

1.5. Вычислительные методы решения задач
оптимального управления
При синтезе систем управления, прежде всего возникает вопрос о нахождении наилучшего в том или ином смысле или оптимального управления объектом или процессом. Речь может идти, например, об оптимальности в смысле быстродействия, т. е. достижении цели за кратчайшее время или, например, о достижении цели с минимальной ошибкой и т. д.
Впервые математически сформулированные эти вопросы являлись задачами вариационного исчисления, которое и обязано им своим возникновением [12]. В классическом вариационном исчислении нет, однако, решения целого ряда вариационных задач, важных для современной техники. Поэтому стали появляться другие методы, например, объединенные одним общим математическим приемом, который называется принципом максимума [13]. В настоящее время, в связи с бурным развитием средств вычислительной техники, наиболее популярны различные вычислительные методы оптимизации, например, методы динамического программирования [14], математического программирования [8, 15] или так называемые генетические алгоритмы [16].
Наибольшее число методов оптимального управления рассматривает такие процессы управления, каждый из которых мажет быть описан системой обыкновенных дифференциальных уравнений:
dxi/dt
=
fi(x1
х2
,..хn,
![]() i =
1, 2, …
n,
(1.33)
i =
1, 2, …
n,
(1.33)
где
x1
х2
,..хn
— величины,
характеризующие процесс, т.е. фазовые
координаты объекта управления,
определяющие его состояние в каждый
момент времени
t,
а ,
![]() —
параметры управления (в том числе и
настраиваемые параметры регуляторов),
определяющие ход процесса.
—
параметры управления (в том числе и
настраиваемые параметры регуляторов),
определяющие ход процесса.
Для
того чтобы ход управляемого процесса
был определен на некотором отрезке
времени ![]() достаточно,
чтобы на этом отрезке времени были
заданы как функции времени параметры
управления:
достаточно,
чтобы на этом отрезке времени были
заданы как функции времени параметры
управления:
![]() (1.34)
(1.34)
Тогда при заданных начальных условиях
![]() (1.35)
(1.35)
решение системы (1.33) определяется однозначно. Подлежащая решению вариационная задача, связанная с управляемым процессом (1.33), заключается в следующем.
Рассматривается интегральный функционал:

где
![]() — заданная функция.
— заданная функция.
Для каждого управления (1.34), заданного на некотором отрезке времени t0 < t < tt однозначно определяется ход управляемого процесса, и интеграл (1.36) принимает определенное значение.
Допустим, что существует управление (1.34), переводящее объект управления из заданного начального фазового состояния (1.35) в предписанное конечное фазовое состояние:
xi(t1)= хi1 , i = 1, 2, ..., п. (1.37)
Требуется отыскать управление
uj(t), j = 1, 2, ..., т, (1.38)
которое осуществит перевод объекта управления из состояния (1.35) в состояние (1.37) таким образом, чтобы функционал (1.36) имел минимальное значение. При этом моменты времени t0, t1 не фиксируются, а требуется только, чтобы в начальный момент времени объект находился в состоянии (1.35), а в конечный — в состоянии (1.37) и чтобы функционал (1.36) достигал минимума (возможен случай, когда t0, не фиксированы).
В
технических задачах параметры управления
не могут принимать любые произвольные
значения. Поэтому для любой точки,
характеризующей текущее значение
управления, должно выполняться
условие (u1
..., um)![]() U.
Причем выбор множества
U
должен отражать
специфику объекта управления. Во многих
технических задачах это множество
замкнуто. Введение подобных ограничений
приводит к неклассическим задачам
вариационного исчисления, которые лучше
решать вычислительными методами.
U.
Причем выбор множества
U
должен отражать
специфику объекта управления. Во многих
технических задачах это множество
замкнуто. Введение подобных ограничений
приводит к неклассическим задачам
вариационного исчисления, которые лучше
решать вычислительными методами.
Часто встречаются задачи об оптимальном переходе объекта управления из некоторого начального многообразия Ма точек фазового пространства на некоторое конечное многообразие Mv причем размерности этих многообразий могут быть произвольными. В частности, когда оба многообразия равны нулю, то мы приходим к исходной задаче.
Совершенно
очевидно, что в технических системах
не только параметры управления, но
и фазовые координаты объекта управления
должны подчиняться некоторым физическим
ограничениям. Например, высота полета
самолета не может быть отрицательной.
Следовательно, в общем случае должно
выполняться условие (![]() )
)![]() X, где множество X отражает специфику
объекта управления и среды его
функционирования.
X, где множество X отражает специфику
объекта управления и среды его
функционирования.
Другой задачей оптимального управления может быть задача об оптимальном попадании в движущуюся точку фазового пространства.
Допустим, что в фазовом пространстве имеется движущая точка
![]() (1.39)
(1.39)
Тогда возникает задача об оптимальном приведении объекта (1.33) в совпадение с движущейся точкой (1.39). Эта задача легко сводится к первой, если ввести новые переменные, положив:
![]() i=
1, 2...
п. (1.40)
i=
1, 2...
п. (1.40)
В результате этого преобразования система (1.33) превращается в новую, правда уже не автономную, а целью управления становится приведение объекта у{ у2, ..., уп в неподвижную точку (0, 0, ..., 0) фазового пространства.
Совершенно новый и практически важный вопрос возникает, когда движение преследуемого объекта не известно заранее, а сведения о нем поступают только с течением времени. Для решения такой задачи нужно иметь некоторые данные о поведении преследуемого объекта.
Весьма важным представляется случай, когда преследуемый объект является управляемым и его движение описывается системой дифференциальных уравнений:
d![]() /dt =
/dt = ![]() (z1,
z2,..,
zn,u1
и2,
..., um )
(1.41)
(z1,
z2,..,
zn,u1
и2,
..., um )
(1.41)
Задача управления заключается в том, чтобы, зная технические возможности преследуемого объекта, т. е. систему уравнения (1.41) и его положение в каждый данный момент времени, определить управление преследующего объекта в тот же момент времени так, чтобы преследование осуществлялось оптимальным образом. В такой постановке задача рассматривается в теории дифференциальных игр [17, 18]. При этом предполагается, что в начальный момент времени положение преследуемого объекта известно, а дальнейшее его поведение описывается вероятностным образом и процесс его движения считается марковским. В этих предположениях ищется такое управление преследующим объектом (1.33), при котором встреча некоторой малой окрестности объекта (1.33) с преследуемым объектом (1.41) или его малой окрестностью являлась наиболее вероятной.
Указанная задача может быть обратной, т. е. ищется управление для преследуемого объекта (1.41), такое, чтобы встреча некоторой малой окрестности объекта (1.41) с преследующим объектом (1.33) или его малой окрестностью являлась наименее вероятной. Более того, может быть задача, когда преследующих объектов несколько. Все эти задачи относятся к теории дифференциальных игр, а оптимальное решение ищется в условиях неполной определенности.
Наконец, в сложных интеллектуальных системах, обладающих целесообразным поведением, управление может заключаться в выборе наилучшего решения из множества альтернативных при нечетком и не обязательно вероятностном или статистическом описании динамики объекта управления и окружающей среды, а также при нескалярном показателе качества системы управления. Такие задачи относятся к теории принятия решений [19].
Таким образом, при синтезе сложных систем управления обычно необходимо решать задачи принятия решения (ЗПР) об оптимальности системы. Для случаев, когда удается указать шкалу — целевую функцию, значение которой определяет решение, известны и хорошо развиты теория и методы математического программирования [19], позволяющие проводить качественный и численный анализ возникающих при этом четких задач оптимизации решения. Учет неопределенностей, которые могут возникать при решении задач принятия решения при управлении сложными объектами, функционирующими в плохо формализуемой среде, позволяет применять указанные методы математического программирования с большим или меньшим успехом и в этих случаях.
Рассмотрим наиболее популярные вычислительные методы принятия решений.
• Математическое программирование (МП).
В простейшей ситуации принятия решения лицо, принимающее решение (ЛПР), — разработчик — преследует единственную цель, и эта цель может быть формально задана в виде скалярной функции, т. е. критерия качества выбора. При этом значения критерия качества могут быть получены для любого допустимого набора значений аргументов. Предполагается также, что известна область определения параметров управления (выбора), т. е. компонент выбираемого вектора или, во всяком случае, для любой заданной точки может быть установлено, является ли она допустимым выбором, т. е. принадлежит ли она области определения критерия качества решения. В такой ситуации задача выбора решения может быть формализована и описана моделью математического программирования.
В
задаче МП требуется вычислить n-мерный
вектор X, оптимизирующий (обращающий
в максимум или минимум в зависимости
от содержательной постановки задачи)
критерий качества решения
![]() (x)
при соблюдении ограничений
(x)
при соблюдении ограничений
![]() (x)
(x)![]() где
f—
известные скалярные функционалы,
и — заданные числа,
G
— заранее заданное
множество
п- мерного пространства.
где
f—
известные скалярные функционалы,
и — заданные числа,
G
— заранее заданное
множество
п- мерного пространства.
Таким образом, задача МП имеет вид:
![]()
![]() (1.42)
(1.42)
В зависимости от свойств функции f = < /0, /,, •••, /„ > и множества G будет тот или иной класс задач оптимизации. Если все функции f— линейные, a G- многогранное множество, то это задачи линейного программирования (ЛМП). Если среди функций f встречаются нелинейные, то это задачи нелинейного программирования (НМГ1). Среди нелинейных экстремальных задач выделяют выпуклые задачи (ВЗНМП), в которых максимизации подлежат вогнутые функции fn(x) при вогнутых функционалах ограничений f(x) и выпуклой области G. Задачи, в которых G имеет конечное или счетное число точек, выделены в специальный раздел математического программирования — целочисленное или дискретное программирование (ДМП). Если функционал f0 квадратичный, а все остальные функции f линейные и G многогранное множество, то это задачи квадратичного программирования (КМП), которые можно привести к задачам (ЛМП) при использовании теоремы Куна-Таккера [8].
В процессе решения задач большинства оптимального управления, в том числе и управления системами логико-вероятностного типа, можно прийти к задачам МП при выборе оптимального решения, когда имеется возможность построения скалярного критерия качества, в том числе и из атрибутов логических переменных.
• Математическое программирование в порядковых шкалах (МППШ).
Традиционная схема МП, требующая задания целевой функции, т. е. критерия качества, и функционалов ограничений, может не использоваться в механизме принятия решения. Так как решения во многих случаях принимают люди, то для них часто понятие последовательного предпочтения одного из сравниваемых вариантов другому — более естественный путь выбора рациональной альтернативы, чем формулировка цели и приближение к ней. В этом случае допустимое множество альтернатив целесообразно задавать не неравенствами, а некоторыми условиями предпочтения выбираемых вариантов. Такие ситуации встречаются, в частности, при проектировании, когда выбор должен обеспечивать достижение ряда целей, а его допустимость определяют разные люди, ведающие различными ресурсами, ограничивающими выбор.
Для решения таких задач можно обобщить схему математического программирования, переходя от количественных шкал к порядковым, т. е. переходя от моделей, требующих задания функционалов, определяющих цели и ограничения задачи, к моделям, учитывающим предпочтения лиц, участвующих в выборе решения. Это расширяет диапазон приложений теории экстремальных задач и может оказаться полезным в целом ряде ситуаций выбора. В частности, к задачам МППШ можно прийти в процессе решения задач оптимального управления системами логико-лингвистического типа при выборе оптимального решения системы логических уравнений, когда часть атрибутов логических переменных является лингвистическими или нечеткими, но имеется принципиальная возможность упорядочивания предпочтений, формируемых на основании анализа атрибутов и мнения лиц, принимающих решения.
Рассмотрим простейший переход от условий экстремальной задачи в количественных шкалах к условиям задачи в порядковых шкалах.
Пусть
G— некоторое
фиксированное компактное множество в
![]() —
рефлексивные, транзитивные и полные
бинарные отношения в шаре, содержащем
G
предпочтения, g0—
предпочтение лица, принимающего решение.
При этом
—
рефлексивные, транзитивные и полные
бинарные отношения в шаре, содержащем
G
предпочтения, g0—
предпочтение лица, принимающего решение.
При этом ![]() —могут интерпретироваться
как предпочтения лиц, ограничивающих,
каждый по-своему, множество допустимых
планов. Некоторые из отношений
gj
могут определяться обычными функциональными
неравенствами, ограничивающими диапазоны
изменения различных компонент решения.
—могут интерпретироваться
как предпочтения лиц, ограничивающих,
каждый по-своему, множество допустимых
планов. Некоторые из отношений
gj
могут определяться обычными функциональными
неравенствами, ограничивающими диапазоны
изменения различных компонент решения.
Обозначим
через
иi
, j
= 1, 2, ..., r — заданные априори
точки
G
и будем считать, что план х ![]() G
допустим по j-му ограничению,
если xgj
иj.
т. е. если пара (х,
uj)
gjСоответственно
назовем точку
х
G
допустимым решением, если
х gj
иj,
j
= 1, 2,..., r.
G
допустим по j-му ограничению,
если xgj
иj.
т. е. если пара (х,
uj)
gjСоответственно
назовем точку
х
G
допустимым решением, если
х gj
иj,
j
= 1, 2,..., r.
Задача МППШ представляет собой задачу выбора "наилучшего" (в смысле бинарного отношения gQ) среди допустимых решений. В ней требуется найти одно из решений х* — такое, что:
![]()

методы МП. Однако точное вычисление P(CQQ) даже при небольшом числе логических переменных qj представляет собой весьма трудоемкого задачи, которую целесообразно решать приближенно [1]. Кроме того, иногда вместо вероятностных оценок решений уравнений типа: C0Q = 0 используют минимаксные оценки достоверности V( С0 Q), которые вычисляют, используя правила:
V(![]() )
= max{V(
)
= max{V(![]() ),
V(
),
V(![]() )}
и
)}
и
![]() =
min{V(
),
V(
)}.
=
min{V(
),
V(
)}.
Большинство
нелинейных задач МППШ не имеет процедуры
решения приемлемой трудоемкости. Однако
для задач выпуклого МППШ, т. е. для
задач, в которых множество
G
выпукло, а предпочтения
g,
j
= 0, 1, 2, ..., r
— вогнуты, разработан диалоговый метод
решения. Такая процедура позволяет по
последовательно предъявляемым
альтернативам и получаемой локальной
информации о предпочтениях g
на соответствующих парах вариантов
получить е приближенное решение задачи.
При расширении понятия "оптимизация
по бинарному отношению" и расширении
понятия "![]() оптимальное по
g0
решение", удается обобщить метод
решения выпуклой задачи МППШ на случай
произвольных (нерефлексивных, неполных
и нетранзитивных) бинарных отношений
[19]. Ожидается, что значительного
прогресса в решении задач МППШ удастся
достичь за счет применения нейронных
сетей.
оптимальное по
g0
решение", удается обобщить метод
решения выпуклой задачи МППШ на случай
произвольных (нерефлексивных, неполных
и нетранзитивных) бинарных отношений
[19]. Ожидается, что значительного
прогресса в решении задач МППШ удастся
достичь за счет применения нейронных
сетей.
* Обобщенное математическое программирование (ОМП).
Обобщенное математическое программирование — это методология, которая распространяет принципы и методы традиционного математического программирования на случай векторных критериев и векторных ограничений. В отличие от традиционной теории оптимизации схемы ОМП не оценивают допустимость и качество каждой альтернативы, а приближаются к решению в процессе сравнения пар альтернатив. Оптимизация и ограничения в ОМП трактуются в терминах отношений предпочтения.
Во многих случаях ОМП представляет собой естественный подход к численному решению многокритериальных задач, к принятию групповых решений и к анализу конфликтных ситуаций. Используемый в ОМП подход к выбору решений учитывает предпочтения лиц, принимающих решения. При этом предполагается, что каждый участник процесса принятия решения индуцирует на множестве альтернатив некоторые бинарные отношения и сохраняет их в процессе решения задачи.
Ф ормально
запись модели ОМП имеет вид:
ормально
запись модели ОМП имеет вид:
где f(x), j = 0, 1, 2, ..., r— вектор-функции в Rmj, и, — фиксированный вектор в Rm, g.,j =0, 1,2, ..., r— бинарные отношения на G с R".
Модель ОМП соответствует выбору объектов, основанному на сравнении его характеристик, тогда как МППШ соответствует выбору объектов, производимому при непосредственном сравнении пар объектов. Поэтому структура модели ОМП значительно сложнее.
К модели ОМП можно прийти в задачах оптимального управления системами логико-лингвистического типа, если при выборе оптимального решения системы логических уравнений требуется анализировать сложные лингвистические выражения, являющиеся атрибутами (w*, w) или формируемые из атрибутов (w*, w) логических переменных q и q*, характеризующих решения (х*, х). При этом, если указанные лингвистические выражения могут быть сведены к логическим выражениям вида f. = C.Y, где С — идентификационная строка из 0 и 1, Y— вектор, компонентами которого являются конъюнкции логических переменных, характеризующих решения (х*, х), то решение может быть автоматизировано программными средствами искусственного интеллекта [20]. Кроме того, к модели ОМП можно прийти и в процессе решения задач оптимизации управления эволюционно-генетического типа, если в процессе эволюции сохранять неизменными предпочтения ЛПР.
Однако
для получения приемлемой трудоемкости
решения задач ОМП необходимо, чтобы
характеристики вектор-функции
![]() ,
области определения решения
G
и используемые бинарные отношения
,
области определения решения
G
и используемые бинарные отношения
![]() удовлетворяли некоторым специальным
требованиям. Так, конструктивные методы
анализа задач ОМП построены для случаев,
когда составляющие вектор-функции f(x)
— линейные или вогнутые функции,
G—
выпуклое множество, а бинарные
отношения g
— непрерывные, вогнутые, монотонные
и регулярные предпочтения. Такие модели
ОМП называют моделями обобщенного
выпуклого программирования (ОВП). Решение
задач ОМП
в настоящее время связывают с использованием
нейронных сетей и сред типа A-
life.
удовлетворяли некоторым специальным
требованиям. Так, конструктивные методы
анализа задач ОМП построены для случаев,
когда составляющие вектор-функции f(x)
— линейные или вогнутые функции,
G—
выпуклое множество, а бинарные
отношения g
— непрерывные, вогнутые, монотонные
и регулярные предпочтения. Такие модели
ОМП называют моделями обобщенного
выпуклого программирования (ОВП). Решение
задач ОМП
в настоящее время связывают с использованием
нейронных сетей и сред типа A-
life.
• Многошаговые задачи обобщенного математического программирования (МнОМП).
В предыдущем случае функция выбора (ФВ), определяемая предпочтениями ЛПР, была постоянна. Многошаговая схема обобщенного математического программирования может реализовывать произвольную ФВ на конечном множестве вариантов. Схема МнОМП предполагает некоторое расширение понятия "задача ОМП". Это расширение сводится к тому, что допустимое множество решений разрешается получать из множеств решений, выделяемых отдельными ограничениями задачи (xguj), не только их пересечением (уничтожение плохих особей в системе A-life), но и их объединением (скрещивание особей в системе A-life). К МнОМП можно прийти в задаче оптимизации управления эволюционно-генетического типа при изменяющихся предпочтениях ЛПР.
Схема МнОМП представляет собой множество задач ОМП, каждая из которых отвечает фиксированному предъявлению X. При этом решение исходной задачи ОМП может быть принято в качестве входа (предъявления) для другой задачи ОМГ1 и т. д. Таким образом, приходим к последовательной многошаговой схеме ОМП. Однако последовательная схема не реализует все ФВ. В частности, в рамках последовательной схемы не могут быть сформированы некоторые экстремальные задачи, например задача о минимаксе. Недостаток последовательной схемы можно устранить, если разрешить использование на шаге t результатов предыдущих шагов.
Для построения схемы МнОМП с большим числом шагов изменения ФВ с заданной точностью требуется чрезмерно много наблюдений за реализациями ФВ. Кроме того, вычислительная сложность решения задач МнОМП быстро растет с увеличением числа шагов. Поэтому возникает проблема аппроксимации ФВ функциями, реализуемыми более простыми механизмами, такими, например, как схема безусловной оптимизации по би- нарному отношению (уничтожение худшей из двух особей после скрещивания), одно-, двух- и т. д. шаговые схемы ОМГ1 (уничтожение худших после первого, второго и т. д. шагов эволюции). Однако использование современных систем типа A-life позволяет достичь определенного прогресса в решении задач МнОМП.
Таким образом, при формализации задач управления сложными динамическими системами последние целесообразно разбить на подсистемы, описываемые моделями разного уровня сложности и соответственно всю задачу разбить на ряд вложенных друг в друга подзадач, для решения каждой из которых могут быть использованы предназначенные для них методы и средства. При этом нечеткие задачи являются наиболее сложными, особенно в случае управления в человеко-машинных системах.
В настоящее время имеется определенное количество вычислительных методов принятия решения, применение которых в задачах оптимизации нечетких систем в совокупности с современными программными средствами искусственного интеллекта открывает новые возможности существенного повышения уровня автоматизации управления в сложных системах.
Рассмотренные вычислительные методы не исчерпывают все возможные методы решения задач оптимизации управления. Однако они являются наиболее продвинутыми в теоретическом плане и в части реализации с помощью интеллектуальных программных систем [1, 20]. Поэтому изложенные методы могут рассматриваться как конструктивная основа рационального выбора решений подобных задач. Кроме того, в зависимости от решаемого типа задачи можно с большим или меньшим успехом использовать готовые вычислительные алгоритмы и соответствующие инструментальные программные средства, среди которых в настоящее время широко применяются нейронные сети и программные системы A-life с генетическими алгоритмами.
Следует ожидать, что некоторое обобщение механизмов выбора позволит существенно расширить приложения теории принятия решений в области инженерии знаний, а точнее — методах синтеза знаний. По-видимому, целесообразно уточнить определение "база знаний", установив общие и гибкие структуры фиксации и накопления знаний на основе формализации обобщенной функции выбора.
УПРАВЛЯЮЩИЕ ВЫЧИСЛИТЕЛЬНЫЕ СИСТЕМЫ
2.1 Обобщенное описание
Структура ЭВМ, получившая имя Дж. фон Неймана, была описана им в "Первом наброске отчета по ЭДВАКу" (First Draft jf a Report on the ED VAC, 1945 г.). В нем приводится, ставшее впоследствии классическим, деление компьютера на арифметическо-логическое устройство, устройство управления и память. Здесь же высказана идея программы, хранимой в памяти.
