Вариант 3. (Парная регрессия)
Изучается зависимость времени, затрачиваемого на обслуживание одного покупателя от стоимости покупок.
|
|
Время обслуживания, мин |
Стоимость покупок, долл |
|
1. |
3,0 |
36 |
|
2. |
1,3 |
13 |
|
3. |
7,4 |
81 |
|
4. |
5,9 |
78 |
|
5. |
8,4 |
103 |
|
6. |
5,0 |
64 |
|
7. |
8,1 |
67 |
|
8. |
1,9 |
25 |
|
9. |
6,2 |
55 |
1.Выбрать признак Х и признак У
2.Проверить исходные данные на однородность.
3.Построить поле корреляции и сформулировать гипотезу о форме связи.
4.Рассчитать параметры парного уравнения регрессии.
5.Оценить тесноту связи с помощью показателей корреляции и детерминации.
6.Оценить качество уравнения регрессии с помощью средней ошибки аппроксимации.
7.Оценить статистическую надежность (практическую значимость) регрессионного моделирования.
8.Выполнить точечный и интервальный прогноз значения y, если х увеличится на 10% от его среднего уровня.
Решение
1) Так как стоимость покупки зависит от времени потраченного на принятие решения о ее приобретении (чем дороже покупка, тем дольше мы думаем о ее необходимости, а следовательно и время обслуживания, затраченное продавцом для покупателя, увеличивается), то признаком результатом (У) будет являться стоимость покупок, а признаком – фактором (Х)- время обслуживания.
2) Построим поле корреляции. Для этого необходимо поместить наблюдения в систему координат. Совокупность полученных точек составляет корреляционное облако. Если оно вытянуто из левого нижнего угла в правый верхний – связь прямая, если из правого верхнего в левый нижний – обратная. Если точки беспорядочно разбросаны по полю, это говорит о том, что связи между двумя признаками нет.
Совокупность точек результативного и факторного признаков называется полем корреляции.
На основании поля корреляции можно выдвинуть гипотезу (для генеральной совокупности) о том, что связь между всеми возможными значениями X и Y носит линейный характер.
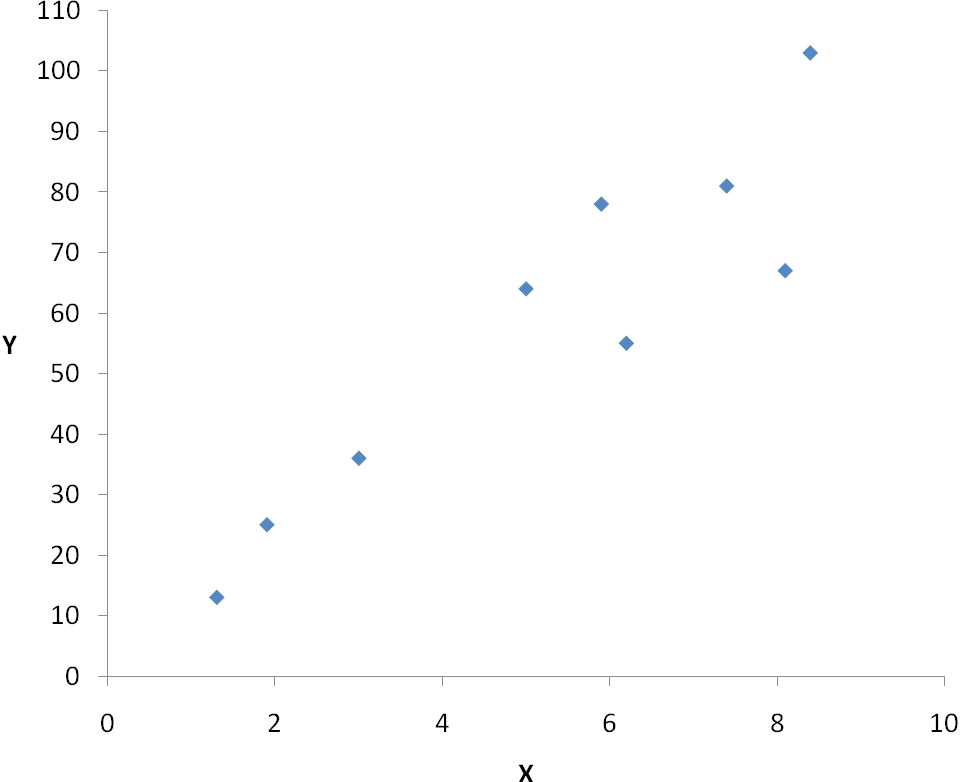
Рисунок 1. Поле корреляции.
