

Глава 4
ВОЗМОЖНОСТИ ПОВЫШЕНИЯ ЭФФЕКТИВНОСТИ УПРАВЛЯЮЩИХ СИСТЕМ
4.1. Программные средства интеллектуализации
Программные средства интеллектуализации, используемые в УВМ, позволяют значительно повысить качество управления. Среди наиболее часто используемых программных средств, ис¬пользуемых в интеллектуальных системах управления, можно выделить следующие:
языки программирования (ЛИСП, ПРОЛОГ и др.); базы данных;
оболочки экспертных систем; нейронные сети;
системы типа "искусственная жизнь" (A-life). Язык ЛИСП занял особое место среди ранних языков про-граммирования, обеспечивающих возможности манипуляции на ЭВМ символами при решении задач искусственного интеллекта. Уже в 1956 году Ньюэлл, Шоу и Саймон разработали язык про¬граммирования ИПЛ, с помощью которого можно было обраба¬тывать списки. Этот язык был одним из предшественников языка программирования ЛИСП, разработанного Дж. Маккарти в 1960 году. ЛИСП стал наиболее популярным в среде специали¬стов по искусственному интеллекту, особенно в США, где в ка¬честве стандартного получил распространение его диалект COMMONLISP [40]. К достоинствам языка можно отнести точ¬ность, определенность, лаконичность и удобство в работе. ЛИСП является хорошим средством для представления древовидных структур, которые служат основой символьной обработки. Имен-
но поэтому до недавнего времени большинство программ искус¬ственного интеллекта писались на языке ЛИСП. Хотя в настоя¬щее время инструментарием для обработки списков обладают и такие развитые языки программирования, как Фортран, ПЛ/1, Паскаль, Ада и др. Кроме того, в последнее время переосмысли¬вается роль и место символьной обработки в задачах искусствен¬ного интеллекта и появляются все новые и новые инструмен¬тальные средства решения задач искусственного интеллекта.
Выражения языка ЛИСП называются ^-выражениями. Они представляют собой либо атом, либо список.
Атом представляется каким-либо алфавитно-цифровым име¬нем, т. е. в сущности числом.
Список — это некоторая внутренняя часть, заключенная в скобки.
Синтаксис языка ЛИСП в форме Бэкуса—Наура определя¬ется следующим образом:
<8-выражение>
<список>
<внутренняя часть> = <атом> = <список> = <внутренняя часть> = <пусто> = <£-выражение>
= <5-выражение> <внутренняя часть>
< пусто > <атом>
: = цепочка алфавитно-цифровых символов без пробелов или специальных символов
Таким образом, всякое S-выражение представляет собой набор атомов и списков, например: ((король ферзь)((ладья) (слон)) пешка).
Как и во всех языках программирования, некоторые предва¬рительно определенные атомы являются функциями, аргументы которых представляют собой следующие за ними ^-выражения. В свою очередь аргумент сам может быть функцией, которую нужно вычислить. При этом надо иметь возможность определить, что представляет собой данный элемент — значение выражения L или же символьное имя L какого-то ^-выражения. В первом случае перед выражением ставится апостроф, например CL, или же пи¬шут в развернутой форме: (QUOTE L). Апостроф запрещает вы-
числение следующего за ним S-выражения, которое восприни¬мается программой в этом случае без изменений.
Для задания выражения используется функция SETQ. В об-щем случае всякое 5-выражение, поступающее в машину, тут же вычисляется. Необходимо отметить, что в языке ЛИСП любая программа сама по себе является 5-выражением. В частности, в ЛИСП данные имеют ту же структуру, что и программы, и так¬же являются выражениями. Результат выполнения программы в Л ИСП также программа. Соответственно этому выражение в ЛИСП является программой. Это свойство языка ЛИСП позво¬ляет создавать программы, которые могут перестраивать сами себя.
Кроме того, в языке ЛИСП имеется возможность создавать новые функции, и для этого используется функция DEFUN.
Более подробно с языком программирования ЛИСП и ме-тодами программирования в нем можно ознакомиться в [41].
Язык ПРОЛОГ применяется для решения какой-либо зада-чи системой в терминах предикатов. История создания языка начинается с 1972 года, когда А. Кольмрауер разрабатывал со своей группой сотрудников систему автоматического доказатель¬ства, построенную на базе логики первого порядка и методе Эрбрана—Робинсона. Система автоматически выдавала ответ, используя для этого унификацию и метод резолюций. Таким образом, ПРОЛОГ можно рассматривать как декларативный язык, где единственные входные данные — это формальное оп¬ределение задачи. Так как часто желательно получение решения задачи в явном виде, то, с этой точки зрения, доказательство, основанное на опровержении специальным образом сконструи¬рованного предложения, получаемого методом резолюций, не является достаточным результатом. Поэтому в 1969 года для уст¬ранения отмеченного недостатка Грин предложил ввести в ис¬ходный набор предложений "ответный" предикат, связанный с заключением: 1 заключение (х) v вывод (х), либо заключение (х) л вывод (х), который обеспечивает получение системой ре¬шения в явном виде и выдачу х пользователю. Тем не менее ис¬пользование ПРОЛОГА эффективно только в тех случаях, когда деревья доказательства не слишком велики.
Важной областью применения языка является реализация запросов к базе данных в тех случаях, когда необходимо извлечь
из базы показатели, имеющие желаемые атрибуты. ПРОЛОГ, получив запрос, тут же начинает отыскивать ответы на него без каких-либо специальных предварительных этапов.
Другой областью, где используется ПРОЛОГ, является уп¬равление роботами. В данном случае речь идет о роботах, спо¬собных принимать решения и, исходя из этого, строить план действий. Тог же способ запоминания с помощью предикатов позволяет запоминать план, построенный с помощью резолю¬ций. При этом робот может ходить, передвигать какой-либо объект, влезать на что-то и т. д.
Наибольшее распространение получило использование языка ПРОЛОГ при создании экспертных систем.
База данных (БД) является обязательным компонентом любой интеллектуальной системы. БД представляет собой сово¬купность экземпляров различных типов записей и отношений между записями, агрегатами данных, элементами данных.
Широко признанным авторитетом в области БД является Ассоциация по языкам систем обработки данных CODASYL (Conference on Data Systems Languages), и поэтому обычно ис¬пользуется ее терминология и определения.
Запись — это поименованная совокупность элементов или агрегатов данных.
Агрегат данных — это поименованная совокупность элемен¬тов данных внутри записи, рассматриваемая как единое целое. Например, агрегат данных DATA может состоять из элементов данных — месяц, день, год.
Элемент данных — это наименьшая единица поименованных данных. Он может состоять из любого количества битов или байтов.
Таким образом, БД можно определить как совокупность вза¬имосвязанных, хранящихся вместе данных при наличии такой минимальной избыточности, которая допускает их использова¬ние оптимальным образом для одного или нескольких приложе¬ний. Данные принято запоминать так, чтобы они были незави¬симы от программ, их использующих. Кроме того, данные структурируются таким образом, чтобы была обеспечена воз- ! можность дальнейшего наращивания приложений.
Создаваемые БД должны обладать следующими свойствами: избыточностью, независимостью, взаимосвязностью данных, их защитой и возможностью доступа в режиме реального времени.
Наиболее важными характеристиками БД являются:
1. Возможность представления внутренней структуры БД, которая отражает наиболее характерные свойства данных.
2. Производительность БД, которая должна обеспечивать удовлетворительное для диалога время ответа и необходимую пропускную способность для обработки транзакций, т. е. пере-даваемых сообщений, инициирующих в системе работу опреде-ленного вида.
3. Минимальные затраты, обеспечивающие организацию дан¬ных с минимальными затратами памяти и позволяющие при их обработке использовать наиболее простые программные средства.
4. Минимальная избыточность, исключающая противоречия, возникающие при излишней избыточности, вследствие того, что различные копии данных могут находиться в различных стадиях обновления, и допускающая контроль за противоречиями.
5. Возможность поиска, которая должна обеспечивать обра-ботку таких запросов и\или формирование таких ответов, кото-рые заранее не были запланированы. При этом поиск по запросу и формирование ответов должно быть быстрым и гибким.
6. Целостность, которая должна обеспечивать неразруши-мость элементов данных и связей между ними при их исполь-зовании многими пользователями, восстанавливаемость дан-ных без потерь после сбоев в системе и проверку целостности данных и связей.
7. Безопасность и секретность, которая должна обеспечивать защиту данных от случайного доступа и от неразрешенной мо¬дификации, а также определение прав отдельных лиц или под¬систем на получение доступа к данным.
8. Связь с прошлым, которая должна обеспечивать инфор-мационную совместимость с предыдущими версиями БД.
9. Связь с будущим, которая должна обеспечивать измене-ния в БД по возможности без модификации прикладных про-грамм.
10. Эффективность настройки, обеспечивающая улучшение производительности БД за счет физической независимости дан-ных и автоматизации управления.
11. Перемещаемость данных, которая должна обеспечивать ре¬гулирование способов хранения данных в соответствии с уровнем спроса на них и возможность иметь несколько уровней доступа.
12. Простота свойств, которые используются для представ-ления общего логического описания данных.
13. Эффективность пользовательских языков в БД, которая должна обеспечивать возможность неподготовленным пользова¬телям обращаться с запросами, осуществлять поиск и обновлять данные, а также манипулировать данными и генерировать отче¬ты и документы на основе этих данных.
Основные требования к организации БД для интеллекту-альных систем (ИС) следующие:
1. Они должны обеспечивать многократное использование данных при решении задач логического вывода.
2. Программные блоки и логические структуры данных не должны переделываться при внесении изменений в БД.
3. Подсистемы и пользователи должны легко узнавать и по-нимать, какие данные имеются в их распоряжении.
4. Должно быть обеспечено обращение к данным и их поиск с помощью различных методов допуска, используемых подсис-темами и пользователями.
5. Изменения в БД должны осуществляться без нарушения имеющихся способов использования данных.
6. Хранение данных должно осуществляться с минимальны-ми затратами памяти.
7. Запросы на данные должны удовлетворяться со скорос-тью, обеспечивающей выполнение требований к времени реше-ния задач логического вывода.
8. Внутренняя структура БД должна обеспечивать хранение и обработку всех типов данных, используемых в ИС.
9. СУБД должна обеспечивать связь с пользователем, с под-системами ИС и с системами сбора и обработки данных в режи-ме реального времени при использовании в цифровых системах управления.
Современный уровень развития теории автоматического управления, искусственного интеллекта, информатики, вычис-лительной техники и опыт построения и эксплуатации интел-лектуальных проблемно-ориентированных программных средств, в частности экспертных систем (ЭС) позволяет гово-рить об актуальности использования методов и технологии об-работки знаний для организации интеллектуального управ- ления. Однако до сих пор существующие примеры применения интеллектуальных программных средств в системах управления весьма немногочисленны [42], что объясняется целым рядом объективных факторов, главными из которых являются слож¬ность и неопределенность характеристик среды функциониро¬вания и быстротечность управляемых процессов, требующая оперативного обеспечения соответствующих ответных реакций.
При разработке экспертные регуляторов (ЭР) систем уп-равления часто используются так называемые оболочки эксперт¬ных систем реального времени.
Инструментальное средство (ИнС) для создания эксперт-ной системы реального времени (ЭС РВ) впервые выпустила в 1985 году фирма Lisp Machine. ИнС называлось Picon и испол-нялось на символьных ЭВМ Symbolics. Его успех на рынкепри- вел к тому, что группа ведущих разработчиков Picon образовала в 1986 году частную фирму Gensym, которая, значительно раз¬вив идеи, заложенные в Picon, выпустила в 1988 году ИнС под названием G2 версии 1.0. Ныне функционирует версия 4.1 и го¬товятся к выпуску 5.0 и 6.0. Ряд других фирм с отставанием от Gensym на 2™3 года начали создавать (или пытаться создавать) свои ИнС для экспертных систем реального времени.
В табл. 4.1 приведен достаточно полный перечень всех фирм и объявленных ими продуктов. Следует отметить, что, несмотря на значительное количество объявленных ИнС, в этом списке мно¬го либо незавершенных ИнС, либо таких, которые только с боль¬шой натяжкой могут быть отнесены к ИнС для создания ЭС РВ.
