

Властивості m (X) для двв і для нвв:
M (С) = С, де С = const;
M (X1 + X2+…+ Xn) = M (X1) + M (X2) + …+ M (Xn);
M (X1 X2 … Xn) = M (X1) M (X2) … M (Xn);
Математичне сподівання біноміального розподілу:
M (X) = n p,
де n – число випробувань, p – імовірність появи події в одному випробуванні.
Для НВВ X (-, ) або X [а, в ], диференціальна функція якої f (x) маємо відповідно:
M (X) =
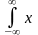 f(x)
dx; M (X) =
f(x)
dx; M (X) =
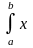 f(x)
dx.
f(x)
dx.
Можна довести, що для X, заданої диференціальною функцією f (x) 0 на відрізку [а, в], а зовні відрізку f (x) = 0, виконується а M (X) в.
Генеральна дисперсія (розсіяння, розкид) Dг випадкової величини X – математичне сподівання квадрату відхилення:
Dг D (X) = M [X – M (X)]2 M (X2) – [M (X)]2 ; D (X) =
=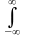 (x
– M (X))2f
(x) dx
x2f
(x) dx – [M
(X)]2 ;
(x
– M (X))2f
(x) dx
x2f
(x) dx – [M
(X)]2 ;
D (X) =
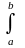 (x
– M (X))2f
(x) dx,
(x
– M (X))2f
(x) dx,
де можливі значення X (–, ) або X (а, в).
Властивості дисперсії:
D (X) 0; D (С) = 0; D (СX) = С2D (X); D (X Y) = D (X) + D (Y),
де X і Y – довільні незалежні випадкові величини. Розмірність (Dim) дисперсії дорівнює квадрату розмірності X. Дійсно, якщо X – випадкова сила F, то Dim X Dim F = Н (Ньютон), то D (X) має розмірність Dim D (X) = Dim M [X – M (X)]2 = Н2. Ось чому уводиться поняття – середнє квадратичне відхилення
(X) =
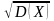 ,
де 2
= Dг.
,
де 2
= Dг.
Теоретичний початковий момент порядку k випадкової величини X – математичне сподівання величини Xk:
k = M (Xk).
Зокрема, початковий момент першого порядку
1 = M (X).
Центральний момент порядку k випадкової величини X – математичне сподівання величини: [X – M (X)]k :
k = M [ X – M (X)]k.
Зокрема, 1 = M [ X – M (X)] = 0,
2 = M [
X – M (X)]2
= D (X);
2 =
2 –
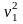 .
.
Для НВВ:
k = xk f (x) dx ; k = (x – M (X))k f (x) dx .
Інші характеристики НВВ X:
Мода Мo(X) можливе значення x0 X, якому відповідає max диференціальної функції f (x).
Медіана Мd(X) – те можливе значення xe X, яке визначається рівністю:
P (X < Мe(X)) = P (X > Мe(X)).
Іншими словами, медіана тлумачиться як точка xe, в якій ордината f (xе) поділяє наполовину площу, яка обмежена кривою розподілу.
Числові характеристики деяких законів розподілу
(більш детально і глибоко про це та інше є в [12]).
2.1. Рівномірний розподіл f
(x) = 1/(в – а), X
(а,
в). M
(X)=(а +
в)/2;D (X)=(в –
а)2/12; (X)=(в
– а)/2 .
.
2.2. Розподіл Лапласа f
(x) = 0,5 exp
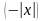 ,
X
(-, )
. M (X) = 0.
,
X
(-, )
. M (X) = 0.
2.3. Показниковий розподіл f (x) = exp (–x), x 0. M (X) = 1/ ; D (X) = 1/ 2; (X) = 1/ .
2.4.
Біноміальний розподіл Pn(k)
=
pk
qn-k
. M (K)
=
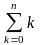 Pn(k)
= np; D
(K) =
npq.
Pn(k)
= np; D
(K) =
npq.
2.5. Розподіл Пуассона Pn(k) = ( ) / k! , = np = const, де –параметр розподілу. M (K) = D (K) = .
2.6. Нормальний розподіл N
(m, 2)
f
(x) = 1/(
)
exp – ,
,
де (X) = , D (X) = 2. M (X) = m.
Значення аргументу x = m
відповідає max
функції f (x)
– густини ймовірностей;
очевидно, при x = m
похідна
 = 0, при x
m похідна
0, при x
m
похідна
0, таким чином, точка
x = m є точкою
максимуму. За визначенням моди М0(X)
= m. Симетричність графіку
функції f (x)
відносно прямої x = m
дозволяє стверджувати, що медіана Мe(X)
= m. Таким чином, мода і
медіана нормального розподілу співпадають
з математичним сподіванням:
= 0, при x
m похідна
0, при x
m
похідна
0, таким чином, точка
x = m є точкою
максимуму. За визначенням моди М0(X)
= m. Симетричність графіку
функції f (x)
відносно прямої x = m
дозволяє стверджувати, що медіана Мe(X)
= m. Таким чином, мода і
медіана нормального розподілу співпадають
з математичним сподіванням:
M (X) = М0(X) = Мe(X) = m.
Нормалізований розподіл буде при
параметрах m = 0 та =1 і має вигляд:
N (0, 1) f (x) = 1/( ) exp (– x2/2).