Корреляционное облако имеет вытянутую форму. Можно использовать линейную функцию.
3) Проверим исходные данные на однородность. Для этого рассчитаем коэффициент вариации для обеих переменных: Для расчета коэффициента вариации нам потребуется среднее значение и СКО по каждой переменной.
Для расчета параметров регрессии построим расчетную таблицу (табл. 1)
|
x |
y |
x2 |
y2 |
x • y |
|
3 |
36 |
9 |
1296 |
108 |
|
1.3 |
13 |
1.69 |
169 |
16.9 |
|
7.4 |
81 |
54.76 |
6561 |
599.4 |
|
5.9 |
78 |
34.81 |
6084 |
460.2 |
|
8.4 |
103 |
70.56 |
10609 |
865.2 |
|
5 |
64 |
25 |
4096 |
320 |
|
8.1 |
67 |
65.61 |
4489 |
542.7 |
|
1.9 |
25 |
3.61 |
625 |
47.5 |
|
6.2 |
55 |
38.44 |
3025 |
341 |
|
∑ = 47.2 |
∑ = 522 |
∑ = 303.48 |
∑ = 36954 |
∑ = 3300.9 |
Выборочные средние.
Выборочные дисперсии:
=
Среднеквадратическое отклонение
Коэффициент вариации:
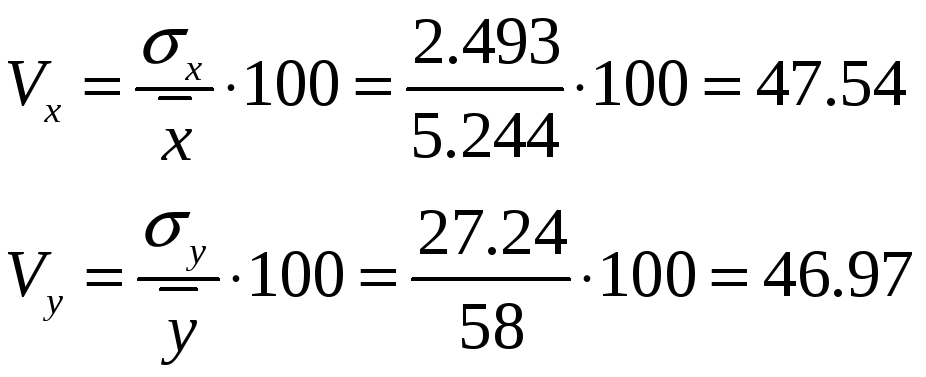
Вариация в пределах нормы. Данные однородны.
4) рассчитаем параметры парного уравнения регрессии
Коэффициент корреляции b можно найти по формуле:
Линейное уравнение регрессии имеет вид y = 10.069 x + 5.192
Коэффициентам уравнения линейной регрессии можно придать экономический смысл.
Коэффициент регрессии b = 10.069 показывает среднее изменение результативного показателя (в единицах измерения у) с повышением или понижением величины фактора х на единицу его измерения. В данном примере с увеличением на 1 единицу y повышается в среднем на 10.069.
Коэффициент a = 5.192 формально показывает прогнозируемый уровень у, но только в том случае, если х=0 находится близко с выборочными значениями.
Но если х=0 находится далеко от выборочных значений х, то буквальная интерпретация может привести к неверным результатам, и даже если линия регрессии довольно точно описывает значения наблюдаемой выборки, нет гарантий, что также будет при экстраполяции влево или вправо.
Подставив в уравнение регрессии соответствующие значения х, можно определить выровненные (предсказанные) значения результативного показателя y(x) для каждого наблюдения.
Связь между у и х определяет знак коэффициента регрессии b (если > 0 – прямая связь, иначе - обратная). В нашем примере связь прямая.
Коэффициент регрессии показывает, что с ростом времени обслуживания на 1 мин, стоимость покупки возрастает в среднем на 10,0693 долл.
