

1.1. Введение
1.2. Определение эконометрики. Примеры решения эконометрических задач
1.3. Определение слова «спецификация»
1.4. Требования к спецификации эконометрической модели
1.5. Дополнительный материал
1.1. Введение
Приводим основные математические обозначения, формулы, которые будут использованы по курсу эконометрика.
Массив чисел: 10, 15, 19, 21 можно обозначить: х1, х2, х3, х4 или Хi, i = 1, 2, 3, 4
Массив чисел можно представить в разных видах:
- перечислением: х1=10, х2= 15, х3= 19, х4= 21;
- таблицами:
-
i
Хi
1
10
2
15
3
19
4
21
-
i
1
2
3
4
Хi
10
15
19
20
Сумма массива чисел - ΣХi = х1+х2+х3+х4 = 10+15+19+21= 65
-
i
Хi
1
10
2
15
3
19
4
21
Сумма
65
Среднее значение массива чисел: Хс = (ΣХi)/n = (х1+х2+х3+х4)/4 = (10+15+19+21)/4=65/4=16,25,
-
i
Хi
1
10
2
15
3
19
4
21
Сумма
65
Среднее
16,25
Вариация массива чисел: Σ(Хi-Хс)2 = (х1-Хс)2 + (х2-Хс)2 (х3-Хс)2 (х4-Хс)2 = (10-16,25)2+(15-16,25)2+(19-16,25)2+(21-16,25)2 = 39,06+1,56+7,56+22,56= 70,74
-
i
Хi
(Хi-Хс)2
1
10
39,06
2
15
1,56
3
19
7,56
4
21
22,56
Сумма
65
70,74
Среднее
16,25
Дисперсия массива чисел: S2 = (Σ(Хi-Хс)2)/(n-1)= 70,74/(4-1) = 23,58,
-
i
Хi
(Хi-Хс)2
1
10
39,06
2
15
1,56
3
19
7,56
4
21
22,56
Сумма
65
70,74
Среднее
16,25
S2
23.58
Среднее квадратическое отклонение массива чисел: S= корень(S2) = корень (23,58) = 4,85
-
i
Хi
(Хi-Хс)2
1
10
39,06
2
15
1,56
3
19
7,56
4
21
22,56
Сумма
65
70,74
Среднее
16,25
S2
23.58
S
4.85
Х – матрица
-
10
Х =
15
19
21
Хт – транспонированная матрица
-
Хт =
10
15
19
21
ХтХ – произведение матриц, Хт – первая матрица, Х – вторая матрица
ХтХ = 10*10+15*15+19+19+21*21 = 1127
Х-1 – обратная матрица Х.
Обозначим выборочные наблюдения через
Х1, Х2, …, Хn;
У1, У2, …, Уn
и введем их арифметические средние
 Х
=
Х
= ,У
=
,У
= ,
,
где
 =
Х1+Х2+ …+Хn;
=
Х1+Х2+ …+Хn;
X – фактор, объясняемая переменная, влияющая на следствие У;
У – следствие, зависимая переменная.
Греческими буквами обозначают параметры модели для генеральной совокупности.
Например, 0, 1 – параметры линейной модели У=0+1X+ для генеральной совокупности,
Где - случайное возмущение или ошибка модели, которая состоит из ошибки уравнения и ошибки измерения.
Латинскими буквами обозначают коэффициенты уравнения регрессии для выборочной совокупности.
Например, а0, а1 – коэффициенты уравнения регрессии У = а0+а1Х+е для выборочной совокупности,
где е = У - (а0 + а1Х) = У - Уp -– отклонение или остаток (Гаусс называл его убытком, В эконометрической литературе принято е называть остатком), учитывающий влияние всех факторов, не включенных в модель;
У – фактические значения зависимой переменной;
Уp= а0+а1Х - расчетные значения У;
Х – фактор.
- белый шум.
m – число степеней свободы.
n – объем выборки.
Т – период периодического колебания.
k – количество всех коэффициентов в модели (включая свободный коэффициент).
Например, уравнение регрессии У=а0+а1Х + е имеет два коэффициента: а0 и а1, следовательно k = 2.
t – индекс времени в моделях временных рядов.
Например, Уt = a0+a1Xt +et, t – индекс времени.
ta1 – фактическое значение критерий Стьюдента для коэффициента а1.
Например, tа1 = a1/Sa1,
где Sa1 – среднее квадратическое отклонение коэффициента а1 от своего математического ожидания 1, или ошибка коэффициента а1.
t/2( = 0.05, m = n - 1) или t/2 – двухстороннее (критическое) табличное значение критерия Стьюдента.
t( = 0.05, m = n - 1) или t – одностороннее (критическое) табличное значение критерия Стьюдента,
где - уровень значимости критерия или вероятность ошибки при отклонении верной нулевой гипотезы или вероятность совершить ошибку первого рода;
ошибка первого рода – неправильное отклонение нулевой гипотезы;
m = n - 1 – число степеней свободы для критерия Стьюдента.
Например, в уравнении регрессии У=а0+а1Х+е, У – зависимая переменная, Х – фактор.
В системах одновременных уравнений У может выступать как объясняемая переменная.
У 1
= а0+а1Х1+а2У2+
е1,
1
= а0+а1Х1+а2У2+
е1,
У2 = b0+b1X2 +b2У1 + е2
В первом уравнении: У1 – зависимая переменная, Х1 – фактор, У2 – объясняемая переменная.
Во втором уравнении: У2 – зависимая переменная, Х2 – фактор, У1 – объясняемая переменная.
Введем обозначения уравнения регрессии для трех переменных.
Предположим, мы имеем три связанные между собой переменные, которые обозначим через X1, X2, У. Переменная У может, например, отражать количество покупок некоторого товара в домашнем хозяйстве семьи, Х1 – цена товара, Х2 – доход семьи. Произведем выборку объемом n из генеральной совокупности, составляющая N семей. Численные значения переменных выборки мы будем записывать в таблице 0.1.
Таблица 0.1. - Исходные значения выборочной совокупности
-
i
X1
X2
У
1
X11
X21
У1
2
X12
X22
У2
i
X1i
X2i
Уi
…
…
…
…
n
X1n
X2n
Уn
Здесь Хdi обозначает величину переменной Хd для i-го домашнего хозяйства. Гипотеза о линейной зависимости У от Х1 и Х2 может быть записана в виде
Уi = α0 + α1X1i + α2X2i + i , i = 1, 2, … , n.
Примечание. Большинство статистических пакетов предполагает предложенную схему размещения переменных в таблице базы данных: сначала размещают столбцы факторов Хd, последним ставят столбец зависимой переменной У.
Е – ошибка модели.
F – фактическое значение критерия Фишера.
Fкр(α = 0,05; m1 = k - 1; m2 = n - k) – критическое значение критерия Фишера на уровне значимости α и числе степеней свободы m1, m2.
S – среднее квадратическое отклонение для выборочной совокупности.
S2 – дисперсия для выборочной совокупности.
- среднее квадратическое отклонение для генеральной совокупности.
2 – дисперсия для генеральной совокупности.
М – условное обозначение математического ожидания.
Например. М(i) = 0 при всех i = 1, 2, … , n.
r – коэффициент корреляции.
r2 – коэффициент детерминации.
R – множественный коэффициент корреляции.
R2 – множественный коэффициент детерминации.
Буквы в формулах, выделенные полужирным шрифтом, означают матрицу.
Например. В формуле
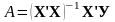
А, Х, У - матрицы.
Расчетные формулы. Расчет коэффициентов регрессионного уравнения
У = а0 + а1Х + е