Существенным недостатком машин фон Неймана является принципиально низкая производительность, обусловленная последовательным характером организации вычислительного процесса. Наличие одного процессора обусловливает и другой недостаток этих машин — низкую эффективность использования памяти. В самом деле, память однопроцессорных ЭВМ можно представить как длинную последовательность ячеек. Центральный процессор выбирает содержимое одной из них, дешифрирует, исполняет команду и, при необходимости, возвращает результат памяти в заранее обусловленную ячейку. Затем обращается к очередной ячейке для считывания следующей команды, и процесс повторяется до тех пор, пока не будет выбрана последняя команда исполняемой программы. Нетрудно заметить, что подавляющее большинство ячеек памяти бездействуют. Если ввести понятие коэффициента использования аппаратуры как отношение числа одновременно работающих элементов ЭВМ к общему числу этих элементов, то для машин фон Неймана этот коэффициент будет очень низким.
Почти все современные компьютеры основаны на этих идеях. Они содержат большую память и процессор, снабженный локальной памятью, ячейки которой называются регистрам»;. Процессор может загружать данные из памяти в регистры, выполнять арифметические и логические операции над содержимым регистров и отсылать значения регистров в память. Каждое устройство этой машины реализуется комплексом устройств, объединенных в вычислительную систему каналами связи и дисциплиной использования ресурсов ввода-вывода, памяти и времени, дисциплиной выполнения вычислений, дисциплиной управления выполнением программы и управления потоком программ.
Программа такой машины представляет собой последовательность команд выполнения перечисленных операций вместе с дополнительным множеством команд управления, влияющих на выбор очередной команды. Хотя компьютеры предназначены для использования людьми, возникающие при их создании трудности были столь значительны, что язык описания проблемы и инструкций для их решения на компьютере разрабатывался применительно к инженерным решениям, заложенным в конструкцию компьютера.
По мере преодоления технических проблем построения компьютеров накапливались проблемы, связанные с их использованием. Трудности сместились из области выполнения программ компьютера в область создания программ для компьютера. Начались поиски языков программирования, пригодных для человека. Начиная с языка, воспринимаемого компьютером (машинного языка), стали появляться более удобные формализмы и системы обозначений. И хотя степень абстракции языков возрастала, начиная с языка ассемблера и далее к Фортрану, Алголу, Паскалю, Аде и т.д., все они несут печать машины с архитектурой фон Неймана. Например, в однопроцессорной машине имеются процессор, оперативная память, внутренние часы (таймер), внешние часы, внешние устройства и шины: адресная, данных и управления. Таймер вырабатывает сигналы одинаковой временной протяженности, которые используются при управлении внутренним потоком информации. Внешние часы используются для измерения работы пользователя и измерения времени, которое занимает выполнение тех или иных операций. Через определенные промежутки времени таймер генерирует прерывание и процессор опрашивает все активные устройства, вырабатывающие запросы на обслуживание процессором (прерывания). Устройства обслуживаются в соответствии с установленными приоритетами прерываний, и после обслуживания процессор удаляет выставленное устройством прерывание. Приоритеты могут изменяться программно, и тогда изменяется порядок обслуживания. Таймер используется процессором и для разделения времени между программами (задачами). Дисциплина обслуживания может учитывать структуру оперативной памяти, количество поступивших на обслуживание программ и назначенные им приоритеты. Дисциплина разделения времени может изменяться, если при выполнении программ определяются характеристики, которые учитываются при их дальнейшем выполнении. В тех случаях, когда память организована постранично и программы, поступившие на обслуживание, могут быть все загружены в оперативную память, программам могут отводиться разные страницы, и прерывание выполнения текущей программы и переход к выполнению следующей программы происходят без выгрузки программы из оперативной памяти, иначе текущая программа выгружается из оперативной памяти и загружается следующая. Порядок выполнения программ определяется выбранным алгоритмом в соответствии с приоритетами и временем, уже затраченным на ее выполнение. Рассматривая сложные многопроцессорные машины для высокоскоростных вычислений, можно увидеть, что, несмотря на различную архитектуру, все управляющие вычислительные машины (УВМ) описываются с помощью обобщенной машины фон Неймана, в основе которой лежат различные автоматические системы дискретного действия для переработки информации и которые в кибернетике обычно называют "автоматами" или "конечными автоматами". Поэтому анализ и синтез указанных устройств основывается на теории систем дискретного действия, которая охватывает широкий круг вопросов, связанных с исследованием возможности автоматизации тех или иных процессов переработки информации, повышением производительности и надежности обработки информации и созданием эффективных методов их анализа и синтеза новой элементной базы.
В таких прикладных областях деятельности человека, как космология, молекулярная биология, гидрология, охрана окружающей среды, медицина, экономика и многих других, существуют проблемы, решение которых требует вычислительных машин, обладающих колоссальными ресурсами. Например, требуется быстродействие до 200 TFI.OPS, оперативная память до 200 Гбайт на процессор, дисковая память до 2Тбайт, пропускная способность устройств ввода — вывода (на один порт) не менее 1 Гбайт/с.
Сегодня схожие технические характеристики реализуются только с помощью дорогостоящих уникальных архитектур от CRAY, SCI, Fujitsu, Hitachi с несколькими тысячами процессоров. В настоящее время концептуально разработаны методы достижения высокого быстродействия, которые охватывают все уровни проектирования вычислительных систем. На самом нижнем уровне — это технология изготовления быстродействующей элементной базы и плат с высокой плотностью монтажа. Это наиболее простой путь к увеличению производительности ЭВМ за счет сокращения задержек при распространении сигналов, хотя, несмотря на успехи в создании элементной базы и методов монтажа, и удваивании в соответствии с законом Мура (рис. 2.1) плотности элементов на кристалле каждые 18 месяцев, увеличения производительности микропроцессоров N вдвое получить уже не удается. В настоящее время уже возможен выпуск процессоров со следующими характеристиками:1 млрд транзисторов на кристалле; тактовая частота 10 ГГц; производительность 2,5 тыс. MFLOPS (1 MFLOPS = 106 операций с плавающей точкой в 1 с). Дальнейшее увеличение эффективности процессора и его рабочей частоты возможно за счет совершенствования полупроводниковых технологий.

Рис. 2.1. Закон Гордона Мура N — число транзисторов в кристалле
При изготовлении процессорных чипов на пластине из кремния создается слой из окиси кремния, и далее, используя в литографическом процессе различные маски, при формировании структуры из него удаляются лишние участки. Затем добавляются необходимые примеси, что позволяет получить полупроводниковые структуры с необходимыми свойствами, затем прокладываются соединительные проводники, обычно из алюминия. Литографический процесс предусматривает засвечивание светочувствительных материалов через маски. Помимо чисто технических проблем совмещения масок при формировании структуры чипа с необходимой точностью, существуют физические ограничения, связанные с длиной волны излучения и минимальными размерами получаемого изображения. Тем не менее, в настоящий момент компании — производители чипов начали переход на нормы 65 нм (в 10 раз меньше длины волны красного света). Внедрение норм 65 нм позволяет интегрировать на кристалле площадью около 110 мм2 более полумиллиарда транзисторов. При этом удается уменьшить утечки в расчете на один транзистор (поскольку примерно вдвое уменьшилась его площадь), снизить на 20 % его балластную емкость и в конечном итоге повысить быстродействие. Утечки новых транзисторов 65 нм при том же рабочем токе уменьшены вчетверо, на чипе введены так называемые спящие транзисторы, которые отключают питание отдельных блоков памяти при их бездействии.
Переход на новые нормы обеспечивается преодолением сложнейших технических и технологических проблем. Решение проблемы совместимости материалов позволяет заменить алюминиевые соединений на медные, уменьшить сечение межкомпонентных соединений. Решение технологической проблемы нанесения дополнительных пленок кремния на изолятор, так называемая технология кремний на изоляторе (silicon-on- insulator, SOI), позволило уменьшить емкость МОП-структур и достаточно просто повысить их быстродействие.
Другим разрабатываемым компонентом является материал чипов. На скорости чипа в несколько гигагерц растут потери в кремнии. Возможное использование такого известного высокочастотного материала, как арсенида галлия, — дорого. Одним из предлагаемых решений стало использование в качестве материала для подложек соединения двух материалов — кремния с германием, SiGe. Результатом применения становится увеличение скорости чипов в 2—4 раза по сравнению с той, что может быть достигнута путем использования кремния. Во столько же раз снижается и их энергопотребление. Стоимость производства чипов при этом практически не возрастает. Их можно производить на тех же линиях, которые используются при производстве чипов на базе обычных кремниевых пластин, что исключает необходимость в дорогом переоснащении производственного оборудования.
Проводятся эксперименты и с различными нетрадиционными материалами. Например, сообщалось о создании фирмой Motorola опытных структур с использованием титаната стронция. Он превосходит по диэлектрическим свойствам диоксид кремния более чем на порядок. Это позволяет в три-четыре раза снизить толщину транзисторов по сравнению с использованием традиционного подхода, значительно снизить ток утечки, увеличить плотность транзисторов на чипе, одновременно уменьшая его энергопотребление.
При переходе к 45-нанометровому технологическому процессу, для создания затворов компания AMD предполагает использовать силицид никеля. Этот металлосодержащий материал обеспечивает лучшие характеристики по токам утечки по сравнению с традиционным кремнием. Отмечается, что подобный подход обеспечивает более чем двукратное увеличение быстродействия.
Компании Sony и Toshiba также начали новый совместный проект, направленный на разработку 45-нанометровых полупроводниковых структур. В рамках проекта компания Toshiba разработала технологию создания чипов, содержащих значительно большее количество слоев, чем используется сегодня. Речь идет о разработке девятислойных чипов, которые можно поместить в корпус высотой 1,4 мм. Сегодня производятся шестислойные чипы и мультичиповые компоненты.
К перспективным относятся планируемые фирмой Intel к применению с 2013 года технологии углеродных нанотрубок и кремниевых нанопроводников. Уже удалось интегрировать углеродные нанотрубки в кремний и создать полевой транзистор размерами всего 5 нм. Следующий шаг — создание транзисторов на полупроводниковых нанотрубках, диаметр которых составляет лишь 1,4 нм. По сообщениям Intel и японской фирмы NEC (владельца патента на коммерческое использование углеродных нанотрубок) с 2011-го по 2019 год чипы будут создаваться на основе нанотрубок из кремния и углерода.
Повышение производительности предполагает также исследования в области схемотехники процессоров. Увеличение быстродействия достигается при уменьшении числа логических уровней при реализации комбинационных схем. Создаются схемы с ограничениями по количеству вентилей и их коэффициентам соединений по входу и выходу. Быстродействие вычислительных систем может быть повышено за счет реализации специальными аппаратными средствами вычисления сложных функций, например корней, сложения, векторов, умножения матриц, быстрого преобразования Фурье. Указанные средства позволяют сократить число команд в программах и более эффективно использовать машинные ресурсы. Существует небольшое подмножество простых и часто используемых команд, которые можно оптимизировать, а сокращение времени обращения к памяти достигается за счет разбиения памяти на модули, обращение к которым может осуществляться одновременно, за счет применения кэш-памяти и увеличения числа внутренних регистров в процессоре.
Полная реализация потенциально высокого быстродействия системы поддерживается разработкой алгоритмов, которые приводили бы к простым комбинационным схемам с небольшим числом циклов для основных операций — сложения, умножения, деления, и с внутренним параллелизмом.
Совершенствование элементной базы — самый простой метод повышения производительности вычислительных систем, но он приводит к существенному удорожанию новых разработок. Поэтому наиболее приемлемым путем к созданию высокопроизводительных УВМ, оцениваемых по критерию "производительность/стоимость", может быть путь исследования и разработки новых методов логической организации систем, а также новых принципов организации вычислений. Основной способ повышения производительности с этой точки зрения — исполь-
зование параллелизма, который реализуется на верхнем уровне структурой алгоритма, по которому работает система. Он состоит в том, чтобы выполнять одновременно несколько команд. Этот подход отличается оттого, который реализован в обычной фон- неймановской машине, когда команды исполняются строго последовательно одна за другой. При такой обработке предусматривается одновременное выполнение программ или их отдельных частей на независимых устройствах.
Параллельный подход приводит к различным вариантам архитектуры в зависимости от способа, по которому осуществляется задание очередности следования команд и управление их исполнением. Распараллеливание позволяет значительно увеличить производительность систем при решении широкого класса прикладных задач.
Известны следующие базовые способы введения параллелизма в архитектуру УВМ:
конвейерная, или векторная (Parallel Vector Processor — PVP) организация. В основе ее работы лежит концепция конвейеризации, т. е. явного сегментирования арифметического устройства на отдельные части, каждая из которых выполняет свою подзадачу для пары операндов (рис. 2.2);

Рис. 2.2. Конвейерная вычислительная система
функциональная обработка — предоставление нескольким независимым устройствам возможности параллельного выполнения различных функций, таких, как операции логики, сложения, умножения, прирашения и т.д., и обеспечение взаимодействия с различными данными;
параллельная или матричная (массивная) (Massively Parallel Processor— МРР) организация, в основе которой лежит идея использования для решения одной задачи нескольких одновременно работающих процессорных элементов (ПЭ). Причем процессоры могут быть как скалярными, так и векторными, с общей системой управления, и организованных в виде матриц. Все процессоры выполняют одну и ту же операцию, но с различными данными, хранящимися в локальной памяти каждого процессора, т. е. выполняют жестко связанные пошаговые операции (рис. 2.3);

Рис. 2.3. Матричная вычислительная система (ПЭ — процессорные элементы, П — модули памяти)
мультипроцессорная обработка — осуществляется несколькими процессорами, каждый из которых имеет свои команды; взаимодействие процессоров осуществляется через общее поле памяти.
Естественно, что в отдельных проектах могут объединяться некоторые или все эти способы параллельной обработки.
Эти подходы позволяют достичь значительного ускорения по сравнению со скалярными машинами. Ускорение в системах матричного типа может быть больше, чем в конвейерных, поскольку увеличить число процессорных элементов проще, чем число ступеней в конвейерном устройстве.
Принцип векторной обработки обоснован существованием значительного класса задач, использующих операции над векторами. При этом под вектором понимаем одномерный массив, который образуется из многомерного массива, если один из индексов пробегает все значения в диапазоне его изменения. В некоторых задачах векторная форма параллелизма представлена естественным образом, например при перемножении матриц. Алгоритмы этих задач в соответствии с терминологией Флинна относятся к классу ОКМД (одиночный поток команд, множественный поток данных, см. далее).
Так как в векгорно-конвейерной системе один (или небольшое число) конвейерный процессор выполняет команды путем засылки элементов векторов в конвейер с интервалом, равным длительности прохождения одной стадии обработки, скорость вычислений зависит только от длительности стадии и не зависит от задержек в процессоре в целом.
Реализация операций обработки векторов на скалярных процессорах с помощью обычных циклов ограничивает скорость вычислений из-за их последовательного характера.
Работа векторных компьютеров опирается на последовательно-групповую алгоритмическую структуру вычислительных процедур. Процедуры внутри группы могут выполняться одновременно, а сами группы — последовательно. Векторные команды — это группы, составленные из идентичных операций, и векторные компьютеры манипулируют всем массивом сходных данных подобно тому, как скалярные машины обрабатывают отдельные элементы таких массивов. При векторной обработке задается одна и та же операция над всеми элементами одного или нескольких векторов. PVP-системы имеют специальные векторно-конвейерные процессоры, в которых предусмотрены команды однотипной обработки. Эти векторные центральные процессоры включают в себя векторные регистры и конвейерные АЛУ. Когда данные обрабатываются посредством векторных модулей, результаты выдаются за один рабочий цикл сразу для всего вектора. При работе в векторном режиме векторные процессоры обрабатывают данные практически параллельно, что делает их в несколько раз более быстрыми, чем при работе в скалярном режиме. Важной особенностью векторных конвейерных процессоров, используемой для ускорения вычислений, является механизм зацепления. Зацепление — такой способ вычислений, когда одновременно над векторами выполняется несколько операций. Например, можно одновременно производить выборку вектора из памяти, умножение векторов, суммирование элементов вектора
Существенной особенностью векторно-конвейерной архитектуры является то, что данные всех параллельно исполняемых операций выбираются и записываются в единую память. Как правило, несколько процессоров работают одновременно с общей памятью в рамках многопроцессорных конфигураций. Несколько таких узлов могут быть объединены с помощью коммутатора (аналогично МРР). Передача данных в векторном формате осуществляется намного быстрее, чем в скалярном. Проблема взаимодействия между потоками данных при распараллеливании становится несуществ. Архитектура векторной обработки в PVP системах позволяет использовать стандартные языки высокого уровня. Задача программирования на PVP-системах заключается в векторизации циклов и их распараллеливании, например за счет переведения задачи в матричную форму и разложении функций в ряд с числом членов, кратным числу процессов.
Существует ряд факторов, приводящих к тому, что при выполнении реальных программ производительность векторных ЭВМ оказывается значительно ниже максимально возможной. К ним относится невозможность построить реальную прикладную программу, состоящую только из векторных операций. Часть вычислений остается скалярной, в том числе команды для подготовки векторных команд и управления их прохождением. Эффективность конвейера определяется длиной векторов, поскольку существует непроизводительное время, затрачиваемое на начальном этапе (загрузка параметров, реконфигурация, ожидание первого результата). Наличие стартового времени приводит к тому, что векторная обработка оказывается эффективней скалярной, лишь начиная с некоторого порога длины векторов. Всегда существуют зависимости по данным между командами, т. е. одна команда не может исполняться до завершения другой, и нарушается условие одновременности исполнения нескольких команд. Аналогичная ситуация с условными переходами, когда не ясно, какая команда должна выполняться следующей, или векторная команда как единое целое не может быть выполнена в ситуациях, когда вид операции над элементами вектора зависит от условия. К неудобным операциям относятся рассылка и сбор элементов по памяти, которые имеются в задачах сортировки, быстрого преобразования Фурье, при обработке графов и списков.
Снижают быстродействие и ограничения, связанные с памятью. С целью достижения максимальной скорости работы в системах применяются сложные способы обращения к памяти. Поэтому любое отклонение от спецификации работы снижает производительность. К ним относятся и нахождение команд вне специального буфера команд, и изменения пропускной способности тракта обмена данными при обращении к памяти, или неполное ее использование, что связано с тем, что время доступа к памяти превышает длительность одной стадии обрабатывающего конвейера. При решении задач иногда массивы данных оказываются столь большими, что не могут уместиться в главной памяти, и существуют потери за счет подкачки и удаление информации в процессе счета. Соотношение объема памяти должно быть хорошо сбалансировано с производительностью системы. По эмпирическому правилу Амдала 1 бит памяти должен приходиться на 1 оп/с. Максимальная пропускная способность системы достигается только в том случае, когда все арифметические устройства используются полностью. Следовательно, реальная производительность зависит от состава операций в конкретной программе и использования всех арифметических устройств полностью. Например, поскольку деление плохо поддается конвейеризации, обычно оно выполняется в устройствах обратной аппроксимации и умножения посредством итерационной процедуры.
Система с матричной архитектурой (МРР) состоит из множества процессорных элементов, организованных таким образом, что они исполняют векторные команды, задаваемые общим для всех устройством управления. Причем каждый процессорный элемент работает с отдельным элементом вектора. Исполнение векторной команды включает чтение из памяти элементов векторов, распределение их по процессорам, выполнение заданной операции и засылку результатов обратно в память.
Существует архитектура, где система строится из отдельных модулей, содержащих процессор, локальный банк операционной памяти, два коммуникационных процессора (рутера) или сетевой адаптер, иногда — жесткие диски и/или другие устройства ввода/вывода. Один рутер используется для передачи команд, другой — для передачи данных. По сути, такие модули представляют собой полнофункциональные компьютеры. Доступ к банку операционной памяти из данного модуля имеют только процессоры из этого же модуля. Модули соединяются специальными коммуникационными каналами. Пользователь может определить логический номер процессора, к которому он подключен, и организовать обмен сообщениями с другими процессорами. Используются два варианта работы операционной системы (ОС) на машинах МРР архитектуры. В одном полноценная операционная система (ОС) работает только на управляющей машине (front-end), а на каждом отдельном модуле работает сильно урезанный вариант ОС, обеспечивающий работу только расположенной в нем ветви параллельного приложения.
Во втором варианте на каждом модуле работает полноценная UNIX- подобная ОС, устанавливаемая отдельно на каждом модуле.
Главным преимуществом систем с раздельной памятью является хорошая масштабируемость, так как в машинах с раздельной памятью каждый процессор имеет доступ только к своей локальной памяти, в связи с чем не возникает необходимости в потактовой синхронизации процессоров. К недостаткам, связанным с отсутствием общей памяти, относится снижение скорости межпроцессорного обмена, поскольку нет общей среды для хранения данных, и ограниченный объем локального банка памяти. Требуется специальное программирование для реализации обмена сообщениями между процессорами. Программирование параллельной работы нескольких сотен процессоров и при этом обеспечение минимума затрат счетного времени на обмен данными между ними определяют высокую цену программного обеспечения для матрично-параплельных систем с раздельной памятью. При работе с МРР-системами используют так называемую Massive Passing Programming Paradigm — парадигму программирования с передачей данных (MPI, PVM, BSPlib).
Н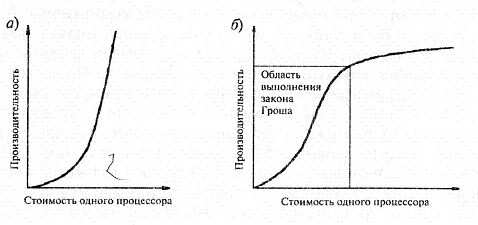 а
основе сопоставления фон-неймановской
ЭВМ и многопроцессорной системы были
сформулированы критерии оценки
производительности: закон Гроша и
гипотеза Минского.
а
основе сопоставления фон-неймановской
ЭВМ и многопроцессорной системы были
сформулированы критерии оценки
производительности: закон Гроша и
гипотеза Минского.
Рис. 2.4. Закон Гроша
Закон Гроша гласит, что производительность одного процессора увеличивается пропорционально квадрату его стоимости (см. рис. 2.4, а). На практике в верхней области графика
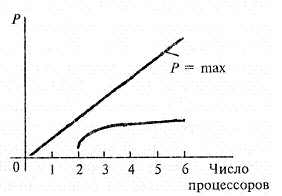
Рис. 2.5. Гипотеза Минского
зависимость имеет совершенно иной вид (см. рис. 2.4, о) и можно расходовать все больше средств, не получая при этом скорости вычислений, предсказываемой законом Гроша.
Гипотеза Минского утверждает, что в параллельной системе с п процессорами, производительность каждого из которых равна единице, общая производительность растет лишь как log2AJ (рис. 2.5) из-за необходимости обмена данными. Однако загруженность п процессоров может быть гораздо выше log2« за счет введения соответствующих механизмов управления.