Таблица 4. 1 Оболочки экспертных систем реального времени
Продукт Фирма- производитель Страна Платформа (ПЭВМ/Рст)
Activation Framework Real Time Intelligent Systems США ПЭВМ
Chronos S20 Франция ПЭВМ
COGSYS SC Scicon Англия Рст
COMDALE/C Comdale Technologes Канада ПЭВМ и Рст
Продукт Фирма- производитель Страна Платформа (ПЭВМ/Рст)
Escort PA Consultants Англия Рст
Expert 90 Bailey США Рст
G2 Gensym США ПЭВМ и Рст
ILOG Rules (XRETE) ILOG Франция ПЭВМ и Рст
Mercury Artificial Intelligence Tech. (A.I.T.) США ПЭВМ
Montrex Stone and Webster США Рст
Muse Cambridge Consultants Англия ПЭВМ
Promass IJnibid Англия ПЭВМ и Рст
Rocky Expert Edge США ПЭВМ
RTES Knowledge Systems США Рст
RTAC /Power Mitech США ПЭВМ
RT/AI XntelliSys США ПЭВМ
RT Expert Integrated Systems Inc. США Рст
RT Works Talarian Corp. США Рст
SNAP Template Software США Рст
NDC Expert Honeywell США Рст
Пока наиболее продвинутым инструментом создания ЭС РВ, безусловно, остается G2 (Gensym, США), за ним со значитель¬ным отставанием (реализовано менее 50 % возможностей G2) следуют RT Works фирмы Talarian (США), COMDALE/C (Comdale, Канада), COGSYS (SC, США), ILOG Rules (ILOG, Франция). В табл. 4.2 G2 сравнивается со следующими группами ИнС для создания ЭС РВ:
Группа А — статистические оболочки ЭС, Группа В — супервизорные системы управления,
Таблица 4. 2
Сравнительная характеристика G2 и программируемых продуктов групп А, В, С, D
Свойства ЭСРВ Группа А Группа В Группа С G2
Работа в реальном, внутренний плани¬ровщик, параллельные процессы рассу¬ждения - + + +
Структурированный естественно¬языковой интерфейс, с управлением че-рез меню и автоматической проверкой синтаксиса - - - +
Общие правила, уравнения и динамиче¬ские модели, применимые к классам объектов - - - +
Обратный и прямой вывод, сканирова¬ние, фокусирование, использование ме¬тазнаний - - - +
Интеграция подсистемы моделирования с динамическими моделями - - - +
Структурирование БЗ, наследование свойств, понимание связей между объ-ектами - - - +
Библиотеки знаний - ASCII-файлы, портируемые на любые аппаратные платформы без какого-либо дополни¬тельного программирования - - - +
Развитый редактор для сопровождения базы знаний без программирования - - - +
Средства инспекции базы знаний + + +
Средства управления доступом с помо¬щью механизма авторизации пользова¬теля и обеспечение желаемого "взгляда" на приложение - + - +
Средства трассировки и отладки БЗ + - + +
Интерфейс оператора включает графи¬ки, диаграммы, шкалы, кнопки, редак¬тор многослойных пиктограмм - + - +
Свойства ЭС РВ Группа А Группа В Группа С G2
Исполняется на ряде универсальных ЭВМ, включая рабочие станции DEC, HP, SUN, IBM + + ... +
Кооперация ЭС реального времени по сетевому протоколу TCP/IP или DECnet с другими приложениями - - - +
Удаленные окна, включая интерактив¬ную многопользовательскую работу - - - +
Интерфейсы с источниками данных обеспечивают эффективную связь с внешними системами и СУБД - + + +
Группа С — оболочки ЭС реального времени, перечислен-ные в табл. 4.1, исключая G2.
При сравнении учитывалось наличие или отсутствие в ука-занных группах ИнС ключевых функциональных возможностей, необходимых для разработки ЭС РВ.
Общий итог по результатам сравнения 16 позиций: Группа А — реализовано 3 свойства из 16 (18 % от функци-ональных возможностей G2),
Группа В — реализовано 5 свойств из 16 (31 % от функцио¬нальных возможностей G2),
Группа С -- реализовано 3 свойства из 16 (18 % от функци-ональных возможностей G2).
Базу знаний (БЗ) во всех трех системах можно условно раз-делить на структуры данных, с которыми работает система, и выполнимые утверждения, которые обеспечивают манипули-рование данными.
Все три системы в части структурирования данных приме-няют объектно-ориентированный подход, однако каждая из них вносит свою специфику в объектно-ориентированную методо¬логию представления данных.
Понятие класса является в G2 основой представления зна-ний. Все, что хранится в БЗ и чем оперирует система, — это эк- землляр того или иного класса. Более того, все синтаксические конструкции G2 тоже являются классами. Классы и ничего кро¬ме классов и их экземпляров! Описание класса (тоже экземпляр специального класса) включает ссылку на суперкласс (иерар¬хия "is-a") и перечень атрибутов, специфичных для класса (иерархия "part-of"). До последнего времени системе G2 были присущи только два недостатка: отсутствие множественного на¬следования (разрешена лишь древовидная схема наследования свойств) и невозможность написания присоединенных проце¬дур-методов для класса. В последней, четвертой, версии системы эти недостатки устранены.
В системе RTworks множественное наследование для клас-сов разрешено, однако, в отличие от G2, каждый конкретный экземпляр может быть представителем только одного класса, т. е. экземпляр производного класса-родителя, что не позволяет записывать обобщенные утверждения, оперирующие сразу с мно¬жеством классов. Кроме того, в отличие от G2, атрибутом клас¬са не может быть экземпляр другого класса. Это значит, что три¬виальная для G2 задача описания составных объектов (например, автомобиль с четырьмя колесами) становится практически не¬разрешимой в RTworks.
Хотя в TDC Expert пользователь тоже оперирует понятиями "класс" и "экземпляр класса", тем не менее в этой системе от-сутствует реализация основной концепции объектно-ориенти-рованного подхода — наследование свойств и иерархии классов. Класс в смысле TDC Expert — это просто описание набора ат¬рибутов, присутствующих в экземпляре данного класса. Можно сказать, что TDC Expert оперирует скорее с записями, чем с объектами.
Самый богатый спектр выполняемых конструкций для пред¬ставления знаний предлагается в системе G2. Разработчик мо¬жет использовать как продукционные правила, так и процедуры и командный язык.
Правила в системе G2 могут быть обобщенными, касающи-мися целого класса объектов, и специфическими, относящими-ся к конкретным экземплярам. Консеквент правила может содер¬жать условные выражения и директивы, указывающие порядок исполнения утверждения консеквента — последовательный или параллельный. Особенностью машины вывода G2 является и бо¬гатый набор способов активизации правил. Правило в G2 может активизироваться в одном из 9 случаев:
данные, входящие в антецедент правила, изменились (пря-мой вывод — forward chaining);
правило определяет значение переменной, которое требу-ется другому правилу или процедуре (обратный вывод — back-ward chaining);
каждые п секунд, где п — число, определенное для данного правила (scan);
явная и неявная активизация другим правилом — путем при¬менения операций фокусирования — focus или invoke;
переменной, входящей в антецедент, присвоено значение независимо от того, изменилось оно или нет; каждый раз при запуске приложения; определенный объект на экране перемещен пользователем или другим правилом;
определенное отношение между объектами установлено или уничтожено;
переменная не получила значения в результате к своему источнику данных.
Если первые два способа достаточно распространены и в ста¬тических экспертных системах, а третий хорошо известен как механизм запуска процедур- демонов, то остальные — уникаль¬ная особенность самой системы G2. Методы с 5-го по 9-й явля¬ются основой для обработки данных на базе управления событи¬ями. Особый интерес представляют операции фокусировки или концентрации внимания. Операция focus позволяет в определен¬ной момент работы приложения сконцентрироваться только на тех правилах, которые касаются определенного объекта, а опера¬ция invoke — на правилах определенной, заранее введенной пользователем категории, что резко повышает эффективность прикладной системы.
Несмотря на то, что продукционные правила обеспечивают достаточную гибкость для описания реакций системы на изме-нения окружающего мира, в некоторый случаях, когда нам не-обходимо выполнить жесткую последовательность действий, например запуск или остановку комплекса оборудования, более предпочтительным является процедурный подход. Язык програм¬мирования, используемый в G2 для представления процедурных знаний, — достаточно близкий родственник Паскаля. Кроме стан¬дартных управляющих конструкций этот язык расширен элемен¬тами, учитывающими работу процедуры в реальном времени: ожидание наступления событий, разрешение другим задачам пре¬рывать выполнение данной процедуры, директивы, задающие последовательное или параллельное выполнение операторов. Еще одна интересная особенность языка — итераторы, позволяющие организовать цикл над множеством экземпляров класса. Перечис¬ленные свойства языка позволяют системе одновременно выпол¬нять множество различных процедур или нескольких копий од¬ной и той же процедуры для различных объектов.
Система RTworks вообще не обладает возможностью опи-сывать процедурные знания; для написания процедур пользова-телю предлагается разрабатывать их на языке Си и подключать в качестве внешних программных модулей (в системе G2 такая возможность тоже предусмотрена).
Мощность языковых конструкций для представления про-дукционных правил и число способов их возбуждения в RTworks также гораздо слабее, чем в G2. В RTworks используются только механизмы построения прямой и обратной цепочек рассужде¬ния и сканирования правил.
Работа TDC Expert основана не на системе продукций, а на дереве решений. Поэтому разрабатываемые приложения покры-вают гораздо более узкий круг задач, чем в G2 или RTworks. Правил в привычном смысле в TDC Expert не существует. Пользо¬ватель описывает конкретные ситуации (узлы дерева решений) и рекомендации оператору для них.
Рассмотрим среду разработки.
Развитая система встроенных текстовых и графических ре-дакторов системы G2 и средств визуализации знаний прибли-жает ее по возможностям к современным CASE-средствам. Уп-рощение взаимодействия разработчика с системой достигается за счет оригинального подхода, реализованного в текстовом ре-дакторе. Процесс редактирования все время направляется про-цедурой грамматического разбора, что гарантирует введение только синтаксически правильных конструкций языка. В окне редактирования появляется динамически изменяемая подсказ¬ка, указывающая, какие языковые конструкции пользователь может вводить, начиная с текущей позиции курсора. Разработ-чик может набирать вводимый текст на клавиатуре или выби-рать подходящие шаблоны из подсказки. При редактировании доступны клавиатурные команды и контекстнозависимое меню операций редактирования.
Система RTworks не обладает встроенными средствами ре-дактирования базы знаний. Приложение должно быть сначала записано в виде ASCII-файла и затем подвергнуто грамматиче-скому разбору средствами RTworks. Фирма Talarian представляет такой подход как возможность пользоваться "вашим любимым текстовым редактором". Очевидно, что отсутствие интерактив¬ных средств разработки увеличивает стоимость и продолжитель¬ность этапа создания приложения.
Создание приложения в TDC Expert заключается в заполне-нии таблиц, представляющих перечень атрибутов используемых объектов.
Сравним интерфейс с конечным пользователем.
RTworks не обладает собственными средствами для отобра-жения текущего состояния управляемого процесса. Разработчик приложения вынужден использовать систему Dataview фирмы VI Corporation, что в значительной степени ограничивает его возможности.
Интерфейс с пользователем TDC Expert ограничен возмож-ностями системы TDC 3000. То есть взаимодействие с конечным пользователем не выходит за рамки текстового режима работы.
Система G2 представляет разработчику богатый выбор спо-собов формирования простого, ясного и выразительного гра-фического интерфейса пользователя с элементами анимации. Предлагаемый инструментарий позволяет наглядно отображать технологические процессы практически неограниченной слож-ности на разных уровнях абстракции и детализации. Кроме того, графическое отображение взаимосвязей между объектами при¬ложения может напрямую использоваться в декларативных кон¬струкциях языка описания знаний.
Система RTworks базируется на возможностях операцион-ной системы Unix для организации распределенной обработки.
Приложения на базе RTworks имеют модульную структуру, вклю¬чающую в себя следующие процессы: коммуникационный сервер (Rtserver); подсистему получения данных (Rtdag); подсистему логического вывода (Rtie); человеко-машинный интерфейс (Rthci). Наличие интерфейса с внешними процедурами, написан-ными на Си, и использование среды Unix для поддержки рас¬пределенной обработки обеспечивает открытость системы RTworks.
К сожалению, распределенная архитектура RTworks доро¬го обходится разработчику. Во-первых, если заключение ма¬шины вывода отображается процессом Rthci, это должно быть специфицировано специальной командой машины вывода. Не-достаточно просто изменить значение в базе знаний, разработ-чик обязан еще указать имя переменной в Rthci и послать из-мененное значение коммуникационному серверу, который передаст его процессу Rthci. Во-вторых, разработка интерфей¬са Rthci, базы разделяемых данных и базы знаний, отличаю¬щихся друг от друга, требует от разработчика знания трех раз¬личных программных интерфейсов. В-третьих, эти различные среды разработки часто требуют избыточных описаний. Напри¬мер, каждая переменная Rthci должна быть описана как в сре¬де разработки Rthci, так и в спецификации базы разделяемых данных. На разработчика возлагается ответственность за то, чтобы оба описания были идентичны и при внесении измене-ний перекомпиляции были подвергнуты оба модуля. Чтобы за-дача стала еще более трудной, перечень описаний в базе разде-ляемых данных хранится в алфавитном порядке, а в Rthci — в порядке ввода. Недостатком RTworks является и односторон¬няя передача данных через процесс Rtdag. Невозможность по¬слать через Rtdag запрос на получение данных делает задачу верификации показаний и диагностики неисправности датчи-ков практически неразрешимой.