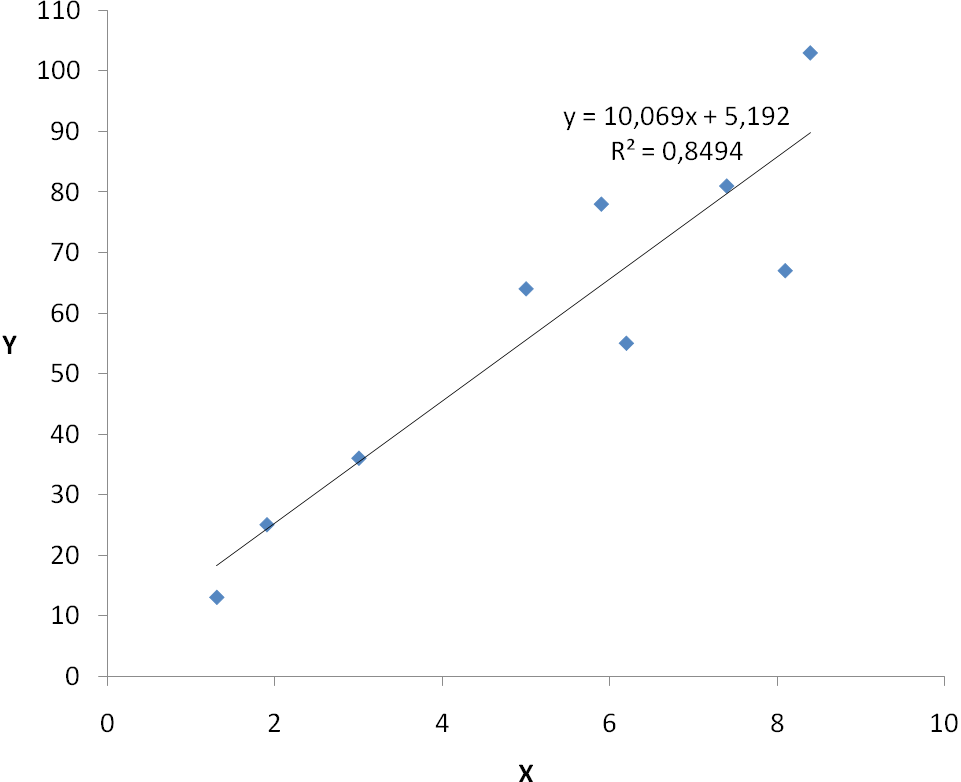
Рисунок 2. Линия регрессия и уравнение регрессии на поле корреляции
5) Оценим тесноту связи с помощью показателей корреляции и детерминации
Ковариация:
Рассчитываем показатель тесноты связи. Таким показателем является выборочный линейный коэффициент корреляции, который рассчитывается по формуле:
Линейный коэффициент корреляции принимает значения от –1 до +1.
В нашем примере связь между признаком Y и фактором X весьма высокая и прямая.
Кроме того, коэффициент линейной парной корреляции может быть определен через коэффициент регрессии b:
Квадрат (множественного) коэффициента корреляции называется коэффициентом детерминации, который показывает долю вариации результативного признака, объясненную вариацией факторного признака.
Чаще всего, давая интерпретацию коэффициента детерминации, его выражают в процентах.
R2= 0.9222 = 0.8494
т.е. в 84.94% случаев изменения х приводят к изменению y. Другими словами - точность подбора уравнения регрессии - высокая. Остальные 15.06% изменения Y объясняются факторами, не учтенными в модели (а также ошибками спецификации).
6) Оценим качество уравнения с помощью ошибки аппроксимации
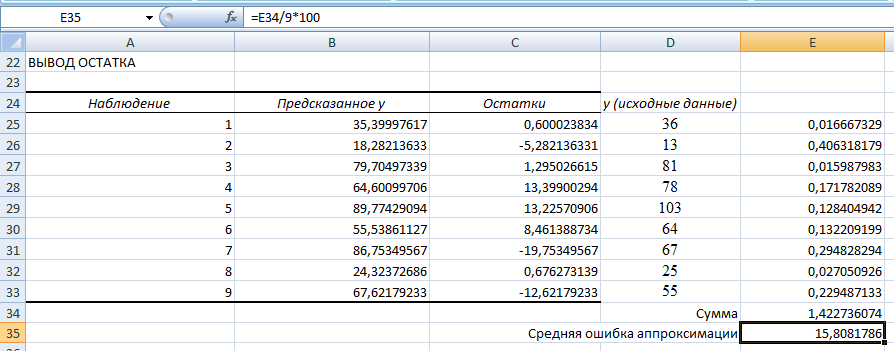
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации. Средняя ошибка аппроксимации - среднее отклонение расчетных значений от фактических:
Ошибка аппроксимации в пределах 5%-7% свидетельствует о хорошем подборе уравнения регрессии к исходным данным.