Эффективность использования различных способов организации вычислительной системы (ВС) напрямую зависит от структур реализуемых алгоритмов. Параллелизм алгоритмов определяется иерархией, которая существует в том смысле, что возможно описание вычислительного процесса в виде последовательности более простых конструкций, которые, в свою очередь, могут быть описаны в виде алгоритмов, состоящих из еще более простых вычислительных конструкций. Детализацию называют мелкой, если вычислительные конструкции алгоритма являются примитивными (т. е. реализуемыми одной командой), и крупной, если эти конструкции являются сложными (т. е. реализуются с помощью другого алгоритма). В системах может использоваться комбинированная детализация. Для ее реализации должны использоваться специальные языки программирования, предоставляющие средства для явного описания параллелизма.
Даже из краткого описания принципов работы таких систем можно сделать вывод, что при выполнении реальных программ производительность систем с параллельной организацией вычислений определяется содержанием конкретных программ, учетом в них факторов, влияющих на производительность машины конкретной архитектуры. Поэтому попытки сравнения
производительности машин на контрольных прикладных задачах с определенным соотношением скалярных и векторных опе раций могут дать лишь грубые оценки. Одними из используемых для оценки машин контрольных задач являются так называемые ливерморские циклы, разработанные в Национальной лаборатории им. Лоуренса в г. Ливермор (США). Специфическое влиянии на производительность машин особенностей организации систем и качества используемого компилятора подтверждается тем, что даже для одного типа машин оценки производительности, полученные на разных циклах, отличаются друг от друга в десятки раз.
Чтобы получить более полное представление о многопроцессорных вычислительных системах, помимо такой их характеристики, как высокая производительность, необходимо отметить и другие отличительные особенности. Прежде всего — это необычные архитектурные решения, направленные на повышение производительности (работа с векторными операциями, организация быстрого обмена сообщениями между процессорами или организация глобальной памяти в многопроцессорных системах и др.). Понятие архитектуры высокопроизводительной системы является достаточно широким, поскольку под архитектурой можно понимать и способ обработки данных, используемый в системе, и организацию памяти, и топологию связи между процессорами, и способ исполнения системой арифметических операций. Попытки систематизировать все множество архитектур начались в конце 1960-х годов и продолжаются по сей день. В 1966 году М. Флинном (Flynn) был предложен подход к классификации архитектур вычислительных систем на основе понятий потока команд или данных, обрабатываемых процессором. Классификация описывает четыре архитектурных класса:
SISD = Single Instruction Single Data (ОКОД-одиночный поток команд и одиночный поток данных)
MISD = Multiple Instruction Single Оа1а(МКОД-множествен- ный поток команд и одиночный поток данных)
SIMD = Single Instruction Multiple Data (ОКМД-одиночный поток команд и множественный поток данных)
MIMD = Multiple Instruction Multiple Data (МКМД-множе- ственный поток команд и множественный поток данных)
К классу SISD относятся последовательные компьютерные системы, которые имеют один центральный процессор, способный обрабатывать только один поток последовательно исполняемых инструкций. В настоящее время практически все высокопроизводительные системы имеют более одного центрального процессора, однако каждый из них выполняют несвязанные потоки инструкций, что делает такие системы комплексами S1SD- систем, действующих на разных пространствах данных. Для увеличения скорости обработки команд и скорости выполнения арифметических операций может применяться конвейерная обработка.
Важное преимущество последовательного подхода, реализующего эту архитектуру, состоит в том, что для машин такого вида разработано большое число алгоритмов и пакетов прикладных программ, созданы обширные базы данных, накоплен богатый опыт программирования, разработаны фундаментальные языки и технологии программирования. Поэтому дальнейшее совершенствование организации ЭВМ (мэйнфреймов и микропроцессоров) шло таким образом, что последовательная структура сохранялась, а к ней добавлялись механизмы, позволяющие выполнять несколько команд одновременно. До последнего времени параллельная обработка на уровне команд (instruction- level-parallelism — ILP) принималась как единственный подход, позволяющий добиваться высокой производительности без изменения программного обеспечения.
В классе машин MISD множество инструкций должно выполняться над единственным потоком данных. До сих пор ни одной реальной машины, попадающей в данный класс, не было создано. Косвенный аналог работы таких машин — обработка базы данных одновременно несколькими потребителями.
Системы архитектуры SIMD обычно имеют большое количество процессоров — тысячи и десятки тысяч, которые могут выполнять одну и ту же инструкцию относительно разных данных в жесткой конфигурации. Единственная инструкция параллельно выполняется над многими элементами данных. Основные технические принципы организации компьютеров этого класса используются на разных уровнях архитектуры систем других классов.
Каждой архитектуре системы можно сопоставить свой вид алгоритмической структуры организации высокоскоростных вычислений (рис. 2.6).
Последовательная структура и соответствующая ей S1SD архитектура является простейшей. В последовательно-групповой алгоритмической структуре вычислительные процедуры объединены в группы, а отношение следования состоит в том, что процедуры внутри группы могут выполняться одновременно, а сами группы — последовательно. Вычислительные процедуры внутри одной группы могут быть одинаковыми или разными. Наиболее типичным является случай, когда одинаковые вычислительные процедуры образуют одиночный поток команд и множественный поток данных (SIMD).
Возможно ускорение вычислений за счет использования алгоритмов, структура которых представляет совокупность слабо связанных потоков команд (последовательных процессов). В этом случае программа может быть представлена как совокупность процессов, каждый из которых может выполняться на отдельном последовательном процессоре и при необходимости
 Рис.
2.6. Алгоритмические структуры: а
—
последовательная;
б—
последовательно- групповая
в —
слабосвязанные потоки; г —■ параллельная
структура общего вида
Рис.
2.6. Алгоритмические структуры: а
—
последовательная;
б—
последовательно- групповая
в —
слабосвязанные потоки; г —■ параллельная
структура общего вида
осуществлять взаимодействие с другими процессорами. Вычислительные системы, отвечающие особенностям данной алгоритмической структуры, — это многопроцессорные системы архитектуры MIMD, особенностью которых является необходимость синхронизации взаимосвязи между процессами. Г1о этому принципу все архитектуры MIMD делятся на два класса: взаимодействующие через общую память (класс А) и путем обмена сообщениями (класс Б) (рис. 2.7). Класс архитектуры Б предназначен для систем с большим числом процессоров.
В архитектуре класса А, или SMP-архитектуре (symmetric multiprocessing) — симметричная многопроцессорная архитектура, физическая память является общей для всех ПЭ. Это означает, что здесь существуют задержки в коммутационном устройстве и при доступе в память. Таким образом, в таких системах требуется, чтобы коммутационное устройство имело высокое быстродействие, а при доступе в память количество конфликтов было минимальным.
П амять
является способом передачи сообщений
между процессорами, при этом все
вычислительные устройства при обращении
к ней имеют равные права и одну и ту же
адресацию для всех ячеек памяти. Поэтому
S MP-архитектура
называется симметричной. Последнее
обстоятельство позволяет очень
эффективно обмениваться данными с
другими вычислительными устройствами.
SMP-система строится на
основе высокоскоростной
амять
является способом передачи сообщений
между процессорами, при этом все
вычислительные устройства при обращении
к ней имеют равные права и одну и ту же
адресацию для всех ячеек памяти. Поэтому
S MP-архитектура
называется симметричной. Последнее
обстоятельство позволяет очень
эффективно обмениваться данными с
другими вычислительными устройствами.
SMP-система строится на
основе высокоскоростной
Рис. 2.7. Схема архитектуры MIMD — класс А и класс Б
системной шины (SGI PowerPath, Sun Gigaplane, DECTurboLaser), к слотам которой подключаются функциональные блоки трех типов: процессоры (ЦП), операционная система (ОП) и подсистема ввода/вывода (I/O) (рис. 2.8). Вся система работает под управлением единой ОС (обычно UNIX-подобной, но для Intel- платформ поддерживается Windows NT). ОС автоматически (в процессе работы) распределяет процессы по ЦП, но иногда возможна и явная привязка.
К преимуществам SMP-систем относится простота и универсальность для программирования. Архитектура SMP не накладывает ограничений на модель программирования, используемую при создании приложения: обычно используется модель параллельных ветвей, когда все процессоры работают абсолютно независимо друг от друга. Однако можно реализовать и модели, использующие межпроцессорный обмен. Использование общей памяти увеличивает скорость такого обмена, пользователь также имеет доступ сразу ко всему объему памяти. Для SMP- систем существуют сравнительно эффективные средства автоматического распараллеливания. Она легка в эксплуатации и относительно дешева.
К основным недостаткам SMP-систем относится плохая масштабируемость, связанная с тем, что в конкретный момент шина способна обрабатывать только одну транзакцию, и возникают проблемы разрешения конфликтов при одновременном обращении нескольких процессоров к одним и тем же областям общей физической памяти. Кроме того, системная шина имеет ограниченную (хоть и высокую) пропускную способность и ограниченное число слотов. В реальных системах используется не более 32 процессоров. При работе с SMP-системами используют
Рис.
2.8. Схематический вид SMP-архитектуры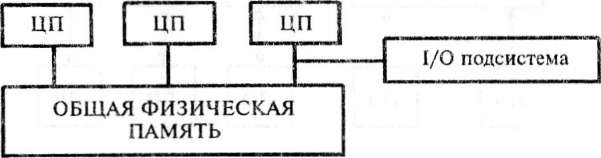
Для построения масштабируемых систем на базе SMP-npo- цессоров используются кластерные или NUMA-архитектуры.
Гибридная архитектура NUiVlA (nonuniform memory access) (рис. 2.9) воплощает в себе удобства систем с общей памятью и относительную дешевизну систем с раздельной памятью. Главная особенность такой архитектуры — неоднородный доступ к памяти за счет такой организации, что память является физически распределенной по различным частям системы, но логически объединяемой, так что пользователь видит единое адресное пространство. Система состоит из однородных базовых модулей (плат), состоящих из небольшого числа процессоров и блока памяти. Модули объединены с помощью высокоскоростного коммутатора. Поддерживается единое адресное пространство, аппаратно поддерживается доступ к удаленной памяти, т. е. к памяти других модулей. При этом доступ к локальной памяти осуществляется в несколько раз быстрее, чем к удаленной.
По существу архитектура NUMA является МРР-архитекту- рой, где в качестве отдельных вычислительных элементов беруг- ся SMP (симметричная многопроцессорная архитектура) узлы. В такой структуре кэш-память принадлежит отдельному модулю, а не всей системе в целом, и данные в кэше одного модуля могут быть недоступны другому. Дальнейшим улучшением архитектуры
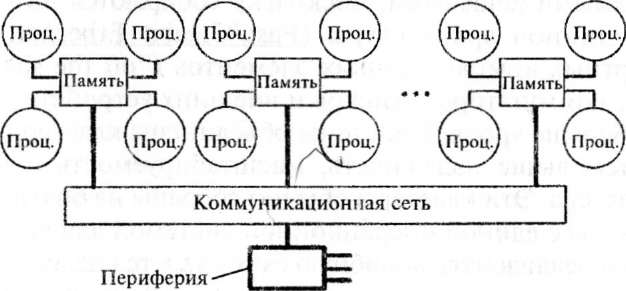
Рис. 2.9. Структурная схема компьютера с гибридной архитектурой: четыре процессора связываются между собой в рамках одного SMP-узла
NUMA является наличие когерентного кэша. Это так называемая архитектура cc-NUMA (Cache Coherent Non-Uniform Memory Access), в которой имеется "неоднородный доступ к памяти с обеспечением когерентности кэшей".
При когерентности кэшей все центральные процессоры получают одинаковые значения одних и тех же переменных в любой момент времени. Для обеспечения синхронизации кэшей используют механизм отслеживания шинных запросов (snoopy bus protocol) или выделяют специальную часть памяти, отвечающую за отслеживание достоверности всех используемых копий переменных.
На настоящий момент максимальное число процессоров в сс- NUMA-системах может превышать 1000. Обычно вся система работает под управлением единой ОС, как в SMP. Возможны также варианты динамического "подразделения" системы, когда отдельные "разделы" системы работают под управлением разных ОС.
В кластерной архитектуре кластеры, которые представляют собой два или больше компьютеров (часто называемых узлами), объединяются при помощи сетевых технологий на базе шинной архитектуры или коммутатора в единый информационно-вычислительный ресурс. В случае сбоя какого-либо узла другой узел кластера может взять на себя нагрузку неисправного узла, и пользователи не заметят прерывания в доступе. Возможности масштабируемости кластеров позволяют увеличивать производительность приложений. Такие суперкомпьютерные системы являются самыми дешевыми, поскольку собираются на базе стандартной шинной архитектуры (Fast/Gigabit Ethernet. Mvrinet) и стандартных комплектующих элементов ("off the shelf'): процессоров, коммутаторов, дисков и внешних устройств.
Чем больше уровней системы объединены кластерной технологией, тем выше надежность, масштабируемость и управляемость кластера. Эти кластеры обычно собраны из большого числа компьютеров с единой операционной системой для всего кластера. Однако реализовать подобную схему удается далеко не всегда, и обычно она применяется для не слишком больших систем.
Многопоточные системы используются для обеспечения единого интерфейса к ряду ресурсов, которые могут со временем произвольно наращиваться (или сокращаться) в размере.
Архитектура кластерной системы (способ соединения процессоров друг с другом) в большей степени определяет ее производительность, чем тип используемых в ней процессоров.
Одной из перспективных структур и протокола для построения больших систем является Scalable Coherent Interface /Local Area Multiprocessor/ (SCI/LAMP). Это расширяемый связной интерфейс (РСИ), представляющий собой комбинацию основных компьютерных шин, шин процессорной памяти, высокопроизводительных переключателей, местных и удаленных оптических связей, информационных систем, использующих связи точка- точка, обеспечивающих когерентное кэширование распределенной памяти и расширений. SCI/LAMP строится на интерфейсах общего применения, таких как PCI, УМЕ, Futurebus, Fastbus, и т.д., и I/O соединениях, таких как ATM или FibreChannel.
Структура и логический протокол РСИ позволяют обеспечить высокую эффективность сотен и тысяч процессоров, совместно работающих в больших системах.
Узел РСИ (рис. 2.10) получает через входной канал пакеты символов, состоящих из двух байтов. В случае совпадения значения первого символа с присвоенным узлу адресом пакет через входную FIFO передается в прикладные схемы узла на обработку, например, процессором. При несовпадении пакет через проходную FIFO и ключ попадает в выходной канал. Ключ нужен для задержки проходящего пакета на время выдачи пакета обработанной информации через выходную FIFO.
Узлы соединяются в так называемые колечки (рис 2.11), в которых пакеты продвигаются всегда в одном направлении
Рис.
2.10. Узел РСИ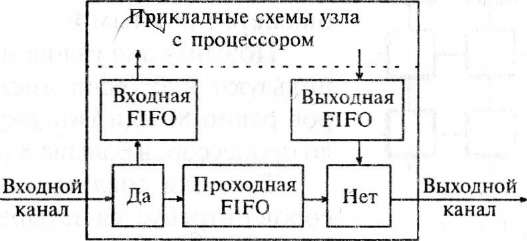
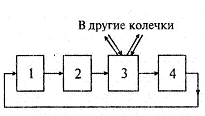
Рис 2.11. Колечко РСИ
(на рисунке один из узлов выполнен в качестве переключателя на другие колечки). Переключатели позволяют образовать из колечек сети произвольной конфигурации, например регулярные структуры. В больших системах, при большом числе узлов с процессорами, одиночное колечко становится неэффективным вследствие того, что слишком большой получается длина структурного пути, выражаемая числом узлов, через которые проходят пакеты. Регулярные структуры позволяют существенно сократить путь. Колечки с & узлами РСИ соединены переключателями в я-мерные структуры, которые содержат: Уг = кп — геометрических узлов.При к > 2 образуются регулярные структуры, удобные для применения на практике, причем для больших систем ценны кубы и гиперкубы. Критическим параметром, влияющим на величину производительности такой системы, является расстояние (количество связей) между процессорами.
Рис.
2.12. Схема соединения процессоров в виде
плоской решетки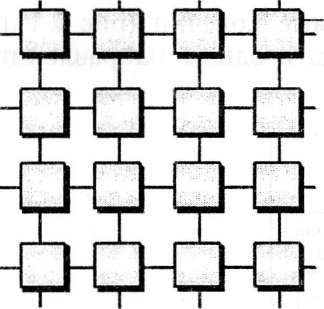
Поэтому для узловой системы используют куб (если число процессоров равно 8) или гиперкуб, если число процессоров больше 8 (см. рис. 2.13).
Так, для соединения 16 процессоров потребуется четырехмерный гиперкуб, который получается за счет сдвига обычного куба.
4-мерный
гиперкуб
Рис.
2.13. Пример гиперкуба
Используются и другие топологии сетей связи: трехмерный тор, "кольцо", "звезда" и другие (рис. 2.14).
Наиболее эффективной является архитектура с топологией "толстого дерева" (fat-tree). Архитектура "fat-tree" (hypertree) предложена Лейзерсоном (Charles Е. Leiserson) в 1985 году.
Процессоры локализованы в листьях дерева, в то время как внутренние узлы дерева скомпонованы во внутреннюю сеть. Поддеревья могут общаться меж^у собой, не затрагивая более высоких уровней сети (рис. 2.15).
В кластерах, как правило, используются операционные системы, стандартные для рабочих станций, чаще всего свободно распространяемые — Linux, FreeBSD, вместе со специальными средствами поддержки параллельного программирования и балансировки нагрузки. При работе с кластерами, так же как и с МРР-системами, используют Massive Passing Programming Paradigm — парадигму программирования с передачей данных (чаще всего — МР1).
В последнее время все более широкое распространение получают транспьютеры, из которых строят системы класса Б. Транспьютер является однокристалльной системой, содержащей процессор и оперативную память. Для объединения транспьютеров в систему используют механизмы связи (линки), являющиеся встроенными специальными средствами обмена сообщениями. Поскольку линки различных транспьютеров совместимы, то через коммутационную матрицу можно конфигурировать системы различной мощности.
Действие ряда отрицательных факторов снижает реальный коэффициент ускорения вычислений за счет выполнения параллельных операций. К этим факторам относятся:
недостаточный параллелизм алгоритма, т. е. отсутствие полной загрузки процессоров. Известно не так много алгоритмов, в которых при их выполнении число параллельных ветвей сохранялось бы достаточно большим. Поэтому для эффективного использования ресурсов в таких системах целесообразно одновременно выполнять несколько разных программ)
конфликты и задержки при обращениях к общей памяти. При назначении каждому процессору локальной памяти снижается коэффициент использования памяти;
большие расходы по организации синхронизации между взаимодействующими потоками.
Дальнейшее развитие архитектур MIMD связывается с комбинированием различных принципов вычислений. Наиболее эффективным является объединение архитектур MIMD и PVP. Другим примером является архитектура НЕР-1 (Heterogenerolis Element Processor} фирмы Denelcor. Особенностью НЕР-1 является организация мультипроцессора как нелинейной системы, состоящей из группы процессоров команд, каждый из которых генерирует "свой" процесс (поток команд). Обработка множества формируемых таким образом процессов осуществляется на одном и том же арифметическом устройстве конвейерного типа в режиме разделения времени без использования коммутационной сети, что значительно снижает стоимость системы, поскольку на реализацию АЛУ обычно приходится до 60 % аппаратных ресурсов центрального процессора.
Основным недостатком MIMD-архитектур является отсутствие возможности составления программ на стандартных языках последовательного типа, в отличие от векторных суперЭВМ. Для эффективного программирования таких систем потребовалось введение совершенно новых языков параллельного программирования, таких, как Parallel Pascal, Modula-2, Occam, Ада, Val, Sisal и др., и создание новых прикладных пакетов программ.
Реализация алгоритмической структуры сильно связанных потоков требует организации принципа вычислений, отличного от фон-неймановского (управление потоком команд) и определяется как управление потоком данных (Data Flow). Этот принцип формулируется следующим образом: все команды выполняются только при наличии всех операндов (данных), необходимых для их выполнения. Поэтому в программах, используемых для потоковой обработки, описывается не поток команд, а поток данных. Отметим следующие особенности управления потоком данных, характерные для Data Flow:
команду со всеми операндами (с доставленными операндами) можно выполнять независимо от состояния других команд, т. е. появляется возможность одновременного выполнения множества команд (первый уровень параллелизма);
отсутствует понятие адреса памяти, так как обмен данными происходит непосредственно между командами;
обмен данными между командами четко определен, поэтому отношение зависимости между ними обнаруживается легко (функциональная обработка);
поскольку управление командами осуществляется посредством передачи данных между ними, то нет необходимости в управлении последовательностью выполнения программы, т. е. имеет место не централизованная, а распределенная обработка.
Таким образом, параллелизм в таких системах может быть реализован на двух уровнях:
на уровне команд, одновременно готовых к выполнению и доступных для параллельной обработки многими процессорами (при наличии соответствующих операндов);
на уровне транспортировки команд и результатов их выполнения через тракты передачи информации (реализуемые в виде сетей).
Достоинством машин потоков данных является высокая степень однородности логической структуры и трактов передачи информации, что позволяет легко наращивать вычислительную мощность.
Для рассмотренной архитектуры существует ряд факторов, снижающих максимальную производительность:
в случае, когда число команд, готовых к выполнению, меньше числа процессоров, имеет место недогрузка обрабатывающих элементов;
перегрузка в сетях передачи информации; из соображений стоимости максимальная пропускная способность сетей достигается только для ограниченного числа вариантов взаимодействия между командами, что приводит к временным задержкам.
Существенный недостаток Data Flow-машин заключается в том, что достижение сверхвысокой производительности целиком возлагается на компилятор, осуществляющий распараллеливание вычислительного процесса, и операционную систему, координирующую функционирование процессоров и трактов передачи информации. Необходима разработка соответствующих языков программирования высокого уровня и подготовка пакетов приложений для решения реальных задач.
Необходимо упомянуть, что существуют и другие классификации вычислительных систем, преследующие следующие цели:
облегчать понимание того, что достигнуто на сегодняшний день в области архитектур вычислительных систем, и какие архитектуры имеют лучшие перспективы в будущем;
подсказывать новые пути организации архитектур — речь идет о тех классах, которые в настоящее время по разным причинам пусты;
показывать, за счет каких структурных особенностей достигается увеличение производительности различных вычислительных систем; классификация может служить моделью для анализа производительности.
Скилликорн в 1989 году разработал подход, призванный преодолеть недостатки классификации Флинна. Предлагается рассматривать архитектуру любого компьютера как абстрактную структуру, состоящую из четырех компонент:
процессор команд (IP) — функциональное устройство — интерпретатор команд;
процессор данных (DP) — функциональное устройство — преобразователь данных, иерархия памяти (IM,DM)— запоминающее устройство, переключатель—абстрактное устройство связи между процессорами и памятью.