G2 предоставляет разработчику гораздо более гибкие и мощ¬ные средства для формирования распределенных приложений на базе архитектуры клиент-сервер. В зависимости от требований конкретной задачи вы можете построить систему как содруже- ство автономных интеллектуальных агентов на базе интерфейса G2-G2. При этом обмен данными осуществляется на уровне пе¬ременных через протокол ICP(Intellgint Communication Protocol). Для организации обмена вам необходимо в описании перемен¬ной, получающей значение от другого G2-npoueccopa, просто указать номер сетевого порта источника. Кроме того, вы можете разрабатывать приложение как иерархическую систему. Для это¬го фирмой Gensym разработана клиентная система Telewindows, обеспечивающая множественный доступ к централизованной базе знаний и групповую работу с приложением.
Связь с внешними источниками данных строится на основе библиотеки стандартных интерфейсов и сервера GSI (G2 Standart Interface). Подсистема GSI работает параллельно с прикладной системой как независимый обработчик событий и обеспечивает ее двустороннее (в отличие от RTworks) взаимодействие с ши¬роким спектром программируемых контроллеров ведущих фирм (Allen Bradley, GE-Fanuc, AEG Modicon), систем сбора данных (ABB, Fisher, Siemens, Yokogawa, Foxboro, ORSI), концентра¬торов данных (Dec BASEstar, Allen Bradley Pyramid Integrator, Setpoint Setcim) и развитых СУБД (Oracle, Sybase, Dec Rdb). Библиотека GSI и так называемые G2 Bridge products позволяют легко интегрировать С2-приложение и существующие системы управления.
В системе TDC Expert специальных средств для распреде-ленной обработки не предусмотрено. Средства связи с управля-емым процессом обеспечиваются комплексом TDC 3000.
Остановимся на переносимости прикладных систем.
Больной вопрос для всех профессиональных программис-тов — переносимость разрабатываемых приложений — в рамках G2 решается элементарно просто. База знаний сохраняется в обычном ASCII-файле, который однозначно интерпретирует¬ся на любой из поддерживаемых платформ. Перенос приложе¬ния не требует его перекомпиляции и заключается в простом переписывании файлов БЗ. Функциональные возможности и вне¬шний вид приложения не претерпевают при этом никаких из¬менений.
Система RTworks также доступна на широком спектре Unix- платформ. Однако отсутствие поддержки Open VMS для рабочих станций фирмы DEC и Windows NT для систем на базе процес¬соров DEC Alpha и Intel ограничивает возможность переносимо¬сти RTworks-приложений по сравнению с G2-приложениями.
TDC Expert работает только на мини-ЭВМ семейства VAX под управлением операционной системы VMS. Мало того, ин-терфейс с устройствами сбора данных предусмотрен только для серии TDC 3000. Эти жесткие ограничения заставили фирму Honeywell использовать в своих разработках для систем управле¬ния (в том числе и на базе TDC 3000) оболочку экспертных систем реального времени G2 фирмы Gensym вместо собствен¬ной системы TDC Expert.
Из приведенного сравнения видно, что именно G2 целесо-образно брать за основу построения интеллектуальной надстройки к существующим системам сетевого управления, таким, как HP Open View или SunNet Manager. В свете изложенного далее речь будет идти преимущественно о G2 и продуктах ее семейства.
Продукты фирмы Gensym для сетевого управления — это не системы управления сетями в привычном понимании, поэтому с традиционными средствами они не конкурируют. Они пред¬ставляют собой скорее надстройки для повышения эффектив¬ности сетевого управления. Инструментальные средства фирмы Gensym широко используются ведущими фирмами, разработ¬чиками прикладных систем управления телекоммуникационны¬ми сетями, такими, как Stanford Telecom, AT & Т, Intelsat.
Еще раз кратко подчеркнем достоинства продуктов Gensym в данной предметной области:
единый интуитивно понятный пользовательский интерфейс для всех продуктов, позволяющий значительно сократить затра¬ты на обучение операторов;
использование парадигмы объектно-ориентированного про¬граммирования;
полная открытость, расширяемость и настраиваемое^, облегчающая модификацию программного обеспечения и под-гонку системы под конкретные условия организации;
возможность выступать в роли клиента, сервера или интел-лектуального агента по отношению к любой из традиционных систем в зависимости от архитектуры приложения;
полная поддержка средств работы в реальном времени;
визуальное программирование, повышающее удобство ра-боты с системой;
встроенные средства идентификации и разграничения прав пользователей как при входе в систему через клиентское прило-жение Tele windows, так и при работе с ней;
наличие средств доступа к С2-приложениям из WWW через WebLink-специальный продукт Gensym для работы с Internet, что снижает требования к аппаратному обеспечению клиент-ского места и в то же время упрощает работу с системой;
инкрементная компиляция, позволяющая модифицировать код даже в процессе выполнения приложения.
Для облегчения разработки собственных интеллектуальных систем сетевого управления или надстроек над существующими фирма Gensym создала Fault Expert — специализированную ин¬струментальную среду для работы с сетями. Внедрение Fault Expert совместно с G2 обеспечивает более высокую скорость реагиро¬вания на возникающие проблемы и более высокую надежность системы. Fault Expert имеет возможность обнаруживать, обоб¬щать и ранжировать по приоритетам неполадки в работе сети, что приводит в конечном счете к повышению производительно¬сти работы оператора. Так как G2 и Fault Expert просты в обра¬щении, требования, предъявляемые к квалификации операто¬ра, снижаются.
Fault Expert позволяет эффективно реагировать на сигналы о сбоях, поступающие от того или иного сетевого оборудова-ния, уменьшая таким образом время простоя в сети и повышая качество обслуживания клиента. Средства управления сообще-ниями и сигналами тревоги включают в себя:
установление взаимосвязей между сообщениями, фильтра-цию сообщений и индикацию наиболее важных из них;
моделирование причин неисправностей для разделения ис-ходных и косвенных сигналов тревоги;
архивирование потоков сигналов и сообщений для анализа и предсказания возможных неисправностей.
Графический язык для описания процедур тестирования из сетевых протоколов прикладного уровня позволяет изображать в виде блок-схемы последовательность шагов, графически по-казывающих процесс выполнения сетевых процедур. Даже пользователи, не имеющие технических навыков, способны выполнять тесты устройств и устранять проблемы.
Перечисленные возможности — это только базовые функ-ции, встроенные в Fault Expert. Кроме них разработчику прило-жений полностью доступны все средства и механизмы, имею-щиеся в G2 и позволяющие добавлять в приложение любую требуемую функциональность, например планирование, разви-тие существующих корпоративных сетей с учетом научно-тех-нического прогресса, моделирование сетей на предмет выявле-ния потенциально узких мест в их работе и т. п.
Fault Expert унаследовала преимущества всех существующих мостов между G2 и внешними программами , Разработчику доступ¬ны готовые высокопроизводительные интерфейсы с такими база¬ми данных, как Oracle, Sybase, Informix. Есть интерфейсы для рас¬пространенных сетевых менеджеров. Эти интерфейсы поддерживают SNMP-протокол и службы управления событиями. Кроме того, имеются средства сопряжения для множества других систем. Данные возможности позволяют легко интегрировать решение на базе G2/Fault Expert с уже существующими на предприятии платформа¬ми сетевого управления, добавляя к ним дополнительные функции.
В последнее время в системах управления стали использо-вать в качестве регуляторов динамическими объектами такие со¬временные программные средства, как нейронные сети и среды типа A-life.
Свойства нейронных сетей были рассмотрены ранее, крат-ко повторим основные положения. Искусственные нейронные сети [43] могут рассматриваться как упрощенная математиче-ская модель человеческого мозга, функционирующая как па-раллельная распределенная вычислительная сеть. Однако, в от-личие от большинства обычных программ, нейронная сеть может быть обучена. Она может сама организовываться и обу-чаться с целью выполнения требуемых функций.
Обрабатывающий информацию элемент (узел) сети можно представить, как элементарное устройство, содержащее локаль-ную память и функцию преобразования. Локальная память со-держит веса связей w., соответствующие входным сигналам х., порог срабатывания элемента и, возможно, еще какие-либо параметры данного узла.
Нейронные сети организуют свои элементы в подмноже-ства, называемые слоями, в которых элементы осуществляют одну и ту же функцию преобразования. Слои могут иметь любую топологию связей.
Возможны несколько типов классификации существующих нейросетей.
По типу входной информации:
сети, анализирующие двоичную информацию (сети Холфил- да, Хеминга),
сети, анализирующие информацию в форме действитель-ных чисел (сети Гроссберга, Кохонена, ART-системы).
По методу обучения:
сети, которые для удовлетворения поставленным критери-ям требуют предварительного обучения перед включением их в реальную обстановку — модели с учителем (backpropagation),
сети, не требующие предварительного обучения, способ¬ные самообучаться (совершенствовать свои характеристики) в процессе работы, модели без учителя (сети Гроссберга, Кохо-нена).
По характеру распространения в сетях информации:
однонаправленные сети, в которых информация распро-страняется только в одном направлении от одного слоя элемен-тов к другому,
рекуррентные сети, в которых выходной сигнал элемента может вновь поступать на этот элемент и другие элементы сети этого же или предыдущих слоев в качестве входного сигнала.
Существуют различные правила обучения нейросетей, из которых наиболее часто используются синхронное, оптимизи-рующее, конкурентное обучение, "filter " и пространственно- временное. Целью всех типов обучения является определение весовой матрицы сети, позволяющей удовлетворять поставлен-ным перед функционирующей сетью критериям.
Самооптимизация позволяет нейросетям "конструировать" самих себя. При этом системный разработчик вначале определя¬ет архитектуру нейросети и способ соединения ее с другими частями системы и выбирает метод обучения сети. Затем нейро- сеть адаптируется к данному приложению. Причем адаптивность позволяет нейросети успешно функционировать даже тогда, когда окружение, в котором работает объект, изменяется с течением времени. Полученную на основе нейросети систему путем неко¬торой подстройки (изменением числа нейронов в слое и числа слоев) можно использовать для решения широкого круга задач, что может сократить время новой разработки.
Для того чтобы система могла решать неполностью опреде-ленные задачи (когнитивность познания) так же, как это спо-собен делать человек, можно инкорпорировать концепцию не-четкой логики в нейронные сети. Тогда получаются так называемые гибридные системы, которые еще называют нейро- фаззисистемами или фаззи-нейросетями [16]. Гибридные систе-мы сочетают достоинства нечетких систем с нейросетями, обес-печивая механизм вывода с учетом нечеткости познавательного процесса и возможностью обучаемости, адаптируемости и па-раллельности вычислений.
Существуют три основные модели функционирования ней - ро-фаззисистем:
в ответ на какое-либо лингвистическое утверждение нечет-кий интерфейсный блок генерирует входной вектор для много-слойной нейронной сети, которая может быть адаптирована (обу¬чена) для выработки на выходе требуемых решений или команд, многослойная нейросеть управляется с помощью нечеткого механизма вывода,
гибридная модель, содержащая и нечеткий интерфейсный блок и нечеткий управляющий механизм вывода.
В artificial life (AL — искусственная жизнь) нет жесткого за-дания реакции внешнего мира, сужающего область применения генетических алгоритмов (GA). AL — это обобщающий метод построения динамических моделей, базирующийся на генети-ческих алгоритмах, методах теории хаоса, системной динамики и др.[10, 11]. Один из главных аппаратов, на который опирается AL, —- это GA.
Самое общее определение AL дает журнал «Midrange Systems», трактуя AL как "компьютерное моделирование живых объектов". Однако на практике к AL принято относить компью¬терные модели, обладающие рядом конкретных особенностей.
Во-первых, центральная модель системы должна обладать способностью адаптироваться к условиям внешнего мира, ния процесс обучения представляет собой решение задачи оптимизации, целью которой является минимизация функции ошибки (или невязки) на данном множестве примеров путем выборки коэффициентов межнейронных связей. Рассмотренный пример обучения называют контролируемым обучением, или обучением с учителем. В рабочем режиме блок обучения, как правило, отключен, и на вход НК подаются сигналы, требующие распознавания (отнесения к тому или иному классу). На эти сигналы (входные образы), как правило, наложен шум. Обученная нейронная сеть фильтрует шум и относит образ к нужному классу.
НК отличается от машины фон Неймана также по принципу взаимодействия структуры машины и решаемой задачи. Для однопроцессорных машин, с их "жесткой" структурой, разработчику приходится подстраивать алгоритм решения задачи под структуру машины. При использовании НК разработчик подстраивает структуру машины под решаемую задачу.
Использование НК для решения задач управления требует проведения ряда предварительных процедур, связанных с кодированием входной и выходной информации, выбором архитектуры НС, алгоритмов обучения, способов оценки и интерпретации получаемых результатов и т.д., т.е. настройки НК на конкретную задачу управления.
Каждая прикладная задача, решаемая на НК, имеет определенные особенности в средствах обработки и представления данных, поэтому вначале необходимо выполнить априорный анализ объекта управления. Если этот этап будет исключен, то возможно получение неадекватных результатов на этапе эксплуатации НК. Технология априорного анализа предметной области и решаемой прикладной задачи при нейросетевом управлении отличается от традиционных методов и включает следующие действия: обобщение опыта и профессиональных знаний об объекте, получение предварительных рекомендаций от экспертов, изучение литературных источников и существующих прототипов, сбор данных и формирование обучающей выборки для нейросети.
