

Реализация семантического анализатора в системе MyLingvo.
В разрабатываемом автором этой книги лингвистическом процессоре MyLingvo за основу построения семантического словаря взят принцип дихотомии (деления группы пополам по какому-то признаку). Изначально все слова в словаре разделены на действия (глаголы), объекты (существительные) и признаки (прилагательные и связанные с ними наречия). Все объекты делятся на одушевленные и неодушевленные, одушевленные, в свою очередь, делятся на животные и растения, животные делятся на людей и прочих животных и т.д. При этом сама структура дихотомии задается гибко и представляет из себя файл, содержащий два поля – 1) признак, наличие или отсутствие которого у объекта позволяет отнести его к той или иной подкатегории в пределах родительской категории, 2) уровень вложения. В результате для каждого объекта может быть задана последовательность нулей и единиц, определяющая его место в семантической классификации и позволяющая оперировать с объектами при помощи алгебры логики. Для нашего примера класс объектов «ЧЕЛОВЕК» может быть представлен двоичным числом «111», а класс объектов «ЖИВОТНОЕ» - числом «011», растения – «01». Нули в первой позиции также существенны и не могут быть опущены. Иначе нельзя было бы отличить класс «РАСТЕНИЯ» (01) от класса «ОДУШЕВЛЕННЫЕ ПРЕДМЕТЫ» (1). В последний входят, как было уже сказано и «ЖИВОТНЫЕ»(11). В системе определены элементарные действия: 1) БЫТЬ; 2) ИМЕТЬ(=держать); 3) ПРЕДСТАВЛЯТЬ; 4) МОЧЬ; 5) ХОТЕТЬ(=намереваться что-либо сделать); Автор исходит из предположения, что любое действие может быть выражено при помощи логической комбинации этих действий, представленных как предикаты, с определенными семантическим объектом, инструментом и субъектом. Например, действие «сказать» может быть представлено как ПРЕДСТАВЛЯТЬ(ЧЕЛОВЕК,ТЕКСТ,ГОЛОС), где «ЧЕЛОВЕК» - класс объектов для обозначения семантического субъекта, «ТЕКСТ» - класс объектов для обозначения семантического объекта, «ГОЛОС» - класс объектов для обозначения семантического инструмента.
5. Структуры хранения данных и знаний.
Одной из важнейших структур, с помощью которых представляются и хранятся в оперативной памяти компьютера анализируемые в лингвистическом процессоре данные, является дерево. Дерево – это структура данных, представляющая из себя граф, у которого одна из вершин определена как корневая.
На языке C дерево может быть представлено в виде следующих структур
struct Node // Структура для описания вершины { char* name; // Имя вершины (или др. информация) ………………. Arc* parent; // Указатель на дугу, идущую от родительской вершины Arc** children; // Указатель на массив исходящих дуг int nNumOfChildren; // Число исходящих дуг } struct Arc // Структура для хранения дуги { char* name; // Имя дуги (или др.информация) ……………….. Node* Prev; // Указатель на вершину-родитель Node* Next; // Указатель на дочернюю вершину } struct Tree // Структура для описания дерева { Node* root; // Указатель на корневую вершину дерева } Очень удобной для хранения и зачастую удобной для обработки формой хранения дерева является линейная скобочная запись или, что то же самое, запись дерева в виде фреймов ( от английского frame – рамка). Линейная скобочная запись строится на основе того или иного обхода вершин дерева. Рекурсивная процедура обхода нашего дерева может иметь вид: void tree_order (Node* nd) { for (int i=0; i { Node* cur_node =nd->children[i]; tree_order(cur_node); } }
Рассмотрим скобочную линейную структуру для следующего дерева:
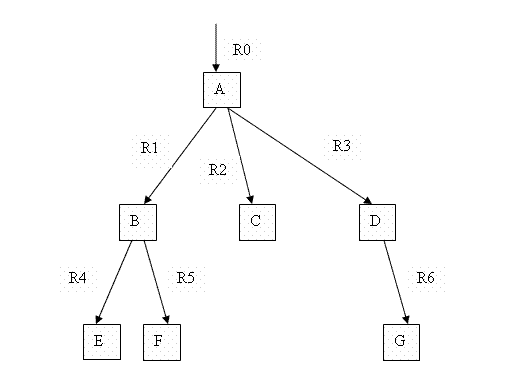
Линейная скобочная структура должна иметь вид:
R0(A)(R1(B)(R4(E)R5(F))R2(C)R3(D)(R6(G)))
Таким образом, алгоритм будет таким:
// Строка для результирующей линейной скобочной структуры, размер 10000 // взят для примера. char* out_str=(char*)malloc(10000*sizeof(char)); strcpy(out_str,””); // вызов процедуры // Tree tr1; - входящее дерево tree_order(out_str, tr1.root); // сама процедура: void tree_order (char* str1, Node* nd) { strcat(nd->parent.name); strcat(str1,”(“); strcat(nd.name); strcat(str1,”)“); if(nNumOfChildren>0) strcat(str1,”(“); for (int i=0; i { Node* cur_node =nd->children[i]; tree_order(str1, cur_node); } if(nNumOfChildren>0) strcat(str1,”)“); }