

- •ПРЕДИСЛОВИЕ
- •1.ОСНОВНЫЕ КОМПОНЕНТЫ СТАТИСТИЧЕСКОЙ СРЕДЫ R
- •1.2.Работа с командной консолью интерфейса R
- •1.3.Работа с меню пакета R Commander
- •1.4.Объекты, пакеты, функции, устройства
- •2.ОПИСАНИЕ ЯЗЫКА R
- •2.3.Факторы
- •2.4.Списки и таблицы
- •2.5.Импортирование данных в R
- •2.6.Представление даты и времени; временные ряды
- •2.7.Организация вычислений: функции, ветвления, циклы
- •2.8.Векторизованные вычисления в R с использованием apply-функций
- •3.6.Категоризованные графики
- •4.ОПИСАТЕЛЬНАЯ СТАТИСТИКА И ПОДГОНКА РАСПРЕДЕЛЕНИЙ
- •4.2.Использование функций summary() и дополнительных пакетов
- •4.4.Заполнение пропущенных значений в таблицах данных
- •4.6.Законы распределения вероятностей, реализованные в R
- •5.КЛАССИЧЕСКИЕ МЕТОДЫ И КРИТЕРИИ СТАТИСТИКИ
- •5.1.Гипотеза о равенстве средних двух генеральных совокупностей
- •5.4.Гипотеза об однородности дисперсий
- •5.9.Оценка статистической мощности при сравнении долей
- •6.2.Линейные модели дисперсионного анализа
- •6.3.Структура модельных объектов дисперсионного анализа
- •6.4.Оценка адекватности модели дисперсионного анализа
- •6.8.Проблема множественных проверок статистических гипотез
- •7.4.Критерии выбора моделей оптимальной сложности
- •7.7.Процедуры диагностики моделей множественной регрессии
- •8.5.Ковариационный анализ
- •8.7.Индуктивные модели (метод группового учета аргументов)
- •9.2.Анализ пространственного размещения точек
- •9.4.Создание картограмм при помощи R
- •БИБЛИОГРАФИЯ И ИНТЕРНЕТ-РЕСУРСЫ
- •Основные литературные ссылки по тексту книги
- •Библиографический указатель литературы по использованию R
- •Основные Интернет-ресурсы
9.2.Анализ пространственного размещения точек
Под пространственным анализом (Spatial analysis) понимается набор методов исследований, в которых случайная переменнаяZ связана с некоторым изучаемым показателем, изменяющимся в пространстве и характеризующим динамику изучаемой системы, а остальные независимые переменные определяют пространственно-временное положение объекта или точки наблюдения (время t, x-y координаты, высота h и т.д).
При изучении пространственных структур принято выделять два направления:
геостатистический анализ и анализ пространственного размещения точек, которые отличаются методом получения исходных данных (т.е. способом реализации выборочного процесса). В первом случае исследователь для анализа пространственного распределения какого-то показателя (например, содержания тяжелых металлов в верхнем слое почвы) сам планирует точки, в которых будут проводиться наблюдения. Полученные выборочные значения пространственной переменной z(x) рассматриваются как возможные реализации случайной функции Z(x). Теоретические аспекты геостатистического анализа и примеры его реализации вR см. в книге (Савельев и др., 2012), представленной на сайте gis-lab.info сообщества "Гис-Лаб".
Во |
втором |
случае |
также |
анализируются |
свойства |
определенного |
участка |
пространства |
по |
выборочным |
данным, полученным в |
разных |
его точках, однако |
|
|
местоположение этих точек устанавливается не по воле исследователя, случайно назначается неким природным"механизмом" (например, число яиц в гнезде можно подсчитать только там, где есть гнездо). Иными словами, изучаемое явление трактуется как не зависящий от наблюдателя процесс, генерирующий поток дискретных событий (Baddeley, 2010). О свойствах этого процесса мы можем судить по характеру размещения на координатной сетке ансамбля точек, соответствующих произошедшим событиям.
Диагностика характера процесса, генерирующего данные, обычно сводится к. отнесению конкретной совокупности точек на изучаемом участке пространства к одному из возможных типов размещения: а) регулярное (детерминированное равномерное или
стохастическое |
равномерное); б) |
групповое или агрегированное(детерминированное |
|
неравномерное); |
в) неоднородное |
случайное , и наконец, г) полностью |
случайное |
размещение (CSR – Complete Spatial Randomness). Тестирование гипотезы о наличии CSR обычно проводится на основе имитацииоднородным процессом Пуассона, т.е. проверяется условие, что количество точек, попавших в любую из непересекающихся областей пространства W, является независимой случайной величиной. Другое условие однородности удовлетворяется, если вероятность того, что в некоторую область A, A Ì W, попадет ровно n точек, не зависит от положения области А на плоскости или ее формы.
Рассмотрим пример, заимствованный из семинарского занятия .НЧижиковой (2012) на конференции "Открытые ГИС!" (gisconf.ru). Текст доклада "Введение в разведочный анализ точечных образов с помощью пакетаspatstat R" можно скачать в разделе "Мастер-классы" на странице gisconf.ru/talks, а скрипты и исходные данные для презентации находятся там же в архивном файле lect18-chizhikova-rsstat.zip.
Пусть таблица наблюдений содержит пространственные координаты точекx и y, где были обнаружены цветковые растенияAdonis vernalis L., количество цветков blossoms, а также фактор возрастаage, который принимает значенияgene (генеративный) и pre. С помощью функции ppp() пакета spatstat создадим объект
типа ppp (point pattern), который содержит всю необходимую информацию для последующего анализа:
library(spatstat)
# Загружаем текстовый файл с данными
plot_13 <- read.table(file="13.txt",header = T,sep = "\t")
# Вычислим размеры площадки по осям Х и Y
367
xmin <- floor(min(plot_13$x)) |
|
xmax <- ceiling(max(plot_13$x)) |
|
ymin <- floor(min(plot_13$y)) |
|
ymax <- ceiling(max(plot_13$y)) |
|
# Создадим объект ppp (point pattern) |
|
ppp_object <- ppp(x=plot_13$x, y=plot_13$y, |
|
marks=data.frame(age=plot_13$age, |
|
blossoms=plot_13$blossoms), |
# марки |
window=owin(c(xmin, xmax), c(ymin, ymax), |
# Окно |
unitname=c("metre","metres"))) # единицы измерения
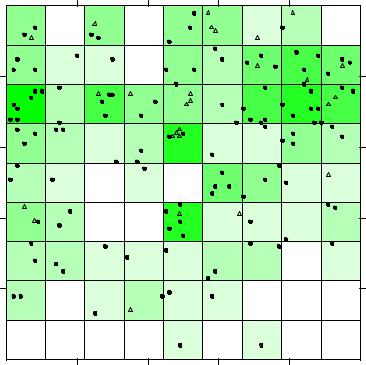
Простейший способ показать графически характер распределения точек– это нанести их на сетку квадратов. Выбрать оптимальные размеры ячейки сетки при площади всего участка A = 10×´10 м2 и общей численности наблюдаемых точекN = 126 можно, например, с использованием эмпирического правила "большого пальца":
Сторона квадрата L = (2×A / N)0.5 = (2×10×10 / 126)0.5 = 1.17 м.
Эмпирические частоты в каждомk-м квадрате (представлены на рисунке ниже) при справедливости гипотезы о случайности размещения точек статистически значимо не
отличаются от теоретических частот распределения |
ПуассонаNpk = N (lk e-l ) / k!. |
Здесь |
||
несмещенной оценкой интенсивности процессаl |
является среднее число |
точек на |
||
единицу площади: l = |
|
pois (k)N / A . |
|
|
n |
|
|
||
# площадь площадки |
|
|
||
A <- area.owin(ppp_object$window) |
|
|
||
# число точек |
|
|
||
N <- ppp_object$n |
|
|
||
#сторона одной ячейки, чтобы в них попадало в среднем 2 точки
L <- sqrt(2*A/N)
#сколько ячеек уместится в сторону площадки 10´10 м
quadnum <- round(10/L)
# построим сетку ячеек
ppp_quadrats<-quadrats(ppp_object, nx = quadnum, ny = quadnum)
# посчитаем число точек в ячейках, округлим до 1 десятичного знака quadcount <- quadratcount(ppp_object, tess=ppp_quadrats) quadcount <- round(quadcount, 1)
##### отобразим число точек в квадратах
# вычислим центры ячеек
xgrid <- quadrats(ppp_object, nx = quadnum, ny = quadnum)$xgrid ygrid <- quadrats(ppp_object, nx = quadnum, ny = quadnum)$ygrid image(xgrid, ygrid,
t(quadcount[order(1:quadnum, decreasing = T), ]), col = colorRampPalette(c("white", "green"))(15), axes=F, asp=1, xlab="", ylab="",
main="Число точек в квадратах") plot(quadcount, add=T, cex=0.7)
axis(2, las = 1, pos = 0, at = seq(0, 10, 2), cex.axis=1) axis(1, las = 1, pos = 0, at = seq(0, 10, 2), cex.axis=1) axis(3, pos = 10, at = seq(0, 10, 2), labels = F, cex.axis=1) axis(4, pos = 10, at = seq(0, 10, 2), labels = F, cex.axis=1)
#добавим точки
plot(ppp_object, which.marks="age", chars=c(19, 24), cex=0.7, add=T)
368
|
|
|
|
Число точек в квадратах |
|
|
|
||
10 |
|
|
|
|
|
|
|
|
|
|
3 |
0 |
3 |
0 |
3 |
3 |
1 |
2 |
0 |
|
3 |
1 |
1 |
0 |
3 |
2 |
4 |
5 |
4 |
8 |
|
|
|
|
|
|
|
|
|
|
7 |
2 |
5 |
3 |
3 |
2 |
5 |
6 |
5 |
6 |
3 |
2 |
1 |
2 |
6 |
1 |
1 |
3 |
2 |
|
|
|
|
|
|
|
|
|
|
|
2 |
1 |
0 |
1 |
0 |
4 |
3 |
1 |
1 |
4 |
3 |
2 |
0 |
0 |
6 |
1 |
1 |
1 |
2 |
|
2 |
2 |
1 |
1 |
1 |
2 |
2 |
0 |
1 |
2 |
|
|
|
|
|
|
|
|
|
|
2 |
0 |
1 |
2 |
1 |
1 |
0 |
0 |
0 |
|
0 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
|
|
|
|
|
|
|
|
|
|
0 |
|
2 |
4 |
|
6 |
|
8 |
10 |
На представленном ниже рисунке кружочками показаны цветущие (age = gene), а треугольниками – несозревшие растения (age = pre).
Проверка гипотезы о равенстве эмпирических и теоретических вероятностей H0: p = ppois осуществляется, например, с использованием критерия согласия c2:
# Хи-квадрат тест CSR с использованием численности точек в квадратах quadrat_test_result <- quadrat.test(ppp_object, nx=9, ny=9) round(quadrat_test_result$expected , 2) # Частоты Пуассона [1] 1.81 1.81 … 1.81 1.81
quadrat_test_result
Chi-squared test of CSR using quadrat counts data: ppp_object
X-squared = 127.9592, df = 80, p-value = 0.0005321 Quadrats: 9 by 9 grid of tiles
Второе проверяемое предположение, заключается в оценкеоднородности (стационарности) пуассоновского процесса: число точек в любых двух непересекающихся частях области исследования являются случайными и независимыми переменными. Пространственная версия теста Колмогорова-Смирнова позволяет проверить, равномерно ли распределено число точек вдоль пространственных осей x или y:
kstest(ppp_object, "x") # Тест Колмогорова-Смирнова по оси Х
Spatial Kolmogorov-Smirnov test of CSR
data: covariate ‘x’ evaluated at points of ‘ppp_object’ D = 0.0783, p-value = 0.3285
alternative hypothesis: two-sided
kstest(ppp_object, "y") # Тест Колмогорова-Смирнова по оси Y
Spatial Kolmogorov-Smirnov test of CSR
data: covariate ‘y’ evaluated at points of ‘ppp_object’ D = 0.2451, p-value = 4.296e-08
369
Выполненные расчеты D-статистики позволяют сделать очевидный вывод, что размещение популяций изучаемых растений равномерно распределено относительно оси x, но не является стационарным относительно осиy. Отметим, однако, что тест на стационарность выполняется, если только в тесте c2 для проверки CSR нулевая гипотеза не отклоняется, т.е. его выполнение нами было не вполне правомочным.
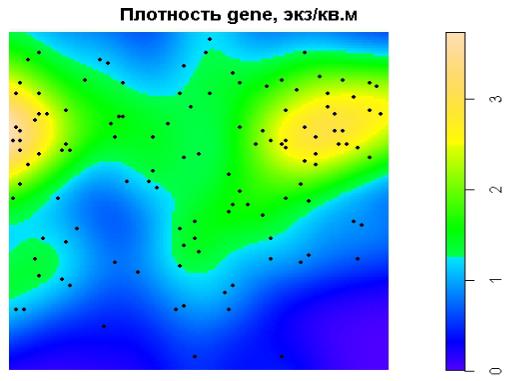
В разделе 8.1 мы рассматривали сглаживание точек на плоскости ядерными функциями. Однако те же модели мы можем использовать для трехмерного (а в общем случае и многомерного) сглаживания. Эти процедуры являются основным инструментом построения карт локальных плотностей, помощью которых осуществляется визуальный ГИС-анализ пространственной неоднородности распределения популяций биологических видов и других переменных.
Выполним построение поверхности интерполяции плотности точек с помощью радиальных гауссовых ядерных функций. При этом, как и при аппроксимации кривых, скользящее "окно" сканирует всю пространственную область и суммирует вклады точек в окрестности, связанной с текущим положением курсора. Гладкость полученной поверхности интерполяции зависит от ширины окна(bandwidth), которая может быть предварительно оценена по эмпирическим формулам или найдена автоматически в ходе кросс-проверки. Интенсивность процесса, генерирующего размещение точек gene, представлена на рисунке:
# выделим генеративные особи
gene_ppp <- ppp_object[ppp_object$marks$age=="gene"]
#вычислим размер скользящего окна, bandwidth
#по правилу Silverman
sigma<-(sd(gene_ppp$x)+sd(gene_ppp$y))/2 iqr<-(IQR(gene_ppp$x)+IQR(gene_ppp$y))/2 bandwidth <- 0.9*min(sigma, iqr)*gene_ppp$n^(-1/5) [1] 0.9102268
gene_intensity <- density.ppp(gene_ppp, sigma=bandwidth) plot(gene_intensity, main="Плотность gene, экз/кв.м") points(gene_ppp, pch=19, cex=0.6)
370
Важной дополнительной возможностью является построение к пространственно-обусловленного относительного риска (например, чтобы обозначить области, где число заболевших особей превысило какой-то процент). Например, на следующем рисунке представлена карта распределения доминирующих возрастных
групп нашего растения, позволяющая легко выделить фрагменты территории, где p = npre / ngene > 0.5, т.е. число экземпляров npre превышает число генеративных экземпляров
ngene:
# выделим коды возрастов
for_relrisk_example <- ppp_object # создадим копию ppp объекта marks(for_relrisk_example) <- ppp_object$marks$age
#вычислим вероятность появления особей возраста pre p <- relrisk(for_relrisk_example, 0.5)
plot(p, main="Доля группы pre", col=colorRampPalette( c("antiquewhite", "aquamarine3","navyblue"))(100))
#добавим изолинии
contour(p, nlevels=5, lwd=seq(from=0.1, to=3, length.out=5), add=T)
9.3. Использование сервисов картографической системы Google Maps
Признанным лидером |
среди современных картографических систем являются |
карты Google (Google Maps; |
maps.google.ru). Система содержит детализированные |
спутниковые изображения для обширных регионов любых стран и предоставляет интерактивный доступ к этим картам онлайн. Разработано также большое количество дополнительных сервисов и инструментов(Google Earth, Google Mars, разнообразные погодные и транспортные сервисы, один из самых мощных API).
Многие из этих сервисов реализованы в пакетеgoogleVis, в состав которого входит также ряд функций, обеспечивающих взаимодействие R с интерфейсом программирования приложений Google Visualization API (см. code.google.com). Функции
371
из этого пакета генерируютhtml-код, который можно легко вставить на страницу вебсайта.
В общем виде синтаксис функции для визуализации изображенийGoogle Maps выглядит следующим образом:
gvisMap(data, locationvar=" ", tipvar=" ", options = list(), chartid)
где
°data – таблица данных (data.frame), которая должна содержать как минимум два столбца – c географическими координатами точек(locationvar) и с текстом всплывающих подсказок для каждой из этих точек (tipvar);
°locationvar – имя столбца, содержащего географические координаты точек. Координаты задаются в формате"широта:долгота" (см. пример ниже). Вместо географических координат можно также указывать[максимально полный] почтовый адрес, однако авторы пакета googleVis рекомендуют этот способ не применять;
°tipvar – имя столбца, содержащего текст всплывающих подсказок для каждой точки;
°options – список опций, определяющих внешний вид карты;
°chartid – текстовая переменная, при помощи которой карте можно присвоить пользовательское имя. По умолчанию данная настройка отключена(в этом случае ID карты генерируется случайным образом автоматически).
Внешний вид карты настраивается при помощи следующих опций:
°enableScrollWheel – логическая переменная, по умолчанию принимающая значение FALSE. При enableScrollWheel = TRUE появится возможность изменять масштаб карты, вращая колесо мышки.
°showTip – логическая переменная, по умолчанию равнаяFALSE. Активация этой настройки (showTip = TRUE) позволит видеть описание точки при наведении на нее курсора.
°ShowLine – позволяет включать (TRUE) или выключать (FALSE) линию, соединяющую точки на карте.
°lineColor – текстовая переменная, задающая цвет вышеупомянутой линии ("red", "green", и т.п.; возможно также использование html-цветов, например "#800000").
°lineWidth – ширина линии. По умолчанию составляет 10 пикселей. Очевидно, что
эта настройка имеет смысл только при ShowLine = TRUE.
°mapType – текстовая переменная, задающая тип карты. Возможные значения:
"normal" (обычная схематичная карта), "terrain" (режим "Земля"),
"satellite" ("спутник") или "hybrid" ("гибрид").
°useMapTypeControl – логическая переменная, по умолчанию равнаяFALSE. Значение TRUE активизирует меню, позволяющее пользователю выбирать тип карты (см. предыдущий пункт).
°zoomLevel – количественная переменная, принимающая целые значения от 0 (виден весь мир) до 19 (максимальное приближение).
Функция gvisMap() возвращает объект класса"gvis", который представляет собой список, состоящий, как минимум, из следующих трех элементов: type (тип Googleкарты), chartid (см. выше) и html. Именно последний элемент интересует нас больше
всего, поскольку он содержит html-код карты. |
|
|
|
||
Работу |
функции gvisMap() проиллюстрируем |
на примере данных |
из |
своей |
|
статьи (Mastitsky, Makarevich, 2007), |
посвященной |
распространению в |
Беларуси |
||
чужеродных |
видов бокоплавов. В ходе |
выполненного |
обследования белорусской |
части |
|
реки Днепр был, например, обнаружен рачок Dikerogammarus haemobaphes – выходец из
372
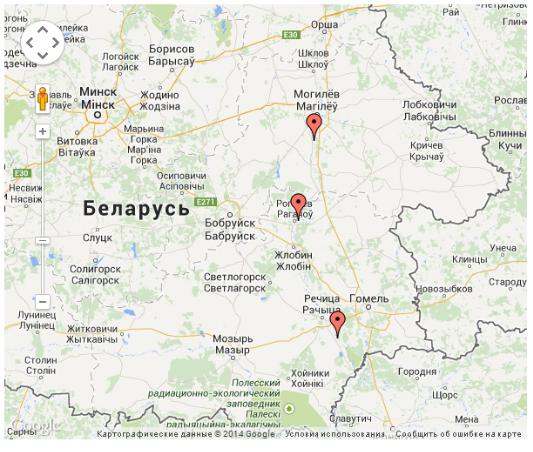
нижнего течения рек Понто-Каспийского бассейна. Этот вид был отмечен на трех обследованных створах реки. Для начала создадим таблицу(назовем ее Dikero – по названию вида), в которой будут храниться координаты створов и их названия:
Dikero <- data.frame(Coords = c("52.2:30.6", |
"53.7:30.3"), |
||
|
|
"53.1:30.1", |
|
|
Location = c("д. Холмеч", "г. Рогачев", "д. Стайки")) |
||
Dikero |
Location |
|
|
1 |
Coords |
|
|
52.2:30.6 |
д. Холмеч |
|
|
2 |
53.1:30.1 |
г. Рогачев |
|
3 |
53.7:30.3 |
д. Стайки |
|
Отобразим координаты этих створов Googleна -карте. Используя функцию gvisMap(), создадим объект с каким-либо произвольным именем(например, Map) в котором будет храниться html-код и другие элементы карты:
Map <- gvisMap(Dikero, "Coords", "Location",
Options = list(showTip=TRUE, mapType='normal', enableScrollWheel = TRUE),
chartid = "Dikerogammarus")
Команда plot()приведет к открытию браузера, в котором появится созданная Google-карта (естественно, при этом компьютер должен быть подключен к Internet).
plot(Map)
373
В тексте настоящего пособия мы привели лишь изображение экрана браузера, но читатель может увидеть работу функции живьем, перейдя к сообщению"Создание пользовательских карт Google" на сайте goo.gl.
Для извлечения html-кода карты из объектаMap необходимо выполнить следующую команду:
print(Map, tag = "chart")
Код будет выведен непосредственно в консольR, откуда его можно скопировать и вставить в свою веб-страницу.
Создание интерактивной веб-графики
В состав библиотекиgoogleVis входят не только функции работы с картами Google, но и сервис для интерактивной визуализации многомерных данных(образцы презентаций Х. Рослинга см. на сайте gapminder.org). Рассмотрим пример создания анимационного графика на основе таблицы данныхFruits, входящей в состав библиотеки googleVis.
Подключаем эту таблицу к рабочей среде R и просматриваем ее содержимое:
data(Fruits) Fruits
Таблица содержит динамику продаж трех видов фруктов(Apples, Bananas, Oranges) в двух регионах (East и West). Предположим, мы хотим визуализировать зависимость затрат Expenses от объема продаж Sales для всех видов фруктов Fruit в разных регионах Location и для разных периодов времени Year.
Для создания графика с набором переключателей, дающих возможность пользователю выбирать разные наборы отображаемых фрагментов данных, используем функцию gvisMotionChart(), которая имеет четыре основных аргумента:
gvisMotionChart(data, idvar = "id", timevar="date", chartid)
где data – имя таблицы данных; idvar – имя номинальной переменной для которой строится график; chartid – аргумент, позволяющий присвоить графику уникальное имя.
В нашем случае команда выглядит следующим образом:
M <- gvisMotionChart(Fruits, idvar = "Fruit", timevar = "Year")
Объект M является списком из трех списков (проверьте командой str(M)). Первые два элемента этого списка содержат информацию о типе графика(MotionChart) и его уникальное имя (chartid). Третий элемент списка наиболее интересен, поскольку он содержит html код графика. Этот третий элемент в свою очередь включает четыре других элемента: header ("шапка"), chart – непосредственно код графика, caption – подпись
графика, и footer ("футер"). |
html-код графика можно |
легко |
извлечь |
командой |
print(M, tag = "chart"), а затем скопировать и вставить на страницу веб-сайта. |
||||
В тексте настоящего |
издания , мыестественно, не |
можем |
показать |
процесс |
анимации и ограничились изображением окна браузера (рисунок приведен ниже). Увидеть непосредственный результат работы функцииgvisMotionChart() можно, перейдя к сообщению "Создаем интерактивную веб-графику" на сайте goo.gl.
374