В состав нейронного регулятора (HP) входят следующие основные блоки (рис. 4.2): менеджер (управляющий модуль),
Рис.
4.2. Структура нейронного регулятора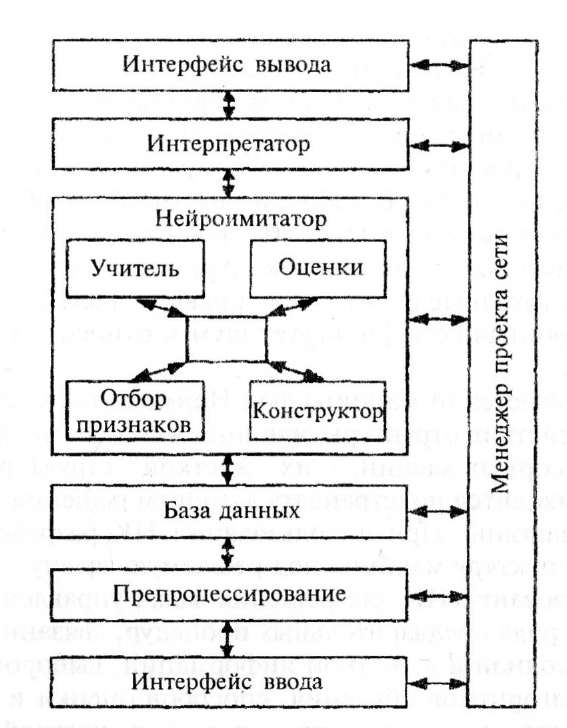
интерфейсы ввода и вывода, предобработчик (препроцессор), интерпретатор, нейроимитатор. В свою очередь, в нейроими- татор включает нейросеть (НС), учитель (при реализации стратегии обучения с учителем), конструктор, блок оценки и блок отбора информативных признаков. Основным компонентом нейроимитатора является искусственная НС.
Конструктор НС предназначен для формирования сети, со ответствующей модели предметной области. В связи с тем что отсутствует формальная процедура определения архитектуры НС (число слоев, число нейронов в каждом слое, вид связи между нейронами и т. д.), используются эвристические процедуры, которые основываются на предшествующем опыте работы с аналогичными нейросетевыми моделями предметной области. Если такой опыт отсутствует, выбор архитектуры выполняется путем перебора большого количества возможных вариантов построения НС.
Учитель, используемый в сетях с обучением, может иметь множество возможных реализаций. При выборе определенной стратегии обучения необходимо учитывать класс решаемых задач, планируемую точность и время получения результатов. Для каждого вида нейронных сетей разработаны различные алгоритмы обучения.
Блок отбора информативных признаков представляет собой надстройку над учителем и предназначен для определения минимально необходимого или "разумного" числа связей и нейронов сети. С помощью этого блока также удается уменьшить число градаций входной переменной. Наиболее важным следствием применения процедуры отбора (контрастирования) является получение логически прозрачных сетей, т. е. таюга сетей, функционирование которых можно описать и понять на языке логики.
Качество обучения НС определяется оценкой (ошибкой обучения) на примерах из обучающей выборки, а эффективность решения конкретной задачи предметной области определяется оценкой (ошибкой обобщения) на тестовой (контрольной) выборке. Эти оценки вычисляются в блоке оценки. В случае, если указанные ошибки превышают заданные допустимые пределы, необходимо вернуться на предыдущие этапы построения ней- росетевой модели и изменить ее параметры.
Наиболее важным блоком НР является база данных, содержащая примеры для обучения и контроля функционирования НС. Важность этого блока определяется тем, что обучение сетей всех видов с использованием любых алгоритмов обучения выполняется на известных примерах решения поставленной задачи. Кроме того, база данных содержит правильные ответы для НС, обучаемых с учителем. Очевидно, невозможно предусмотреть все варианты интерфейса между пользователем и базой данных, так как примеры могут иметь числовые поля, содержать графическую информацию или представлять собой текст. Наиболее подходящим форматом представления входной информации является формат табличных (реляционных) баз данных.
Сигналы, подаваемые на вход НС, должны быть представлены в соответствующем формате данных, при этом очень часто фиходится их масштабировать, чтобы в максимальной степени 1Спользоватьдиапазон их изменения. Поэтому необходимо про- юдить предобработку (препроцессирование) входных сигналов, тричем для каждого вида должен быть реализован определен- 1ый способ предобработки.
Формат ответов НС в явном виде часто оказывается непонятным для интерпретации человеком получаемых результатов. Ответ, выдаваемый НС, как правило, является вещественным числовым вектором. Если при решении какой-то прикладной задачи требуется получить ответ, например в градусах по шкале Кельвина или в дюймах, то необходимо преобразование выходного вектора. Представление ответа НС при решении задач классификации, когда необходимо для каждого входного вектора определить принадлежность его определенному классу, также вызывает определенные трудности. Эта задача может быть решена следующим образом. Пусть имеется К классов. Каждому выходному нейрону НС поставим в соответствие номер класса. При подаче на вход обученной НС некоторого входного вектора на ее выходе будет получен вектор, состоящий из К сигналов. Единого универсального правила интерпретации этого вектора не существует. Наиболее часто используют оценку по максимуму: номер нейрона, выдавшего максимальный по величине сигнал, является номером класса, к которому относится предъявленный сети вектор, Интерпретатор напрямую взаимодействует с пользователем через интерфейс вывода, следовательно, от качества его организации зависит эффективность работы HK.
Управление операциями подготовки входных данных, обучения, тестирования НС, интерпретации выходныхданных ocy- шествляется менеджером проекта сети.
Современный уровень развития теории и практики НС, а также достижения схемотехники и микроэлектроники позволяют создавать различные по принципу построения нейронные регуляторы. При практической реализации базового элемента НР — формального нейрона, его отдельных компонентов, соединение нейронов по слоям в сеть, обучение сети разработчик может выбрать одно из трех принципиально отличающихся направлений:
программное — все элементы НР реализуются программно на универсальных ЭВМ с архитектурой фон Неймана;
аппаратно-программное — часть элементов реализуется аппарагно, а часть — программно;
аппаратное — все элементы НР выполнены на аппаратном уровне, кроме специфических программ формирования синап- тических коэффициентов.
Сегодня существует множество реализаций для каждого из этих направлений. Программные системы, реализующие первое направление, даже если для них требуется многопроцессорная или многомашинная аппаратная поддержка, получили название нейроэмуляторы или нейроимитаторы.
Второе и третье направления аппарагно реализуются на заказных кристаллах (3K-ASIC), встраиваемых микроконтроллерах (МК-цС), процессорах общего назначения (GPP), программируемых логических интегральных схемах (ПЛИС-FPGA), транспьютерах, цифровых сигнальных процессорах (ЦСП-DSP), нейрочипах (НЧ), оптических и оптико-электронных нейронах (ОН и ОЭН), логических элементах (ОЛЭ и ОЭЛЭ) и волоконно-оптических и оптико-электронных линиях связи (ВОЛС и ОЭЛС) и информационных каналах (ВОИК и ОЭИК). Имеется много примеров практической реализации НК на различной элементной базе, однако все больше ученых и разработчиков отдают предпочтение ЦСП, ПЛИС, нейрочипам и ОЭИК.
Следует отметить, что второе направление характерно тем, что аппаратная часть нейровычислительного модуля выполняется в виде платы расширения для универсальной ЭВМ, имеющей, как правило, архитектуру фон Неймана. В таких платах ап- паратно, например, может выполняться операция взвешенного суммирования, а операция нелинейного преобразования — про- граммно-базовой ЭВМ. Такие платы расширения получили название нейроускорители.
Если вычислитель спроектирован по архитектуре, представленной на рис. 4.1, то его основной операционный блок выполняет все операции в нейросетевом базисе, а в запоминающем устройстве хранится не программа решения конкретной задачи, а программа формирования синаптических коэффициентов. Если его блок обучения на аппаратном или программном уровне реализует конкретный алгоритм обучения НС, то такой вычислитель следует отнести к собственно HK.
Рассмотрим некоторые вопросы применения для построения нейровычислителей второго и третьего направлений ПЛИС., ЦСП, НЧ, ОН, ОЭН, ОЛЭ и оэлэ.
Особенности ПЛИС как элементной базы НК рассмотрим на примере ПЛИС фирмы XILINX типа FPGA (Field Programmable Gate Array). ПЛИС XILINX (в дальнейшем просто ПЛИС) представляет собой массив конфигурируемых логических блоков (КЛБ) с полностью конфигурируемыми высокоскоростными межсоединениями. Нарис. 4.3 представлена обобщенная структурная схема ПЛИС XILINX серии XC4000. Весь массив КБЛ и конфигурируемые межсоединения расположены на кристалле. По периферии кристалла расположены блоки ввода-вывода, из которых каждый включает два триггера: один для ввода, другой для вывода информации. Кроме того, сюда включена логика дешифрации и цепи контроля высокоомных состояний.
Рис.
4.3. Обобщенная структура ПЛИС XILINX
серии
XC4000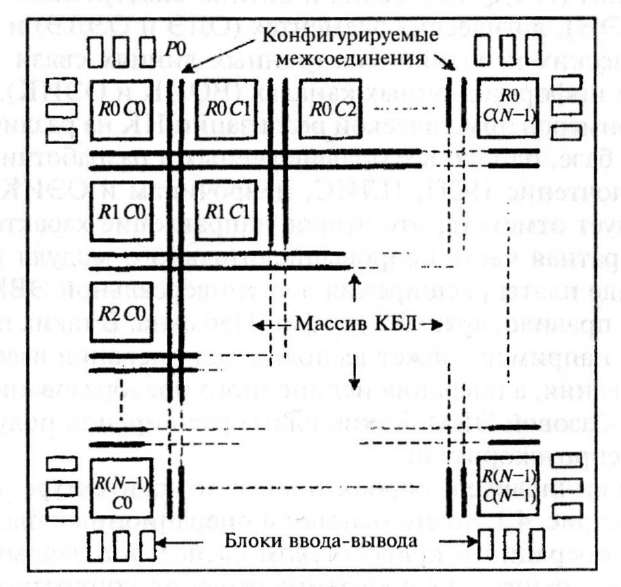
На рис. 4.4 приведена упрощенная структура КБЛ ПЛИС серии XC4000/Spartan. Каждый КБЛ состоит из следующих устройств: двух просмотровых таблиц XILINX 16x1 — LUT-таблиц (Look Up Table), двух блоков логики ускоренного переноса, двух триггеров. Время распространения сигналов через устройства КБЛ составляет: через LUT-таблицу — около 0,5 нс, через блок ускоренного переноса — 0,1 нс, время переключения триггеров — не более 0,5 нс.
Внутренние межсоединения ПЛИС конфигурируются пользователем и дают задержку по кристаллу между двумя произвольными точками не более 5 нс.
На одном КБЛ ПЛИС можно реализовать полный двухразрядный сумматор. Каскадное соединение двухразрядных сумматоров позволяет построить сумматор 16-разрядных чисел. Время суммирования двух 16-разрядных чисел составит 5 нс при тактовой частоте 200 МГц. Кроме того, каждый КЛБ ПЛИС серии XC4000 можно конфигурировать в виде блока высокоскоростного синхронного ОЗУ 3281 или двух блоков ОЗУ 1681, или двухпортового ОЗУ 1681, что позволяет совместно с имеющимся блочным ОЗУ строить мощные высокопроизводительные системы.
Рис.
4.4. Упрощенная структура КБЛ ПЛИС серии
XC4000/Spartan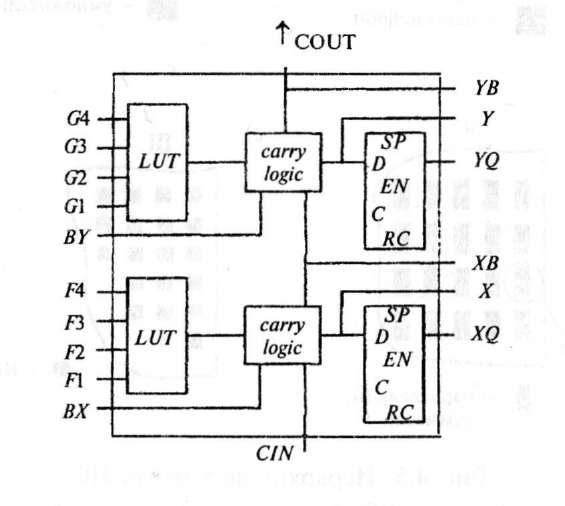
Из рис. 4.3 видно, что ПЛИС имеет матричную структуру. Элементарной ячейкой матрицы является КБЛ. Такое построение кристалла ПЛИС позволяет организовывать иерархические структуры НС. На низшем иерархическом уровне таких структур стоит двухразрядный полный сумматор, построенный на базе КБЛ. Следующий уровень в иерархии занимает сумматор, например 16-разрядныхдвоичныхчисел. На базе сумматоров строятся умножители. Далее, на более верхнем уровне иерархии, стоит отдельный нейрон, а из нейронов строят фрагменты НС. На рис. 4.5 показан принцип иерархического фрагмента НС.
