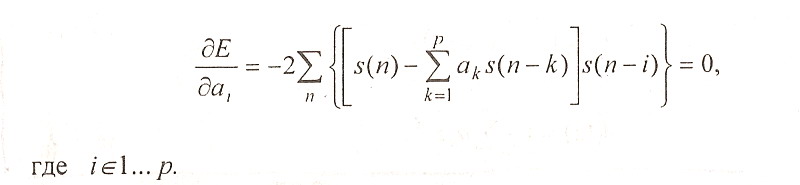 (1.19)
(1.19)
Преобразуем (1.19) к виду
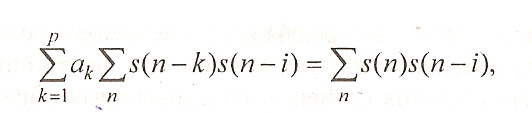
(1.20)
где i 1... р, а суммирование ведут по всем "n" отсчетам сегмента.
Запись системы (1.20)
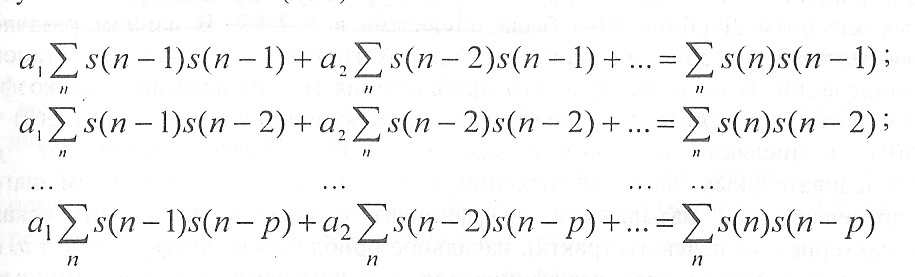
можно упростить, поскольку знак суммирования ∑ означает суммирование по всем п , т.е. формально суммирование бесконечного ряда. Так как отсчеты s (п) за пределами сегмента приняты равными нулю, то любую сумму можно представить автокорреляционной функцией
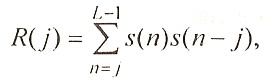
где параметр j - сдвиг в номере выборок.
В результате система (1.20) приобретает следующий вид:
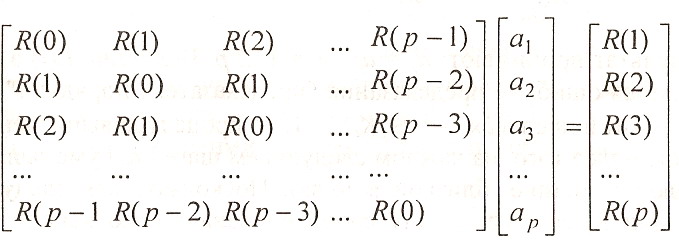
(1.21)
Левая матрица системы (1.21) является симметричной матрицей Теплица и для. решения этой системы применяют рекурсивную процедуру, известную как алгоритм Дурбина.
На практике используют следующий подход. Алгоритм содержит р этапов вычислений. В качестве нулевого приближения (i = 0) полагают все коэффициенты аk = 0 (k=1...р), а среднеквадратичную ошибку предсказания Е(0) = R(0) вычисляют в соответствии с (1.18). Далее выполняют р последовательных шагов вычислений, от i = 1 до i = р. На каждом шаге определяют так называемый коэффициент отражения Кi , (акустическая характеристика речевого тракта), начальное приближение коэффициента аk и уточняют значения всех коэффициентов аk с номерами j < i с помощью следующих соотношений:

(1.22)
За конечный результат принимают aj = aj p , j = 1 ... р. Величина E(i) в уравнении (1.22) является ошибкой предсказания "предсказателя порядка i" . Так как диапазон Kt лежит в пределах -1 < Kt < 1, то процедура вычислений Kt сходящаяся. Более того, на каждом следующем шаге |Kt| уменьшается, стремясь к малой величине, близкой к нулю. Поскольку аk и Kt связаны между собой однозначно, по каналу связи целесообразно вместо вектора коэффициентов {аk} передавать вектор
{ Kt } и даже не сами Ki а так называемые логарифмические отношения
LARi = log ((1-Ki )/( 1+Ki))
С увеличением номеров i динамический диапазон LARi сжимается, что требует меньшего числа бит для передачи. Обычно при р = 8 для передачи вектора {LARi} достаточно 36 бит, распределение которых приведено в табл. 1.1.
