

Параметры линейного однофакторного
уравнения регрессии
Показатели |
X |
Y |
Среднее значение |
15 |
9,3 |
Дисперсия |
14 |
6,08 |
Среднее квадр. отклонение |
3,7417 |
2,4658 |
Корреляционный момент |
8,96 |
|
Коэффициент корреляции |
0,9712 |
|
Параметры |
b=0,64 |
a=0,3 |
В итоге наше уравнение будет иметь вид:
y = 0.3 + 0.64x
Используя это уравнение, можно найти расчетные значения Y и построить график (рис. 1).
![]()
Рис.
1. Фактические и расчетные значения
![]()
Ломаная линия на графике отражает фактические значения Y, а прямая линия построена с помощью уравнения регрессии и отражает тенденцию изменения спроса в зависимости от дохода.
Оценка адекватности линейного однофакторного уравнения
Анализ качества полученной регрессионной модели начинается с анализа случайных отклонений. Свойства коэффициентов регрессии существенным образом зависят от свойств случайной составляющей. Для того чтобы регрессионный анализ, основанный на обычном методе наименьших квадратов, давал наилучшие из всех возможных результаты, случайные отклонения должны удовлетворять условиям, известным как условия Гаусса—Маркова. Не будет преувеличением сказать, что именно понимание важности этих условий отличает компетентного исследователя, использующего регрессионный анализ, от некомпетентного. Если эти условия не выполнены, исследователь должен это сознавать. Если корректирующие действия возможны, то аналитик должен быть в состоянии их выполнить. Если ситуацию исправить невозможно, исследователь должен быть способен оценить, насколько серьезно это может повлиять на результаты.
Рассмотрим теперь эти условия одно за другим, объясняя кратко, почему они имеют важное значение.
Предположения о случайном отклонении
Условия Гаусса – Маркова.
1. Математическое ожидание случайного отклонения ui равно нулю для всех наблюдений
![]()
Данное условие означает, что случайное отклонение ui в среднем не оказывает влияния на зависимую переменную. В каждом конкретном наблюдении случайное отклонение может быть либо положительным, либо отрицательным, но оно не должно иметь систематического смещения.
Фактически если уравнение регрессии включает постоянный член, то обычно бывает разумно предположить, что это условие выполняется автоматически, так как роль константы состоит в определении любой систематической тенденции в у, которую не учитывают объясняющие переменные, включенные в уравнение регрессии.
2. Дисперсия случайных отклонений постоянна для любых наблюдений.
![]()
Данное условие подразумевает, что несмотря на то, что при каждом конкретном наблюдении случайное отклонение может быть либо большим, либо меньшим, не должно быть какой-то причины, вызывающей большую ошибку (отклонение).
Выполнимость данной предпосылки называется гомоскедастичностью (постоянством дисперсии отклонений). Невыполнимость данной предпосылки называется гетероскедастичностью (непостоянством дисперсий отклонений).
Величина
![]() ,
конечно, неизвестна. Одна из задач
регрессионного анализа состоит в оценке
стандартного отклонения случайного
члена.
,
конечно, неизвестна. Одна из задач
регрессионного анализа состоит в оценке
стандартного отклонения случайного
члена.
3. Случайные отклонения ui и uj являются независимыми друг от друга для ij.
![]()
Выполнимость данной предпосылки означает отсутствие систематической связи между любыми случайными отклонениями. Т.е. величина и определенный знак любого случайного отклонения не должны быть причинами величины и знака любого другого отклонения.
Если данное условие выполняется, то говорят об отсутствии автокорреляции.
4. Объясняющие переменные не являются стохастическими.
![]()
Случайное отклонение должно быть независимо от объясняющих переменных. Значение любой независимой переменной в каждом наблюдении должно считаться экзогенным, полностью определяемым внешними причинами, не учитываемыми в уравнении регрессии.
Предположение о нормальности
Наряду с условиями Гаусса—Маркова обычно также предполагается нормальность распределения случайного отклонения. Дело в том, что если случайное отклонение и нормально распределено, то так же будут распределены и коэффициенты регрессии. Предположение о нормальности основывается на центральной предельной теореме. В сущности, теорема утверждает, что если случайная величина является общим результатом взаимодействия большого числа других случайных величин, ни одна из которых не является доминирующей, то она будет иметь приблизительно нормальное распределение, даже если отдельные составляющие не имеют нормального распределения.
Теорема Гаусса-Маркова. Если предпосылки 1 – 4 выполнены, то оценки, полученные по МНК, обладают следующими свойствами:
Оценки являются несмещенными, т.е. отсутствует систематическая ошибка в определении положения линии регрессии. M(b0)=0, M(b1)=1. Это вытекает из того, что M(i)=0.
Оценки состоятельны, так как дисперсия оценок параметров при возрастании числа n наблюдений стремится к нулю:
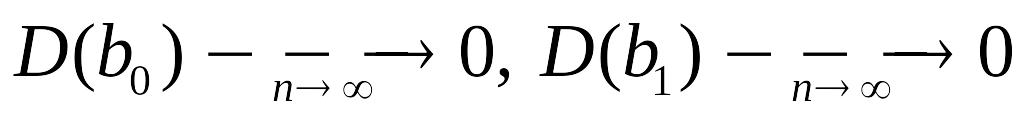 .
Другими словами, при увеличении объема
выборки надежность оценок увеличивается
(b0
наверняка близко к 0,
b1
- близко к 1).
.
Другими словами, при увеличении объема
выборки надежность оценок увеличивается
(b0
наверняка близко к 0,
b1
- близко к 1).Оценки эффективны, т.е. они имеют наименьшую дисперсию по сравнению с любыми другими оценками данных параметров, линейными относительно величин yi.
В англоязычной литературе такие оценки называются BLUE (Best Linear Unbiased Estimators) – наилучшие линейные несмещенные оценки.
Однако встает вопрос, насколько значимы параметры a и b? Какова величина погрешности?