Рис.
4.5. Иерархия фрагмента НС: а — фрагмент
НС; б — топология одного нейрона; в
— топология одного умножителя;
г —
топология параллельного сумматора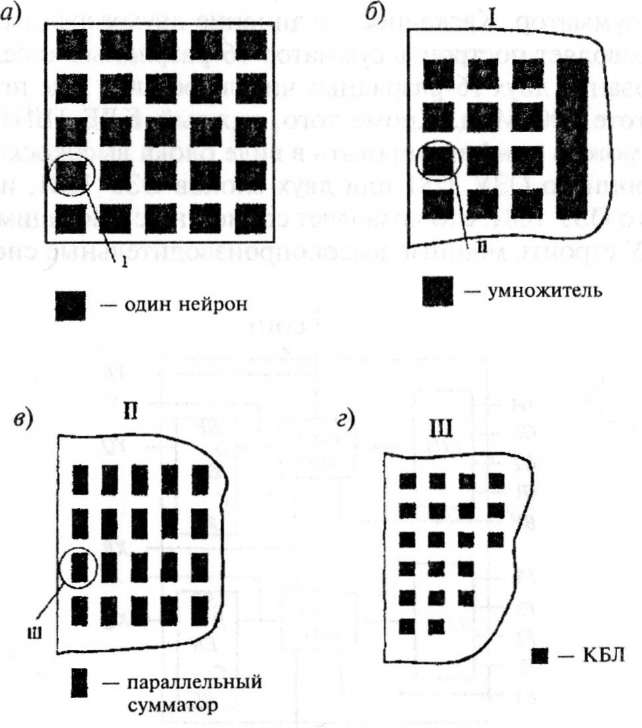
Фирмой "Scan Engineering Telecom" на основе элементарного массива КБЛ разработана библиотека простейших арифметических блоков, таких, например, как сумматоры, умножители, компараторы, некоторые виды нейронов. Это облегчает и ускоряет работу разработчика.
Многоуровневая конвейерная структура НС на базе ПЛИС серии XC4000 обеспечивает время вычисления одного нейрона 6 нс (для нейрона с 8-ю 8-разрядными входами). А поскольку в такой структуре все нейроны работают параллельно, то обработка в общем случае N-мерного входного вектора происходит также за 6 нс. Иерархическая структура по своей природе многотактовая. Поэтому выходной К-мерный отклик сети поступает на выход относительно входного с некоторой задержкой. В общем случае этот факт не снижает быстродействия сети, так как конвейер обеспечивает единый такт приема входной информации и выдачу выходной. Для рассматриваемой ПЛИС такт приема может быть равен 6 нс.
В нейронах фирмы "Scan Engineering Telecom "входной вектор может иметь размерность от 2 до 16. Соответственно в этом диапазоне изменяется и число синаптических коэффициентов. Разрядность входных данных и разрядность коэффициентов может меняться независимо по каждой координате от 1 до 16. Разрядность внутренних данных (выходные данные умножителей и дерева сумматоров), как правило, устанавливается равной разрядности входных данных, хотя при необходимости разработчик может ею варьировать. Наиболее просто в рассматриваемой ПЛИС могут быть реализованы функции активации либо в виде операции вычисления знака взвешенной суммы, либо в виде операции сравнения с загружаемым порогом (аппаратный компаратор).
В настоящее время фирмой "Scan Engineering Telecom" разработано пять подходов реализации нейрона, отличающихся быстродействием и аппаратными затратами:
наибольшее быстродействие, значительные аппаратные ресурсы, загрузка весовых коэффициентов (обучение) в реальном масштабе времени;
среднее быстродействие, малые аппаратные ресурсы, загрузка весовых коэффициентов в реальном масштабе времен;
высокое быстродействие, средние аппаратные ресурсы, загрузка весовых коэффициентов не в реальном масштабе времени;
среднее быстродействие, малые аппаратные ресурсы, загрузка весовых коэффициентов не в реальном масштабе времени;
среднее быстродействие, чрезвычайно малые аппаратные ресурсы, загрузка весовых коэффициентов не в реальном масштабе времени, однобитные высокоскоростные межсоединения.
В первом подходе используются восемь конвейерных умножителей 8x8 бит в дополнительном коде, выполненных по алгоритму Бута, свертывающееся дерево сумматоров и компаратор с загружаемым 8-разрядным порогом.
Реализация нейрона во втором подходе осуществляется с использованием восьми параллельно-последовательных 8-раз- рядных умножителей, 16-разрядного аккумулятора частичных произведений с временным мультиплексированием, использующих внутренние буферные регистры с тремя устойчивыми состояниями. Компаратор с загружаемым пороговым значением аналогичен используемому в предыдущем подходе. Синхронные элементы схемы функционируют на частоте 80 МГц, в то время как период загрузки новых данных и соответственно времени активизации нейрона составляет 100 нс (100 МГц). Смена значений 8-разрядных весовых коэффициентов и пороговой функции может осуществляться также с периодом 100 нс.
Следующие три подхода используют принципы распределенной арифметики, что позволяет экономить аппаратные ресурсы, сохраняя быстродействие, соизмеримое с реализациями традиционных методов. Применение параллельной распределенной арифметики (PDA — Parallel Distributed Arithmetic) в третьем подходе позволяет более чем вдвое сократить аппаратную реализацию, сохраняя высокое быстродействие. Период полного обновления всех 8-разрядных весовых коэффициентов нейрона в этом случае составит 160 нс. Применениедля четвертого подхода последовательной распределенной арифметики (SDA — Serial Distributed Arithmetic) дает еще больший выигрыш в экономии аппаратных ресурсов. В таком случае на один нейрон потребуется 85 КБЛ, что составляет 3 % от возможностей ПЛИС XC4085XLA, а общее число нейронов, которое возможно реализовать на кристалле, составит 30. Рабочая частота нейронов равна 10 МГц, тактовая частота работы синхронных элементов нейрона — 90 МГц, время полного обновления весовых коэффициентов составляет 160 нс.
Наибольшую экономию аппаратных ресурсов обеспечивает реализация нейрона на последовательно-последовательной распределенной арифметике. При этом соответствующие нейроны связаны однобитными высокоскоростными потоками, а загрузка коэффициентов осуществляется параллельно.
На рис. 4.6 приведена обобщенная структурная схема НС на ПЛИС XILINX. Основой вычислителя является матрица из ПЛИС 1-4, связанных максимально возможным числом межсоединений. Размерность матрицы определяется разработчиком и в общем случае не имеет ограничений. В каждом столбце матрицы из ПЛИС размешаются от одного до нескольких слоев НС. Наращивание числа строк в матрице эквивалентно увеличению размерности входного и выходного векторов.
Входной демультиплексор и выходной мультиплексор размещаются непосредственно в ПЛИС крайних столбцов и предназначены для ввода-вывода данных на стандартный интерфейс (системную шину).
Управляющий контроллер служит для общей синхронизации работы сети, организации процесса обучения и загрузки весовых коэффициентов. Он связан с контроллером стандартного интерфейса (PCI, VME) и имеет специфический набор команд, необходимых и задаваемых разработчиком. Через стандартный интерфейс осуществляется связь сети с достаточно медленными по сравнению с возможностями межсоединений ПЛИС периферийными устройствами, например персональным компьютером, где осуществляется визуализация и частичная обработка передаваемой и принимаемой из сети информации.
Разработчики ПЛИС Л7£/Л^Хпредусмотрели возможность каскадирования матрицы, что позволяет конструировать сети более высокой размерности. Каскадирование осуществляется с использованием корпусов BG560 (серия Virtex), имеющих514 пользовательских выводов, позволяющих осуществлять двунаправленный
Рис.
4.6. Обобщенная структурная схема
нейронной сети на ПЛИС
XILINX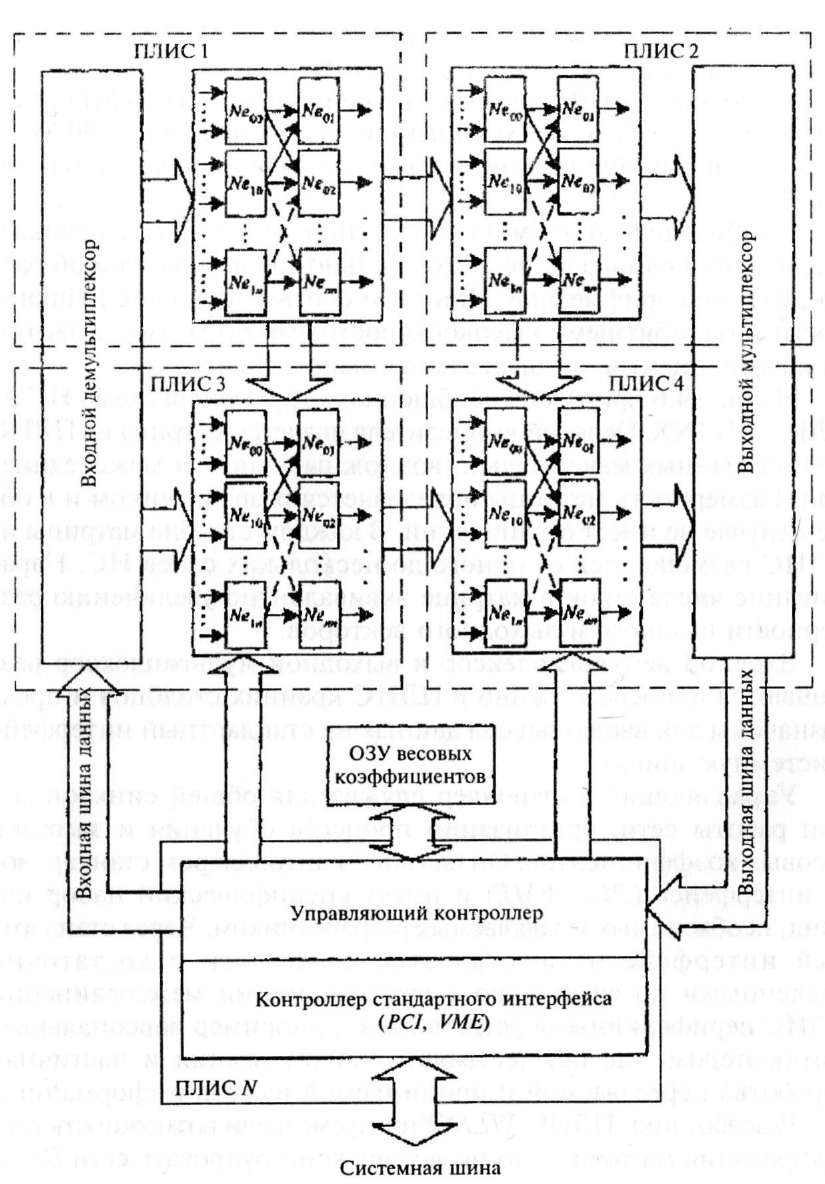
ввод-вывод данных с пропускной способностью 103Гбит/с. Наращивание осуществляется через горизонтальные (ПЛИС 1 и ПЛИС 2, ПЛИС 3 и ПЛИС 4 на рис. 4.6) и вертикальные (ПЛИС 1 и ПЛИС 3, ПЛИС 2 и ПЛИС 4 на рис. 4.6) шины. Пропускная способность ограничивается лишь пропускной способностью физических межсоединений. Поэтому последние целесообразно выполнять волоконно-оптическими.
Фирмой "Scan Engineering Telecom" предложен следующий вариант реализации аппаратно-программного направления конструирования нейровычислителей на нейросетевой платформе XNeuro-1.0, структурная схема которой приведена на рис. 4.7. На основе обрабатывающих модулей XDSP-680 и XDSP-4M составляется матрица ПЛИС, подобно приведенной на рис. 4.6. Модули объединяются двумя путями: через стандартный интерфейс — для осуществления управляющих и обучающих функций, и высокоскоростными прямыми портами межслойных и внутрислойных связей. В качестве управляющего контроллера можно использовать универсальный процессор Pentium. Модули, выполненные
Рис.
