

Модели синтаксического анализа, применяемые в зарубежных промышленных решениях.
1. Модели, основанные на Link Grammar.
Link Grammar (LG) (грамматика ссылок) – это теория синтаксиса, разработанная Дэйвом Темперли и Дэниэлом Слитором, которая построена на отношениях между парами слов в отличии от деревоподобных структур в других моделях. В то время как большинство систем используют структуры уровня именных и глагольных групп при построении дерева фразы, грамматика ссылок использует информацию о типах связей, которое каждое слово может иметь со словами, находящимися справа и слева и несколько общих грамматических правил. Например, в языках типа SVO (подлежащее+сказуемое+объект), таких как английский, сказуемое содержит левую ссылку на субъект и правую ссылку на объект. Существительное имеют ссылку вправо, если это субъект (подлежащее), и влево – если объект. В языках SOV (субъект+объект+сказуемое)), таких как персидский, сказуемое содержит левую ссылку на объект и более длинную левую сслыку на субъект. Существительное имеет ссылку вправо как в случае подлежащего, так и объекта. Ссылки вправо представляются как a+, а ссылки влево как a-. Необязательные ссылки заключаются в фигурные скобки. Неожиданные ссылки в любом количестве заключаются в квадратные скобки. Множественные ссылки соединяются посредством конъюнкции & или дизъюнкции or. Каждое правило заканчивается точкой с запятой. Например, список базовых правил для языка SVO может иметь вид:
<артикль>: D+; <существительное-субъект>: {D-}&S+; <существительное-объект>: {D-}&O- <сказуемое>: S-&{O+}
Тогда английское предложение «The man killed a shark.»(«Человек убил акулу») должно быть представлено так:
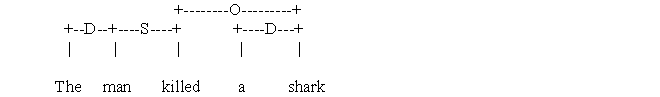
В качестве примера использования такой модели можно привести Link Parser, разработанный в Carnegie-Melon University. Пример разбора предложения этой системой может выглядеть так:

Здесь обозначения таковы: Xp – связь между началом и концом предложения, Sp – связь между существительным и глаголом, Wd – связь между началом предложения и предложением, Mp - связь между именной группой и модифицирующей ее предложно-именной группой, Jp - связь между предлогом и относящейся к нему именной группой, MVa – связь между глаголом (прилагательным) и модификатором..
2. Модели, использующие структуры уровня именных и глагольных групп.
В качестве примеров таковых систем можно привести Ergo Linguistic Technologies Parser Д. Биккертона и Ф.Бралика из университета Гонолулу и Functional Dependency Grammar, созданный исследователями Хельсинкского Университета, позднее основавшими фирмы Lingsoft и Conexor. Пример синтаксического разбора в Ergo может быть таким:
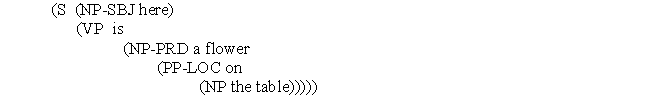
Здесь: S – предложение, NP – именная группа, NP-SBJ – именная группа-субъект, VP – глагольная группа, NP-PRD - именная группа-объект, PP-LOC – предложно-именная группа, локатив. Отличительной особенностью Functional Dependency Grammar является то, что в случаях, когда невозможно снять многозначность, синтаксический анализатор либо не достраивает дерево данной части предложения либо выдает несколько вариантов анализа. Пример разбора может выглядеть так:
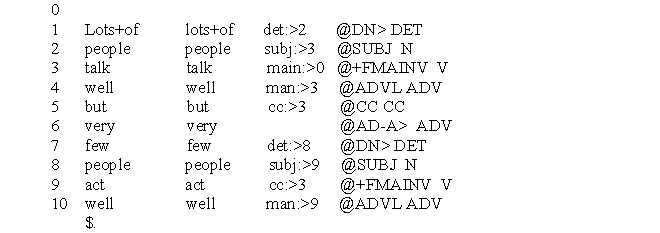
Эта запись представляет дерево фразы. Колонка 1 – номер по порядку, 2-3 содержат само слово, 4 – идентификаторы, отражающие вид и направление связи ( символ > предшествует номеру того элемента, которому подчинен данный), 5 – функциональные идентификаторы вершин. Идентификаторы связей дерева таковы: det: - определение, subj: - субъект (подлежащее), main: - основной элемент, man: - обстоятельство образа действия, cc: - сочинительный союз. Функциональные идентификаторы: @DN> - определение, @SUBJ - субъект (подлежащее), @FMAINV – личный предикат, @ADVL – обстоятельство, @CC – сочинительный союз, @AD-A – интенсификатор.