Далее рассматриваются обобщенные функции каждой компоненты в компьютере в целом, в терминах операций, связей и переключателей, что позволяет построить архитектуру машины. Так, все матричные процессоры имеют переключатель типа 1-я для связи единственного процессора команд со всеми процессорами данных. Если каждый процессор данных имеет свою локальную память, связь будет описываться как п-п. Если каждый процессор команд может связаться с любым другим процессором, связь будет описана как п-п.
Классификация Д. Скилликорна состоит из двух уровней. На первом уровне она проводится на основе восьми характеристик:
количество процессоров команд (IP);
число запоминающих устройств (модулей памяти) команд (IM);
тип переключателя между IP и IM;
количество процессоров данных (DP);
число запоминающих устройств (модулей памяти) данных (DM);
тип переключателя между DP и DM;
тип переключателя между IP и DP;
тип переключателя между DP и DP.
Например, для машин с сильно связанными мультипроцессорами, соединенными с модулями памяти с помощью динамического переключателя, при одинаковой задержке при доступе любого процессора к любому модулю памяти описание в данной классификации выглядит так:
(n, п, п-п, п, n, пхп, п-п, нет), а архитектура — так, как показано на рис. 2.16:

Используя введенные характеристики и предполагая, что рассмотрение количественных характеристик можно ограничить только тремя возможными вариантами значений: 0, 1 и я, можно получить 28 классов архитектур.
В классах 1—5 находятся компьютеры типа dataflow и reduction, не имеющие процессоров команд в обычном понимании этого слова. Класс 6 — это классическая фон-неймановская последовательная машина. Все разновидности матричных процессоров содержатся в классах 7—10. Классы 11 и 12 отвечают компьютерам типа MISD-классификации Флинна и на настоящий момент, по мнению автора, пусты. Классы с 13-го по 28-й занимают всесозможные варианты мультипроцессоров, причем в 13—20-м классах находятся машины с достаточно привычной архитектурой, в то время как архитектура классов 21—28 пока выглядит экзотично.
На втором уровне классификации уточняется описание, сделанное на первом уровне, с добавлением возможности конвейерной обработки в процессорах команд и данных.
В классификации, предложенной А. Базу (A.Basu) (рис. 2.17), делается попытка описать любую вычислительную систему через последовательность проектных решений.
На первом этапе определяется уровень параллелизма на уровне данных (обозначается буквой D на рис. 2.17 ), параллелизм на уровне команд обозначается буква О, если же компьютер способен одновременно выполнять целые последовательности команд, то рассматривается параллелизм на уровне задач — буква Т.
Второй уровень в классификационном дереве соответствует методу реализации алгоритма. Системам, использующим аппаратную (при помощи микросхем) реализацию алгоритмов целиком, например, быстрого преобразование Фурье или произведения матриц, соответствует буква Сна рис. 2.17, а системам, использующим традиционный способ программной реализации, — буква Р.
Третий
уровень конкретизирует тип параллелизма,
используемого для обработки инструкций
машины: конвейеризация инструкций (Р)
или их независимое (параллельное)
выполнение (Ра).Для
случая конвейерного исполнения имеется
в виду лишь к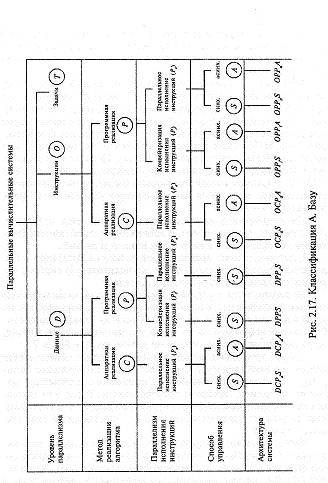 онвейеризация
самих команд.
онвейеризация
самих команд.
Последний уровень данной классификации определяет способ управления, принятый в вычислительной системе: синхронный (5) или асинхронный (А).
Таким образом, например, конвейерные компьютеры и многие современные Л/Л'С-процессоры, разбивающие исполнение всех инструкций на несколько этапов, в данной классификации имеют обозначение OPPS. К векторным компьютерам подходит обозначение DPPfi. Матричные процессоры, в которых целое множество арифметических устройств работает одновременно в строго синхронном режиме, принадлежат к группе DPPaS. Data-flow компьютеры могут быть описаны либо как ОГРА, либо как ОРР А.
I ' а
Для описания систем с несколькими процессорами, использующими параллелизм на уровне задач, операций или данных, предлагается, используя букву Т, использовать знак "*" между символами, обозначающими уровни параллелизма, одновременно присутствующие в системе. Например, комбинация T*D означает, что некоторая система может одновременно исполнять несколько задач, причем каждая из них может использовать векторные команды. Очень часто в реальных системах присутствуют особенности, характерные для компьютеров из разных групп данной классификации. В этом случае для корректного описания автор использует знак "+". Например, практически все векторные компьютеры имеют скалярную и векторную части, что можно описать как OPPS + DPPS, а описание системы с несколькими процессорами имеет вид T*(0*DPP.S + OPPS).
Ни один из рассмотренных принципов организации вычислительных систем не является абсолютно лучшим для всех прикладных областей. Более того, существуют задачи, которые являются не формализуемыми и которые нельзя представить в виде рассмотренных классических алгоритмических структур. К ним относятся: различные аспекты синтеза и распознавания речи; распознавание символов; задачи классификации объектов; субъективные процессы принятия решений (техническая и медицинская диагностика, прогнозирование на финансовом рынке); проектирование сложных объектов; сложные проблемы управления, требующие идентификации и выработки решения для систем в реальном времени; создание адекватных систем биологического зрения; моделирование функций понимания, восприятия и др. Следовательно, требуется разработка нозых принципов вычислений, позволяющих ставить и решать задачи подобного типа, а также способных значительно повысить скорость обработки традиционных вычислительных алгоритмов.
В основе любой вычислительной машины, в том числе и управляющей, лежат автоматические системы дискретного действия для переработки информации, которые в кибернетике обычно называют "автоматами" или "конечными автоматами". Эти автоматы, реализуемые в виде блоков, строятся на различных элементах. Реально вся цифровая техника может быть описана теорией цифровых автоматов. Комбинационные схемы, рассыпная логика и программируемая логика, устройства с памятью — все это конечные цифровые автоматы. Любой микроконтроллер и процессор — это тоже цифровой автомат с гигантским числом состояний, переходы в котором определяются внешней программой. Любая программа может быть составлена на основе очень ограниченного числа команд, описывающих простейшие операции, что позволяет создавать системы автоматического программирования.
Конечные автоматы имеют конечное число входов, воспринимающих информацию, и конечное число выходов для выдачи обработанной информации (рис. 2.18). Иначе говоря, цифровой автомат — это устройство, которое обрабатывает входные данные. При этом воспринимаемая и выдаваемая информация изображается символами, множество которых конечно и физически реализуемо в виде квантованных сигналов, обычно образующих последовательности уровней напряжений, соответствующих "нулю" и "единице" двоичного кода.
С другой стороны, существует большой класс устройств, которым
требуется менять свое поведение в течение времени. Последовательности сигналов поступают в квантованной шкале времени на входы автомата с некоторым запаздыванием At, обусловленным физическими свойствами работы автомата. Они вызывают на его выходах последовательности ответных сигналов. Характер действий автомата определяется организацией определенной зависимости между возбуждением его входов и возбуждением его выходов (между внешним воздействием и реакцией), которая задается предписанным алгоритмом переработки информации. Образуются обратные связи в устройстве, которые определяют переход в новое состояние (рис. 2.19).
Взаимодействие между блоками УВМ (различными конечными автоматами) осуществляется устройством управления (супервизором), он также является конечным автоматом, и его действие задается предписанным алгоритмом управляющей программы.
Физическая реализация любого автомата обычно осуществляется путем соединения (коммутации) некоторого набора элементарных компонентов или элементов, осуществляющих элементарные логические или алгебраические по модулю 2 операции ("и", "'или", либо сложение и умножение по модулю 2).
Р ассмотрим
автоматы, реализующие только так
называемые детерминистские процессы
переработки информации. В этом случае
последовательности символов, вырабатываемые
на выходах автомата, однозначно
определяются входными
ассмотрим
автоматы, реализующие только так
называемые детерминистские процессы
переработки информации. В этом случае
последовательности символов, вырабатываемые
на выходах автомата, однозначно
определяются входными
последовательностями. Такие автоматы можно назвать детерминистскими в отличие от вероятностных автоматов, вырабатывающих случайные последовательности (при фиксированных входных последовательностях). В вероятностных автоматах появление того пли иного символа имеет ту или иную вероятность. Можно указать три возможных типа автомата, качественно отличающихся друг от друга в функциональном отношении. В устройствах первого типа набор выходных сигналов, вырабатываемый в момент времени t + At, зависит только от набора входных сигналов, поданных в момент времени Г, и не зависит от сигналов, поступивших на входы автомата в предшествующее время. Интервал At — время реакции автомата — остается одинаковым для всех t при любых допустимых наборах входных сигналов. Это означает, что возбуждение одних и тех же входов автомата, в какой бы момент времени оно ни произошло, всегда вызывает возбуждение соответствующих им одних и тех же выходов. Такое однозначное и неизменное во времени соответствие между наборами входных и выходных сигналов обусловливается неизменностью внутреннего состояния автомата и независимостью этого состояния от внешнего воздействия.
Устройства описанного типа называют иногда автоматами без памяти. Примером подобного устройства может служить шифратор для кодирования десятичных цифр четырехзначными кодовыми группами (рис. 2.20).
Зависимость между возбуждениями входов и выходов шифратора имеет вид. показанный в табл. 2.1.

В автоматах второго типа набор выходных сигналов, вырабатываемый в некоторый квантованный момент времени, зависит не только от сигналов, поданных в тот же момент (здесь, как и в дальнейшем изложении, удобно полагать, что At = 0), но и от сигналов, поступивших ранее. Эти предшествующие внешние воздействия (или их фрагменты) фиксируются в автомате путем изменения его внутреннего состояния. Реакция такого детерминистского автомата однозначно определяется
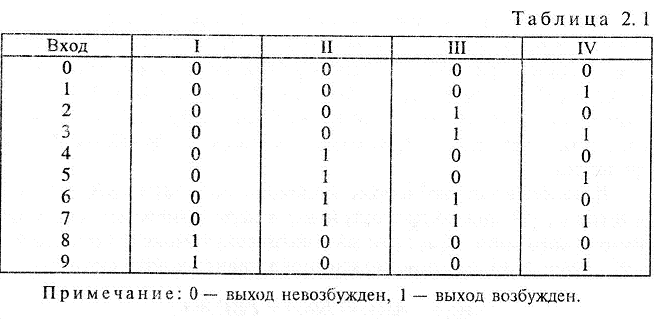
поступившим набором входных сигналов и его внутренним состоянием в данный момент времени. Этими же факторами однозначно определяется и то состояние, в которое автомат переходит. Представляется очевидным, что, поскольку любое физически реализуемое устройство может состоять лишь из конечного числа элементов, оно может пребывать в конечном числе функционально различимых состояний, трактуемом как объем (внутренней) памяти. Таким образом, мы естественно приходим к понятию конечного автомата как объекта, имеющего конечное число внутренних состояний и конечное число входов, работа которого носит детерминистский характер в указанном выше смысле.
Простым примером конечного автомата является устройство, преобразующее последовательность единиц, поступающих в квантованной шкале времени на его вход, в некоторую периодическую последовательность, например, вида 100 100 100... Очевидно, что в этом случае автомат должен обладать тремя различными внутренними состояниями.
Если конечный автомат снабдить внешней памятью и постулировать допустимость ее неограниченного расширения, то такая система будет принадлежать к автоматам третьего типа, называемым машинами Тьюринга. А. Тьюринг показал, что с помощью автомата этого типа может быть реализован любой алгоритм переработки информации. Изучение машин Тьюринга представляет большой интерес с точки зрения теории алгоритмов.В теории автоматов наибольшее внимание уделяется изучению конечных автоматов второго типа, поскольку они составляют основу практически реализуемых систем для обработки дискретной информации, в том числе и вычислительных машин (компьютеров, микроконтроллеров и др.). Автоматы первого типа могут рассматриваться как частный случай конечных автоматов.
В наиболее общей форме конечные автоматы (КА) в соответствии с [9] можно рассматривать как динамические системы логического типа. При этом математическую модель произвольной логической системы можно представить в виде системы:

где
x(t),
y(t),
u(t),
z(t)
— двоичные [0,1 ] векторы;
А, В, G,
D,
F,
К H—
двоичные
[0,1] матрицы;
A
— квадратная не особенная;
г,
s,
q
— постоянные
двоичные [0,1] векторы; t
= 1,2, 3, ..., Т— параметр целого типа; ![]() — оператор сложения по модулю 2 (mod2).
— оператор сложения по модулю 2 (mod2).
В выражении (2.1) оператор & означает, что компонентами вектора z(t) являются логические (или алгебраические по mod 2) произведения компонент вектора x(t), номера которых задаются ненулевыми (единичными) значениями компонент матрицы К. Таким образом, компонентами вектора z(t) являются конъюнкции из компонент вектора x(t).
П![]() ри
отсутствии аргумента
t
система (2.1) переходит в алгебраическую
форму:
ри
отсутствии аргумента
t
система (2.1) переходит в алгебраическую
форму:
В![]() этом случае анализ КА сводятся к анализу
и решению системы:
этом случае анализ КА сводятся к анализу
и решению системы:
где А — прямоугольная двоичная матрица размерностью [п,т], п>т; S— фундаментальный вектор логической системы [9] размерностью я; b — двоичный вектор размерностью n. Основная задача состоит в TOW, чтобы найти матрицу, псев¬дообратную матрице А. Решение системы (2.3), в которой пере¬менных больше чем уравнений, приводит к множеству решений. Поэтому псевдообратная матрица не является единственной. Полный набор псевдообратных матриц определяет полный на¬бор допустимых векторов решения.
О![]() дним
из методов решения является метод,
аналогичный методу исключения Гаусса
при решении линейных систем алгебраических
уравнений с вещественными числами. Суть
метода состоит в сложении уравнений
для исключения переменных, входящих в
эти уравнения. Эффект поглощения членов
уравне¬ний в результате их сложения по
mod 2 связан с выполнением одной из аксиом
алгебры Жегалкина:
дним
из методов решения является метод,
аналогичный методу исключения Гаусса
при решении линейных систем алгебраических
уравнений с вещественными числами. Суть
метода состоит в сложении уравнений
для исключения переменных, входящих в
эти уравнения. Эффект поглощения членов
уравне¬ний в результате их сложения по
mod 2 связан с выполнением одной из аксиом
алгебры Жегалкина:
Процедура заключается в преобразовании матрицы А так, чтобы в результате сложения строк матрицы по правилам элементарных преобразований по mod 2 результирующая матрица имела бы минимальное число ненулевых элементов. Это и есть решение.
С каждой компонентой х. вектора х может быть связан вектор, названный вектором атрибутов ха. Например, значениями атрибутов могут быть: ха(/, 1) — значение "/'"-й компоненты вектора х, тип данных — двоичный;
xa(i,2) — значение параметра t, тип данных — целый;
xa(i,3) — текст высказывания на естественном языке, с которым связана "/"-я компонента вектора х, тип данных — символьная строка;
xa(i,4) определяет, является ли высказывание "атомом" или нет, тип данных — двоичный; и т. д.
Значения "атома" имеют высказывания, которые по определению пользователя не требуют семантической (смысловой) интерпретации.
Количество компонент вектора атрибутов не является фиксированным и может изменяться в зависимости от смыслового содержания задачи.
Формализованное представление цели задачи заключается в том, что высказывания, заданные в вопросительной форме, можно интерпретировать как цели и преобразовывать их в математическую форму. Например:
задача прогнозирования, соответствующая процессу эволюции, когда надо для системы (2.1) определить дс(7) при заданных дс(0), u(t), г, s, q,
задача идентификации состояния, соответствующая процессу выявления уничтожаемых решений, когда надо для системы (2.1) определить х(0), по наблюдению y(t) за число шагов Т;
задача оптимального управления, соответствующая процессу синтеза генетического алгоритма, когда надо для системы
определить минимальное число шагов Т для перевода ее из заданного состояния дс(0) в другое заданное состояние х(Т);
прямая задача логического вывода, соответствующая процессу скрещивания решений и наследования, когда надо для системы (2.2) определить х при заданном г,
обратная задача логического вывода, соответствующая процессу корректировки и самообучения, когда надо для системы
определить г при заданном х.
Согласно существующей парадигме, перечисленные задачи относятся к классу логических задач и обычно решаются посредством так называемой дедуктивной машины логического вывода. Как отмечалось выше, недостатком этих методов является эвристический характер принятия решений.
Основным препятствием к решению перечисленных задач является их нелинейный характер, скрытый в векторе конъюнкций г. Поэтому для устранения этого препятствия предлагается системы (2.1)—(2.2) преобразовать в линейные. Возможность такого преобразования не является очевидной.
Векторы х и z являются компонентами фундаментального вектора S, а логические функции, образованные путем умножения их идентификационных строк на вектор S, являются линейными. Это и есть основание для приведения систем (2.1)— (2.2) к линейной форме.
Основным результатом решения ЛУ в линейной форме является нахождение допустимых значений двоичных переменных и функций.
Нахождение лучшего (или более корректно предпочтительного) решения из допустимых приводит к проблеме оценивания с использованием значений атрибутов переменных. При этом вначале осуществляется переход от логических переменных к численным. Затем, если все атрибуты могут быть представлены в виде метризуемых множеств, то после выбора критерия предпочтительного решения задача сводится к числовой задаче математического программирования. Методы решения задач математического программирования хорошо разработаны, поэтому сведение исходной задачи к задаче или последовательности задач математического программирования можно считать желаемой целью применительно к излагаемому нами алгебраическому подходу.
Алгоритм приведения ЛУ к форме ЛПМ включает в себя следующие шаги.
Сначала задача описывается системой ЛУ в полиномиальной форме (форме Рида — Малера — Жегалкина), отнесенной к некоторому начальному шагу алгоритма и соответствующем ему начальному вектору состояния. Затем рассматривается последовательный ряд шагов алгоритма, на которых векторы состояний выражаются через компоненты вектора начального состояния и компоненты неповторяющихся конъюнкций (термов) из этих компонент (компонент фундаментального вектора 5).
Внутренний язык задачи L в алфавите (0,1), определяющийся на первом шаге суммарным вектором начального состояния и вектором термов из компонент этого вектора, расширяется за счет термов, составленных из новых комбинаций компонент вектора начального состояния, отнесенных к различным тактам алгоритма.
Расширение исходного языка L заканчивается на такте Г, после которого на каждом новом такте не образуется новых комбинаций (сочетаний) термов из компонент вектора начального состояния. В результате исходная система ЛУ, описывающая задачу, преобразуется в расширенную систему ЛУ по форме совпадающую с системой, характерной для ЛПМ.
Рассматриваемый ниже метод, названный методом расширения пространства состояний (РПС), базируется на известных идеях расширения алфавитов операторов логических систем и наиболее близок к методам "Диагностического расширения " и "Линейного расширения конфигураций" [21]. Метод "Диагностического расширения" основан на понятиях о диагностических матрицах. Однако этот метод не дает ответа на вопрос, как в явной форме найти диагностическую матрицу для заданного оператора. Более того, в [22] делается вывод, что подобная задача, по всей видимости, относится к классу NP-полных, и поэтому поиск ее простого решения вряд ли оправдан. Формулируя определение диагностических матриц, мы преследуем совсем иную цель — "навязать" любому оператору некоторую диагностическую матрицу, не проверяя предварительно ее существование. Метод "Линейного расширения конфигураций" разработан для оценки мощности конфигураций и не решает основной проблемы сведения исходной нелинейной системы к линейной. Напомним, что под линейной системой ЛП понимается система, записанная в базисе Жегалкина. В этой системе все алгебраические операции выполняются по mod 2 и такая система не содержит конъюнкций Л П.
Приведение ЛУ к форме ЛПМ связано с применением технологии символьных преобразований. Для этих целей используются известные приемы сравнения символьных строк и подстановок, а также новые приемы матрично-векторного умножения и сложения данных типа символьной строки, компонентами которой являются целые числа, обозначающие номера слов языка L. При этом символьные строки типа полиномов Рида — Малера— Жегалкина подставляются в другие символьные строки и преобразуются за счет приведения подобных членов по правилам вычислений логических функций по mod 2 в новые полиномы.
![]()
где X(t) — расширенный, по отношению к первому словарю, двоичный вектор состояния; «(/) — вектор входа; Y(t) — вектор выхода; gy h — 0,1 векторы; А, В, С, D — 0.1 матрицы.
В качестве примера рассмотрим двоичный счетчик, который является типичным конечным автоматом простейшего вида. Его структурная схема изображена на рис. 2.21.

Откуда:
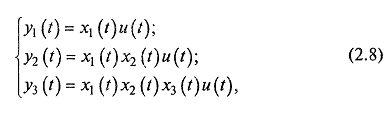
следовательно, в нем происходит замыкание КА обратной связью по состоянию.
П окажем,
как двоичный счетчик представить в
форме ЛПМ. Положим, что на вход двоичного
счетчика подаются импульсы, равные
"1", т. е.
u(t)
—
1. Пусть число двоичных разрядов равно
3, тогда
окажем,
как двоичный счетчик представить в
форме ЛПМ. Положим, что на вход двоичного
счетчика подаются импульсы, равные
"1", т. е.
u(t)
—
1. Пусть число двоичных разрядов равно
3, тогда
О бъединяя
(2.10), (2.11) и проводя преобразования по
правилам алгебры логики, получим
бъединяя
(2.10), (2.11) и проводя преобразования по
правилам алгебры логики, получим
Откуда получаем

Матричное уравнение (2.13) типично для КА в форме ЛПМ.
При каскадном наращивании структуры (2.12) двоичный счетчик можно представить в форме ЛПМ для любого числа разрядов.
Рассмотрим другой пример: приведение к форме ЛПМ системы ЛУ автономного синхронного конечного автомата.
П усть
КА описывается следующей системой ЛУ:
усть
КА описывается следующей системой ЛУ:

В результате система уравнений, описывающая КА, преобразуется в расширенную систему логических уравнений (2.19), по форме совпадающую с системой уравнений, характерной для ЛПМ. К виду ЛПМ можно привести достаточно большой класс КА. В этом случае для решения задач логического анализа придется решать уже ряд других математических задач, постановки которых являются известными, а особенности решения — исследованными. К таким задачам, в первую очередь, относятся задачи решения систем линейных уравнений с дискретными неизвестными и задачи минимизации линейной целевой функции с линейными ограничениями.