4.7. Структурная схема системы XNeuro-1.0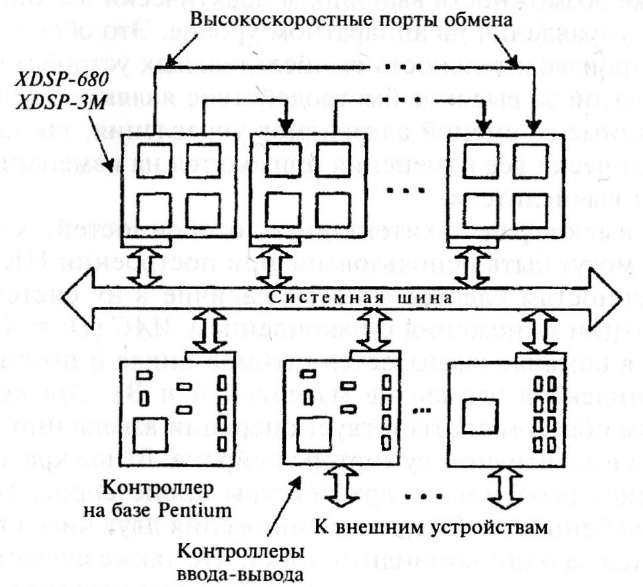
в соответствии со стандартом на шину PCI, поддерживают Plug&Play протокол PCI версии 2.1. Система Х№иго-1.0допуска- ет установку до 18 модулей типа XDS, имеет в резерве два слота для установки контроллера на Pentium и платы видеоадаптера.
Нейронная сеть, реализованная на базе XNeuro-1.0, имеет следующее число нейронов, рассмотренных выше (подход 4):
103000 для XDSP-680 с установленными ПЛИС XCV1000E;
7500 для XDSP-3M с установленными ПЛИС XCV2600E.
В самом конце семидесятых годов прошлого столетия появились цифровые сигнальные процессоры (ЦПС — DSP — Digital Signal Processor), что было обусловлено желанием разработчиков систем управления сложными динамическими объектами включать в свои проекты именно цифровые вычислительные устройства, обеспечивающие высокие точностные характеристики систем.
Важным преимуществом ЦПС как элементной базы нейро- вычислителей перед универсальными микропроцессорами является возможность работы на максимальных тактовых частотах, а также возможность выполнять практически все операции алгоритма управления на аппаратном уровне. Это обеспечивает высокую производительность вычислительных устройств на их основе. Платой за высокое быстродействие являются осложнения, связанные со сменой алгоритмов управления, так как при этом практически все изменения приходятся на изменения схемотехники вычислителя.
ЦПС имеют ряд архитектурных особенностей, которые с успехом могут быть использованы при построении HK. К таким особенностям следует отнести наличие в их системе команд операции умножения с накоплением MAC (D: = АВ + D. При этом в команде указывается глубина цикла и правило изменения индексов элементов массивов А и В). Эта команда наилучшим образом соответствует операции взвешенного суммирования в адаптивном сумматоре нейрона. Выше кратко рассматривались особенности архитектуры процессоров. Напомним эти особенности. Операция умножения двух чисел в ЦПС выполняется за один командный цикл, что также существенно повышает производительность вычислительного устройства. При выполнении арифметической операции необходимо осуществить выборкудвух операндов, собственно операцию и сохранить результат или удержать его до повторения. Если архитектура вычислительного устройства имеет одну шину данных, одновременно выполнить эти операции (за один такт) невозможно. Гарвардская архитектура (SHARC— Syper Harvard Architectur) предполагает наличие двух физически разделенных шин: одну для команд, вторую — для данных. Можно установить три раздельных шины — для двух операндов и для команды, что значительно повышают стоимость микросхемы. В компромиссном варианте применения лишьдвух шин в архитектуре процессора используется кэш-память, которая хранит те команды, которые будут вновь использоваться, оставляя свободными шины команд и данных. Гарвардская архитектура с кэшпамятью получила название расширенной гарвардской архитектуры. Многие ЦПС построены по гарвардской и расширенной Гарвардской архитектуре.
Перспективным является построение вычислительных устройств по новой архитектуре — TrigerSHARC, сочетающей в себе высокую степень конвейеризации и программируемость RISC- процессоров, SHARC-ядро, структуру памяти, особенности реализации интерфейса ввода/вывода ЦПС, параллелизм на уровне команд VLIW(Very Long Instruction Word)-apxHTeKTyp.
На рис. 4.8 приведена схема, поясняюшая принцип архитектуры TrigerSHARC.
Как видно из рисунка, в системе имеются два вычислительных блока Хи Y( ВБХи ВБУ ), каждый из которых имеет регистровый файл (РгФ). Объем РгФ составляет 32 слова по 32 разряда каждое. Вычислительный блок может выполнять все операции обычного арифметико-логического устройства (модуль ALU), однотактного умножения, включая умножение с накоплением (модуль MAQ, различные регистровые операции (сдвиги, инверсия и т. п., модуль Shift). Данные для работы модулей ALU, MAC, Shift выбираются из регистрового файла, туда же записываются результаты работы этих модулей. Большое число регистровой памяти способствует эффективному применению языков программирования высокого уровня.
Высокая внутренняя скорость передачи информации достигается применениемдвух 128-разрядных шин, связывающих
Рис.
4.8. Архитектура TrigerSHARC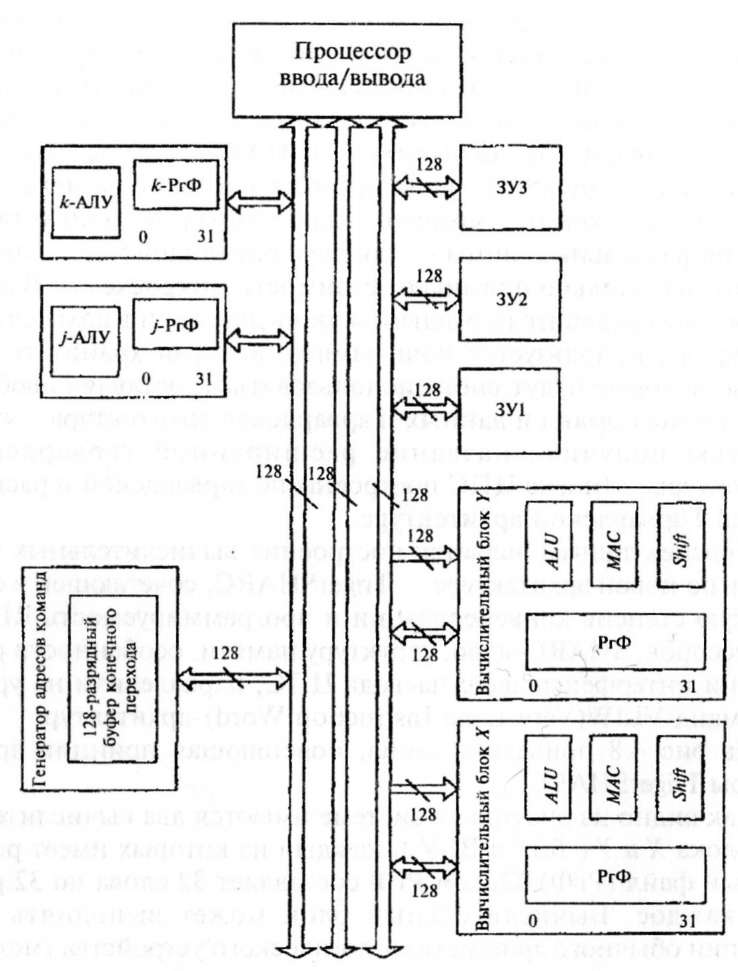
регистровый файл с тремя 128-разрядными системными шинами. Обе шины вычислительного блока позволяют одновременно выполнять операцию чтения из памяти (блоки ЗУ1, ЗУ2, ЗУЗ), а одна шина — операцию записи в память. Такая организация шин весьма эффективца для вычислительных систем, реализующих большое число математических операций.
Архитектура TrigerSHARC предполагает три независимых блока памяти (модули ЗУ1, ЗУ2, ЗУЗ). Каждый модуль имеет 128-разрядную шину данных. Адрес доступа к данным может состоять из одного, двух или четырех слов, что позволяет пользователю отказаться от традиционной сегментации памяти на память программ и память данных. Передача данных в память и из памяти может осуществляться одновременно двумя вычислительными блоками за один такт. Архитектура TrigerSHARC предусматривает наряду с внутренней памятью организацию и традиционной оперативной.
Генератор адресов команд определяет порядок и правильность их выполнения во всех модулях. Буфер конечного перехода (Branch Target Buffer) предсказывает переходы в программе и записывает адреса этих переходов. Объем буфера составляет 128 ячеек. Предсказание переходов с сохранением их адресов позволяет осуществлять эту операцию за один цикл вместо 3—6 в традиционной организации.
Объединение процессоров, выполненных по архитектуре TrigerSHARC, позволяет проектировать нейроускорители с обширными функциями.
Оценкой производительности ЦПС является число типовых операций (обычно миллионов операций) цифровой обработки сигналов в единицу времени. Ктаким типовым операциям относятся фильтрация, быстрое преобразование Фурье, преобразование Уолша и др. Для оценки производительности нейровы- числителей используют следующие показатели:
CUPS (connections update per second} — число изменений значений весов в секунду (оценка скорости обучения);
CPS (connections per<second) — число соединений в секунду;
CPSPW = CPS/Nw — число соединений на один синапс (здесь Nw — число синапсов в нейроне);
CPPS— число соединений примитивов в секунду, CPPS = CPU Bw Bs (здесь Bw — разрядность весов, Bs — разрядность синапсов);
ММАС— миллион умножений с накоплением в секунду.
Специализированную сверхбольшую интегральную схему, ориентированную на реализацию нейросетевых алгоритмов, принято называть нейрочипом (СБИС-нейрочип). Разработкой нейрочипов занимаются многие фирмы в различных странах. Значительный рост выпуска СБИС-нейрочипов наметился с середины 1990-х годов.
По принципу построения, по назначению и характеристикам они сильно отличаются друг от друга. На рис. 4.9 приведена схема классификация СБИС-нейрочипов.
По виду информационного носителя нейрочипы делятся на аналоговые, цифровые и гибридные.
Аналоговая элементная база характеризуется большим быстродействием и низкой стоимостью, что в значительной мере способствует ее производству. Самыми простыми являются СБИС с битовыми весовыми коэффициентами, которые, как правило,
Рис.
4.9. Схема классификации нейрочипов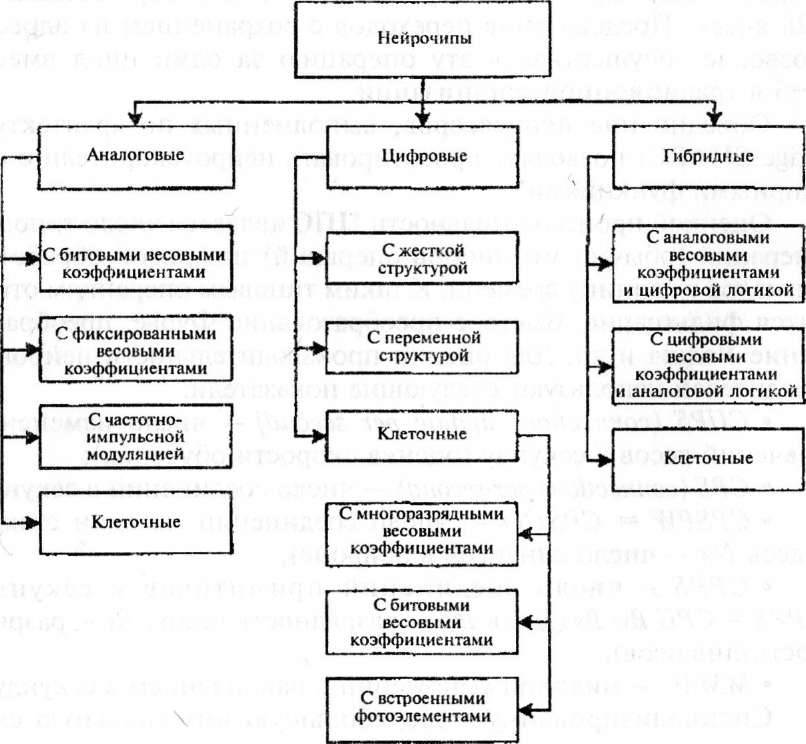
настраиваются, с фиксированными весовыми коэффициентами и полными последовательными связями. В аналоговой технике широко применяется частотно-импульсная модуляция. Аппаратура, использующая эту модуляцию, характеризуется низким энергопотреблением и высокой надежностью. Отметим, что в биологических НС сигналы представляются именно частотно- импульсной модуляцией. Очевидно, что эти факторы и способствовали появлению на рынке аналоговых СБИС-чипов с гакой модуляцией сигнала.
По способу реализации нейроалгоритмов различают нейро-чипы с полностью аппаратной и с программно-аппаратной реализацией (когда нейроалгоритмы хранятся в программируемом запоминающем устройстве).
Как видно из схемы классификации (см. рис. 4.9), нейрочи- пы бывают как с жесткой, так и с переменной структурой.
Отдельным классом выделяют нейросигнальные процессоры. Ядро этих СБИС представляет сигнальный процессор, а реализованные на кристалле специальные дополнительные модули обеспечивают выполнение нейросетевых алгоритмов. Таким дополнительным модулем, например, может быть векторный процессор.
Возможности микроэлектроники и запросы потребителей привели к созданию проблемно-ориентированного направления выпуска нейрочипов. Можно выделить следующие области их проблемной ориентации [42]:
обработка, сжатие и сегментация изображения;
обработка стереоизображений;
выделение движущихся целей на изображении;
обработка сигналов;
ассоциативная память.
