

Параллельные вычисления.
Пример параллельной обработки информации N-устройствами в единицу времени.
Количество устройств |
Количество операций |
Единица времени |
1 |
1 |
1 |
1 |
1000 |
1000 |
5 |
1000 |
200 |
n |
1000 |
1000/n |
П ример
конвейерной обработки.
ример
конвейерной обработки.
В CISC – процессорах операции выполняются последовательно, одна за другой, пока не будет получен окончательный результат. Идея конвейерной обработки заключается в разбиении процесса выполнения инструкции на микроинструкции. Каждая микрооперация выполняет свою микропрограмму, передает результат следующая микроинструкция, одновременно принимая новые входные данные.
В большинстве процессорных систем используются 2 конвейера: команд и данных.
Зависимость по данным.
Д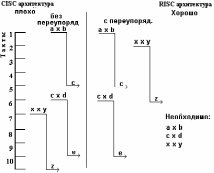 ля
разработки параллельной программы в
ней необходимо выделить части, которые
могут одновременно вычисляться разными
процессорами или функциональными
устройствами или разными ступенями
конвейера, такая возможность определяется
количеством или отсутствием в программе
инородных зависимостей. Таким образом,
чтобы распараллелить программу
необходимо найти инородную независимую
операцию, распределить между устройствами
и обеспечить их синхронизацию и
коммуникацию. Такой прием называется
предварительная выборка инструкций с
переупорядочиваем.
ля
разработки параллельной программы в
ней необходимо выделить части, которые
могут одновременно вычисляться разными
процессорами или функциональными
устройствами или разными ступенями
конвейера, такая возможность определяется
количеством или отсутствием в программе
инородных зависимостей. Таким образом,
чтобы распараллелить программу
необходимо найти инородную независимую
операцию, распределить между устройствами
и обеспечить их синхронизацию и
коммуникацию. Такой прием называется
предварительная выборка инструкций с
переупорядочиваем.
64-х разрядная архитектура.
64-х разрядная архитектура, использующая следующие особенности: Длинные слова команд; Предикаты команд; Устранение ветвлений; Предварительная загрузка данных.
Отличие архитектуры.
х86 |
IA - 64 |
1.использовались сложные инструкции переменной длины, обрабатываемые по одной. |
1. Простые инструкции, сгруппированные по три в один пакет (одинаковой длины) |
2. переупорядочивание и оптимизация инструкций во время выполнения. |
2. Переупорядочивание и оптимизация во время компиляции |
3. Попытка предсказания перехода |
3. Отсутствие предсказаний перехода |
4. Загрузка данных из памяти по мере необходимости с проверкой КЭШ памяти |
4. Загрузка данных до того, как они потребуются, КЭШ память проверяется предварительно. |
Особенности архитектуры.
Команды упакованы в 128 битный пакет для быстрой обработки. Это называется LIWencoding.
Этот пакет содержит шаблон из нескольких бит, шаблон помещается компилятором, в шаблоне указывается, какие команды можно выполнить параллельно.
Компиляторы IA –64 используют технологию «отмеченных команд» (предикаты) для устранения потерь производительности из-за неправильно предсказанных переходов.
Компиляторы этой архитектуры просматривают исходный код с целью поиска команд, использующих данные из памяти. Обнаружив такую команду, компилятор доставляет еще две команды: 1.Команда предварительной загрузки; 2. Проверка загрузки.
Во время выполнения программы первая команда загружает данные до того как они понадобятся программе, а вторая команда проверяет, на сколько успешно произошла загрузка.
«-»: Вся работа по оптимизации программного кода возлагается на компилятор; Программа, скомпилированная для одного поколения процессоров IA –64 может быть не эффективна для другого поколения; Увеличение размеров кода, следовательно, компиляция занимает больше времени; Совместимость с существующим программным обеспечением; Не все ветвления возможно предсказать и отметить. В этом случае на выполнение кода можно затратить больше тактов, чем сэкономить.