Таблица. 1.1
-
i
Длина LARi бит
1:2
6
3:4
5
5:6
4
7:8
3
Структура работы кратковременного анализатора показана на рис. 1.14
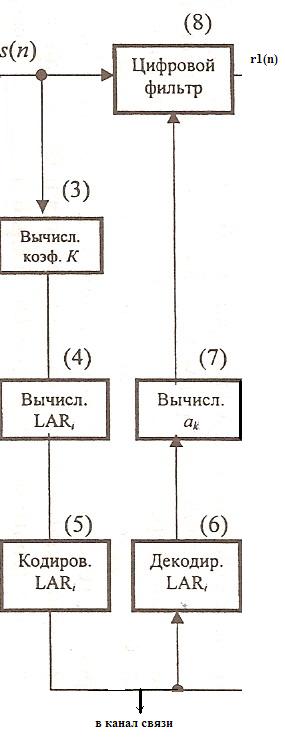 Рис.
1.14. Алгоритм работы кратковременного
анализатора
Рис.
1.14. Алгоритм работы кратковременного
анализатора
П осле
проведения анализа на основе
кратковременного предсказания с помощью
операции (1.12) вычитанием "предсказанного"
сигнала из реального получаем первый
остаточный сигнал.
осле
проведения анализа на основе
кратковременного предсказания с помощью
операции (1.12) вычитанием "предсказанного"
сигнала из реального получаем первый
остаточный сигнал.
Над этим сигналом далее производят операцию по устранению избыточности, выявляя и удаляя колебания с частотой основного тона. Поскольку речь идет о квазипериодическом колебании, то его можно охарактеризовать двумя параметрами: амплитудой и периодом. Для этой цели на втором этапе анализа используют долговременный предсказатель. Ошибка на его выходе представляет собой второй остаточный сигнал
е2(п) = r2(п)= r1(п) – G r1(п - α), (1.23)
где α - целое число, лежащее в пределах 20 160, что соответствует частоте основного тона 40 400 Гц.
Выполняя над обеими частями (1.23) z-преобразование, получаем
r2(z) = (1-Gz-α)r1(z) (1.24)
где 1-Gz-a - передаточная характеристика цифрового фильтра с одним отводом. Обратное преобразование
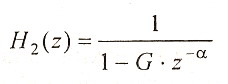
(1.25)
в синтезаторе речи позволяет восстановить первый остаточный сигнал r1 (п) по второму остаточному сигналу:
![]() (1.26)
(1.26)
Выбор оптимальных G и α производят путем минимизации среднеквадратичной ошибки
![]()
(1.27)
где N1 - число анализируемых отсчетов. Приравнивая ∂E/∂G=0, находим оптимальный коэффициент передачи
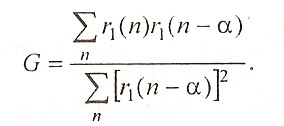
(1.28)
После подстановки (1.28) в (1.27) получим
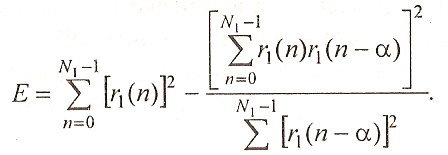
(1.29)
Величину α находят перебором, максимизируя второе слагаемое в выражении 1.29, после чего вычисляют согласно (1.28) оптимальное G.
Для получения требуемой точности синтеза речевого сигнала при приеме речевой сегмент длиной 20 мс на этапе долговременного анализа разбивают на 4 подсегмента длиной 5 мс каждый.
Для α ≥ N 1 элементы вектора

Вторая особенность выполнения процедуры долговременного предсказания обусловлена видом применяемой обратной связи в кодирующем устройстве по схеме "анализ-синтез" (рис.1.15). На практике часто упрощают схему рис.1.13, используя частичные обратные связи. Так, в кодерах станций системы GSM петля обратной связи охватывает все блоки 3-го этапа анализа и замыкается на долговременном предсказателе (рис. 1.15).