Особое место в проблемной ориентации нейрочипов занимает ориентация на клеточную структуру. На такой структуре строятся резистивные решетки, нейрочипы с внутрикристаллической реализацией слоя фоторецепторов, так называемые ретины. Ретины используют в робототехнике, медицине (для вживления в глаз слепого человека) и других областях.
В настоящее время значительно возрос выпуск нейрочипов, структурные особенности которых определены совместной
работой биолога и схемотехника-электронщика. Такие чипы и вычислительные устройства на их основе предназначены для решения конкретных технических задач путем моделирования на аппаратном уровне функционирования тех или иных подсистем живых организмов.
В научно-техническом центре "Модуль" (Россия, Москва) разработан нейропроцессор J11879BM1 (NeuroMatrix 7VA/6403) [43]. Он представляет собой высокопроизводительный микропроцессор со статической суперскалярной архитектурой. Одним из назначений JI1879BM1 является аппаратная эмуляция разнообразных типов нейронных сетей.
JT1879BM1 предназначен для обработки 32-разрядных скалярных данных и данных программируемой разрядности, упакованных в 64-разрядные слова, которые в дальнейшем будут называться векторами упакованных данных. Структурная схема нейропроцессора JI1879BMl приведена на рис. 4.10.
Рис.
4.10. Структурная схема нейропроцессора
JI1879BM1
Основой нейрочипа является центральный процессор RfSC CORE. Он предназначен для выполнения арифметико-логических операций и операций сдвига над 32-разрядными скалярными данными, формирования 32-разрядных адресов команд и данных при обращении к внешней памяти и выполнения всех основных функций по управлению работой нейропроцессора.
Выборка команд из внешней памяти осуществляется 64-раз- рядными словами, каждое из которых представляет собой одну 64- или две 32-разрядные команды.
Нейропроцессор использует 32-разрядный вычисляемый адрес при обращении к внешней памяти. Доступное адресное пространство нейропроцессора равно 16 Гбайт. Оно делится на две равные части — локальное и глобальное. На рис. 4.11 показано распределение адресного пространства нейропроцессора.
Ядром нейропроцессора является блок RISC CORE (см. рис. 4.10). Он состоит из регистрового арифметико-логического устройства (РАЛУ — RALU), двух генераторов адресов данных {DAGl,DAG2), генератора адресов команд (Programm Seqimcer) и блока управления (Control Unit).
Нейропроцессор поддерживает одно внешнее прерывание и девять внутренних:
• два прерывания от таймера;
Рис.
4.11. Распределение адресного пространства
нейропроцессора Л1879ВМ1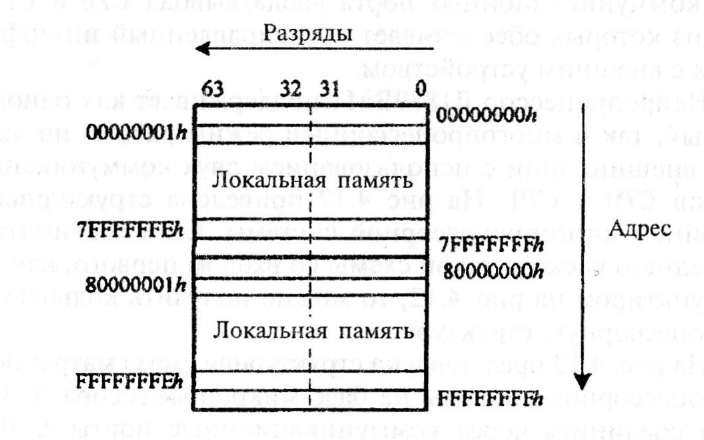
прерывание по переполнении при выполнении арифметических операций в RISC-ядре;
прерывание по запрещенной векторной команде;
четыре прерывания от каналов ввода/вывода но завершении обмена через коммуникационные порты;
пошаговое прерывание в режиме отладки.
Векторный сопроцессор VCP. Этот блок (см. рис. 4.10) ориентирован на обработку данных произвольной разрядности от 1 до 64, упакованных в 64-разрядное слово. Сопроцессор включает в себя следующие блоки:
OU — операционное устройство;
RCS— циклический сдвигатель вправо на один разряд;
SU1, SU2 — узлы аппаратной реализации функции насыщения;
FlCR, F2CR — регистры управления узлами насыщения;
SWITCH 3->2 — коммутатор 3 в 2;
WBUFvL WOPER — матрицы памяти весовых коэффициентов;
WFIFO-FIFO весовых коэффициентов;
AFIFO — накопительное FIFO;
RAM— векторный регистр;
VR — регистр порогов.
Нейропроцессор содержит два идентичных высокоскоростных коммуникационных порта ввода/вывода CP0 и CPl, каждый йз которых обеспечивает двунаправленный интерфейс для связи с внешним устройством.
Нейропроцессор JI1879BM1 поддерживает как однопроцессорный, так и многопроцессорный режим работы по любой из двух внешних шин с использованием двух коммуникационных портов CP0 и CPl. На рис.4.12 приведена структурная схема линейной" многопроцессорной системы. Если соединить выход последнего каскада такой схемы со входом первого, как показано пунктиром на рис. 4.12, то можно получить кольцевую многопроцессорную структуру.
На рис. 4.13 представлена структурная схема матричной многопроцессорной системы на базе микропроцессора JI1879BM1. Если соединить через коммуникационные порты СЮ и СР\ выходы крайнего правого столбца схемы со входами крайнего левого, то получится схема в виде вертикального цилиндра.
Рис.
4.12. Структурная схема линейной
многопроцессорной системы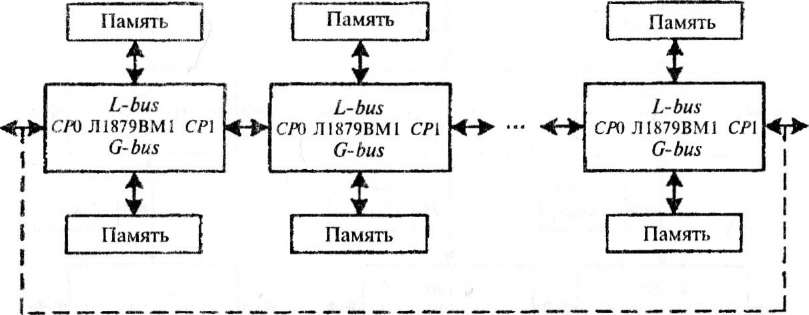
Очевидно, что схему горизонтального цилиндра можно получить, соединив по внешним шинам L-bns и G-bus входы/выходы крайних верхней и нижней линеек процессоров. Если соединить правые и левые входы/выходы у горизонтального цилиндра или верхние и нижние входы/выходы у вертикального цилиндра, то получим тороидальные многопроцессорные системы. При обмене информацией через общую память внешняя шина, соединяющая два нейропроцессора, должна быть локальной (L-bus) для одного из них и глобальной {G-bus) для другого. Скорость обмена информацией через порты CP0 и CPl составляет 20 Мбайт в секунду.
В нейропроцессоре применяются четыре основные группы команд: управления скалярные, управления векторные, пересылки, модификации адресных регистров. В каждой команде программист имеет возможность задать операцию обработки операндов. Команды имеют фиксированную длину 32 или 64 разряда. Все команды выполняются за один такт синхронизации.
В связи с бурным развитием в последнее время методов и средств оптоэлектронной обработки информации и созданием всевозможных устройств для применения в различных сферах науки и техники, представляет значительный интерес создание оптоэлектронных реализаций нейронных сетей, так как они могут иметь более высокое быстродействие и помехозащищенность.
Рис.
4.13. Структурная схема матричной
многопроцессорной системы
Рис.
4.14. Схемадефлекторного фаззификатора
Рассмотрим варианты реализации оптических и оптико-элек- тронных элементов НС.
Простейшая дефлекторная схема оптического фаззифика- тора показана на рис. 4.14.
Коллимированный луч света диаметром d от источника А отклоняется дефлектором F таким образом, что засвечивает, в зависимости от угла v(x), одно из отверстий маски М. Угол отклонения зеркала дефлектора v является функцией входной величины х. За маской устанавливаются либо фотоприемники, либо оптические элементы канализации света для передачи сигналов (при необходимости — после нормализации) через оптико-электронную линию связи (ОЭЛС) либо через волоконно-оптическую линию связи (BOJlC) на последующую обработку. Выходной функцией системы является площадь засветки фогоприемника ОЭЛС, либо входной апертуры ВОЛС S., где /' — номер засвеченного отверстия маски. При диаметре отверстий D = d, их шаге W— 1,5Д постоянном расстоянии от дефлектора до маски, квадратных сечениях отверстий и пучка вид зависимости £.(□), а следовательно, и S.(x), примет вид, показанный на рис. 4.15.
Если принять входной сигнал описанной дефлекторной системы как "четкий" входной параметр х, то площадь засветки каждого отверстия маски SP отнесенная к 5^, будет соответствовать величине A(x) (рис. 4.15) для каждого /-ro терма. Интерпретируя пример лингвистически, можно сказать, что, если входной величиной х является температура (ф = at), то засветка первого отверстия маски будет соответствовать значению температуры "низкая", второго — "средняя", и третьего — "высокая" с соответствующими значениями At(t) — bS,(ф), где b — некоторый коэффициент.
Рис.
4.15. Пример функции засветки 5,(ф)
откуда видно, что >5" можно рассматривать, как некоторый оптический аналог (модель) А, а функцию 5(ф) — аналог (модель) функции принадлежности.
Соотношения диаметров пучка света d, отверстий маски D и периода их следования W, равно как и форма отверстий и сечения пучка? задают вид функции принадлежности. Так, при D > d будет иметь место трапеЩидальная функция, при сечениях пучка и отверстий, отличных от прямоугольных, вид функции будет близок "колокообразной" и т. д.
где [а,
b]
— "пик"
или "ядро" А,
![]()
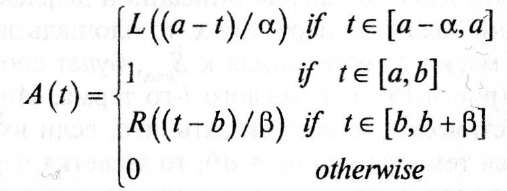
есть непрерывные и невозрастающие функции с Z,(0) = R{0) = 1 и L(1) = R( 1) = 0.
Таким
образом, в то время, как нечеткое
множество определяется множеством
кортежей
вид
выходной функции описываемого устройства
определяется множеством
![]()
![]()
В качестве дефлекторов можно использовать следующие электрооптические и акустооптические модуляторы: призменные дефлекторы, решетки гтризменных дефлекторов, решетки канальных фазовых модуляторов и др., основанные на электрооптическом или акустооптическом эффектах/ Такие фазификаторы относятся к электронно-оптическим. При этом входной величиной будет напряжение, подаваемое на модулятор. На рис. 4.16 приведен пример схемотехнического решения акустооптического устройства, состоящего из встречно-штыревого преобразователя для возбуждения поверхностно-акусгической волны (ПАВ) 4, оптической вол- новодной системы (полупроводниковый лазер 1, сформированные в оптическом волноводе 2 планарные линзы 3 и 5), линейки 6 фотоприемников ОЭЛС или элементов канализации света BOJlC и поглотителей ПАВ 7 и недифрагировавшего пучка света 8.
Входным параметром здесь является частота электрического сигнала U(t), в зависимости от изменения которой засвечивается тот или иной фотоприемник. Такая структура практически не отличается от известной схемы спектроанализатора [44] за исключением того, что в схеме спектроанализатора линейный размер фотоприемника s должен быть не меньше дифракционного изображения волноводного пучка в фокальной плоскости линзы, а в данном случае, наоборот, изображение пучка должно
7
Рис.
4.16. Схема оптоинтегрального
акустооптического фазификатора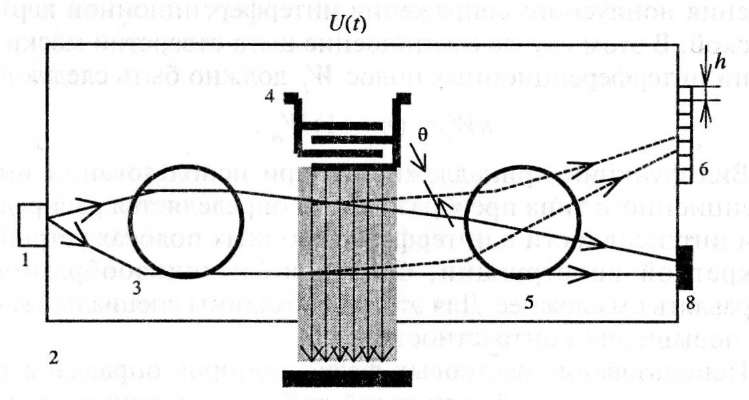
быть не меньше линейного размера фотоприемника или входной апертуры последующей оптической схемы. В остальном известные расчетные соотношения [45] справедливы и для расчета параметров такого фазификатора.