Решение задач сводимости произвольных систем логических уравнений к уравнениям линейного типа в форме известной, как линейные последовательностные машины, может быть представлено в виде обобщенной схемы. Для автономной системы такая схема может иметь следующий вид:
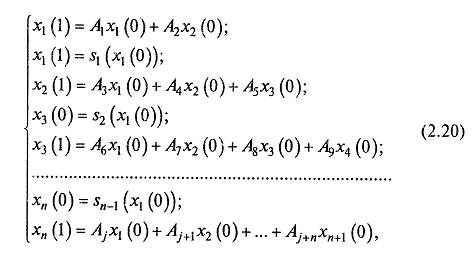
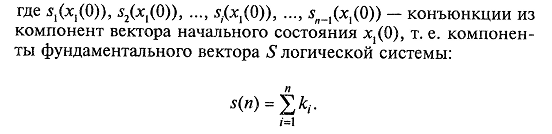
В основе излагаемого метода лежит рекурсивный прием символьного выражения последующих состояний КА через начальный вектор состояния. В результате рекурсивной подстановки символьного выражения для x(i) в x(i + 1) оказывается, что после приведения подобных членов в x(i + 1) появляются но- I вые компоненты фундаментального вектора S. Генерация каждого нового уравнения происходит при условии, что после преобразований и вычислений "А.+ " не равно нулю. Генерация уравнений прекращается при "Л.+п = 0", т. е. тогда, когда не появляется новых компонент вектора S.
В этом случае система (2.20) принимает вид:
этом случае система (2.20) принимает вид:
При AJ+n=0, число переменных в системе (2.22) становится равным числу уравнений, и матрица А превращается из прямоугольной в квадратную, а система (2.21) принимает форму ЛПМ. Число компонент фундаментального вектора S равно 2а вектор ЛГявляется линейной функцией из этих компонент, поэтому очевидно, что его размерность не превышает этой величины.
Линеаризация систем уравнений логического типа, содержащих конъюнкции из компонент вектора состояний, позволяет за счет его расширения упорядочить причинно-следственные связи в комбинаторных задачах математического программирования и сравнительно просто определить их сложность, а также оценить логическую замкнутость и непротиворечивость исходной нелинейной системы ЛУ. Модели в форме ЛПМ, в свою очередь, могут быть использованы в качестве исходных моделей для:
численного оценивания состояний и параметров динамического двоичного объекта (блока УВМ);
определения базисных и небазисных переменных вектора состояния ДО в логическом пространстве двоичных переменных; операций над символьно-полиномиальными матрицами; численного определения характеристик управляемости, наблюдаемости, идентифицируемости, контроле пригодности двоичных динамических объектов (блоков УВМ); вычисления сигнатур дискретных устройств;
обнаружения ошибок в циклических кодах; генерирования последовательности псевдослучайных чисел на основе заданного циклического кода и др.
2.3. Микроконтроллеры и микро-ЭВМ
Развитие технологических и системных решений позволило разместить на одном кристалле многочисленные функциональные блоки — процессор, память, периферию. Подобные устройства, предназначенные для решения специальных задач контроля и управления, стали называть микроконтроллерами (МК), или однокристальными ЭВМ. Широкое применение МК стимулировало работы по увеличению их возможностей, повышению степени интеграции, но при этом привело к резкому снижению стоимости (стоимость некоторых типов не превышает 1 доллара). Ориентация на применение МК позволяет сократить размеры, стоимость и сроки разработки систем управления. Сокращение числа компонентов влечет за собой повышение надежности готовых устройств, а часто для построения полноценной встроенной системы управления достаточно одного микроконтроллера. Модельный ряд микроконтроллеров, выпускаемых такими известными фирмами, как Motorola, Microchip, Intel, Zilog, Atmel и многими другими, чрезвычайно велик. При этом современные МК полностью удовлетворяют основным требования, предъявляемым к управляющим блокам. Они имеют широкие возможности интеграции в систему, высокую производительность, низкую стоимость, высокую надежность, микропотребление, выдерживают жесткие условия эксплуатации.
Все МК можно условно разделить на 4-х и 8-разрядные МК для встраиваемых приложений, 16- и 32-разрядные МК и специализированные цифровые сигнальные процессоры (DSP)
Наиболее распространенным являются 8-разрядные МК с модульной организацией, при которой на базе одного процессорного ядра выпускается целый ряд устройств, различающихся объемом и типом памяти программ, объемом памяти данных, набором периферийных модулей, частотой синхронизации. Используются таймеры, процессоры событий, контроллеры последовательных интерфейсов, аналого-цифровые преобразователи, имеющие схожие алгоритмы работы для МК различных производителей. Расширение числа режимов работы периферийных модулей задается в процессе инициализации регистров.
Структура модульного МК приведена на рис. 2.22, Процессорное ядро включает в себя центральный процессор, внутреннюю магистраль в составе шин адреса, данных и управления, схемы синхронизации и управления режимами работы.
Основными характеристиками, определяющими производительность процессорного ядра, являются набор регистров для хранения промежуточных данных, система команд процессора, способы адресации операндов в пространстве памяти, организация процессов выборки и исполнения команды.
С точки зрения системы команд и способов
адресации операндов процессорное
ядро реализует один из двух принципов
построения процессоров — с обширным
набором инструкций и относительно
медленно выполняющимися программами
(архитектура CISC —
Complex Instruction
Set Computers), и
с ограниченным набором исполняемых
команд, позволяющим увеличить скорость
работы (архитектура RISC —
Reduced Instruction
Set Computers).
Однако надо отметить, что в современных
МК сложно провести эту градацию, опираясь
на количество инструкций и скорость
их выполнения. В применении к 8-разрядным
МК процессор с CISC-архитектурой
может иметь однобайтовый, двухбайтовый
и трехбайтовый (редко четырехбайтовый)
формат команд. Время выполнения команды
может составлять от 1 до 12 циклов
синхронизации. В процессорах с
RISC-архитектурой все
команды имеют формат фиксированной
длины,
точки зрения системы команд и способов
адресации операндов процессорное
ядро реализует один из двух принципов
построения процессоров — с обширным
набором инструкций и относительно
медленно выполняющимися программами
(архитектура CISC —
Complex Instruction
Set Computers), и
с ограниченным набором исполняемых
команд, позволяющим увеличить скорость
работы (архитектура RISC —
Reduced Instruction
Set Computers).
Однако надо отметить, что в современных
МК сложно провести эту градацию, опираясь
на количество инструкций и скорость
их выполнения. В применении к 8-разрядным
МК процессор с CISC-архитектурой
может иметь однобайтовый, двухбайтовый
и трехбайтовый (редко четырехбайтовый)
формат команд. Время выполнения команды
может составлять от 1 до 12 циклов
синхронизации. В процессорах с
RISC-архитектурой все
команды имеют формат фиксированной
длины,
выборка команды из памяти и ее исполнение осуществляются за один цикл (такт) синхронизации. Система команд RlSC-npo- цессора предполагает возможность равноправного использования всех регистров процессора.
Для организации процессов выборки и исполнения команды в современных МК применяется одна из двух архитектур: фон-неймановская (принстонская) или гарвардская.
Основной особенностью фон-неймановской архитектуры является использование общей памяти для хранения программ и данных, как показано на рис. 2.23
Основное преимущество архитектуры фон-неймана — простота устройства, так как реализуется обращение только к одной общей памяти. Она является более дешевой, требует меньшего количества выводов шины. Использование единой области памяти для областей программ и данных повышает гибкость и упрощает работу при разработке программного обеспечения.
Основной особенностью гарвардской архитектуры является использование раздельных адресных пространств для хранения команд и данных, как показано на рис. 2.24. Гарвардская архитектура выделяет одну шину для выборки инструкций (шина адреса ША), а другую — для выборки операндов (шина данных ШД).
Область
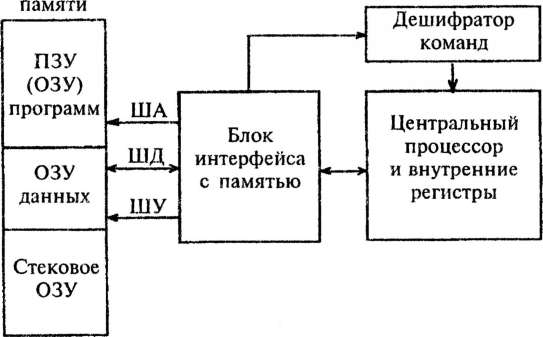
Рис. 2.23. Структура с фон-неймановской архитектурой
Память Память
программ данных
Рис.
2.24. Структура с гарвардской архитектурой
Гарвардская архитектура имеет определенные преимущества для разработки автономных систем управления. Применение отдельной небольшой по объему памяти данных позволяет сократить длину команд и ускорить поиск информации в памяти данных.
Гарвардская архитектура обеспечивает возможности реализации параллельных операций. Выборка следующей команды может происходить одновременно с выполнением предыдущей, что позволяет увеличить скорость вычислений.
Влияние архитектуры на быстродействие можно проследить на DSP-процессорах, предназначенных для высокоэффективного выполнения специализированных функций. Типичные DSP-операции требуют выполнения множества простых сложений и умножений. Анализ показывает, что для выполнения этих операций за один командный цикл необходимо осуществить два доступа к памяти одновременно для получения операндов, затем сохранить результат и прочитать инструкцию. Поэтому число доступов в память за один командный цикл при обычной организации будет больше двух. Для целей увеличения быстродействия DSP-процессоры поддерживают множественный доступ к памяти за один и тот же командный цикл. Однако невозможно осуществить доступ к двум различным адресам в памяти одновременно, используя для этого одну шину памяти. Поэтому в DSP-процессорах применяют гарвардскую архитектуру (с расширением) и модифицированную архитектура фон Неймана.
Для выполнения простейшей DSP-операции бывает недостаточно одной шины адреса и одной шины данных гарвардской архитектуры, так как в основном используются по два операнда, и необходимо произвести выборку трех компонентов — инструкции с двумя операндами, что в целом для операции требует выполнения четырех доступов к памяти — три для выборки двух операндов и инструкции и один для сохранения результата в памяти. В таком случае архитектура включает в себя кэш-память, которая используется для хранения тех инструкций, которые будут использоваться вновь. При использовании кэш-памяти шина адреса и шина данных остаются свободными, что делает возможным выборку двух операндов. Такое расширение — гарвардская архитектура плюс кэш — называют расширенной гарвардской архитектурой или SHARC (Super Harvard ARChitecture).
В некоторых процессорах применяется другой тип архитектуры, позволяющей обойти данное препятствие. Это так называемая модифицированная архитектура фон Неймана.
В настоящее время наиболее яркими представителями CISC МК и соответственно с фон-неймановской архитектурой являются микроконтроллеры i8051 фирмы Intel с ядром MCS-51, которые поддерживаются целым рядом производителей — Philips, Atmel, Siemens, Intel, Winbond, Dallas, OKI, Cygnal, МК семейств HC05, HC08 и HC11 фирмы Motorola, ряд других.
К МК с RISC-процессором с гарвардской архитектурой относятся AVR фирмы Atmel, PIC 16 и PIC 17 фирмы Microchip и другие.
Семейство х51 (МК-51, С-51) разработки фирмы Intel относится к одному из первых, нашедших самое широкое применение и послуживших основой для разработки разнообразных МК. Средства поддержки разработок для микроконтроллеров С51 чрезвычайно развиты и широко распространены. Можно подобрать набор средств разработки практически любого уровня сложности — от стартового до профессионального. Выпускаются разнообразные компиляторы с языков высокого уровня, ассемблеры, отладчики, операционные системы реального времени, отладочные платы и комплексы, внутрисхемные эмуляторы, программаторы, Многие программные средства доступны в свободных, ограниченных по времени использования, размеру кода или в просто бесплатных (GNU) версиях.
Рассмотрим особенности семейства на примере микроконтроллера 8051. Он имеет внутреннее ОЗУ объемом 128 байт, четыре двунаправленных побитно настраиваемых восьмиразрядных порта ввода-вывода, два 16-разрядных таймера-счетчика, встроенный тактовый генератор, адресацию 64 кбайт памяти программ и 64 кбайт памяти данных, две линии запросов на прерывание от внешних устройств, интерфейс для последовательного обмена информацией с другими микроконтроллерами или персональными компьютерами.
Микроконтроллер выполнен на основе n-МОП технологии. Через четыре программируемых параллельных порта ввода/вывода и один последовательный порт микроконтроллер взаимодействует с внешними устройствами (рис. 2.25). Внутренняя двунаправленная 8-битная шина связывает между собой основные узлы и устройства микроконтроллера: резидентную память программ, резидентную память данных, арифметико-логическое устройство, блок регистров специальных функций, устройство управления и порты ввода/вывода (РО-РЗ). Восьмибитное арифметико-логическое устройство может выполнять арифметические операции сложения, вычитания, умножения и деления; логические операции И, ИЛИ, исключающее ИЛИ, а также операции циклического сдвига, сброса, инвертирования и т. п. Простейшая операция сложения используется для инкрементирования содержимого регистров, продвижения регистра-указателя данных и автоматического вычисления следующего адреса резидентной памяти программ. Простейшая операция вычитания используется для декрементирования регистров и сравнения переменных. Реализуется механизм каскадного выполнения простейших операций для реализации сложных команд. Важной особенностью является способность оперировать не только байтами, но и битами. Отдельные программно-доступные биты могут быть установлены, сброшены, инвертированы, переданы, проверены и использованы в логических операциях.
70,71 — входы счетчиков внешних событий;
INT0,INT1 — запросы внешних радиальных прерываний;
RxD — вход данных последовательного канала;
TxD — выход данных последовательного канала.
Пространства частично пересекаются и образуют единую внутреннюю среду для хранения данных. Это позволяет одни и те же данные рассматривать с разных позиций (ячейка памяти, регистр, битовое поле, порт ввода/вывода и т. п.) и организовывать наиболее удобный для данного случая доступ к ним.
Пространство регистров представлено четырьмя банками регистров по 8 в каждом, а так же 16-разрядными программным счетчиком и регистром косвенного адреса, 8-разрядными аккумуляторами, указателем стека и регистром.
Программный счетчик адресует пространство памяти программ объемом до 64К байт, причем переход из области внутренней памяти программ к внешней осуществляется автоматически.
Указатель стека образует системный стек глубиной до 256 байт. Регистры каждого банка используются в качестве указателей данных. Память программ адресуется и может составлять до 64К байт, причем младшие 4 К байта могут располагаться непосредственно на кристалле, а остальные - во внешнем ЗУ. Питание МК51 осуществляется от одного источника +5В.
Командный цикл содержит один или несколько машинных циклов.
К "внешним" устройствам МК51 относятся: 4 параллельных двунаправленных порта ввода/вывода P0..P3, буфер и регистр управления последовательного канала, таймеры/счетчики с регистрами управления и режимов, другие регистры управления. В состав МК51 входит дуплексный последовательный канал связи с буферизацией, который может быть запрограммирован для работы в одном из четырех режимов. Архитектура МК51 поддерживает двухуровневую приоритетную подсистему прерываний с шестью источниками запросов. В системе команд МК-51 используются регистровая, прямая, косвенная и непосредственная адресация. Система команд включает 111 команд — 49 однобайтовых, 45 двухбайтовых и 17 трехбайтовых. Большинство двухбайтовых команд — одноцикловые, а все трехбайтовые — двухцикловые. Программная память, внутренняя память и внешняя память данных запоминают и возвращают данные в виде байтов, внутренние магистрали данных имеют 8-битный размер. При этом использование команд сложения с битом переноса и вычитание с заемом делает программирование 16-битной арифметики относительно простым.
По типу операций можно выделить следующие классы команд: пересылки; арифметические и логические; передачи управления; специальные команды.
Микроконтроллеры 51 -го семейства выпускают многие фирмы, широко распространены PIC-контроллеры фирмы I Microchip.Но они имеют ряд недостатков, система команд их ограничена (33 команды). К нестандартным МК-51 относится, например, Philips 80С552. Они имеют АЦП, таймеры, компараторы временных интервалов, ШИМ, шину PC, большое количество портов, их тактовая частота достигает 33 МГц, они допускают перепрограммирование внутри системы, что позволяет дистанционно менять программное обеспечение. МК программируются через стандартный UART, и при определенной последовательности команд можно запустить внутреннюю программу BOOTSTRAP, которая позволяет изменить коды. Есть система отслеживания провалов питания, сторожевой таймер, флэш-память большого объема — 32 или 64К байта.
Есть МК, работающие с внутренним удвоением частоты, то есть вплоть до 66 МГц. Фирма Dallas Semiconductor выпускает быстродействующие контроллеры, которые применяются в специальных разработках, где разработчикам не хочется уходить от х51, но нужна повышенная скорость, два последовательных порта и т. д. Фирма Scinex выпускает аналог PIC, но с 52-мя командами, улучшенной архитектурой. У этого МК команды выполняются вчетверо быстрее, чем у Microchip. Тактовая частота повышена до 100 МГц. По ряду характеристик они превзошли очень известные Р1С-микроконтроллеры.
В настоящее время появились и более совершенные устройства 51-го семейства.
К таким улучшенным 8-разрядным микроконтроллерам этого семейства относится 89-е МК фирмы Atmel.
Компания Atmel входит в числе мировых технологических лидеров по разработке и производству сложных изделий микроэлектроники — микросхем энергонезависимой памяти, flash-микроконтроллеров и микросхем с программируемой логикой.
Возможности компании позволяют создавать высокоэффективные изделия, в том числе микроконтроллеры, с ориентацией на конкретных потребителей рынка.
Высокая популярность микроконтроллеров архитектуры С51 производства Atmel была обусловлена удачным стратегическим решением корпорации. За счет объединения передовой Flash- технологии энергонезависимой памяти с популярным процессорным ядром Atmel первой реализовала недорогие электрически стираемые и программируемые Flash — 8x51, полностью вытеснив дорогие масочные версии С51 с ультрафиолетовым стиранием. Flash-микроконтроллеры семейства С51 имеют развитую структуру и обширный набор периферийных блоков. Появилась возможность оптимального выбора микроконтроллера с небольшим количеством внешних выводов, аналого-цифровым преобразователем, модулем таймеров/счетчиков с функцией "захват/сравнение", коммуникационными интерфейсами 12С/ uWire/SPI/UART, клавиатурным интерфейсом, массивом памяти программ до 64К и памяти данных SRAM. Выпускаются изделия, содержащие блоки CAN — интерфейса 2.0А/2.0В, МРЗ— декодера и мультимедийного интерфейса ММС для аудио приложений, интерфейса IS07816-3 для построения считывателей Smart Cards, а также специальные контроллеры для систем сбора/обработки данных. МК С51 производства Atmel поддерживают режим скоростного внутрисхемного программирования Flash- памяти программ в системе (ISP). Процесс программирования может осуществляться через различные коммуникационные каналы (SPI, UART, I2C, CAN), при этом используется рабочее напряжение питания микросхемы. Некоторые микроконтроллеры имеют специальное скоростное ядро, что означает возможность удвоения внутренней тактовой частоты процессора и/или периферийных блоков по сравнению с частотой, задаваемой внешним источником. Для отдельных кристаллов реализована возможность самостоятельно, без внешнего программатора переписывать содержимое ячеек во Flash-памяти программ, т, е. изменять алгоритм своего функционирования и далее работать уже по новой программе.
Оценить большие возможности различных современных МК можно, рассматривая другие группы изделий компании Atmel.
К ним относится MARC4 — семейство 4-разрядных однокристальных микроконтроллеров, в основу которого положено 4-битное стек-ориентированное ядро гарвардской архитектуры. Эти МК содержат до 8К памяти программ ROM, 256 бит статической памяти данных SRAM, параллельные порты ввода/вы- вода, 8-разрядный многофункциональный таймер/счетчик, супервизор напряжения, интервальный таймер с функциями сторожевого таймера и сложный тактовый генератор, блок энергонезависимой памяти данных EEPROM. Микроконтроллеры семейства имеют синхронный последовательный интерфейс SSI. Три независимые шины используются для параллельной связи между ROM, SRAM и узлами периферии. Благодаря одновременной предварительной выборке команд и передаче данных на узлы периферии, архитектура MARC4 позволяет увеличить скорость выполнения программы. Сложный контроллер прерываний имеет несколько уровней приоритета и позволяет быстро обслуживать многочисленные источники — запросы на прерывание (до 14). Низкое рабочее напряжение и малое энергопотребление, специализированная периферия идеально подходят для портативных и носимых применений с батарейным питанием, для построения считывателей Smart Cards. Для программирования микроконтроллеров MARC4 разработано программное обеспечение для платформы PC с компилятором языка высокого уровня, без потери эффективности и плотности программного кода.
Другой группой МК компании являются микроконтроллеры семейства ARM Thumb.
В архитектуре ARM используется 32-разрядное процессорное RISC-ядро с простой системой команд и высокой скоростью обработки команд. Система команд Thumb является производной от стандартной 32-разрядной системы команд ARM, перекодированных в 16-разрядные коды, что позволило достичь очень высокой плотности кода, поскольку команды Thumb составляют половину ширины формата команд ARM. Средства декодирующей логики просты. Основные достоинства ARM Thumb — высокая производительность, низкое энергопотребление и многофункциональность. Технология Thumb была лицензирована большим количеством фирм-производителей, таких как Atmel, CirrusLogic, Sharp, Samsung, Triscend и др., применяется в приемниках GPS (фирмы Mitel и SiRF), оборудовании для базовых станций GSM (Ericsson), в телефонах GSM, приложении Audio WMA/MP3 (dBTech и Microsoft), модемах (Ericsson), торговых терминалах, сетевых и многих других устройствах.
К этим МК относятся устройства 91-го семейства. Микроконтроллеры производятся по CMOS-технологии Atmel и обеспечивают оптимальное сочетание 32-разрядной производительности и малого потребления (лидируют по соотношению MIPS/ Watt).
Они содержат 32-разрядное процессорное RISC-ядро ARM7TDMI с двумя наборами инструкций — высокопроизводительная 32-разрядная система команд ARM и 16-разрядная система команд с высокой плотностью кода Thumb. МК включает встроенный аппаратный перемножитель, интерфейс внутрисхемной эмуляции, программируемый интерфейс внешней шины, контроллер данных периферии для быстрого обмена данными без участия центрального процессора, векторный контроллер прерывания с малым временем ожидания, широкий диапазон встроенной периферии, наличие различных режимов энергосбереже ния, в том числе усовершенствованный контроллер управления питанием. Диапазон напряжений питания от 1,8 до 3,6 В.
Полностью программируемый интерфейс внешней шины EBI обеспечивает прямое соединение с внешней памятью. Вось- миуровневый векторный контроллер прерываний совместно с контроллером данных периферии PDC существенно увеличивает производительность МК при работе в реальном масштабе времени.