r1 вос (п) = r2 вос (п) + G r1 вос (п-α) (1.30)
В этой схеме предшествующий сигнал, т.е. сигнал r1 (п- α ) заменяют восстановленным сигналом r1вос(n-a) предыдущих подсегментов, полученным из восстановленного второго остаточного сигнала
Таким образом, в поисковом буфере, в кодовой книге хранят α max - α min векторов восстановленного сигнала r1вос(п). При расчетах в формулах (1.27) - (1.29) используют векторы кодовой книги, составленные из отсчетов r1вос(п- α). Второй остаточный сигнал на выходе долговременного предсказателя (рис.1.15)
r2 (п) = r1(п) - G r1вос(п- α) (1.31)
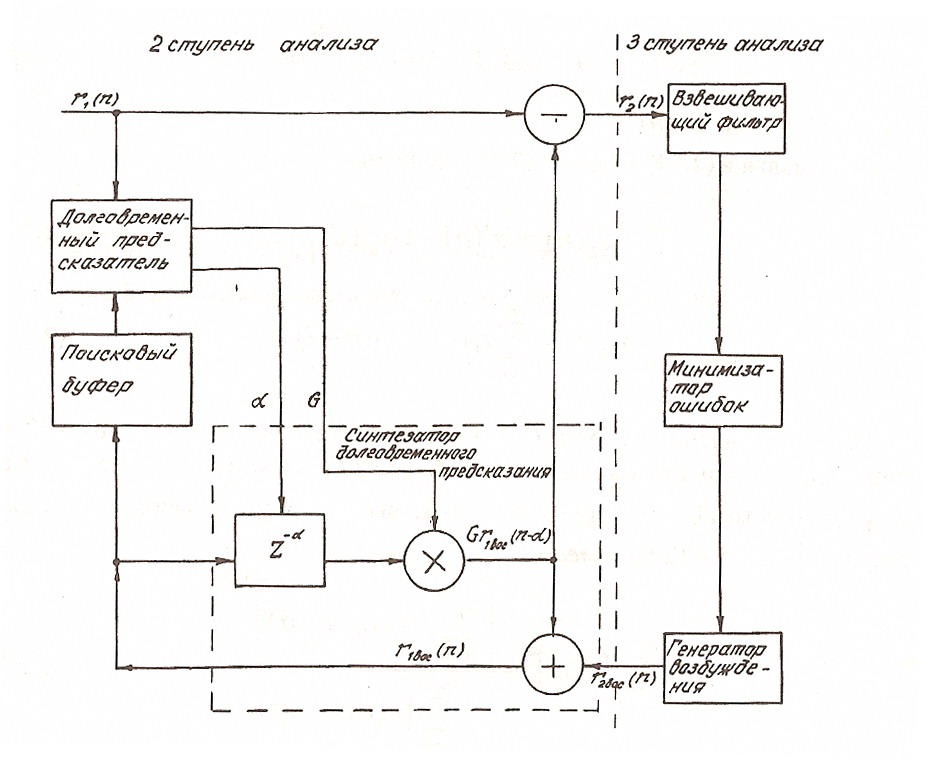
Рис.1.15. Структура долговременного предсказателя
Итак, в результате выполнения процедуры долговременного предсказания по каналу связи передают параметры G и а для каждого подсегмента речи. При передаче α кодируют семибитовым двоичным числом; для передачи G используют от двух до четырех бит. Временные диаграммы сигналов: исходного речевого сигнала s (t), первого остаточного r1(t) и второго остаточного г2 (/) показаны на рис.1.16. Второй остаточный сигнал является чисто шумовым. В схеме рис.1.15 именно его подвергают аппроксимации на 3-м этапе обработки в кодере.
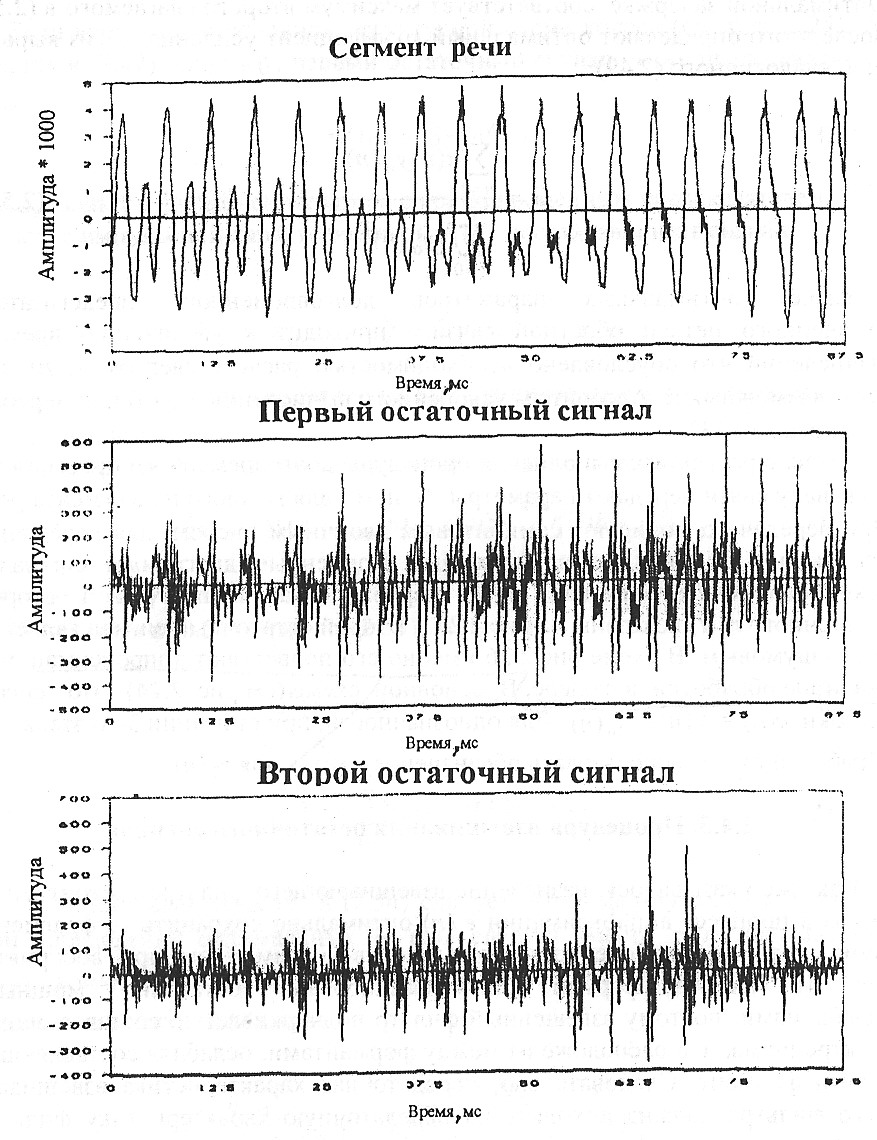
