

184 Приложение 1
методом Бернштейна это дает следующие результаты (подробнее в разд. 3.2.2):
p = 0,287685 + 0,002411, q = 0,106555 ±0,001545, r = 0,605760 ±0,002601.
Было показано, что метод максимального правдоподобия приводит к точно таким же результатам [711]. Дисперсии по методу максимального правдоподобия получились следующими:
Vp = 0,000005811, Vq = 0,000002386, Vr = 0,000006763.
Для получения стандартных отклонений нужно извлечь квадратные корни из этих дисперсий.
Точно так же, как было показано для групп крови MN, по частоте аллелей А, В и О можно вычислить ожидаемые генотипические частоты и сравнить их с наблюдаемыми частотами по критерию хи-квадрат.
Еще более сложные проблемы возникают при анализе групп крови Rh и вообще при анализе всех систем, в которых вместе
наследуется много разных комбинаций антигенов. Для этих случаев опубликованы или упомянуты в публикациях компьютерные программы. Для системы Rh можно воспользоваться публикациями [585; 586]. Рядом авторов предложены правила вычисления частот аллелей и гаплотипов для системы HLA [554; 738; 779; 805; 962]. Находит свое применение также система ALLTYPE [789].
Однако неадекватность составления выборки не компенсируется обработкой на компьютере. Все упомянутые до сих пор методы основаны на предположении, что выбор индивидов проводился независимо, т .е. выбор какого-либо одного индивида не увеличивает и не уменьшает шанс быть выбранным для любого другого индивида в популяции. Это правило нарушается, например, при сборе данных о родственниках. Однако нельзя сказать, что выборки, содержащие родственников, всегда бесполезны для вычисления генных частот. Но включение родственников в выборку должно быть обязательно отмечено вместе со степенью их родства, и для анализа должны использоваться специальные статистические методы [211].
Приложение 2 Анализ сегрегации распространенных признаков: отсутствие смещений вследствие регистрации, доминирование [876; 877]
Если тип наследования кодоминантный, так что каждый генотип соответствует своему, отличному от других фенотипу, и если анализируемые семьи выбирались из популяции независимо от генотипов их членов, то анализ сегрегационных отношений проводится непосредственно. В этом случае число. индивидов в каждом генотипическом классе следует сравнивать с числом, ожидаемым из распределения на основе менделевского закона, с помощью критерия хи-квадрат, как показано в разд. 3.3.3 и табл. 3.7. |