Процесс разработки приложений на основе микроконтроллеров семейства АТ91 полностью поддерживается современными средствами проектирования (включая компиляторы языка Си, ассемблеры, отладчики, операционные системы реального времени) ведущих мировых производителей, таких как ARM, IAR Systems, GreenHills Software, Metaware, WindRiver и др. Кроме того, для этих микроконтроллеров доступны бесплатные средства разработки (GNU). Постоянно совершенствуются и аппаратные средства поддержки разработок для ARM, которые выпускаются сторонними фирмами внутрисхемные эмуляторы и отладочные комплексы.
Очень удачным является другое семейство компании — AVR микроконтроллеры. Это серия мощных и недорогих RISC МК (AVR), основанных на применяемых компанией технологических решениях и разработанном усовершенствовании 8-разрядного RISC ЦПУ с загружаемым Flash - ПЗУ. Широкие возможности приборов при их экономичности и малой стоимости (несколько долларов) обеспечили стремительный рост их практического применения. Растет число фирм, выпускающих программные и аппаратные средства поддержки разработок для этих микроконтроллеров.
AVR представляет собой 8-разрядный RISC-микроконтроллер, имеющий быстрое процессорное ядро гарвардской архитектуры с полным разделением не только адресных пространств, но и информационных шин для обращения к ROM и SRAM, Flash-память программ ROM, память данных SRAM, порты ввода/вывода и интерфейсные схемы. Такое построение напоминает структуру цифровых сигнальных процессоров и обеспечивает существенное повышение производительности. В микроконтроллерах AVR используется одноуровневый конвейер при обращении к памяти программ. Короткая команда в общем потоке выполняется всего за один период тактовой частоты. Для примера, у стандартных микроконтроллеров семейства 51 короткая команда выполняется за 12 тактов генератора, в течение которого процессор последовательно считывает код операции и исполняет ее.ВРЮ-контроллерах фирмы Microchip, где тоже реализован конвейер, короткая команда выполняется в течение 8 периодов тактовой частоты.
В рамках базовой архитектуры AVR-микрокоитроллеры подразделяются на три подсемейства:
• Classic AVR — микроконтроллеры с производительностью отдельных модификаций до 16 MIPS, FLASH ROM программ до 8 Кбайт, EEPROM данных до 512 байт, SRAM до 512 байт;
mega AVR с производительностью до 16 MIPS, с увеличенным объемом памяти, FLASH ROM программ до 128 Кбайт, EEPROM данных до 512 байт, SRAM до 4 Кбайт, аппаратный умножитель;
tiny AVR — микроконтроллеры в 8-выводном исполнении имеют встроенную схему контроля напряжения питания, Flash до 8К, EEPROM до 256.
Все микроконтроллеры AVR имеют встроенную FLASH ROM с возможностью внутрисистемного перепрограммирования и загрузки через SPI последовательный канал (до 1000 циклов стирание/запись). EEPROM данных имеет возможность внутрисистемной загрузки через SPI последовательный канал (до 100 000 циклов стирание/запись).
МК AVR являются полностью статическими приборами и могут работают при тактовой частоте от 0 Гц.
Отличительной чертой архитектуры AVR является регистровый файл быстрого доступа, содержащий 32 байтовых регистров общего назначения. Шесть регистров файла могут использоваться как три 16-разрядных указателя адреса при косвенной адресации данных, что существенно повышает скорость пересылки данных при работе прикладной программы.
Старшие микроконтроллеры семейства AVR имеют в своем составе аппаратный умножитель.
Система команд AVR весьма развита и насчитывает до 133 различных инструкций. Почти все команды имеют фиксированную длину в одно слово (16 бит), что позволяет в большинстве случаев объединять в одной команде и код операции, и операнд(ы). По разнообразию и количеству инструкций AVR больше похожи на CISC, чем на RISC-процессоры. Например, у Р1С-контролле- ров система команд насчитывает до 75 различных инструкций, а у МС-51 она составляет 111. Инструкции битовых операций включают инструкции установки, очистки и тестирования битов и развитую систему команд фиксированной 16-битной длины.
МК AVR имеют развитую периферию, включая встроенные аналоговый компаратор, сторожевой таймер, порты SPI и UART, от 1 до 4 таймеров/счетчиков общего назначения с разрядностью 8 или 16 бит, с наличием различных векторов прерываний ДЛЯ событий.
Программно отключаемый сторожевой таймер у AVR имеет свой собственный RC-геиератор, который позволяет подстраивать временной интервал переполнения таймера и сброса микроконтроллера. Десятиразрядные АЦП (до 16 каналов) с программируемым временем преобразования построены по схеме АЦП последовательных приближений с устройством выборки/ хранения. Для повышения его точности введена функция подавления шума при преобразовании.
Порты ввода/вывода AVR имеют от 3 до 53 независимых линий "Вход/Выход". Выходные драйверы обеспечивают высокую токовую нагрузочную способность — 20 мА на линию.
AVR-микроконтроллеры поддерживают спящий режим и режим микропотребления. В один из шести режимов пониженного энергопотребления МК могут быть переведены программным путем, при этом сохраняется содержимое всех регистров.
Напряжение питания МК (в зависимости от типа) от 1,8 В.
В отдельные МК встраиваются специализированные устройства (радиочастотный передатчик, USB-контроллер, драйвер ЖКИ, программируемая логика, контроллер DVD, устройства защиты данных) и др.
AVR-архитектура оптимизирована под язык высокого уровня Си. МК AVR содержат также совместимый с IEEE 1149.1 интерфейс JTAG или debugWIRE для встроенной отладки. Кроме того, микроконтроллеры megaAVR с флэш-памятью емкостью 16 К и более могут программироваться через интерфейс JTAG.
Практика работы с AVR показывает возможность простого выполнения проекта с достижением необходимого результата в кратчайшие сроки. Этому способствует наличие полного спектра недорогих инструментальных средств проектирования, выпускаемого большим числом фирм. Все приборы семейства AVR совместимы по исходным кодам и тактированию.
Программные и аппаратные средства поддержки для AVR разрабатываются параллельно с самими кристаллами и включают в себя компиляторы, внутрисхемные эмуляторы, отладчики, программаторы и простейшие отладочные платы — конструкторы, стандартные разработки и стартовые наборы.
Собственно Atmel предлагает программную среду AVR-studio для отладки программ в режиме симуляции на программном отладчике, а также для работы непосредственно с внутрисхемным эмулятором, доступным с WEB-страницы Atmel.
Самые разнообразные микроконтроллеры выпускают и другие производители.
Motorola производит микроконтроллеры под заказ с добавлением или удалением любых аппаратных средств — таймеров, портов и т. п. элементов по спецификации заказчика. Разработанные стандартные библиотеки позволяют подготавливать к выпуску и производить контроллеры с необходимыми функциями за короткое время. В соответствии с программой No excuses были выпущены МК типа KJ1, имеющие память чуть меньше, чем у стандартного 51-го, но с аналоговым компаратором, сторожевым таймером, встроенным RC-генератором. Новые серии 908JK3, JL3 имеют бит защиты, более быстрое ядро (НС08-е), электрически перезаписываемую память программ, программируемую внутрисистемно, порты с высокой нагрузочной способностью, 8-разрядный 12-канальный АЦП, 3 разных режима пониженного энергопотребления с действительно малым потреблением. Они могут активизироваться событиями типа нажатия клавиши на клавиатуре.
16-разрядные МК Futjitsu отличаются хорошим быстродействием — более 10 MIPS, развитой периферией— 3 последовательных интерфейса, 10 таймеров, АЦП, ЦАП, ШИМ, большое количество портов ввода/вывода(68или96—это нормальноеколичество), до 256 кбайт флэш-ПЗУ и 4—6 кбайт ОЗУ. Они программируются внутрисистемно. Выпускаются мощные контроллеры фирмы Toshiba-10 MIPS, 16-разрядные и 32-разрядный, с производительностью 20 MIPS. У них развитая периферия, они способны поддерживать SIMM модули памяти.Для иллюстрации широкой номенклатуры выпускаемых микроконтроллеров можно упомянуть малогабаритные (размера SOIC) 8-разрядные 8-выводные контроллеры АСЕ. К особо малым микроконтроллерам можно отнести 8- разрядные с гарвардской архитектурой PIC МК фирмы Parallax. Простейший микроконтроллер имеет 8 выводов. В некоторых микроконтроллерах есть операции умножения, деления, операции с плавающей точкой. Система команд компактная — не более 51 команды. Есть ПЗУ разных типов и периферийные устройства (АЦП, ЦАП). В составе периферийных устройств имеется несколько выводов последовательного интерфейса — обычный RS232, интерфейс PC фирмы Philips, SPI.Контроллеры PIC могут быть использованы как "умные" периферийные устройства, т. е. SLAVE — контроллер может быть подсоединен к управляющему контроллеру PIC как обычное периферийное устройство через порт (или линию данных). На основе PIC может быть организована сеть микроконтроллеров (через шину PC).
Фирма Microchip также выпускает семейство 8-выводных Flash-микроконтроллеров, которые объединили все преимущества архитектуры микроконтроллеров PICmicro и гибкость программной Flash-памяти. При низкой цене и малых размерах новые контроллеры обеспечивают функциональность и удобство использования. Основные особенности контроллеров (в зависимости от типа) серии — это диапазон питающих напряжений от 2 до 5,5 В, тактовая частота до 20 МГц, возможность включения калиброванного внутреннего RC-генератора на 4 МГц, внутренняя память данных EEPROM, аналоговый компаратор и источник опорного напряжения, до 4 каналов 10-разрядного АЦП, до 6 портов ввода-вывода с высоким выходным током (20 мА), два таймера. МК имеют режим микропотребления. В этом режиме работа ядра останавливается и потребление контроллера может снизиться до 0,9 мкА. Наличие Flash-памяти программ и средства разработки, включая внутрисхемный отладчик, а также поддержка языка Си позволяют в короткие сроки создавать программы. Основной номенклатурой микроконтроллеров фирмы Holtek Semiconductor являются 8-разрядные приборы, ориентированные на использование в самых различных областях. Эти микроконтроллеры оснащены большим количеством разнообразных функций, включая: аналого-цифровые преобразователи, сторожевые таймеры, функции остановки и сброса, таймеры, последовательные интерфейсы и т. д. Микроконтроллеры способны обеспечить гибкие и экономичные по стоимости функции управления в применения^ с LCD-дисплеями, в применениях с развитым вводом-выводом, в применениях дистанционного управления и во многих других. Выпускаются серии микроконтроллеров с расширенными функциями аналого-цифрового преобразования (тип "A/D"), микроконтроллеры для систем дистанционного управления, микроконтроллеры с расширенными возможностями ввода/вывода (тип "I/O")» USB-микроконтрол- леры для мышей, клавиатур и джойстиков.
Семейство 16-разрядных RISC-микроконтроллеров MSP430 фирмы Texas Instruments отличается низким уровнем энергопотребления. Ток, потребляемый микроконтроллером MSP430, в рабочем режиме составляет 250—400 мкА. Основная особенность семейства микроконтроллеров MSP430 заключается в том, что периферия — АЦП, таймеры, порты I/O — могут работать автономно, т. е. независимо от процессора. При отключении процессора командой "CPU Off' потребляемый от батареи ток снижается до 30 мкА, а при отключении системной частоты ток, потребляемый ог батареи, снижается до 0,8 мкА. Энергии литиевой батареи достаточно для питания прибора в течение 5 лет.
Фирма Chi peon AS выпускает микроконтроллер СС1010. Он включает в себя CMOS RF-трансивер для частот 300 -1000 МГц, интегрированный с микроконтроллером 8051. В этом МК RF-трансивер был объединен на одном кристалле со ставдартным ядром микроконтроллера 8051, включая 32 кбайт интегрированной энергонезависимой Flash-памяти, имеющей режим самопрограммирования "в системе". Однокристальный микроконтроллер СС1010 сравним со стандартным микроконтроллером Intel 8051, но имеет приблизительно в 2,5 раза большее быстродействие. Память данных на кристалле организована в виде двух блоков SRAM (128 байт и 2 кбайт). Дополнительные особенности включают трехканальный 10-разрядный АЦП, часы реального времени, опорный генератор, программируемый сторожевой таймер, два таймера 8051 и два таймера PWM, два программируемых последовательных UART, аппаратную поддержку внешнего интерфейса SPI, встроенный криптографический блок (DES) и 26 конфигурируемых выводов I/O общего назначения. К особенностям трансивера относятся очень низкое энергопотребление, высокая чувствительность, программируемая выход ная мощность передатчика, модуляция со скоростью передачи данных до 76,8 кбит/с, программируемая сетка частот, бит- синхронизация и выходной сигнал RSSI, который может быть зафиксирован встроенным АЦП. Приборы поддерживаются различными инструментами проектирования. Встроенная интерактивная система отладки поддерживается Keil ц Vision IDE через простой последовательный интерфейс. Доступна большая библиотека кодов и множество примеров применений, существуют интегрированное программное обеспечение SmartRF Studio, специальные аппаратные средства отладки и проектирования.
К микро-ЭВМ условно можно отнести разнообразные одноплатные блоки, изготовленные в определенном конструктиве и предназначенные для выполнения определенного вида операций. При их разработке ставится задача упростить конструирование законченных системы сбора, обработки информации и управления. Поэтому номенклатура выпускаемых блоков широка. Каждый блок семейства унифицирован по питающим напряжениям и виду информационных сигналов. Конструктивное исполнение блоков позволяет легко их монтировать, эксплуатировать в самых жестких условиях, обеспечивать подавляющее большинство перспективных разработок самых разнообразных технологических систем.
В качестве примера можно рассмотреть популярные изделия концепции MicroPC (разработчик и основной поставщик изделий этого формата фирма Octagon Systems).
Размеры плат MicroPC 114x124 мм, а специальная технология их изготовления обеспечивает работу при температурах от —40 до +85 °С, при вибрациях до 5g и ударах до 20g. Изделия MicroPC предназначены для работы в экстремальных условиях, а среднее время наработки на отказ (MTBF) для них составляет порядка 200 000 часов. Оборудование фирмы Octagon Systems используется на самолетах, космических кораблях Space Shuttle, подводных аппаратах, на железнодорожном транспорте, в нефтяной и газовой промышленности. Платы MicroPC не требуют принудительного воздушного охлаждения и могут устанавливаться в герметизированные корпуса. Для питания необходим единственный источник напряжения 5 В.
Изделия серии MicroPC полностью совместимы с шиной ISA, разработку и отладку программного обеспечения можно производить на обычном персональном компьютере, установив в него платы ввода-вывода MicroPC, а затем переносить готовое программное обеспечение в контроллер, где в ПЗУ находится ядро операционной системы DOS 6.22. При этом можно использовать практически любое программное обеспечение и средства разработки (например, DOS, Windows NT/95/98, QNX, Linux и др.), работающие на стандартной IBM PC платформе, или специальные инструментальные пакеты и библиотеки (UltraLogik, RTKernel и др.). Номенклатура изделий очень широка, насчитывает несколько десятков наименований, и предназначена для самых разнообразных областей применения. Диапазон процессорных плат лежит от простых и недорогих до высокопроизводительных. Например, с одной стороны, это модули центрального процессора с 8-разрядной магистралью ISA и процессором 386SX/25 МГц, памятью ОЗУ 4 Мбайт, твердотельными дисками, с DOS 6.22 и CAMBASIC в ПЗУ, последовательными и параллельными портами, поддержкой НГМД и EIDE НЖМД, с 48 каналами ввода- вывода, поддержкой сети, с другой стороны, это процессорный модуль с процессором Geode/200 МГц и ОЗУ 32 Мбайт.
В состав изделий входят многочисленные варианты плат пре образователей интерфейсов RS-232 в RS-422/485 с гальванической развязкой, модули ввода-вывода, например платы с 16-ю каналами 14-разрядных преобразователей АЦП-ЦАП, другие платы. Использование изделий упрощает наличие разнообразных принадлежностей: блоков питания, соединительных кабелей, каркасов с 8-разрядной магистралью, шлейфов, клеммных плат, интерфейсных модулей, коммутаторов сигналов, панелей релейной коммутации, модемов, матричных клавиатур, индикаторных панелей и адаптеров и т. п. В этом формате выпускаются промышленные файл-серверы, одноплатные компьютеры для мобильных применений, специализированные процессоры с каналами АЦП и ЦАП.
Хотя в настоящий момент эти устройства испытывают сильную конкуренцию со стороны микроконтроллеров, широкая номенклатура плат, отработанные методы программирования делают их использование в ряде случаев оправданным.
Если изделия в формате MicroPC привлекают широкой номенклатурой плат устройств ввода-вывода, то изделия фирмы Advantech представляют интерес как современные мощные малогабаритные компьютеры и контроллеры промышленного исполнения, как IBM PC совместимые одноплатные технологические контроллеры управляемых ОС РВ QNX.
В номенклатуру продукции фирмы Advantech, насчитывающую несколько сотен наименований продукции, входят промышленные компьютеры с шиной CompactPCI, позволяющие показать хорошие результаты в сфере обработки больших потоков данных, там, где имеется возможность полностью реализовать ее основное достоинство — высокую пропускную способ ность. Базовые конструктивы для изделий позволяют производить "горячую" замену модулей и охлаждающих вентиляторов, оснащаются источником питания формата АТХ (возможно также использование резервных модулей питания) и системой контроля параметров функционирования системы, включая контроль исправности источника питания, температуры внутри корпуса, скорости вращения охлаждающих вентиляторов. Еще один продукт фирмы Advantech — так называемые панельные компьютеры. Их развитие идет в направлении увеличения размеров плоскопанельных дисплеев по диагонали (свыше 15 дюймов), а также перехода на более мощные процессоры. Производится промышленный панельный компьютер IPPC-950, смонтированный на шасси из нержавеющей стали и оснащенного ярким 15-дюймовым TFT-дисплеем.
Следует отдельно упомянуть о целой группе компьютеров для встраиваемых применений (как в формате BiscuitPC. так и с шиной ISA), предлагаемой пользователям с предустановленной операционной системой Windows СЕ v2.Q. Эта ОС, сочетающая стандартный интерфейс с возможностью загружаться и работать с твердотельного диска небольшого объема, подходит не только для портативных компьютеров класса palmtop, но и для оборудования информационных киосков, торговых терминалов и т. д. В ближайшее время ожидается выход новой версии Windows СЕ v3.0, которая будет работать в режиме реального времени, что позволит использовать ее в системах управления.
К настоящему моменту фирма Advantech импортировала Windows СЕ в одноплатные компьютеры BiscuitPC на базе процессоров Pentium (РСМ-5862, РСМ-5820), в одноплатные компьютеры половинного размера с шиной ISA (РСА-6154, РСА- 6145). При этом ОС находится на флэш-диске типа DiskOnChip 2000 фирмы М-Systems емкостью 12 или 16 Мбайт, половина которого отведена для программ пользователя.
Продолжая рассмотрение одноплатных компьютеров, можно отметить изделия фирмы Siemens, предназначенные для экстремальных условий работы в составе технологических систем. Это центральные блоки типа Ecooline (три варианта ЦПУ) для промышленных микрокомпьютеров с рабочей температурой до 75 °С. CPCI-/SMP16-CPU076 Basic Ecooline оснащен процессором на 400 МГц, версия Professional — на 650 МГц, и версия Superior — на 933 МГц. Новые ЦПУ используются в автоматах, в серийных и специальных станках, а также для встроенных систем автоматизации. Оснащение платы памятью SDRAM на 128 Мбайт и Flash- Eprom на 1 Мбайт позволяет строить компактные системы шин Compact-PCI (CPCI), системы SMP16 или смешанные системы из CPCI и SMP16. В качестве операционных систем имеются Windows NT, ХР, а также MS-DOS, а для жестких требований работы в реальном режиме времени есть операционная система RMOS3. В распоряжении имеются разнообразные интерфейсы, например для управления двумя дисководами на гибких дисках и четырьмя жесткими платами EIDE, соответствующие интерфейсы для клавиатуры/мыши (комбинированные), по два гнезда USB на лицевой и тыльной стороне, два параллельных интерфейса RS232, а также выход Ethernet на 10/100 Мбит/с.
Другим примером современного мощного одноплатного компьютера является низкопрофильный CPCI-786 (Motorola Computer Group). Он комплектуется двумя процессорами Pentium III с низким энергопотреблением, разработан специально для систем, соответствующих спецификации PICMG 2.16 - CompactPCI Packet-Switching Backplanes (cPSB). Этот одноплатный компьютер предназначен как составная часть при построении систем для телекоммуникационных приложений — таких, как поддержка web- узлов, поисковые системы, хранение данных, и других интернет-ориентированных приложений.
Он представляет собой одноплатный компьютер для 64- бит- кош системного слота. Может работать в периферийных слотах как изолированный модуль (без связи с другими периферийными модулями), так как шина CPCI модуля CPCI-786 изолирована от кросс-платы). Компьютер имеет:
два процессора Pentium III с низким энергопотреблением;
один слот РМС, 64 бита для специфических адаптеров, требуемых приложением;
2 Гб оперативной памяти SDRAM с ЕСС (по заказу — до 4 Гб);
флэш-память 32 Мб (интегрированный IDE флэш-диск);
удаленное администрирование (P1CMG 2.9);
соответствие полной спецификации Hot Swap (PICMG 2.1, R2.0);
два порта 10/100 Мбит Ethernet;
частоту системной шины 133 МГц;
два порта USB;
два порта СОМ;
порт клавиатуры/мыши;
удаленное администрирование (PICMG 2.9);
защиту от перепадов напряжения и короткого замыкания по току;
энергопотребление 40 Вт (max) для процессоров Pentium III с пониженным напряжением питания.
По спецзаказу может комплектоваться жестким диском (2.5", АТА100). Его рабочая температура: 0—55 °С.
Таким образом, в настоящее время имеется большое разнообразие микроконтроллеров и микро-ЭВМ различных фирм и стоимостной шкалы для использования в системах управления малой и средней сложности.
2.4. Персональные вычислительные машины
и суперкомпьютеры
Персональные вычислительные машины (PC) для систем управления, как и любая УВМ, содержат системный блок и периферийное оборудование, отличающиеся большим разнообразием функциональных возможностей и конструкторского исполнения. Можно выделить следующие характерные компоненты системного блока: корпус; материнская плата; процессоры; сопроцессоры и ускорители; оперативная память (ОЗУ); флэш-память и постоянное запоминающее устройство (ПЗУ); контроллеры ввода-вывода; порты ввода-вывода; встроенные подсистемы, в том числе графические; флоппи-контроллер; жесткие диски (винчестер); устройства чтения оптических CD и DVD; сетевые и интерфейсные адаптеры; аналого-цифровые и циф- роаналоговые преобразователи; системы охлаждения (вентиляторы); системы питания (блок питания и аккумулятор); индикаторы состояния; выключатели и переключатели режимов.