Рис. 1.16. Временные диаграммы речевого сигнала в процессе удаления
избыточности
Последний этап кодирования речевого сигнала после выявления избыточности в кратковременном и долговременном предсказателях состоит в аппроксимации сигнала ошибки. Его надо заменить сигналом возбуждения так, чтобы для передачи по каналу связи потребовалось бы как можно меньше бит. В вокодере RPE-LTP используют возбуждение регулярной последовательностью импульсов (РПИ).
Идея метода состоит в том, что N 1, отсчетов подсегмента заменяют "решеткой" из М отсчетов, расположенных эквидистантно.
Оптимальной решетке соответствует максимум остаточного сигнала на выходе. При передаче параметров решётки по каналу связи для каждого подсегмента используют:
2 бита для кодирования смещения решётки,
6 бит для кодирования амплитуды максимального по величине импульса,
3 бита для кодирования относительной амплитуды каждого из отсчетов решётки.
При D =3, N1= 40, М= 13 получаем 47 бит на один подсегмент, 188 бит для передачи параметров четырёх решёток и всего 260 бит за 20 мс, что соответствует скорости передачи 13 кбит/с.
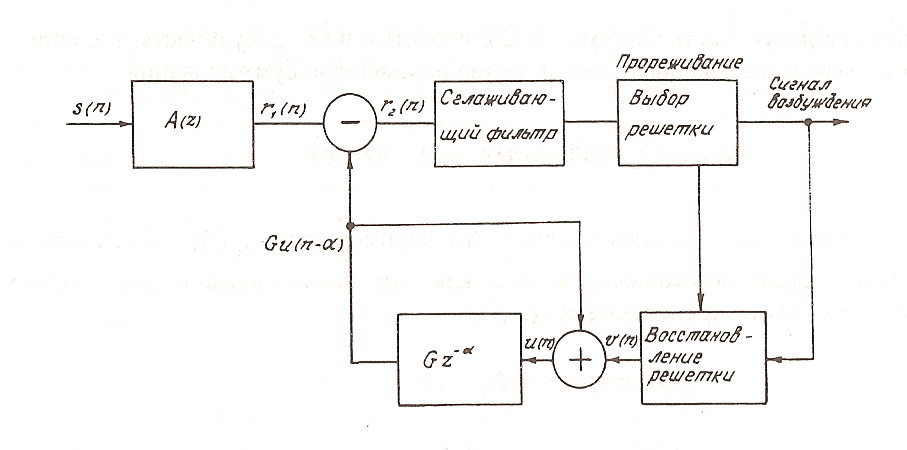
Рис.1.18. Структура кодирующего устройства
Схема, изображенная на рис.1.18, использована в речевых кодерах RPE-LTP стандарта GSM.
