

3.3.2. Концептуальные и физические er-модели
Разработанный выше пример ER-диаграммы является примером концептуальной диаграммы. Это означает, что диаграмма не учитывает особенности конкретной СУБД. По данной концептуальной диаграмме можно построить физическую диаграмму, которая уже будут учитываться такие особенности СУБД, как допустимые типы и наименования полей и таблиц, ограничения целостности и т.п. Физический вариант диаграммы, приведенной на Рис. 9 может выглядеть, например, следующим образом:
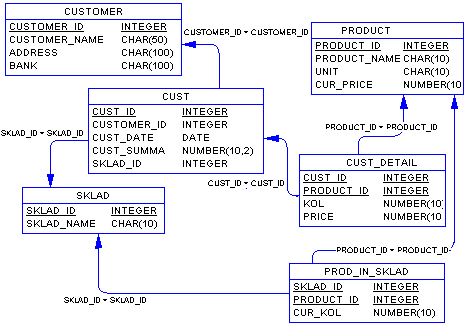
Рис. 10
На данной диаграмме каждая сущность представляет собой таблицу базы данных, каждый атрибут становится колонкой соответствующей таблицы. Обращаем внимание на то, что во многих таблицах, например, "CUST_DETAIL" и "PROD_IN_SKLAD", соответствующих сущностям "Запись списка накладной" и "Товар на складе", появились новые атрибуты, которых не было в концептуальной модели - это ключевые атрибуты родительских таблиц, мигрировавших в дочерние таблицы для того, чтобы обеспечить связь между таблицами посредством внешних ключей.
Легко заметить, что полученные таблицы сразу находятся в 3НФ.
Тема 3. Язык SQL
3.1. Выборка данных
3.1.1. Основы SQL
Инструкции
В SQL существует приблизительно сорок инструкций. Каждая из них “просит” СУБД выполнить определенное действие, например извлечь данные, создать таблицу или добавить в таблицу новые данные. Все инструкции имеют одинаковую структуру, которая изображена на рис. 3.1.
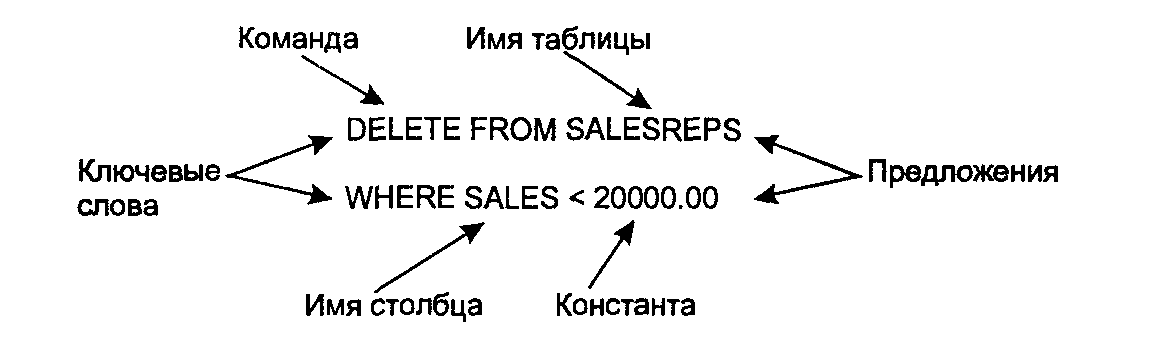
Рис 3.1. Структура инструкции SQL
Каждая инструкция SQL начинается с команды, т.е. ключевого слова, описывающего действие, выполняемое инструкцией. Типичными командами являются СRЕАТЕ (создать), INSERT (добавить), DЕТЕТЕ (удалить) и COMMIT (зафиксировать). После команды идет одно или несколько предложений. Предложение описывает данные, с которыми работает инструкция, или содержит уточняющую информацию о действии, выполняемом инструкцией. Каждое предложение также начинается с ключевого слова, такого как WHERE (где), FROM (откуда), INTO (куда) и HAVING (имеющий). Одни предложения в инструкции являются обязательными, а другие — нет. Конкретная структура и содержимое предложения могут изменяться. Многие предложения содержат имена таблиц или столбцов; некоторые из них могут содержать дополнительные ключевые слова, константы и выражения.
В стандарте ANSI/ISO определены ключевые слова, которые применяются в качестве команд и в предложениях инструкций В соответствии со стандартом эти ключевые слова нельзя использовать для именования объектов базы данных, таких как таблицы, столбцы и пользователи. Во многих СУБД этот запрет ослаблен, однако следует избегать использования ключевых слов в качестве имен таблиц и столбцов.
Имена
У каждого объекта в базе данных есть уникальное имя. Имена используются в инструкциях SQL и указывают, над каким объектом базы данных инструкция должна выполнить действие. Основными именованными объектами в реляционной базе данных являются таблицы, столбцы и пользователи; правила их именования были определены еще в стандарте SQL1. В стандарте SQL2 этот список значительно расширен и включает схемы (коллекции таблиц), ограничения (ограничительные условия, накладываемые на содержимое таблиц и их отношения), домены (допустимые наборы значений, которые могут быть занесены в столбец) и ряд других объектов. Во многих СУБД существуют дополнительные виды именованных объектов, например хранимые процедуры (Sybase и SQL Server), отношения “первичный ключ — внешний ключ” DB2) и формы для ввода данных (Ingres).
В соответствии со стандартом ANSI/ISO имена в SQL должны содержать от 1 до 18 символов, начинаться с буквы и не содержать пробелов или специальных символов пунктуации. В стандарте SQL2 максимальное число символов в имени увеличено до 128. На практике поддержка имен в различных СУБД реализована по-разному. В DB2, к примеру, имена пользователей не могут превышать 8 символов, но имена таблиц и столбцов могут быть более длинными. Кроме того, в различных СУБД существуют разные подходы к использованию в именах таблиц специальных символов. Поэтому для повышения переносимости лучше делать имена сравнительно короткими и избегать употребления в них специальных символов.
Имена таблиц
Если в инструкции указано имя таблицы, СУБД предполагает, что происходит обращение к одной из ваших собственных таблиц (т.е. таблиц, которые создали вы). Обычно таблицам присваиваются короткие, но описательные имена. В небольших базах данных, предназначенных для личного или группового использования, выбор имен зависит от разработчика базы данных. В более крупных, корпоративных базах данных могут существовать определенные корпоративные стандарты именования таблиц, позволяющие избежать конфликтов имен.
Большинство СУБД позволяют различным пользователям создавать таблицы с одинаковыми именами. Имея соответствующее разрешение, можно обращаться к таблицам, владельцами которых являются другие пользователи, с помощью полного имени таблицы. Оно состоит из имени владельца таблицы и собственно ее имени, разделенных точкой. Например, полное имя таблицы BIRTHDAYS, владельцем которой является пользователь по имени SAM, имеет следующий вид:
SAM.BIRTHDAYS
Полное имя таблицы можно использовать вместо короткого имени во всех инструкциях SQL.
Стандарт SQL2 еще больше обобщает понятие полного имени таблицы. Он разрешает создавать именованное множество таблиц, называемое схемой. для доступа к таблице в схеме также применяется полное имя. Например, обращение к таблице BIRTHDAYS, помещенной в схему EMPLOYEEINFO записывается так:
EMPLOYEEINFO.BIRTHDAYS
Имена столбцов
Если в инструкции задается имя столбца, СУБД сама определяет, в какой из указанных в этой же инструкции таблиц содержится данный столбец. Однако если в инструкцию требуется включить два столбца из различных таблиц, но с одинаковыми именами, необходимо указать полные имена столбцов, которые однозначно определяют их местонахождение. Полное имя столбца состоит из имени таблицы, содержащей столбец и имени столбца (короткого имени), разделенных точкой. Например, полное имя столбца SALES из таблицы SALESREPS имеет следующий вид:
SALES.SALESREPS
Если столбец находится в таблице, владельцем которой является другой пользователь, то в полном имени столбца следует указывать полное имя таблицы. Полное имя столбца можно использовать вместо короткого имени во всех инструкциях SQL; об исключениях говорится при описании конкретных инструкций.