

Вторая нормальная форма
Вторая и третья нормальные формы касаются отношений между ключевыми и неключевыми атрибутами. Реляционная таблица находится во второй нормальной форме (2НФ), если никакие неключевые атрибуты не являются функционально зависимыми лишь от части ключа. Таким образом, 2НФ может оказаться нарушена только в том случае, когда ключ составной, то есть ключом является набор из нескольких атрибутов.
Рассмотрим реляционную схему на рис. 6. В ней ключ состоит из атрибутов WORKER-ID и BLDG-ID. NAME определяется атрибутом WORKER-ID и, следовательно, функционально зависит от части ключа. Это означает, что для определения имени работника достаточно знать WORKER-ID. Таким образом, таблица не удовлетворяет 2НФ. Если мы оставим эту таблицу в таком виде, не приведя ее к 2НФ, то могут возникнуть следующие проблемы:
1. Имя работника повторяется в каждой строке, относящейся к назначению этого работника.
2. Если имя работника изменяется, то требуется обновить все строки содержащие записи о назначениях этого работника.
3. Из-за такой избыточности может возникнуть несоответствие данных, когда в разных строках содержатся разные имена для одного и того же работника.
4. Если в какой-то момент времени работник не имеет назначений, то может не оказаться строки, в которой можно хранить имя работника. Это аномалия ввода.
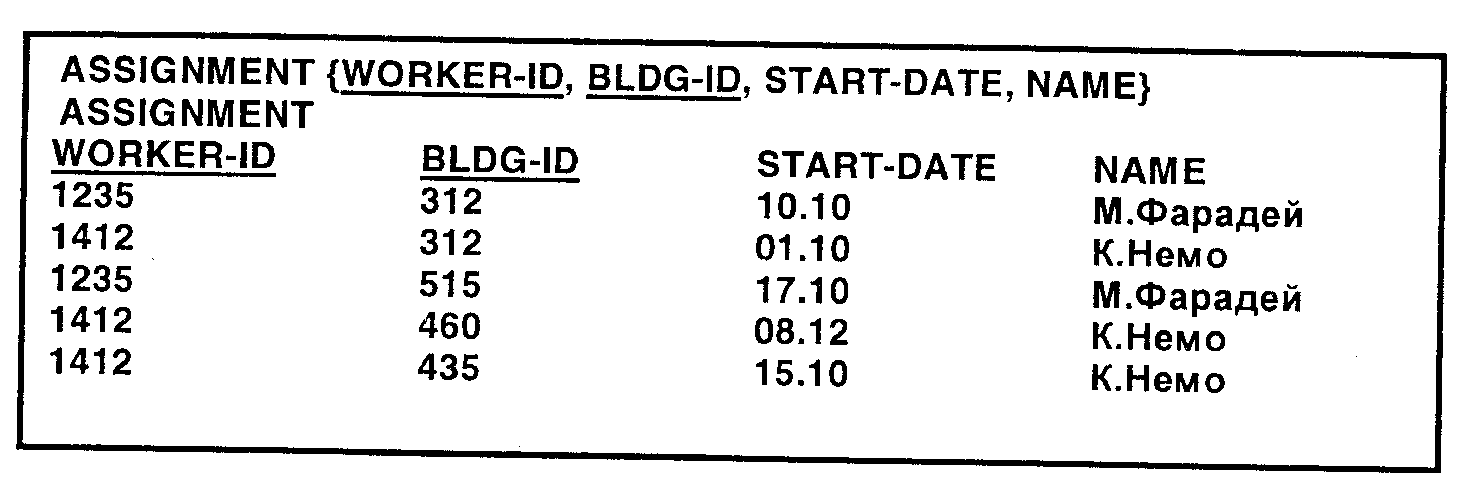
Рис. 6. Реляционная таблица ASSIGNMENT
Для того чтобы решить эти проблемы, таблицу необходимо разбить на две реляционные таблицы, каждая из которых удовлетворяет 2НФ:
ASSIGNMENT {WORKER-ID, BLDG-ID, START-DATE} Внешний ключ: WORKER-ID ссылается на WORKER WORKER {WORKER-ID, NAME}
Ясно, что эти две реляционные таблицы находятся во 2НФ и исключают перечисленные выше проблемы. Таким образом, 2НФ сокращает избыточность данных и несоответствия. Однако, она может усложнить работу некоторых приложений, извлекающих данные. Если бы мы хотели получить имена всех работников, назначенных на данное здание, то нам пришлось бы каким-то образом скомбинировать данные из этих двух таблиц.