Рассмотрим теперь интерференционныйтип фазификатора. Известны так называемые интерференционно-кодовые преобразователи (ИКП) [45], принцип действия которых основан на преобразовании входной величины в перемещение интерференционных полос и оптическом сопряжении их с оптическим кодирующим устройством. Входная величина в ИКП, как правило, является электрической. Тот же принцип лежит и в основе функционирования нечеткого преобразователя, но вместо сопряжения интерференционной картины с кодирующим устройством применяется сопряжение с маской. При этом особенностью данного типа модуляторов по сравнению с дефлекторными является характер распределения интенсивности, являющийся периодической функцией с периодом т. Поэтому шаг отверстий маски W в этом случае составляет
![]()
где п — количество отверстий (равное количеству термов).
При необходимости можно значительно (в п раз) повысить чувствительность интерференционного преобразователя путем введения нониусного сопряжения интерференционной картины с маской. В этом случае соотношение шага отверстий маски Wm | и шага интерференционных полос Wt должно быть следующим:
![]()
Вид функции принадлежности при использовании интерференционного типа преобразователя определяется распределением интенсивности в интерференционных полосах устройства конкретной.конструкции, близок к "колоколообразному", и управлять им сложнее. Для этого необходимы специальные приемы повышения контрастности и т. д.
Использование растровых фазификаторов оправдано в тех случаях, когда входной величиной является механическое перемещение (линейное или угловое). Методы и средства применения различных типов растровых сопряжений (нониусные, муаровые, комбинированные) в разнообразных технологических исполнениях (объемная, интегральная и волоконная оптика) для целей обработки информации исследованы и описаны [46], поэтому здесь можно ограничиться лишь одним примером для пояснения принципов использования растровых сопряжений? именно в оптических фазификаторах.
Предположим, имеется входная величина x(t) — СМЕЩЕНИЕ с набором п термов {незначительное (S), влево (L), вправо (R), значительное влево (LL), значительное вправо (LR)}. При этом интерпретация термов следующая:
"незначительное"— x(t) примерно около 0;
"влево" — x(t) примерно около -x,;
"вправо" — x(t) примерно около x,;
"значительное влево" — x(t) меньше —х2;
"значительное вправо" — x(t) больше х2,
причем для упрощения расчета примем х2 = 2х1 Геометрические параметры простейшего нониусного растрового сопряжения в данном случае следующие:

где dm и df- ширина щелей измерительного и неподвижного растров соответственно, Wm и Wf — шаги их щелей.
На рис. 4.17 приведена схема такого датчика. С объектом, смещение которого является входной величиной x(t), связан измерительный растр М, оптически сопряженный с неподвижным растром F. Связь объекта с измерительным растром полужесткая, с тем, чтобы ограничить амплитуду смещения величиной х2 для корректной реализации граничных термов "x(t) < —х2"и "x(t) > x". Измерительный растр засвечивается световым потоком I0, графики засветки отверстий неподвижной маски, соответствующие различным термам при смещении измерительного растра, приведены на рисунке.
Форма получаемых функций принадлежности приведена для прямоугольных щелей растров, но в общем случае при использовании нониусного сопряжения можно изменять форму так же,
Рис.
4.17. Схема нониусного фаззификатора
как и в описанной выше дефлекторной схеме, например, изменением формы отверстий подвижного и неподвижного растров. Более того, если использовать в качестве обоих растров управляемые транспаранты, становится возможным самая широкая вариация всех параметров преобразователя.
Использование муарового сопряжения позволяет достичь более высокой чувствительности (разрешающей способности), муаровая картина по распределению интенсивности аналогична интерференционной картине, соответственно и приведенные выше соображения насчет интерференционного типа преобразователя справедливы и для муарового.
Обобщая, можно заключить, что в качестве фазификаторов могут быть применены (естественно, с некоторой схемотехнической адаптацией) большинство известных устройств датчиков и измерительных преобразователей, в которых используется принцип пространственно-временного кодирования.
Сложным и не полностью решенным вопросом до сих пор остается анализ погрешностей фазификаторов. Действительно выходом подобного датчика является не только численное значение функции принадлежности А(х) логической переменной х, но и сама логическая переменная х, принимающая значение 1 при у е (а, в), либо 0 при у e (а, в), где у — переменная на входе нечеткого сенсора. Анализ погрешности определения А(х) традиционен. Анализ же погрешности определения значения х может быть сведен к анализу определения границ интервалов а и в, что также может быть проведено традиционными методами. Однако остается дискуссионным вопрос: надо ли погрешность фазификаторов характеризовать набором погрешностей определения А(х), аив, либо следует ввести какую-либо новую обобщенную оценку погрешности.
Наиболее просто оптическими методами реализуется логическая операция "ИЛИ". Например, если считать, что наличие луча света соответствует значению логической переменной Xi= 1, а его отсутствие — значению логической переменной Xj = 0, то подавая на вход оптического волокна (световода) два луча (х, = 1 и X2 = 1), на его выходе будет луч, соответствующий логической переменной у<=> X1V х2 (операция "ИЛИ") (рис. 4.18).
При реализации других логических операций и функций одной оптикой не обойтись. В частности, для реализации логической операции "НЕ" потребуется использование, как минимум фотоприемника (фотодиода), порогового элемента (компаратора) и излучателя (светодиода), как показано на рис. 4.19.
Рис.
4.18. Схема оптического логического
элемента "ИЛИ"
Рис.
4.19. Схема оптико-электронного логического
элемента "НЕ"
1—
фотодиод; 2— компаратор; 3— светодиод;
X — луч света, соответствующий значению
X— 1; -X—
луч
света, соответствующий значению X=
0;
-U-
опорное
напряжение, соответствующее
логической
1
Использование оптико-электронных схем для реализации машины нечеткого вывода (MHB) и дефазификатора также возможно. Например, с помощью волоконных кодирующих устройств можно осуществить решение нечетких правил типа "если — то" [47], с помощью сопряжения волокон с матрицей или линейкой ПЗС — дефазификатор [48].
Задачей MHB является отработка всей системы правил над полученными с выходов фазификаторов нечеткими входными величинами и получение результата в виде нечеткого множества, которое далее должно быть дефазифицировано, т. е. путем некоторой процедуры получена четкая величина управляющего воздействия.
В простейшем случае MHB может быть построена на основе оптических кодирующих устройств, например, оптоволоконных. Рассмотрим реализацию фрагмента набора из двух правил, описывающих некое "управляющее воздействие" на объект Z на основе входной информации о "перемещении Г' X и "перемещении 2" Y, которые получены с фазификаторов, аналогичных описанным выше.
Если X = "большое влево (LL)" И Y = "вправо (R)", то Z= "очень сильное (LF)" Если X= "влево (L)" Y= "большое вправо (LR)", то Z= "сильное (F)".
На рис. 4.20 приведена схема оптической реализации приведенной системы правил в виде кодирующе-суммирующей оптоволоконной схемы.
На рисунке показаны оптоволоконные сумматоры оптических сигналов, снимаемых с выходов LL и L фазификатора входной величины X и выходных сигналов R и LR, снимаемых с фазификатора входной величины Y. Результатом суммирования будут сигналы, снимаемые с выходов LF и F выходной нечеткой величины Z. Выход представляет собой линейку выходных апертур волоконного кодирующего устройства.
Рассмотрим графики функций засветки выходов обоих фазификаторов (рис. 4.21) и покажем, каким образом формируется выходная четкая величина Z0 при входных четких величинах X0 и у0.
Выходная величина Z0 по термам F и LF образуется путем сложения входных оптических сигналов в соответствии с правилами вывода:
Рис.
4.20. Схема оптической реализации системы
двух нечетких правил
Рис.
4.21. Функции засветки выходов фазификаторов
входных величин
хи у
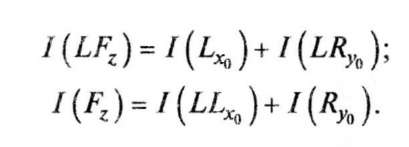
На линейке выходных апертур кодирующего устройства получим суммарные интенсивности I(LFz) и I(Fz).
Для того чтобы на основе полученного распределения засветки линейки выходов суммирующего кодера получить величину четкого управляющего воздействия Z0 (т. е. осуществить операцию дефазификации), необходимо первоначально осуществить диффузное рассеяние линейной засветки. Это осуществляется, например, установкой микролинз на выходах оптово- локон, при помощи дифракционной решетки или другими оптическими средствами. Затем выделяется пространственное положение максимума полученного распределения (показанного на рис. 4.22 пунктиром) при помощи либо ПЗС линейки, либо, когда необходимо получить цифровой выход, сопряжением выходной линейки кодера с оптическим кодирующим устройством (маской с двоичным или иным кодом). При этом для повышения точности аналого-цифрового преобразования пространственного положения пятна засветки в выходной код, соответствующий необходимому управляющему воздействию, целесообразно применить схему оптического кодирующего устройства с инверсными разрядами [48].
Таким образом, дефазификатором в данном случае служит оптическая система из выходной линейки кодера-сумматора, оптических элементов для "размывания" линейной картины за-
Рис.
4.22. Функции засветки выходов кодирующего
устройства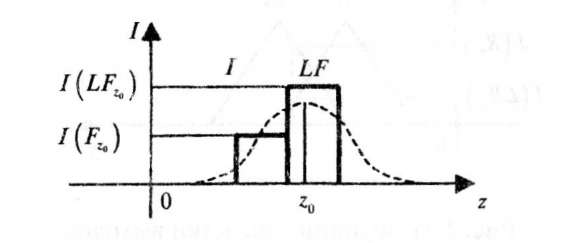
светки и устройства пространственного декодирования. Описанная схема дефазификации близка к известному методу наиболее часто применяемого способа дефазификации по методу нахождения центра масс, когда дефазифицированное значение нечеткого множества С определяется, как его нечеткий центроид:
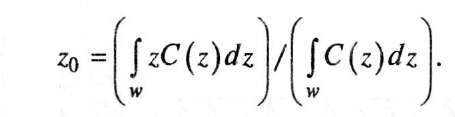
В структурах оптоэлектронных нечетких логических регуляторов возможно применение различных комбинаций элементов, оптических, электрических, оптоэлектронных. Так, на выходе оптического фазификатора (любого типа — растрового, как описано в данной работе, либо интерференционного или дефлек- торного) может быть установлена линейка фотоприемников, и дальнейшая обработка сигналов ведется уже в электрическом виде. Весьма перспективно применение управляемых транспарантов для изменения и настройки баз знаний и формы функций принадлежности. В случае реализации предложенных структур на основе оптоинтегральных технологий возможно создание микроминиатюрных однокристальных или гибридных устройств обработки информации на основе принципов нечеткой логики.
С учетом того, что, как было отмечено выше, в оптических фазификаторах несложно получить и инвертированный выходной сигнал (точнее, нечеткое множество сигналов), на основе описанной структуры возможна реализация широкого спектра баз нечетких знаний и механизмов вывода.
Также несложно сконструировать оптический или оптико- электронный нейрон. В качестве примера на рис. 4.23 приведена возможная схема оптического нейрона.
Входные сигналы подаются на блок дефлекторов. Он представляет собой линейку кристаллов, на каждый из которых подается напряжение Uj, в зависимости от которого луч в кристалле отклоняется на некоторый угол в плоскости, перпендикулярной рисунку. Далее лучи проходят через блок полупрозрачных зеркал, который является мультиплексором. Линза JI собирает световой поток с мультиплексора в один луч некоторой интенсивности и подает его на демультиплексор. Сигналы с демультиплексора
Рис.
4.23. Структура оптического нейрона
подаются на блок дефлекторов, управляемый напряжениями Vi, причем напряжения ^принимают значения либо 0, либо 1. Далее каждый луч, отклоненный на тот или иной угол засвечивает либо не засвечивает входы оптоволоконной линии связи, соединяющей его с другим нейроном. В процессе обучения такого нейрона меняют напряжения Uj и V1 (U1- весовые коэффициенты,V1 коэффициенты коммутации).
Однако использование подобных нейронов в настоящее время проблематично, так как, во-первых, не решена проблема создания чисто оптической памяти для баз данных и знаний. Во- вторых, оптическая реализация машины нечеткого вывода не обладает необходимой гибкостью и перестраиваемостью, а оптико-элекгронная нейронная сеть более сложная, менее надежная и менее универсатьная, чем ее программная реализация на микропроцессоре. Поэтому в настоящее время в качестве машины нечеткого вывода и базы знаний и данных целесообразно использовать микропроцессоры. Последнее делает неактуальным использование оптико-электронных схемных реализаций как нейронов, так и дефазификаторов.
Поэтому наиболее актуально использование оптических и оптико-электронных элементов (BOJ1C, ОЭЛС, ВОИК и ОЭИК) для входных, выходных и межблоковых информационных каналов нейроподобных управляющих систем и комплексов. Особенно привлекательно использование оптики и оптоэлектроники во входных каналах НС, так как они позволяют вводить в HC информационные сигналы практически любой физической природы (электрические, магнитные, акустические и др.) с высоким быстродействием, точностью и помехозащищенностью.