Рассмотрим характеристики основных компонентов.
Материнская плата помещается в корпус системного блока и служит для размещения и коммутации основных модулей (блоков) системного блока. Ее параметры и характеристики существенно влияют на надежность и производительность PC.
Процессоры являются основным элементом PC, отвечающим за ее функционирование в соответствии с выполняемыми программами.
Центральной частью PC являются центральный процессор (ЦП), память, системная плата и периферийные устройства, включающие устройства хранения данных, ввода-вывода, коммуникационные и прочие. Процессор, память и периферийные устройства взаимодействуют между собой с помощью шин и интерфейсов, аппаратных и программных. Процессор взаимодействует с набором ячеек памяти и регистров устройств. Сигналы прерываний от ЦП могут вызвать изменения в последовательности исполняемых инструкций. Вместо прерываний возможен опрос состояния ЦП (полинг) в сочетании с прерываниями. В PC также можно выделить две глобальные категории архитектур процессоров — CISC и RISC.У PC, как и у МК CISC (Complete Instruction Set Computer), — это процессоры с полным (сложным) набором инструкций. Регистры существенно неоднородны, имеется широкий набор команд разной длины, что усложняет декодирование инструкций и на что расходуются аппаратные ресурсы. Это ведет к росту числа тактов, необходимых для выполнения инструкций. RISC (Reduced (Restricted) Instruction Set Computer) — это процессоры с сокращенной системой команд. Они имеют набор большого числа однородных регистров универсального назначения. Система команд относительно простота, коды инструкций имеют четкую структуру, как правило, с фиксированной длиной. Аппаратная реализация проста, легко конвейеризируется.
Рассмотрим организацию процессоров на примере семейства процессоров х86. Они имеют сложную адресацию и управление доступом к памяти. В реальном режиме адресация памяти в пределах 1 Мб через 16-битные регистры (РОН и сегментные регистры). Сегменты по 64К, перекрывающиеся, незащищенные, сворачивающиеся через нуль. Ввод-вывод 64 К. В защищенном режиме виртуальных адресов у него сложная система адресации памяти с защитой. Сегменты (до 64 К или 4Гб для 16/32-разрядных процессоров) управляются (положение, размер, права доступа) дескрипторами через селекторы. Сегментная организация памяти (сегмент — это логическая организационная единица) обеспечивает увеличение адресуемого пространства и перемещаемость кода и данных и ее защиту, а так же и виртуальность. У них плоская модель памяти, когда все сегментные регистры используют один и тот же селектор (сегмент). Для ввода-вывода используются отдельные пространство и инструкции. Прерывания могут быть аппаратные (маскируемые и немаскируемые), программные и внутренние. Форматы данных: целые (байт, слово, двойное) со знаком и без, строки, биты, битовые строки. Сегментная защита памяти обеспечивает проверку назначения (данные-код), прав доступа (RO, привилегии), выход за границы, изменение параметров сегментов без прав. Защита ввода-вывода осуществляется с помощью карты разрешения. Основа защиты — сегментация памяти, на которой можно строить и виртуальную память до 64 Тбайт (16 к сегментов по 4 Гбайт).
Обеспечивается многозадачность (ради нее и введена защита) за счет возможности быстрого переключения контекста загрузкой TR. Сегмент состояния задачи (TSS) обеспечивает автоматическую перезагрузку всех регистров, кроме FPU/MMX/XMM. Там же имеется карта разрешения для портов ввода-вывода.Используется страничное управление памятью как средство организации виртуальной памяти с подкачкой страниц по запросу. Линейный адрес делится на страницы фиксированного размера (4к, 4М, 2М), которые могут присутствовать в ОЗУ или нет. Элементы каталогов и таблицы следующие: базовый адрес (если есть) и атрибуты: присутствие, R/W, U/S (2-ур защита), управление кэшированием. Таблицы каталогов и страниц должны быть в ОЗУ (иначе двойной отказ — исключение). Введено кэширование описателей — буферассоциативной трансляции (TLB Translate Look-Aside Buffer), в котором хранятся последние используемые описатели. Страничное управление позволяет использовать 36 бит физического адреса. Обеспечено кэширование памяти. Длина строки для Р 486 — 16 байт, для Р5-Р6 — 32 байта, для Р4 — 64 байта.
Имеются прерывания в защищенном режиме, т. е. переключение задач. При этом задачи должны иметь возможность сообщать о прерываемом или нет состоянии, но им нельзя давать прямое управление флагом. В V86 программные прерывания (вызовы сервисов DOS и BIOS) влекут переключение задач. В EV86 —- модификация режима и возможность перенаправления программных прерываний на обработчик в той же задаче.
В микроархитектуре процессоров семейства Pentium существенное значение имеет реализация различных способов конвейеризации и распараллеливания вычислительных процессов, а также других технологий, не свойственных процессорам прежних поколений. Процессоры Intel — Pentium 4 (у AMD — Athlon) целенаправленно разрабатывались в направлении развития конвейеризации и потоковости работы.
Конвейер Pentium 4 состоит из 20 ступеней. Возможности распараллеливания архитектурой х86 ограничены, так как 8 неравноправных регистров не располагают к программированию с учетом параллельности исполнения.
Основные особенности процессоров Pentium следующие.
Подсистема памяти содержит системную шину, кэш 1 и 2 уровня, блок интерфейса памяти, блок переупорядочивания обращений к памяти.
Блок выборки/декодирования содержит блок выборки инструкций, буфер целевых адресов переходов, декодер инструкций, секвенсор микрокодов и таблицу переименования регистров NetBurst (микроархитектура процессора Pentium 4) и ориентирован на такие новые задачи, как потоковые приложения, включая обработку видеоинформации в реальном вре мени, трехмерная визуализация; распознавание речи — SSE2 (2*64 бит FP в ХММ, новые целочисленные в ММХ и ХММ, управление кэшированием, загрузка в обход кэша).
Процессор (рис. 2.26) имеет гиперконвейерную архитектуру: 20 ступеней от выборки из трассы кэша, не считая декодирования и вывода (тогда 30—35).
Процессор вместо первичного кэша инструкций имеет кэш трасс исполнения ТС (Execution Trace Cache). Трассы — это последовательности микроопераций, в которые были декодированы инструкции х86. Кэш трасс плюс блок выборки и декодирования — это устройство предварительной обработки, обеспечивающее: предварительную выборку инструкций; декодирование инструкций в микрооперации; генерацию последовательностей микрокодов для сложных инструкций;
доставку декодированных инструкций из кэша трассы; предсказание переходов с использованием "продвинутого" алгоритма.
NetBurst позволяет сократить задержки декодирования инструкций с целевого адреса, указанного в переходе, а также потери производительности декодеров в случаях, когда точка перехода или целевой адрес находятся в середине строки кэша. Последовательность микроопераций хранится в кэше трассы в порядке потока исполнения.

Поэтому не надо прыгать по стро кам кэша при ветвлении. В память кэша трассы не попадают инструкции, которые никогда не будут исполняться. Кэш трассы способен хранить до Г2К микроопераций и за каждый такт доставлять ядру до трех микроопераций.
Кэш трасс и транслирующий механизм кооперируются с аппаратурой предсказания ветвлений. Целевые адреса ветвлений предсказываются по своим линейным адресам. Если целевая инструкция уже имеется в кэше трасс, то ее готовая последовательность микроопераций берется из ТС. Если ее в кэше нет, то приходится инструкцию выбирать из иерархии памяти (вторичного кэша (на кристалле процессора) или ОЗУ) и декодировать.
Для предсказания ветвлений используется комбинация статических и динамических методов, а также прямые указания программного кода. По сравнению с Р6 размер буфера ВТВ увеличен в 8 раз (теперь он хранит до 4 К адресов инструкций ветвлений). "Намеки" используются только на этапе построения трасс, и если в ВТВ данной инструкции еще нет, они перекрывают статическое предсказание.
Исполнительное ядро процессора имеет пиковую пропускную способность, превышающую возможности блока предварительной обработки и блока завершения (до 6 микроопераций за такт).
Блок завершения выполняет до трех микроопераций за такт.
В Pentium 4 с частотой 3,06 ГГц и в Хеоп внедрена технология Hyper-Threading. Она обеспечивает 2 логических процессора на 1 физическом и повышение производительности и коэффициента загрузки блоков. Есть общие и выделенные ресурсы. Требует поддержки BIOS, ОС и приложений (пустой цикл блокирует второй поток). Доступные ОС лицензированы на 2 SMP.
Процессор Pentium 4 содержит 42 миллиона транзисторов и имеет:
системную шину с частотой 800 МГц при частоте генератора 3 ГГц;
системную шину с частотой 533 МГц при генераторах: 3,06 ГГц, 2,80 ГГц, 2,66 ГГц, 2,53 ГГц, 2,40В ГГц, 2,26 ГГц;
системную шину с частотой 400 МГц при генераторах: 2,60 ГГц, 2,50 ГГц, 2,40 ГГц, 2,20 ГГц, 2А ГГц, 2 ГГц, 1,90 ГГц, 1,80 ГГц, 1,70 ГГц;
кэш L2 - 512 Кб (у Celeron - 128 Кб).
Компания AMD выпускает процессор Athlon. Производительность у него достигается не только высокой тактовой частотой, но и особой суперконвейерной суперскалярной микроархитектурой. Преимущества процессора Athlon проявляются на приложениях, использующих интенсивные вычисления (особенно с плавающей точкой) и, естественно, оптимизированных под расширенную систему команд.
Процессоры Athlon ХР имеют микроархитектуру QuantiSpeed. У них повышенная рабочая частота и больше инструкций за цикл. Процессор Duron — это облегченный вариант Athlon (кодовое название — Spitfire). У него вторичный кэш, уменьшенный до 64 кбайт, но работающий на частоте ядра, располагается на кри сталле ядра.
В процессорах применяется системная шина EV6, использованная в процессоре Alpha (DEC) (200—400 МГц, 1,6 Гбайт/с), Протокол шины EV6 поддерживает многопроцессорность, что является новинкой для AMD, так как ее предыдущие процессоры мулыипроцессирование не поддерживали.
Другие процессоры AMD на ядре Hammer — это Athlon 64 (для настольных и мобильных) и Opteron (для серверов 1—8 SMP и рабочих станций 1—4 SMP). У них:
удвоена разрядность, есть совместимость, введены дополнительные РОН;
ядро процессора L1 имеет кэш 64+64 К, L2 — 1 М (256 К у Athlon-64), а также параллельность, микроинструкции и др.;
интегрированный контроллер памяти DDR РС2100—2700, Opteron —128 бит, Athlon — 64 бит, 256 Тбайт;
шина ввода/вывода на основе технологии Hyper Transport: последовательно-параллельная шина, программно хорошо стыкуется с PCI, от процессора 16 бит — 6,4 Гбайт/с, после "туннеля" 8 бит — 3,2 Гбайт/с и AGP (2 Гбайт/с), адресация 40/ 64 бит. В серверном варианте 3*16 бит — 19,2 Гбайт/с.Процессоры архитектуры RISC (Power PC, MIPS, SPARC, и др.) имеют "упрощеные" системы команд не по выполняемым операциям, а по сложности и регулярности. У них фиксированная длина инструкции, много РОН, операции в регистрах, с памятью только пересылки, нет инструкций со сложной адресацией. Они легче конвейеризируются, распараллеливаются, разгоняются. На архитектуру 32/64-битных RISC-процессоров имеется открытый стандарт SPARC (Scalable Processor Architecture.
Можно указать следующие известные RISC-процессоры:
High End — UltraSPARC IIICu для мощных серверов (до 100- процессорных);
Mid Range — UltraSPARC Illi для 2-4 SMP (и однопроцес-сорных);
Blades — UltraSPARC II — сервер на одном кристалле.
Мультипроцессорные системы — это объединение нескольких ЦП с общей памятью, что обеспечивает надежность (FRC) и производительность (SMP). В FRC два процессора соединяются параллельно, шиной управляет 1-й (Master), 2-й (checker) проверяет шинные операции, если находит несоответствие, то дает прерывание. В SMP встает вопрос объединения процессоров, их кэшей и связи с памятью. В х86 Intel (Pentium, Pentium 4) используется общая шина, ее полоса делится между всеми CPU и памятью. У AMD Athlon EV6 — это двухточечная шина, полоса которой используется монопольно, несколько ЦП объединяются на хабе. У Athlon-64 и Opteron каждый процессор входит в систему со своим контроллером памяти, шина объединения отделена от шины памяти. По сути это уже мультикомпьютер.
В PC используются два уровня иерархии интерфейсов; системный (шины расширения ввода-вывода: ISA/EISA, PCI, PC Card, CardBus, порт AGP) и периферийный. Интерфейсы периферийного уровня связаны с системным уровнем через адаптеры и контроллеры.
Спецификой интерфейсов системного уровня в настоящее время является использование параллельных шин на системной плате, обеспечивающих тесную связь с центром (процессором и памятью), высокие требования к производительности (быстродействию), малую протяженность и требовательность к протоколу. Однако это приводит к уязвимости всего компьютера при нарушениях и к сложности отладки.
Периферийные интерфейсы изолированы от центра компьютера своими адаптерами и контроллерами, являющимися фактически регистрами ввода и вывода, обеспечивающими взаимодействие памяти и пространства ввода-вывода. Смысловые различия ОЗУ и регистров состоят в том, что память используется для хра нения, а регистры могут образовывать каналы передачи данных ! или управления. При этом недопустимы кэширования, изменения порядка физических операций и холостые чтения регистров.Прерывания — это сигнализация асинхронных событий от устройств. Они могут быть маскируемые и немаскируемые, При маскируемых прерываниях контроллер принимает сигналы запросов, передает общий запрос процессору, по INTA отвечает 1 вектором прерывания. В соответствии с вектором запускается обработчик (ISR). Если операционная система (ОС) не может идентифицировать источник, она выстраивает ISR в цепочки. Немаскируемыми прерываниями являются сообщения о фатальных ошибках, возможно, требующих перезагрузки. Стандартным для персональных компьютеров (PC) контроллером прерываний является PIC (Peripheral Interrupt Controller), а для мультипроцессорных систем продвинутым контроллером прерываний является APIC (Advanced PIC), который используется и в однопроцессорных ЭВМ. Альтернативой и дополнением прерываний может быть полинг.
Основными блоками памяти являются оперативное запоминающее устройство (ОЗУ) и BIOS (постоянное запоминающее I устройство (ПЗУ), флэш). Иерархия памяти обычно следующая: регистры ЦП, кэш, ОЗУ, устройства хранения фиксированные, устройства хранения со сменными носителями.
Элементной базой ОЗУ является структура ячейки DRAM на полевых транзисторах, которые хранят заряд в емкости за- ; твора. Однако заряд стекает, и поэтому нужна регенерация через -10 мс. Обращение к матрице хранящих ячеек производится через RAS CAS по классической временной диаграмме чтения (RAS I CAS Data). Время доступа Гс> 20 не. Для повышения производительности используется широкая шина данных (64/128 бит). Имеется режим быстрого страничного обмена FPM (Fast Page Mode). Для обеспечения некоторой конвейеризации работы, повышающей производительность при чтении, используется регистр-защелка (data latch) EDO DRAM (Extended или Enhanced Data Out). Кроме регистра-защелки выходных данных имеется еще и внутренний счетчик адреса колонок для пакетного цикла. В результате удлинения конвейера выходные данные как бы отстают на один такт от сигнала CAS#, зато следующие данные появля ются без тактов ожидания процессора, чем обеспечивается лучший цикл чтения.
Синхронный интерфейс SDRAM обеспечивает возможность подачи команд к разным банкам одной микросхемы. То же, но с удвоенной частотой передачи данных обеспечивает DDR SDRAM.
Память RDRAM (Rambus DRAM) имеет синхронный интерфейс, существенным образом отличающийся от выше описанного. Запоминающее ядро этой памяти построено на все тех же КМОП-ячейках динамической памяти, но пути повышения производительности интерфейса совершенно иные. Подсистема памяти (ОЗУ) RDRAM состоит из контроллера памяти, канала и собственно микросхем памяти. Разрядность ОЗУ RDRAM (16 байт) не зависит от числа установленных микросхем, а число банков, доступных контроллеру, и объем памяти суммируются по всем микросхемам канала. При этом в канале могут при сутствовать микросхемы разной емкости в любых сочетаниях. Если есть несколько слотов для модулей, то во всех должна быть либо память, либо заглушки (нужен непрерывный канал).
Память SMRAM — это физически изолированное пространство для процедур системного управления, таких как управление энергосбережением, эмуляция устройств (например, контроллера клавиатуры через US В).
Статическая память SRAM (Static RAM) не требует регенерации. Она быстродействующая и применяется в КЭШе (и в других местах). Плотность упаковки ниже DRAM, энергопотребление выше.
Буферы — это память для промежуточного хранения (в устройствах, контроллерах), часто FIFO (не адресуемые).
Кэш — это неадресуемая сверхоперативная (быстродействующая) память, хранящая копии некоторых блоков ОЗУ.
Масочные постоянные запоминающие устройства ПЗУ или ROM имеют высокое быстродействие (время доступа 30-70 не).
Однократно программируемые постоянные запоминающие устройства ППЗУ или PROM имеют аналогичные параметры (раньше использовали для BIOS).
Репрограммируемые постоянные запоминающие устройства РПЗУ или EPROM до недавних пор были самыми распространенными носителями BIOS.
Электрически стираемая (и перезаписываемая) память EEPROM, или E2PROM (Elecrical Erasable PROM), отличается простотой выполнения записи.
Флэш-память по определению относится к классу EEPROM (электрическое стирание), но использует особую технологию построения запоминающих ячеек. Стирание во флэш-памяти производится сразу для целой области ячеек (блоками или полностью всей микросхемы).
Кроме того, может использоваться статическая энергонезависимая память FRAM (Ferroelectric RAM).
Системная плата — это основа PC. На ней располагаются ЦП (CPU, 1-2), ОЗУ (RAM, может и с кэшем), (Г1)ПЗУ (флэш-BIOS), системная периферия (таймер, контроллер прерываний, контроллер клавиатуры, динамик), интегрированные ПУ (необязательно), шины расширения ввода-вывода, вспомогательные цепи (синхронизация, аппаратный сброс, управление питанием).
"Северная" часть системной платы содержит процессор(ы) и память, а "Южная" часть:
шину PCI, являющуюся основой расширения, и остальные шины (ISA и др.) подключаются к ней через мосты;
контроллер ATA (PCI IDE) со скоростью обмена 33/66/100/ 133 Мбайт/с (на канал) или Serial ATA со скоростью от 150 Мбайт/с;
порты USB 2.0 со скоростью 480 Мбит/с (60 Мбайт/с); другие штатные устройства (контроллеры прерываний, клавиатуры, НГМД, портов СОМ и LPT) со скоростью порядка 2 Мбайт/с.
Эволюция системных плат прошла от систем PC/XT на основе шины ISA, а на ней все, включая ЦП и контроллер DRAM до (Pentium) подключения к шине процессора контроллера памяти (с кэшем) и моста на шину расширения (ISA, EISA, PCI). При этом шина на "экваторе", (отсюда и названия "север-юг"), "север" усложнился (появился AGP) и хабовая архитектура. В данном контексте хабы (мосты) — это специализированные микросхемы, обеспечивающие передачу данных между подключенными к ним шинами.
Северный хаб (мост) определяет:
поддерживаемые процессоры, их типы, частоты системной шины, возможности мультипроцессорных или избыточных конфигураций;
типы памяти и частоту работы шины памяти; максимальный объем памяти (число слотов и поддерживаемые объемы модулей);
Число каналов памяти — чаще всего один, но бывает два канала RDRAM, чередование банков DRAM.
контроль достоверности памяти и исправления ошибок (паритет, ЕСС);
наличие и возможности порта AGP;
возможности системы управления энергопотреблением (ACPI или АРМ) — реализуемые энергосберегающие режимы процессора и памяти, SMM.
Северный хаб (мост) плат для сокетов 5, 7 и Super? определяет также возможности кэша, частоты шины PCI (33 и 66 МГц), возможное количество контроллеров шины PCI (число пар сигналов арбитра PCI), способы буферизации, возможности одновременных обменов. Северный хаб на эти параметры уже не влияет, поскольку PCI подключается к южному хабу.
Южный хаб чипсета обеспечивает подключение шин PCI, ISA (но уже не всегда), АТА (2 канала), USB, а также "мелких" контроллеров ввода-вывода, памяти CMOS и флэш-памяти с системной BIOS. В южной части располагаются таймер (8254), контроллер прерываний (совместимый с парой 8259 или APIC), контроллер DMA для шины ISA и периферии системной платы. Если в чипсет интегрирован и звук, то южный хаб (мост) имеет контроллер интерфейса AC-Link для подключения аудиокодека, а то и сам аудиокодек, а также контроллер SMBus.
Флэш-память BIOS подключается к специальному хабу (Firmware hub), соединяемому с южным хабом отдельной шиной (аналогичной LPC).
Чипсет обеспечивает взаимодействие множества шин, большинство которых синхронные. У синхронного чипсета все часто ты жестко связаны между собой с коэффициентами 1:1, 1:2, 2:3.Асинхронный чипсет обеспечивает возможность относительно произвольного задания частот системной шины, шины памяти, порта AGP, шины PCL.
Интерфейсы системного уровня, самые близкие к центру (процессору и памяти) обеспечивают доступ к их абонентам непосредственно инструкциями процессора. Абоненты отображаются на пространстве памяти (Mem) и ввода/вывода (10); могут сами, управляя шиной, получить доступ к памяти и другим устройствам. В адресации используются физические адреса, формируемые процессором (после страничного преобразования логического адреса). Конструктивно — это параллельные шины на системной плате, со слотами для карт расширения (шины расширения ввода-вывода). Есть и непосредственно подключенные абоненты (интегрированная периферия).
Все абоненты всех шин расширения должны занимать непересекающиеся адреса в допустимых диапазонах Mem, I/O (между собой и с ОЗУ-ПЗУ). У каждого имеется свой дешифратор адреса, программируемый механически (джамперы) или программно. Задача распределения ресурсов — это опрос потребностей, выбор распределения, конфигурирование устройств, сообщение настроек заинтересованному ПО. Для ее решения требуется возможность селективного обращения (без помех) к каждому устройству на стадии конфигурирования. При нормальной работе — это просто обращения по адресам (Mem, I/O). Шин расширения может быть несколько, все они связаны мостами с хостом (друг через друга). Мосты программируются, после чего обеспечивается прозрачность.
Транзакция — это элементарная операция на шине (обмен данными по адресу). В каждой транзакции есть инициатор (задат- чик, master) и целевое (ведомое) устройство (target). Инициатор задает адрес и тип операции и в операциях записи передает данные. Целевое устройство опознает адресованные к нему транзакции, принимает данные записи, передает данные в чтении.