Для оценки качества параметров регрессии построим расчетную таблицу (табл. 2)
|
x |
y |
y(x) |
|y - yx|:y |
|
3 |
36 |
35.4 |
0.0167 |
|
1.3 |
13 |
18.282 |
0.406 |
|
7.4 |
81 |
79.705 |
0.016 |
|
5.9 |
78 |
64.601 |
0.172 |
|
8.4 |
103 |
89.774 |
0.128 |
|
5 |
64 |
55.539 |
0.132 |
|
8.1 |
67 |
86.753 |
0.295 |
|
1.9 |
25 |
24.324 |
0.0271 |
|
6.2 |
55 |
67.622 |
0.229 |
|
47.2 |
522 |
522 |
1.423 |
В среднем, расчетные значения отклоняются от фактических на 15.81%. Поскольку ошибка больше 7%, то данное уравнение не желательно использовать в качестве регрессии.
7) Проверка гипотез относительно коэффициентов линейного уравнения регрессии.(t-статистика. Критерий Стьюдента).
Оценим статистическую надежность (значимость) результатов регрессионного моделирования.
Ранее мы получили лишь оценки параметров уравнения регрессии, которые характерны для конкретного статистического наблюдения (конкретного набора значений x и y).
Для оценки статистической значимости коэффициентов регрессии и корреляции рассчитываются t-критерий Стьюдента и доверительные интервалы каждого из показателей. Выдвигается гипотеза Н0 о случайной природе показателей, т.е. о незначимом их отличии от нуля.
Чтобы проверить, значимы ли параметры, т.е. значимо ли они отличаются от нуля для генеральной совокупности используют статистические методы проверки гипотез.
В качестве основной (нулевой) гипотезы выдвигают гипотезу о незначимом отличии от нуля параметра или статистической характеристики в генеральной совокупности. Наряду с основной (проверяемой) гипотезой выдвигают альтернативную (конкурирующую) гипотезу о неравенстве нулю параметра или статистической характеристики в генеральной совокупности.
Проверим гипотезу H0 о равенстве отдельных коэффициентов регрессии нулю (при альтернативе H1 не равно) на уровне значимости α=0.05.
H0: b = 0, то есть между переменными x и y отсутствует линейная взаимосвязь в генеральной совокупности;
H1: b ≠ 0, то есть между переменными x и y есть линейная взаимосвязь в генеральной совокупности.
В случае если основная гипотеза окажется неверной, мы принимаем альтернативную. Для проверки этой гипотезы используется t-критерий Стьюдента.
Найденное по данным наблюдений значение t-критерия (его еще называют наблюдаемым или фактическим) сравнивается с табличным (критическим) значением, определяемым по таблицам распределения Стьюдента (которые обычно приводятся в конце учебников и практикумов по статистике или эконометрике).
Табличное значение определяется в зависимости от уровня значимости (α) и числа степеней свободы, которое в случае линейной парной регрессии равно (n-2), n-число наблюдений.
Если фактическое значение t-критерия больше табличного (по модулю), то основную гипотезу отвергают и считают, что с вероятностью (1-α) параметр или статистическая характеристика в генеральной совокупности значимо отличается от нуля.
Если фактическое значение t-критерия меньше табличного (по модулю), то нет оснований отвергать основную гипотезу, т.е. параметр или статистическая характеристика в генеральной совокупности незначимо отличается от нуля при уровне значимости α.
tкрит (n-m-1;α/2) = (7;0.025) = 2.365
Поскольку 6.28 > 2.365, то статистическая значимость коэффициента регрессии b подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Поскольку 0.56 < 2.365, то статистическая значимость коэффициента регрессии a не подтверждается (принимаем гипотезу о равенстве нулю этого коэффициента). Это означает, что в данном случае коэффициентом a можно пренебречь.