Оптимальному выбору решетки соответствует максимум суммы квадратов отсчетов решетки, полученной в результате фильтрации и прореживания второго остаточного сигнала. Таким образом, для нахождения оптимальной решетки достаточно отфильтровать второй остаточный сигнал в сглаживающем фильтре и затем (D - 1) раз вычислить сумму квадратов отсчетов прореженной решетки.
Структура кодирующего устройства вокодера RPE-LTP показана на рис. 1.19.
Схема
речевого декодера приемника приведена
на рис. 1.20. Так как в кодере на отдельных
этапах обработки производилось
восстановление остаточных сигналов
г1вос
(п)
и
г2вос(п)
аналогично
тому, как это происходит в декодере,
схема декодера (рис.1.20) не требует особых
пояснений. После демультиплексирования
260 бит информации (блок 1) на выходе блока
(2) восстанавливают аппроксимированный
остаточный сигнал г2вос(п),
а
на выходе блока (4) сигнал г1вос(и).
В блоке (10) происходит декодирование
коэффициентов LARi
в
блоке (9) вычисление коэффициентов
цифрового фильтра и, наконец, на выходе
цифрового фильтра (8) преобразованием
H1(z)получают
синтезированный сигнал
![]() (п).
Выходной
корректор (11) восстанавливает исходный
дискретизированный речевой сигнал
(п).
Выходной
корректор (11) восстанавливает исходный
дискретизированный речевой сигнал
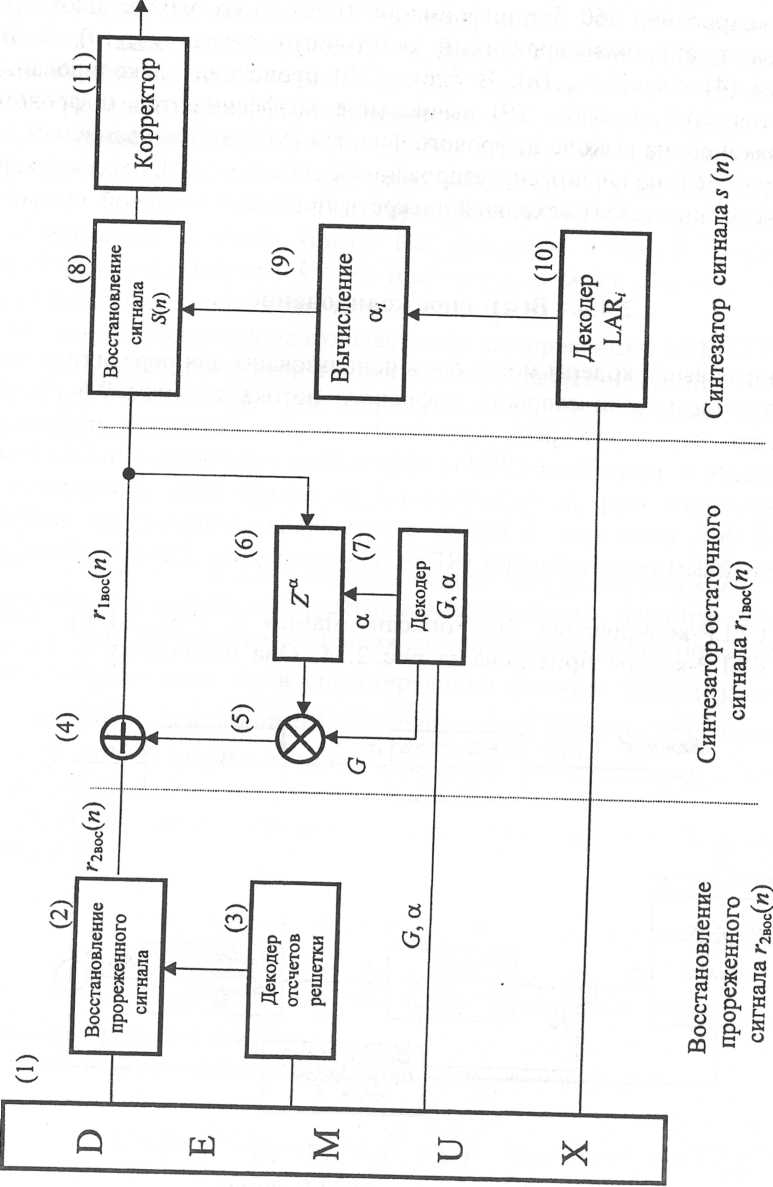
Рис. 1.20. Декодер RPE-LTP

Рис 1.19