где А - матрица коэффициентов модели; Х и У - матрицы соответственно факторов и зависимой переменной.
Ошибка модели:

где Урi = а0 + а1Хi .
Основное вариационное уравнение


где = Собщ. – вариация общая;

= Сост – вариация остатков;
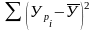
= Срег = Собщ- Сост – вариация регрессии.

Sобщ2 = - дисперсия общая.

Sоcт2 = - дисперсия остатков.

Sрег2= - дисперсия регрессии.

- коэффициент детерминации.
Множественный коэффициент детерминации:
 .
.
Критерий Фишера:

.
Ошибка коэффициента а0:

.
Ошибка коэффициента а1:

Критерий Стьюдента для коэффициента а1:

.
Частный коэффициент детерминации для фактора Х1:

где ti - критерий Стьюдента для фактора Хi
Точечный прогноз:
Упр = а0+а1Хож,
где Хож – ожидаемое значение Х.
95% интервальный прогноз для математического ожидания У:

Р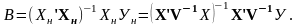 асчет
коэффициентов модели методом Эйткена:
асчет
коэффициентов модели методом Эйткена:
Парный коэффициент корреляции:

Частный коэффициент корреляции:

где Сij – элементы обратной матрицы от матрицы всех парных коэффициентов корреляции.
Критическое значение коэффициента корреляции:

где t/2 = t/2( = 0,05; m = n - 2).
Коэффициент автокорреляции:
 .
.
Критерий Дарбина – Уотсона (Дарбина – Ватсона):
 .
.
Элементы математической статистики
Напомним основные правила работы с массивами чисел и основные формулы математической статистики, которые потребуются нам в дальнейшем изложении курса.
Операции суммирования
Пусть величина Х задается последовательностью данных Х1, Х2, … , Хn, каждое из которых можно записать как Хi, i = 1, , n.
Сумма этих чисел записывается следующим образом:
 .
.
Если из текста понятно, какие начальные и конечные суммируемые члены, то можно использовать сокращенное обозначение:
 .
.
Обозначим:
 -
среднее значение величины Х.
-
среднее значение величины Х.
Правила суммирования (а, b – константы):
1. Σа = na.
2. ΣaХi = aΣХi = anХ.
3. Σ(a+bХi) = na+bnХ.
4. Σ(Хi+Уi) = ΣХi + ΣУi = n(Х + У).
5. Σ(Хi-Х)=0.
6.
 .
.
7.
 .
.
Математическое ожидание дискретной случайной величины – это взвешенное среднее всех ее возможных значений, причем в качестве весового коэффициента берется вероятность соответствующего исхода.
Предположим, что Х может принимать n конкретных значений
(Х1, Х2, …, Хn) и что вероятность получения Хi равна pi, тогда
М(Х) = Х1р1 +Х2р2+…+Хnpn = ΣХipi .
Если рi = ni/n, i = 1, 2, …, k, где Σni = n, то
М(Х) = Х1р1 +Х2р2+…+Хkpk = (Х1n1 +Х2n2+…+Хknk )/n =
= (ΣХini)/n = X.
Если ni = 1 для каждого i= 1, 2, …, n, то
М(Х) = (Х1 +Х2+…+Хn)/n = (ΣХi)/n = X.
Свойства математического ожидания:
(а, b – константы; Х, У – случайные величины; р – вероятность случайной величины)
1) М(а) = а;
2) М(аХ) = аМ(Х);
3) М(а+bX) = a + bM(X);
4) M(X + У) = М(Х) + М(У);
5) М(ХУ) = М(Х) М(У), при условии, что Х и У не связаны между собой;
6) математичемкое ожидание функции f(X) определяется выражением:
М(f(X)) = Σf(Xi)pi.
Например, если f(X) = X2 , то М(f(X)) = М(Х2) = ΣХi2 pi.
Свойства дисперсии:
* Дисперсия для генеральной совокупности
σ2 = D(X)=M(Xi-X)2;
a, b – константы, Х – случайная величина
1) D(a) = 0;
2) D(aX) = a2D(X);
3) D(a+bX) = b2D(X).
* Дисперсия для выборочной совокупности
Var(X)
=
 .
.
Выборочная дисперсия var(X) является смещенной оценкой генеральной дисперсии σ 2, при этом
М[Var(X)]
=
 .
.
В качестве несмещенной оценки генеральной дисперсии используется величина
S2
=

1) Var(a) = 0;
2) Var(aX) = a2Var(X);
3) Var(a+bX) = b2Var(X).
Основные понятия регрессионного анализа
Линейная регрессионная модель. Зависимость следствия У от причины Х моделируется с помощью линейного регрессионного уравнения
Уi = a0 + a1Xi + ei,
где Уi - фактическое значение товарооборота;
Хi - фактическое значение затрат на рекламу;
i - порядковый номер измерения.

Рис. 1.2. Структура регрессионного уравнения Уi =а0+а1Хi+еi=Урi+еi
Уpi=a0+a1Хi - расчетные значения товарооборота отражают существующую связь между У и X;
ei = (Уi - Уpi) - остатки модели, отражают влияние неучтенных факторов;
a1- коэффициент модели, определенный методом наименьших квадратов, численно равный приросту значения У при изменении Х на единицу.


где - ковариация или сумма произведений отклонений значений X и У от своих средних значений;
Х - среднее значение Хi;
У - среднее значение Уi;
 -
вариация переменной Х или сумма квадратов
отклонений
-
вариация переменной Х или сумма квадратов
отклонений
значений X от своего среднего значения;
- коэффициент модели, определенный методом наименьших квадратов, численно равный значению Ур при значении Х равном нулю.
Виды моделей:
модель распределенных лагов:
Уt = 0 + 1Xt + 2Xt-1 + 3Xt-2+ t;
авторегрессионная модель распределенных лагов:
Уt = 0 + 1Xt + 2Уt-1 + t;
авторегрессионная модель:
Уt = 0 + 1Уt-1 +2Уt-2 + t;
модель скользящей средней:
t= t + t-1 + 2 t-2 + t ;
модель последовательных отклонений:
Уt = Уt – Уt-1, t = 2, … n;
модель периодических составляющих временного ряда:
Уt = 0 + 1t + 2Sin(2t/T1) + 3Cos(2t/T1) + 4Sin(2t/T2) + 5Cos(2t/T2) + … + t, где Т1, Т2 периоды для сезонной и длинно периодической составляющей;
модель экспоненциально взвешенного среднего:
Zt = Уt+ (1-)Уt-1 + (1-)2Уt-2 + (1-)3Уt-3 +…. =
=Уt + (1-)[Уt-1 + (1-)Уt-2 + (1-)2Уt-3+ …];
линейная модель с автокоррелированными возмущениями:
Уt =0 +1Хt + ρt-1+ t.
Прогноз по линейной модели с автокоррелированными возмущениями:
Упр(n+1) = 0 + 1Xn+1 + n.
Метод устранения гетероскедастичности:
Уi/|ei| = a0/|ei| + a1XI/|ei| + ei/|ei| .
ЛИНЕЙН – функция Ехсе1, для расчета коэффициентов и качества линейной модели.
Регрессия – программа Ехсе1 для расчета коэффициентов и качества линейной модели.