8) Выполним точечный и интервальный прогноз y, если х увеличится на 10% от его среднего уровня.
Экономическое прогнозирование на основе построенной модели предполагает, что сохраняются ранее существовавшие взаимосвязи переменных и на период упреждения. Для прогнозирования зависимой переменной результативного признака необходимо знать прогнозные значения всех входящих в модель факторов.
Прогнозные значения факторов подставляют в модель и получают точечные прогнозные оценки изучаемого показателя.
Точечный прогноз получаем путем подстановки в уравнение прогнозного значения признака-фактора: Xp =5,224*1,1= 5,768 ≈ 6 мин.
y(6) = 10.069*6 + 5.192 = 65.608 долл.
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и Xp = 6
tкрит (n-m-1;α/2) = (7;0.025) = 2.365
Вычислим ошибку прогноза для уравнения y = bx + a
=
или
=
65.608 ± 9.875
(55.73;75.48)
С вероятностью 95% можно гарантировать, что значения Y при неограниченно большом числе наблюдений не выйдет за пределы найденных интервалов.
Решение задачи в MS Excel
1. C помощью инструмента анализа данных Регрессия можно получить результаты регрессионной статистики, дисперсионного анализа, доверительных интервалов, остатки и графики подбора линии регрессии.
2. Построим поле корреляции. Скопировать данные своего варианта на лист Excel.
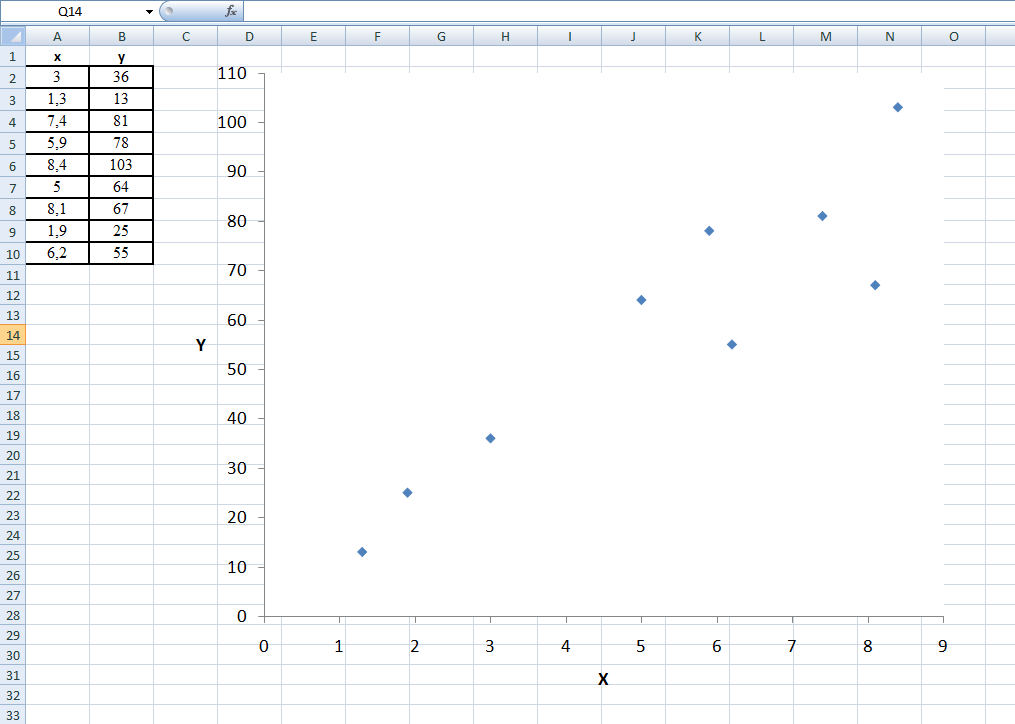
Корреляционное облако имеет вытянутую форму. Можно использовать линейную функцию.
