

9.Код Голея: параметры, доказательство оптимальности, схемы кодирования
Код Голея - совершенный двоичный код (23, 12, 7) (имеет длину n = 23, число информационных символов k = 12, кодовое расстояние d = 7) кода, способный исправлять до трех ошибок в словах длиной 23 символа.
Троичный код Голея : (11, 6, 5).
Расширенный двоичный код линейный код Голея (24, 12, 8) получается из кода Голея путем добавления ко всем кодовым комбинациям проверочного символа. Он тоже совершенный.
Линейный код Голея (23, 12) можно генерировать как циклический код посредством порождающего полинома g(p)=p11+p9+p7+p6+p5+p+1. Кодовые слова имеют минимальное расстояние dmin=7.
Код является совершенным, т.к. удовлетворяет границе Хэмминга с равенством:
для
двоичного блокового кода (n,
k)
с корректирующей способностью t
граница Хэмминга определяется неравенством
 .
Существование совершенного кода Голея
подтверждается тем, что
.
Существование совершенного кода Голея
подтверждается тем, что
 .
.
Кодирование. Из-за относительно небольшой длины (23) и размерности (12) кодирование м декодирование двоичного кода может выполняться табличным методом. Кодирование реализуется просмотром таблицы, содержащей список всех 212=4096 кодовых слов, которые пронумерованы непосредственно информационными символами. Обозначим u информационный вектор размерности 12 бит и v – соответствующее кодовое слово (23 бита). Табличный кодер использует таблицу, в которой для каждого информационного вектора вычислен и записан синдром (11 бит). Синдром берется из таблицы и приписывается справа к информационному вектору. То есть для кодирования производится взаимно однозначное отображение из множества векторов u на множество векторов v.
Декодирование. Задачей декодера является оценка наиболее вероятного (обладающего минимальным Хэмминговым весом) вектора ошибок по принятому вектору. Процедура табличного декодирования:
1) выписать все возможные вектора ошибок e, вес Хэмминга которых не превышает 3;
2) для каждого вектора ошибок вычислить соответствующий синдром s;
3) записать в таблицу для каждого значения s соответствующий ему вектор e.
Кодирование как циклический код
Рисунок 1– Кодирование с помощью (n – k) – разрядного
регистра сдвига
10. Алгебро-геометрический подход
Пусть
 ,
а также
,
а также
 конечное поле.
конечное поле.
Положим
 (обычно
(обычно
 ).
).
Пусть
 и пусть
и пусть
 .
.
Определим отображение через оценку

которая
отображает f(x)
в вектор


где

Определение 2
q-ичный
РС-код с параметрами [n,k],
определяется
как множество оценочных значений
полиномов
 .
.

Множество P будем называть множество точек с.
Пример 1

Положим
α=3 –
примитивный элемент, тогда



Т.к.



Т.к.

Пример 2
Найдем
 для кода РС
(15,11) над
полем GF(16)
для j0=1,
n-k=4=2t.
для кода РС
(15,11) над
полем GF(16)
для j0=1,
n-k=4=2t.
Решение:

Информационный многочлен – 11 символов поля.
Каждый символ несёт информацию в 4 бита, т.е. эквивалентная ёмкость информации сообщения будет 44 бита.
11.Алгоритм Берлекэмпа-Месси: его применение при декодировании помехоустойчивых кодов и при анализе линейной сложности криптографических функций
Алгоритм Берлекэмпа — Мэсси — алгоритм построения наиболее короткого регистра с обратными связями, порождающего m компонент синдрома S по правилу:
![]() где
ν
- количество произошедших ошибок;
r=ν+1,
…, 2ν
где
ν
- количество произошедших ошибок;
r=ν+1,
…, 2ν
и перестраивающего свою структуру в зависимости от возможной ошибки в структуре формируемого сигнала:
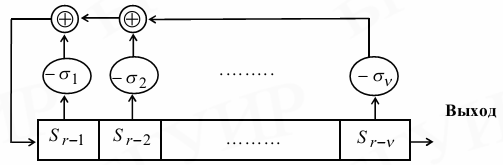
Для нахождения полинома локатора ошибок используется итерационная процедура. На каждой итерации вычисляется модель регистра с обратными связями, генерирующего первые r компонентов синдрома, где r – номер этапа. Длина регистра на r-м этапе обозначается Lr .
Теорема Берлекемпа–Месси. Пусть заданы компоненты синдрома S1, … S2t из некоторого поля, тогда при начальных условиях σ(0)(x)=1, B(0)(x)=1, L0=1 выполняются следующие рекуррентные равенства, использующиеся для вычисления σ(x):

При выполнении таких условий полином σ(x) является многочленом наименьшей степени, коэффициенты которого удовлетворяют равенству
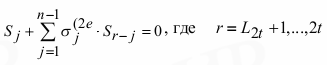
Граф-схема алгоритма Берлекемпа–Месси приведена на рисунке.
Задача декодера – найти полином Λ(z) или σ(z) минимальной степени ν , где ν - число ошибок, причём заранее не известное. Алгоритм Берлекемпа – Месси позволяет строить такую последовательность полиномов σj (z), j=1, 2, …m, в которой каждый последующий полином удовлетворяет большему числу уравнений. Одновременно итеративно вычисляется полином величин ошибок Ω(z).
Исходные данные - это m компонент синдрома S , где обычно b=1 . Начальные условия для полиномов σ(z), Ω(z), C(z), D(z) и переменной L задаются вначале.
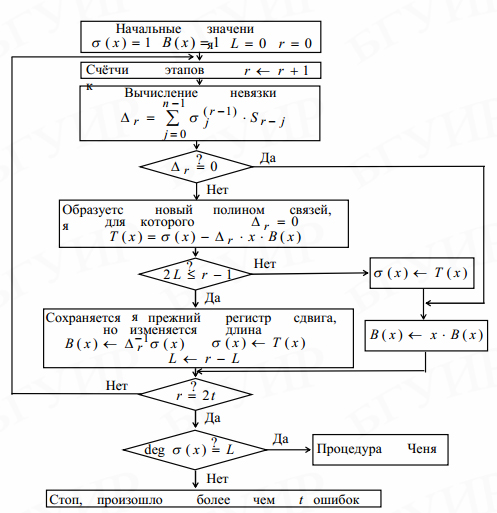
Алгоритм выполняется за m итераций. Если в процессе вычислений невязка Δ=0 , то полиномы σ(z) и Ω(z) не изменяются, в противном случае осуществляется их коррекция

где Cj-1(z) и Dj-1(z) - вспомогательные полиномы, взятые из предыдущего шага. На шаге j они формируются из следующих соображений. Если 2Lj-1 > j-1, то содержание регистров, хранящих эти вспомогательные полиномы, сдвигается: C(z)=z C(z); D(z)= zD(z) , а переменная L не изменяется. При 2L j-1 ≤ j-1 указанные полиномы и переменная L трансформируются :
![]()
По окончании m итераций целесообразно выполнить проверку : deg σ(z)=L ; если это равенство несправедливо, то вырабатывается сигнал FLAG=1 защитного отказа от декодирования, так как принятое слово содержит более чем t ошибок.
Линейной сложностью конечной двоичной последовательности Sn называется число, которое равно длине самого короткого регистра сдвига с обратными связями, который генерирует последовательность, имеющую в качестве первых членов Sn . То есть с помощью алгоритма БМ составляется регистр сдвига, длина которого численно равна линейной сложности последовательности.
12. Вычисление синдрома ошибок помехоустойчивых кодов с помощью спектральных преобразований в поле Галуа.

Выберем
и зафиксируем некоторое поле Галуа
GF(q) с
![]() ,
примитивный элемент
,
примитивный элемент
![]() и
параметр d.
Рассмотрим
информационный вектор
и
параметр d.
Рассмотрим
информационный вектор
![]() длины
k = n — d+ 1 = q —
dc компонентами
из GF(q). Поставим
в соответствие вектору и вектор
длины
k = n — d+ 1 = q —
dc компонентами
из GF(q). Поставим
в соответствие вектору и вектор
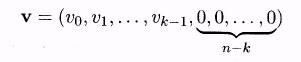 длины
п =
q — 1,
у которого первые k
компонент
совпадают с компонентами вектора и,
а остальные компоненты — нулевые.
Рассмотрим прямое преобразование Фурье
вектора v
в вектор V,
определяемое (5.1) и удовлетворяющее
теореме 5.2.1. Тогда справедлива следующая
теорема:
Теорема
5.3.2. Множество
qk
векторов V
в частотной области образует (п,
k)-код Рида
- Соломона.
Теорема
5.3.3. Любой
код Рида - Соломона является МДР кодом.
длины
п =
q — 1,
у которого первые k
компонент
совпадают с компонентами вектора и,
а остальные компоненты — нулевые.
Рассмотрим прямое преобразование Фурье
вектора v
в вектор V,
определяемое (5.1) и удовлетворяющее
теореме 5.2.1. Тогда справедлива следующая
теорема:
Теорема
5.3.2. Множество
qk
векторов V
в частотной области образует (п,
k)-код Рида
- Соломона.
Теорема
5.3.3. Любой
код Рида - Соломона является МДР кодом.
Декодирование кодов Рида - Соломона
Не
трудно заметить, что при образовании
кодов Рида - Соломона информационные
символы можно размещать в любых k
рядом стоящих
разрядах вектора v. Из методических
соображений отведем под информацию
старшие компоненты V.
В этом случае многочлен v(X)
будет иметь
вид
![]() а
порождающий многочлен соответствующего
кода Рида - Соломона имеет вид
а
порождающий многочлен соответствующего
кода Рида - Соломона имеет вид
![]() слова
рассматриваемого кода Рида - Соломона
являются прямым преобразованием Фурье
множества векторов V,
то есть
слова
рассматриваемого кода Рида - Соломона
являются прямым преобразованием Фурье
множества векторов V,
то есть
![]() .
В канале кодовому слову V
добавляется вектор ошибки Е
кратности
.
В канале кодовому слову V
добавляется вектор ошибки Е
кратности
![]() Рассмотрим
обратное преобразование Фурье принятого
из канала слова
Рассмотрим
обратное преобразование Фурье принятого
из канала слова
![]() В
силу свойства линейности обратного
преобразования Фурье имеем
В
силу свойства линейности обратного
преобразования Фурье имеем
![]() где
где
![]() -
информационный вектор, лежащий во
временной области,
-
информационный вектор, лежащий во
временной области,
![]() -
обратное преобразование вектора ошибок.
Так как п —
k правых
компонент вектора обратного
преобразования Фурье от V
+ E не зависят
от кодового слова V,
эти компоненты образуют синдром ошибок.
Запишем этот синдром в виде
-
обратное преобразование вектора ошибок.
Так как п —
k правых
компонент вектора обратного
преобразования Фурье от V
+ E не зависят
от кодового слова V,
эти компоненты образуют синдром ошибок.
Запишем этот синдром в виде
![]() где
где
![]() .
Заметим, что синдром является
некоторым «окном», через которое можно
наблюдать обратное преобразование
Фурье вектора ошибки Е.
Обозначим
индексы l
ненулевых
компонент вектора Е через
.
Заметим, что синдром является
некоторым «окном», через которое можно
наблюдать обратное преобразование
Фурье вектора ошибки Е.
Обозначим
индексы l
ненулевых
компонент вектора Е через
![]() .
Определим
вектор во временной области, прямое
преобразование Фурье которого
содержит нулевые компоненты для всех
частот j, для
которых
.
Определим
вектор во временной области, прямое
преобразование Фурье которого
содержит нулевые компоненты для всех
частот j, для
которых
![]() .
Проще всего такой вектор задать в виде
многочлена локаторов ошибок
.
Проще всего такой вектор задать в виде
многочлена локаторов ошибок
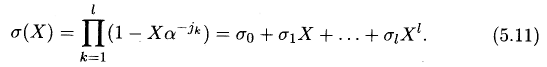 Покомпонентное
произведение прямого преобразования
Фурье от многочлена σ(Х)
на вектор
ошибки Е в частотной области равно
нулю, следовательно циклическая свертка
во временной области вектора σ
с вектором
е также равна нулю
Покомпонентное
произведение прямого преобразования
Фурье от многочлена σ(Х)
на вектор
ошибки Е в частотной области равно
нулю, следовательно циклическая свертка
во временной области вектора σ
с вектором
е также равна нулю
![]() Из
(5.9) и (5.10) следует, что для определения
компонент
Из
(5.9) и (5.10) следует, что для определения
компонент
![]() (согласно
(5.11) σ0
= 1),
используя (5.12), мы можем составить
систему d
— 1 — l
линейных
уравнений с l
неизвестными
(согласно
(5.11) σ0
= 1),
используя (5.12), мы можем составить
систему d
— 1 — l
линейных
уравнений с l
неизвестными
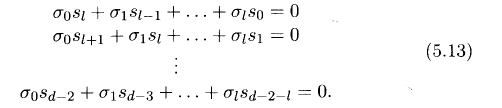 Сложность,
возникающая при решении системы уравнений
(5.13) состоит в том, что кратность
ошибки I нам
заранее не известна.
Сложность,
возникающая при решении системы уравнений
(5.13) состоит в том, что кратность
ошибки I нам
заранее не известна.
Предположим,
что все коэффициенты многочлена σ(Х)
определены.
В этом случае остальные k
компонент вектора е, то есть компоненты![]() во
временной области, могут быть рекурентно
определены, исходя из (5.12).
Для
определения компоненты efc_i
нам достаточно решить уравнение
во
временной области, могут быть рекурентно
определены, исходя из (5.12).
Для
определения компоненты efc_i
нам достаточно решить уравнение
![]() относительно
относительно
![]() ,
так как все остальные компоненты уже
определены.
На втором шаге мы уже
можем составить уравнение для определения
,
так как все остальные компоненты уже
определены.
На втором шаге мы уже
можем составить уравнение для определения
![]() .
Это уравнение имеет вид
.
Это уравнение имеет вид
![]() Рекурентно
продолжая описанную процедуру, мы найдем
все оставшихся компоненты вектора
е.
Для определения информационного
вектора v
нам достаточно вычесть найденные
компоненты
Рекурентно
продолжая описанную процедуру, мы найдем
все оставшихся компоненты вектора
е.
Для определения информационного
вектора v
нам достаточно вычесть найденные
компоненты
![]() из
полученных обратным преобразованием
Фурье от R
значений
из
полученных обратным преобразованием
Фурье от R
значений
![]()
![]() Самое
замечательное в рассмотренном алгоритме
состоит в том, что при его реализации
не приходится находить ни корни многочлена
σ (X) (локаторы
ошибок), ни значения ошибок.
Теперь
общая картина процедуры декодирования
ясна и ее можно сформулировать в виде
пяти шагов.
Шаг
1. Вычислить
обратное преобразование Фурье принятого
вектора R
= V + Е. Выделить
Самое
замечательное в рассмотренном алгоритме
состоит в том, что при его реализации
не приходится находить ни корни многочлена
σ (X) (локаторы
ошибок), ни значения ошибок.
Теперь
общая картина процедуры декодирования
ясна и ее можно сформулировать в виде
пяти шагов.
Шаг
1. Вычислить
обратное преобразование Фурье принятого
вектора R
= V + Е. Выделить
![]() во
временной области и зашумленные
компоненты информационного вектора
v;
Шаг
2. Найти σ(Х)
из (5.13);
Шаг
3. С помощью
реку рентной процедуры вычислить
компоненты
во
временной области и зашумленные
компоненты информационного вектора
v;
Шаг
2. Найти σ(Х)
из (5.13);
Шаг
3. С помощью
реку рентной процедуры вычислить
компоненты
![]() ;
Шаг
4. Найти
информационный вектор v;
Замечание.
Рассмотренный
алгоритм всегда исправляет
;
Шаг
4. Найти
информационный вектор v;
Замечание.
Рассмотренный
алгоритм всегда исправляет
![]() и
менее ошибок. В следующем разделе будет
рассмотрен также случай, когда число
канальных ошибок превышает
и
менее ошибок. В следующем разделе будет
рассмотрен также случай, когда число
канальных ошибок превышает
![]() Для
контроля правильности декодирования
часто проводится следующий шаг.
Шаг
5. Вычислить
прямое преобразование Фурье вектора
v,
получив при этом кодовый вектор
Для
контроля правильности декодирования
часто проводится следующий шаг.
Шаг
5. Вычислить
прямое преобразование Фурье вектора
v,
получив при этом кодовый вектор
![]() (не
всегда совпадаяющий с V).
(не
всегда совпадаяющий с V).