К первому поколению шин ввода-вывода относится ISA(Industrial Standard Archtecture) — асинхронная параллельная шина без обеспечения надежности и достоверности, без автоконфигурирования. В первых IBM PC она была системной шиной (к ней подключались и CPU с памятью), потом стала шиной расширения. Происхождение ведет от microbus/multibus i8080-8088 и их периферийных ИС. Исходно ISA-8 (62-контактный слот), а начиная с PC/AT и до сих пор-- ISA-16 (с дополнительным 18-контактным слотом) имеют раздельные шины адреса, данных и управления, асинхронный обмен (привязка к сигналам шины управления), maxV = 8 Мбайт/с (PIO, 16 бит).
Шина данных имеет 16 бит с возможностью 8-битных обменов (16-битный обмен запрашивается устройством явно). 32- и 16-битные транзакции от инструкций процессора разбиваются на 8-, 16-битные в соответствии с возможностями устройства и выравненностью адреса, порядок адресов в 386+ зависит от положения относительно границы 32-битного слова. Не рекомендуются 16(32)-битные транзакции по нечетному адресу.
Шина адреса имеет 24 бита для адресации 16 Мбайт памяти (0~FFFFFFh)3 устройства могут занимать OAOQQO-OEFFFFh, иногда и F00000—FEFFFFh (если в Setup включено Memory Hole). Для I/O используются младшие 16 бит (64К портов), но старые карты расширения были и с 10-битной адресацией.
Шина управления на каждый тип транзакции (R/W, Мет/ 10) имеет свой управляющий сигнал, общий сброс. Возможность программирования длительности циклов (число WS — тактов ожидания, задается по типам операций в Setup), растяжки и укорочения (0WS) по инициативе устройства. Централизованный контроллер DMA (8237А+регистры страниц) имеет 4 канала на 8-бит плюс 3 канала на 16-бит. Он следит за границами страниц. Режим передачи: одиночный, блочный (max V=2 Мбайт/с, 16 бит), по запросу. 16-битные каналы используются для запроса управления шиной.
Шина РС/104 - это логически та же шина ISA, но другой разъем и маломощные сигналы.
ISA и РС/104 применяются в промышленных компьютерах и управляющих контроллерах.
Второе поколение шин — это MCA, EISA, PCI. Основные признаки этого поколения следующи.
Параллельный интерфейс с протоколом обеспечения надежного обмена. Разрядность шины адреса и данных — 32 бита с возможным расширением до 64 бит. Достоверность обеспечивается контролем четности, надежность передачи — обязательным ответом целевого устройства, благодаря чему инициатор транзакции всегда узнает ее судьбу.деСинхронный интерфейс и пакетные передачи с высокой скоростью. Тактовая частота 33 МГц при разрядности 32 бита позволяет достигать пиковой скорости передачи 133 Мбайт/с; возможно повышение частоты до 66 МГц, что при разрядности 64 бит дает пиковую скорость до 532 Мбайт/с.
Автоматическое конфигурирование устройств, заноженное в спецификации шины. Набор стандартизованных конфигурационных регистров позволяет собирать сведения о потребностях всех устройств в системных ресурсах (адресах и прерываниях), конфигурировать устройства (назначать ресурсы) и управлять их поведением (разрешать работу в качестве целевых устройств и инициаторов транзакций).
Набор команд обращений к ресурсам различных пространств, включая и команды оптимизированного обращения к целым строкам кэш-памяти.
Шина EISA имеет дополнительные контакты слота (недоступны картам ISA) и обеспечивает расширение шин данных и адреса до 32 бит. Это новая шина управления для передачи в синхронном режиме и пакетных циклов, обеспечивающая надежный ввод-вывод. Селективное управление AEN для слотов позволяет в специальном режиме изолированно обращаться к I/O каждого слота. Карты ISA можно вставлять в слоты EISA, но не наоборот.
PCI (Peripheral Component Interconnect) local bus — это шина соединения периферийных компонентов, основная шина расширения в современных компьютерах. Синхронная, параллельная, высокопроизводительная, надежная, со средствами автоматизированного конфигурирования устройств.
Шина адреса/данных мультиплексирована и ориентирована на пакетные передачи. Каждая транзакция начинается с фазы передачи адреса, за ней может следовать произвольное (заранее не указываемое) число фаз данных. Данные имеют 32 бита, в каждой фазе могут быть разрешены любые из 4 байт. Есть расширение шины до 64 бит. Адрес; Mem — 32 бита, можно 64 (даже и на 32-битной шине); I/O — 16 бит. Отдельное пространство адресов — конфигурационные регистры, по 256 байт на каждую функцию устройства. Для выбора конфигурационного пространства каждого устройства (слота) — своя линия CSEL, ее формирует мост.
Заметим, что декларированная высокая пропускная способность шины достигается лишь при работе активных устройств шины (Bus Master'oB) — только они способны генерировать длинные пакетные транзакции. Ввод-вывод по шине PCI, выполняемый центральным процессором, дает гораздо более скромные значения реальной пропускной способности.
Особенностью шины PCI является ограниченное (не более 5—6) число устройств, подключаемых к шине (в предыдущих шинах такого жесткого ограничения не было). Для подключения большего числа устройств используются мосты PCI, организующие дополнительные шины. Мосты PCI прозрачны и через них проходят все необходимые транзакции. Однако механизмы буферизации, применяемые в мостах PCI, вносят значительную задержку в выполнение транзакций через мост.
Слабое место протокола PCI — это операции чтения, особенно если они адресуются к не очень быстрой памяти. Эти операции могут на длительное время непродуктивно занимать шину ожиданием данных.
Нарекания вызывает и традиционный способ сигнализации аппаратных прерываний на PCI, так как 4 линии запроса на все устройства всех шин обрекают на их разделяемое использование несколькими устройствами. Хотя электрических противопоказаний (как на ISA) здесь нет, отсутствие стандартизованного признака запроса прерывания затрудняет и замедляет идентификацию устройства, вызвавшего прерывание. Этот стандартный признак появился только в PCI 2.3 — после долгих лег активного использования шины. Начиная с версии 2.2 появился новый механизм оповещения о прерываниях — MSI, который снимает все проблемы традиционной сигнализации.
Спецификация PCI стала отправной точкой для создания выделенного интерфейса графического акселератора — порта AGP. Порт AGP (Accelerated Graphic Port) — это синхронный 32-разрядный параллельный двухточечный интерфейс системного уровня для подключения графического акселератора (ГА). Он обеспечивает конвейеризацию обращений к памяти и ускоренную передачу данных (2х, 4х, 8х). При тактовой частоте 66 МГц достигается скорость 264 Мбайт/с (режим 1х), 533 Мбайт/с (2х за счет двойной синхронизации), 1066 Мбайт/с (4х с синхронизацией от источника данных) и в самой последней версии AGP8x— 2,132 Мбайт/с. Кроме повышения пиковой скорости, в AGP применен более сложный протокол, позволяющий ставить запросы к памяти в очереди. Благодаря этому шина не простаивает в ожидании данных, что положительно сказывается на эффективной производительности. Еще одна особенность AGP — аппаратная трансляция адресов памяти, позволяющая согласовать "видение" физической памяти со стороны акселератора с виртуальной памятью, в которой работает графическое ПО на центральном процессоре. Порт AGP является специализированным интерфейсом к нему подключают только графический акселератор (видеокарту).
GART (Graphics Address Remapping Table) обеспечивает непрерывную область памяти для акселератора, отображаемую на разбросанные страницы ОЗУ. Он реализуется в чипсете, используется при обращениях ГА к ОЗУ через апертуру AGP (диапазон транслируемых адресов, примыкает к локальной памяти ГА).
С шин PCI к устройству на AGP возможна запись, при этом чтение не гарантируется. ЦП может с устройством на AGP делать все. Если чипсет разрешает процессору обращения по физическим адресам внутри апертуры, то это разрешается и устройствам шин PCI, и через GART должны выполняться те же преобразования адреса, что и для обращений от устройства на AGP (может и не разрешать, но тогда он обязан отвергать транзакции).В качестве шины общего назначения PCI получила развитие в виде стандарта PCI-X, вышедшего уже и во второй версии. Здесь тоже повышена пиковая скорость: тактовая частота может быть поднята до 133 МГц (варианты PCI-X66, PCI-X100 и PCI- XI33). В версии 2.0 появился новый режим Mode 2 с синхронизацией от источника данных, в котором скорость записи в память (и только для этой операции) может подниматься в 2 или 4 раза (PCI-X266 и PCI-X533 соответственно). Таким образом, пиковая скорость записи в память в 64-битном варианте шины может достигать 4 Гбайт/с (чтения — до 1 Гбайт/с). В версии 2.0 определен и 16-битный вариант шины. В PCI-X изменен шинный протокол: введена дополнительная фаза передачи атрибутов транзакции, в которой инициатор сообщает свой идентификатор (на PCI целевое устройство не имеет понятия о том, кто запрашивает транзакцию). Кроме того, сообщается и число байтов, подле жащих передаче — это позволяет участникам транзакции планировать свои действия. Главное изменение протокола — это возможность расщепленных транзакций: если целевое устройство не способно быстро ответить, оно заставляет инициатора освободить шину, а позже само организует доставку запрошенных данных. Благодаря этому существенно повышается эффективность использования шины, так как исключаются простои при ожидании данных. Расщепление транзакций повышает и эффективность работы мостов — их издержки становятся менее "разорительными".
В PCI-X2.0 введен и новый способ коммуникации между устройствами: обмен сообщениями, адресуемыми по идентификаторам устройств (номер шины, устройства и функции), а не по адресам ресурсов (памяти или ввода-вывода). В предыдущих версиях шин такой возможности не было; этот способ коммуникации полезен для повышения "интеллектуальности" подсистемы ввода-вывода.
Интересно, что во всех нововведениях PCI-X остается совместимость с устройствами и шинами PCI: каждая шина будет работать в режиме, доступном самому слабому участнику — от PCI с частотой 33 МГц до PCI-X533. Мосты позволяют разным сегментам системы (шинам PCI) работать в разных режимах, так что можно выбрать эффективную конфигурацию, в которой новые устройства, критичные к пропускной способности, будут нормально уживаться со старыми.
Третье поколение организации ввода-вывода — это PCI Express, Hyper Transport. Для третьего поколения характерен переход от шин к двухточечным соединениям с последовательным интерфейсом. По сути, третье поколение ввода-вывода приближается к совсем локальным (в пределах системной платы) сетям. Здесь между узлами сети передаются пакеты, в которых содержится как управляющая информация (команды), так и собственно передаваемые данные. Каждый интерфейс состоит из пары встречных однонаправленных связей (link), работающих независимо друг от друга (никакого квитирования при передаче не предусматривается). Пропускная способность связей одного интерфейса в разных направлениях может различаться — она выбирается с учетом потребностей данного применения. В архитектуре ввода-вывода появились новые возможности: управление качеством сервиса (QoS), потреблением и бюджетом связей. Топология соединения узлов и свойства связей различны, но и HyperTransport, и PCI Express, как и шины прежних поколений, не допускают петель в топологии.
PCI Express, она же 3GIO (3-Generation Input-Output, ввод- вывод 3-го поколения), — это двухточечное подключение периферийных компонентов как в пределах системной платы, так и карт расширения. Интерфейс с разрядностью 1, 2, 4, 8, 12, 16 или 32 бит обеспечивает скорость передачи до 8 Гбайт/с. Здесь сохраняются программные черты шины РС1 (конфигурирование, типы транзакций), что обеспечивает плавность миграции от PCI к PCI Express.
HyperTransport — это высокоскоростное двухточечное соединение между микросхемами в пределах платы (разъемы и карты расширения не предусмотрены). Основной вариант топологии — цепочка устройств-туннелей, имеющих по два интерфейса, и транслирующих все пакеты насквозь. Возможно применение мостов и коммутаторов, осуществляющих маршрутизацию пакетов. Разрядность связей может быть 2, 4, 8, 16 или 32 бита; тактовая частота от 200 до 800 МГц при двойной синхронизации обеспечивает пиковую скорость передачи данных до 6,4 Гбайт/с (32-битная связь). Поскольку пакеты могут передаваться одновременно в обоих направлениях, можно говорить о пропускной способности интерфейса 12,8 Гбайт/с. Общая идея конфигурирования и поддерживаемые типы транзакций обеспечивают удобную интеграцию с PCI/PCI-X посредством мостов.
InfiniBand — это новая архитектура соединений для серверов, основанная на построении централизованной "фабрики ввода-вы вода" (I/O fabric). Узлы InfiniBand объединяются с помощью "коммутационной фабрики" — структуры коммутаторов, допускающей избыточные связи. Избыточность связей приветствуется, так как позволяет повысить суммарную пропускную способность. Избыточность обеспечивается как внутренними связями элементов коммутационной фабрики, так и наличием нескольких интерфейсов у устройств, позволяющих подключаться к нескольким точкам коммутационной фабрики.
В InfiniBand представлены три уровня пропускной способности связей: 0,25, 1 и 3 Гбайт/с. Каждая связь (IB Link) состоит из 1, 4 или 12 пар встречных однонаправленных линий, работающих в полнодуплексном режиме со скоростью передачи в каждой линии 2,5 Гбит/с. Соединения обеспечиваются как межплатными разъемами, так и кабельными соединениями: медными до 17 м и оптическими до 10 км; в медном соединении каждая линия — это пара проводов с дифференциальными сигналами, в оптическом — одно волокно. Архитектура позволяет объединять до десятков тысяч узлов в единую подсеть. В зависимости от назначения, узлы снабжаются канальными адаптерами InfiniBand двух типов: НСА (Host Channel Adapter) для процессорных узлов, являющихся инициаторами транзакций, и ТСА (Terminal Channel Adapter) для узлов ввода-вывода (кон троллеров интерфейсов устройств хранения и сетей, графических контроллеров, шасси ввода-вывода с традиционными шинами расширения и т. п.).
Карты PCMCIA и PC Card — это 68-контактный разъем. Назначение контактов (тип интерфейса), которое "заказывается" картой при установке ее в слот, следующее:
Интерфейс памяти, 8/16-битные обращения, Vmax=10/20 Мбайт/с.
Интерфейс ввода-вывода, 8/16-битные обращения, Vmax=3,92/7,84 Мбайт/с.
Интерфейс CardBus: чуть упрощенная PCI 33 МГцх х32 бит = 132 Мбайт/с; дополнительно — цифровая передача аудиосигнала, ИКМ или ШИМ (PWM).
Интерфейс АТА, предназначенный для дисков.
Существует 4 типа PC Card. У них у всех размер в плане 54x 85,5 мм, но разная толщина (меньшие адаптеры встают в большие гнезда):
PC Card Type I — 3,3 мм — карты памяти;
PC Card Type II — 5 мм — карты устройств ввода-вывода, модемы, адаптеры локальных сетей;
PC Card Type III — 10,5 мм — дисковые устройства хранения;
PC Card Type IV- 16 мм.Small PC Card размером 45 x 42,8 мм — это тот же коннектор и те же типы по толщине.
ZV Port (Zoomed Video) — это двухточечный интерфейс для доставки видеоданных с карты в экранный буфер VGA, 4 аудио- канала.
"Мелкие" интегрированные контроллеры ПУ (порты СОМ, LPT, GAME, контроллер клавиатуры, мыши PS/2, НГМД, аудио), по традициям совместимости как устройства PCI не оформляют. Для них есть "маленькие" шины:
X-Bus (на старых системных платах) — конструктивно не оформленная (слотами) шина ISA со всеми атрибутами (IRQ, DMA). Асинхронная (как ISA), неудобна в стыковке с синхронным окружением.
LPC (Low Pin Count) — синхронная (33 МГц) 4-битная мультиплексированная шина, адрес памяти 32-битный; прерывания, DMA, BusMaster, пропускная способность на уровне ISA/X -Bus. В современных платах подключается через мост к PCI. Автоконфигурирование не предусмотрено (все абоненты априорно известны BIOS).
Рассмотрим периферию.
Основной поток информации от PC — зрительный, через активные (монитор) и пассивные (принтер, плоттер) средства вывода.
Графическая подсистема содержит монитор, подключенный через графический адаптер. При этом изображение формируется программно.
Видеосистема обеспечивает ввод/вывод "живого" видео.
Видеокарта (в современном понимании) обеспечивает графику, возможно и видео.
Устройство графического адаптера — это видеопамять, контроллер атрибутов (RAMDAC), контроллер ЭЛТ (развертки), интерфейс монитора, интерфейс к хосту, акселератор, VideoBIOS.
Интерфейсы мониторов могут быть дискретные, аналоговые и цифровые. Наиболее известные интерфейсы следующие:
Дискретный RGB TTL: DB-9, синхронизация HSync, +/—VSync; Video + Intens, RGB + Intens, RrGgBb.
Аналоговый RGB (VGA): DB-15; синхронизация раздельная/общая, RGB - 75 Ом/О,7 В.
Цифровые интерфейсы: P&D, DVI, DFP.
Интерфейс Panel-Link (VESA) —- основа; кодек последователь ного интерфейса, протокол T M.D.S. (Transition Minimazed Difleretial Signaling), 4 канала (3 data + 1 clock). Каждый канал данных (8 бит) образован кодером, расположенным на видеокарте, линией связи и декодером, расположенным в дисплее; передает либо видео, либо синхронизацию и дополнительные сигналы.
Аналоговый интерфейс Composite Video: полный видеосигнал 1,5 В, коаксиал (75 Ом), разъемы RCA "колокольчики" (в бытовых видеомагнитофонах, аналоговых телекамерах, телевизорах).
Аналоговый интерфейс S-Video (Separate Video, S-VHS и Y/C): Y — это яркость и синхронизации (luminance+sync, обычный черно-белый видеосигнал, 1В) и С — это цветность (под- несущая, модулированная цветоразностными сигналами, 0,3 В). Коаксиал 75 Ом. Разъем mini-DIN (4 конт. или 7).
Рассмотрим другую важную часть обеспечения функционирования УВМ.
Работа УВМ в реальном масштабе времени обеспечивается операционной системой реального времени (ОС РВ), являющейся фундаментом базового программного обеспечения любой ЭВМ. ОС РВ должна обеспечивать полный цикл жизни программного обеспечения: создание текста программы, ее компиляцию, построение, отладку, исполнение и сопровождение. Требования, которым должны удовлетворять любые ОС РВ, изложены в стандарте POSIX 1003.4 (Real Time Extensions for Portable Operating Systems) рабочего комитета IEEE, утвержденном ISO/IEC как международный стандарт 9945. Этот стандарт определяет операционную систему как систему реального времени (ОС РВ), если она обеспечивает требуемый уровень сервиса за вполне определенное, ограниченное время. Сказанное можно сформулировать таким образом, что ОС РВ должна быть предсказуема. Правильная, но запоздалая реакция системы на внешнее событие зачастую может быть просто гибельной, например, в системе безопасности атомной станции, системах управления воздушным транспортом и т. п. При этом важно не абсолютное время реакции системы, а то, что оно определено заранее. В системе управления прокатным станом время реакции системы должно быть в пределах нескольких миллисекунд, а в системе контроля за окружающей средой — несколько минут. Однако оба эти при- ■ мера из области задач реального времени.
Попробуем с учетом изложенных особенностей режима реального времени ответить на вопрос: а можно ли задачу реального времени решать с помощью операционных систем общего назначения (MS-DOS, UNIX и др.)? j Прежде чем ответить на него, вспомним, что все операционные системы делятся на системы реального времени и разделения времени (общего назначения). Главное требование, предъявляемое к системам общего назначения, заключается в обеспечении оптимального разделения всех ресурсов между всеми процессами,, Соответственно, не должно быть высокоприоритетных задач, которые использовали бы какой-либо ресурс системы только по мере необходимости. Поэтому разработчики операционных сис тем так или иначе стремятся достичь компромисса между меха- j низмом приоритетности и упомянутым требованием.
Самыми популярными операционными системами до на~ стоящего времени остаются UNIX — подобные системы. Более j того, UNIX стал de facto стандартом для последующих операционных систем. Он реализован и на микро- и на суперкомпьютерах. Многие программные международные стандарты и согла шения основаны на UNIX, например: POSIX (Portable Operating System Interfase Standard), SV1D, BSD 4.3 UNIX Socket и др. Однако UNIX разрабатывалась как система общего назначения, не имеет эффективного механизма приоритетности задач ! и поэтому мало пригодна в задачах реального времени. В то же время, как будет показано позже, очень многие ОС РВ можно отнести к UNIX-подобным.
MS-DOS в принципе можно использовать в задачах реального времени. Однако надо учесть, что существует еще целый ряд требований к системам реального времени, чисто практического свойства, которым MS-DOS не удовлетворяет, а имен- j но: многозадачность (MS-DOS — однозадачная система), легкость написания и включения в систему драйверов внешних устройств и хорошо развитый механизм синхронизации процессов и межзадачных обменов.
Таким образом, очевидно, что задачи реального времени целесообразно реализовывать в рамках специфической системной программной среды — ОС РВ, которую мы и рассмотрим более подробно.
Начнем с классификации ОС РВ. Обычно выделяют 4 класса ОС РВ:
1.0С РВ с программированием на уровне микропроцессоров.
Такие системы очень небольшие и обычно написаны на языке низкого уровня, типа ассемблера или PLM и используются для программируемых процессоров. Эти микросхемы встраиваются в исполнительные механизмы и другие устройства. Внутрисхемные эмуляторы пригодны для отладки, но другие средства высокого уровня для разработки и отладки программ не применимы. Операционная среда обычно недоступна.
2. ОС РВ с минимальным ядром системы реального времени.
s9to более высокий уровень системы реального времени, обеспечивающий минимальную среду исполнения. Предусмотрены основные функции, но управление памятью и диспетчер недоступны. Ядро представляет собой набор программ, выполняющих типичные, необходимые для встроенных систем низкого уровня функции типа арифметические операции с плавающей запятой и функции минимального сервиса ввода-вывода. Прикладные программы разрабатываются в инструментальной среде и выполняются на различных объектных устройствах с помощью встраиваемых микропроцессоров.
З.ОС РВ с ядром системы реального времени и инструментальной средой.
Этот класс систем обладает многими чертами полноценной операционной системы с полным сервисом. Разработка ведется в инструментальной среде, а исполнение -— на целевых системах. Обеспечивается гораздо более высокий уровень сервиса для разработчиков прикладных программ. Например, сюда включены такие средства, как дистанционный символьный отладчик, анализаторы эффективности, протокол ошибок и другие средства CASE (Computer Aided Software Engineering tools — средства разработки вспомогательного программного обеспечения для работы на компьютере). Кроме того, часто доступно параллельное программирование как часть среды исполнения.