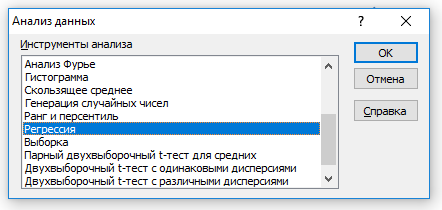
Для расчета показателей корреляции и регрессии выбираем Данные Анализ данных Регрессия.
Заполняем диалоговое окно ввода данных и параметров вывода
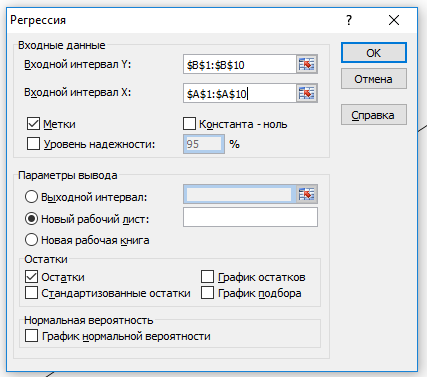
Здесь:
Входной интервал Y - диапазон, содержащий данные результативного признака;
Входной интервал X - диапазон, содержащий данные признака- фактора;
Метки - «флажок», который указывает, содержит ли первая строка названия столбцов;
Константа - ноль - «флажок», указывающий на наличие или отсутствие свободного члена в уравнении;
Выходной интервал - достаточно указать левую верхнюю ячейку будущего диапазона;
Новый рабочий лист - можно указать произвольное имя нового листа (или не указывать, тогда результаты выводятся на вновь созданный лист).
Получаем следующие результаты для рассмотренного выше примера.
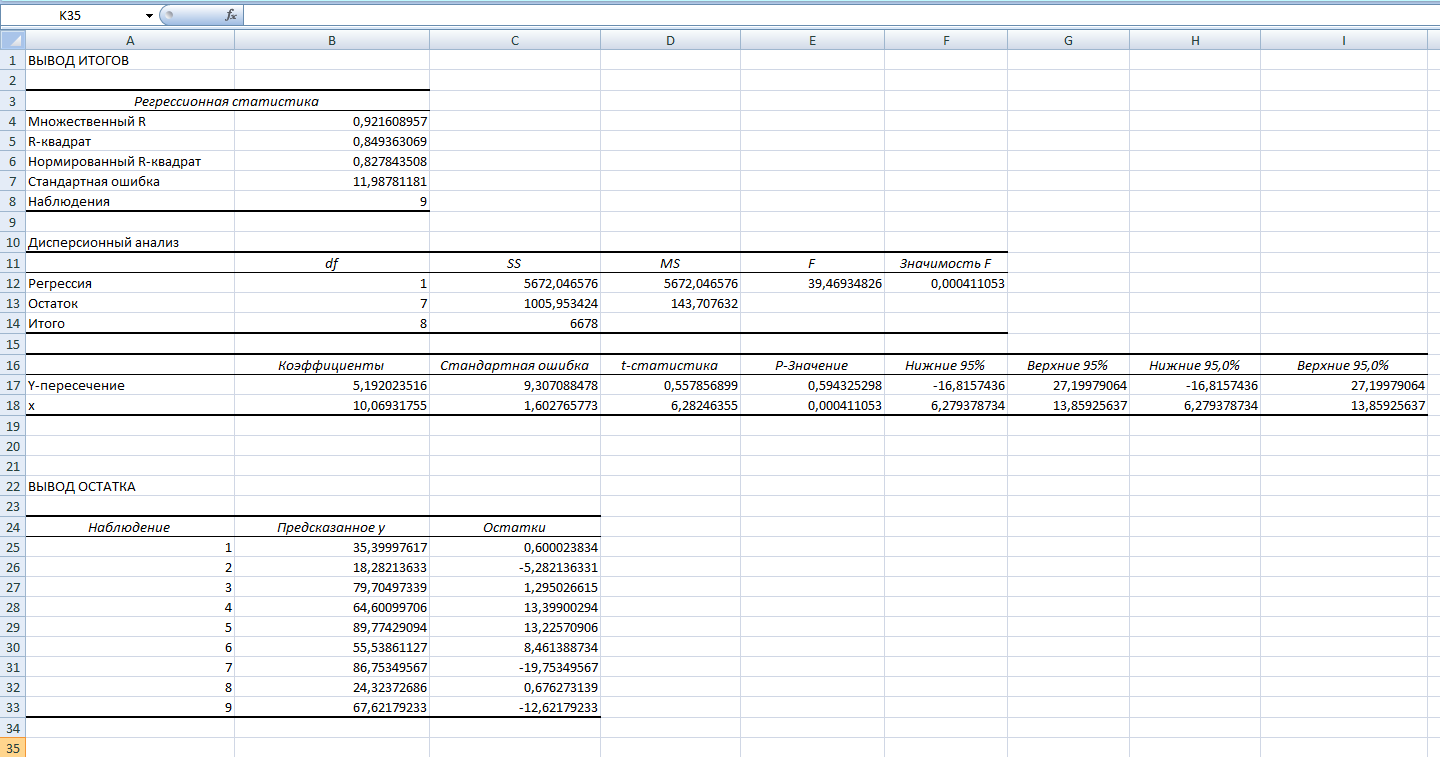
В таблице «Регрессионная статистика» представлены следующие показатели:
Множественный R- коэффициент корреляции между результатом и факторами.