Эти две меньшие таблицы называются проекциями исходной таблицы. Легко видеть, что проекция просто выбирает некоторые атрибуты исходной таблицы и представляет их в виде новой таблицы. Это достаточно просто. Теперь содержимое таблиц ASSIGNMENT и WORKER выглядит так, как показано на рис. 7. Обратите внимание, что таблица ASSIGNMENT по-прежнему состоит из пяти строк, так как наборы значений атрибутов WORKER-ID. BLDG-ID и START-DATE (ДАТА-НАЧАЛА), взятые вместе, были различны. Однако таблица WORKER теперь состоит лишь из двух строк, так как существует лишь два различных набора значений для атрибутов WORKER-ID и NAME. Таким образом, избыточность данных и возможность аномалий исключены.
Проекция таблицы. Таблица, состоящая из нескольких выбранных атрибутов другой таблицы.
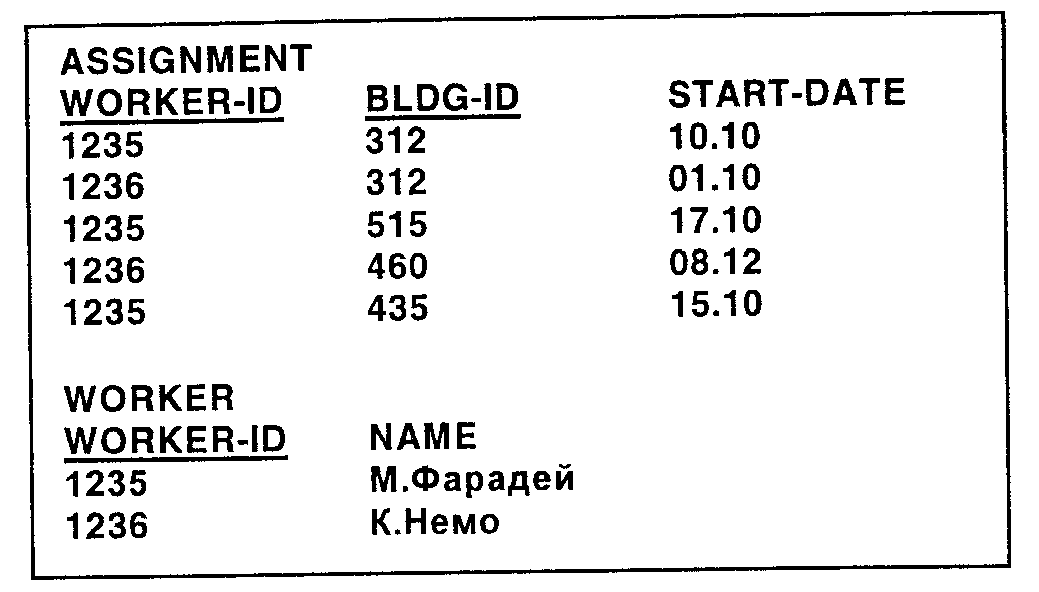
Рис. 7. Таблицы ASSIGNMENT и WORKER, обе в 2НФ
Процесс разбиения на две 2НФ-таблицы состоит из нескольких простых шагов, первые два из которых были проиллюстрированы нашим примером:
Создается новая таблица, атрибутами которой будут атрибуты исходной таблицы, противоречащей правилу ФЗ. Детерминант ФЗ становится ключом новой таблицы.
Атрибут, стоящий в правой части ФЗ, исключается из исходной таблицы.
Если более одной ФЗ нарушают 2НФ, то шаги 1 и 2 повторяются для каждой такой ФЗ.
Если один и тот же детерминант входит в несколько ФЗ, то все функционально зависящие от него атрибуты помещаются в качестве неключевых атрибутов в таблицу, ключом которой будет детерминант.