При доминировании сегрегационный анализ сложнее, чем при кодоминантном наследовании. В фенотипическом браке |
|
АА x Аа и Аа x Аа. Оригинальный метод сегрегационного анализа был разработан Смитом [876]. |
Тип брака А x а. В этой группе представлены два генотипических брака АА x аа и Аа x аа. Первый дает только детей с генотипом Аа и с фенотипом А, а второй - детей Аа и аа в соотношении 1:1. Для иллюстрации используются данные по группам крови (табл. П.2.1, П.2.2). Ниже приводятся численности семей по крайней мере с одним рецессивным ребенком (аналог регистрации семей по «пораженным» потомкам) |
|
Ожидается, что в этих семьях число детей с рецессивным фенотипом подчиняется «усеченному биномиальному распределению» Например, ожидаемое соотношение двухдетных семей с 0, 1 или 2 рецессивными |
детьми должно быть равным 1:2:1. Однако класс с нулем рецессивов отсутствует в силу способа регистрации. Следовательно, с вероятностью 2/3 двухдетная семья будет иметь одного рецессивного потомка и с вероятностью 1/3 - двух. Ожидаемое число рецессивных детей в двухдетных семьях равно |
|
а дисперсия |
|
В принципе те же рассуждения можно использовать для семей с 3, 4 и большим числом детей и вычислить а3, a4 ··· и b3, b4... . В общем случае вероятность того, что семья из s детей по крайней мере с одним рецессивным ребенком имеет точно r рецессивных детей, равна |
|
(ср. с биномиальным распределением, разд. 3.3.2). Отсюда вытекает, что |
|
Ожидаемое общее число детей с рецессивным фенотипом в выборке составит |
|
(используя данные Смита, приведенные здесь в табл. П.2.3). Дисперсию этой величины можно вычислить из аналогичной |
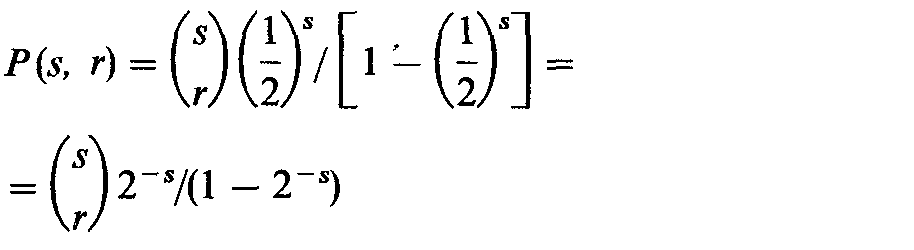
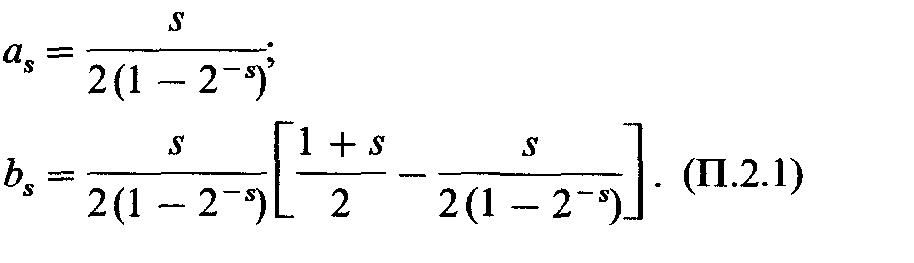
186 Приложение 2
Таблица
П.2.1. Фенотипический брак |
|
линейной комбинации значений b v1 = 8,555. Общий вид формул следующий: |
|
Наблюдаемое число рецессивов (из табл. П.2.1) равно |
O1 = 11 χ 1 + 10 χ 2 + 2 χ 3 = 37. |
|
Таблица П. 2.2.
Фенотипический брак |
|


типическому браку А х А (табл. П.2.2) с той лишь разницей, что в браке Аа х Аа дети с фенотипами А и а ожидаются в соотношении 3:1. Ожидаемые средние значения As и дисперсии Bs можно взять из табл. П.2.3. В 10 семьях по крайней мере с одним ребенком наблюдались 11 таких детей. Сравнивая эту величину с ожидаемым средним значением Е2 = 12,3 и дисперсией V2 = 2,069, получаем |
|
Снова наблюдаемые значения превосходно соответствуют ожидаемым. |
До сих пор мы не использовали генные частоты. Наблюдаемые численности семей по крайней мере с одним рецессивным ребенком нужно сравнить с ожидаемыми численностями таких семей, рассчитанными из общего количества семей в выборке. Для этого необходимы надежные оценки генных частот. Их можно получить, имея большую выборку случайных индивидов из популяции. Фенотипический брак Axa, например, может включать два генотипических АА х аа и Аа х аа. Их ожидаемая частота |
Таблица П.2.3. Ожидаемые средние значения аs, дисперсии bs и величины ds для фенотипического брака A x a. Ожидаемые средние значения As, дисперсии Bs и величины Ds для фенотипического брака А х А [876] |
|
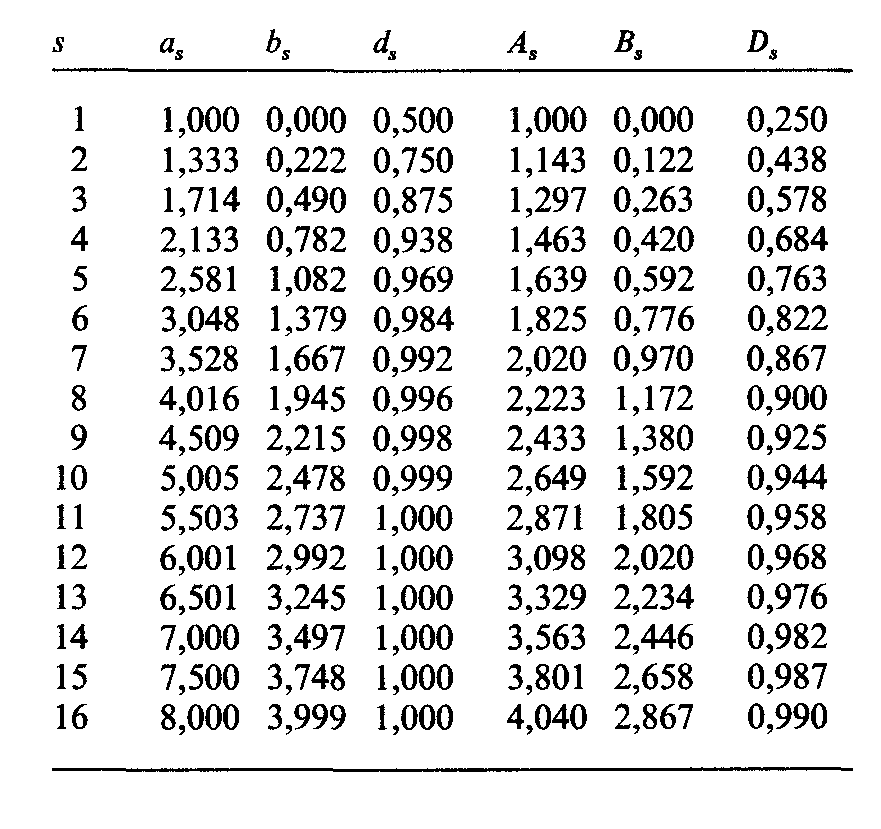
Приложение 2 187
2 x ρ2 x q2 + 2 x 2pq x q2 = 2p2q2 + 4pq3. В то же время это значение является вероятностью того, что случайно выбранный брак будет иметь фенотип А х а. На самом деле семья может иметь рецессивного ребенка, только если генотипический брак будет Аа х аа. Даже в этом случае вероятность иметь по крайней мере одного рецессивного ребенка среди s детей равна 1 - (l/2)s, т. к. с вероятностью (1/2)S будут появляться только доминантные дети. |
По этой причине вероятность π того, что семья типа Аха с s детьми будет иметь по крайней мере одного рецессивного ребенка, составит |
|
Значения ds приведены в табл. П.2.3, и когда известны генные частоты, то легко вычислить uds. Если имеется ns семей размера s (s = l, 2, ...), то ожидаемые среднее значение и дисперсия числа семей по крайней мере с одним рецессивным ребенком составят |
|
Таблица П.2.4. Ожидаемые и наблюдаемые частоты семей с рецессивными детьми, фенотипический брак А х à |
|
|
|
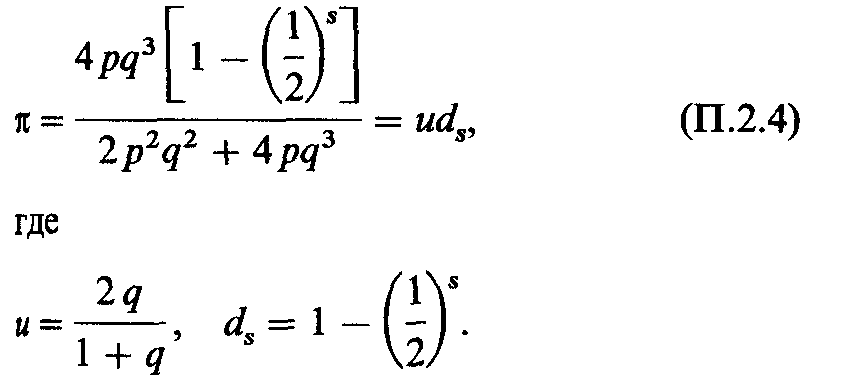

Таблица П.2.5. Ожидаемые и наблюдаемые частоты семей с рецессивными детьми, фенотипический брак ÄxÄ |
|
Например, генная частота q рецессивного аллеля ρ в системе Ρ равна 0,51. Следовательно, и = 0,675. Дальнейшие вычисления приведены в табл. П.2.4. |
В принципе те же расчеты можно выполнить для А х А семей с u2 и Ds = 1 — — (3/4)s вместо u и d соответственно; значения Ds приведены в табл. П.2.5. |
Все сравнения собраны вместе в табл. П.2.6, где приведена также сумма всех сравнений. В первых двух строках таблицы представлены значения критерия хи-квадрат для сравнения с ожидаемыми сегрегационными отношениями, а в следующих двух - наблюдаемые частоты разных типов брака сравниваются с ожидаемыми на основе закона Харди-Вайнберга, при этом используются генные частоты. Такое четкое разделение делает метод более понятным. |
Таблица П.2.6. 2-сравнения |
|
|
|