R-квадрат – коэффициент детерминации
Нормированный R-квадрат – коэффициент детерминации, скорректированный на число степеней свободы.
Стандартная ошибка (регрессии)– корень из остаточной дисперсии на 1 степень свободы.
Наблюдения – число единиц совокупности, участвующих в расчете.
Коэффициент корреляции: 0,922 (связь очень тесная)
Коэффициент детерминации: 0,849 (84,9% вариации стоимости покупки объясняется вариацией времени обслуживания).
В таблице «Дисперсионный анализ» представлены результаты проверки значимости коэффициента детерминации – практической значимости полученного уравнения в целом.
df – число степеней свободы: для строки «Регрессия» число степеней свободы определяется количеством факторных признаков в уравнении =m.
Для строки «Остаток» число степеней свободы = n-m-1.
Столбец SS – сумма квадратов отклонений
Столбец MS - дисперсии на 1 степень свободы, рассчитываемые как MS= SS/df
Столбец F = MS(Регрессия)/MS(Остатки).
Фактическое значение F -критерия Фишера:F = 39,47 (Можно сравнить с табличным значением, воспользовавшись функцией =FРАСП (Fp; df (регрессия); df(остаток), а можно воспользоваться столбцом «Значимость F». Если расчетное α (уровень значимости) меньше, чем 0,05, уравнение регрессии статистически значимым и может быть использовано для прогноза.
В последней таблице представлены коэффициенты регрессии и их статистические оценки.
Уравнение регрессии: у(x) = 10,069 + 5,19x
Далее проверим значимость коэффициентов регрессии: a и b. Сравнивая попарно значения столбцов Коэффициенты и Стандартная ошибка в таблице, видим, что абсолютные значения коэффициентов больше, чем их стандартные ошибки. К тому же эти коэффициенты являются значимыми, о чем можно судить по значениям показателя Р-значение, которые меньше заданного уровня значимости α=0,05.
Стандартные ошибки для параметров регрессии: mа = 9,3, mb = 1.6
Фактические значения t -критерия Стьюдента: ta = 0.56, tb = 6,28.
Фактические значения t -критерия Стьюдента сравниваются с табличным значением.
6) Для расчета средней ошибки аппроксимации необходимо воспользоваться таблицей «Вывод остатков», где приведены «Предсказанное у» и остатки. Рассчитав дополнительный столбец со значениями, можно определить среднюю ошибку аппроксимации.
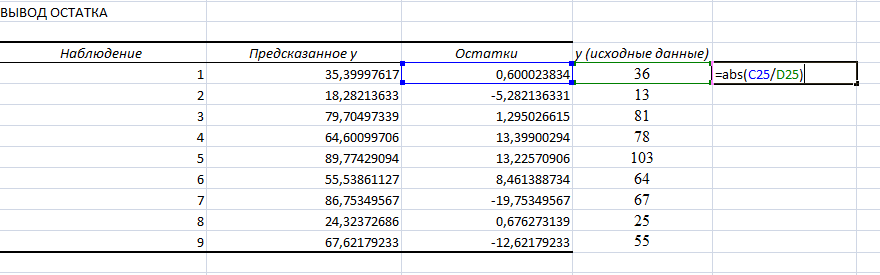
Результат: