

1.2.3. Анализ и управление производительностью
Эффективная реализация функциональных возможностей информационной системы основывается на оптимальном использовании ее аппаратно-программных средств для чего необходимо проводить регулярный системный анализ производительности и других параметров от нее производных.
В небольших информационных системах настройки по использованию возможностей системы либо определены по умолчанию, либо заданы при проектировании и настроены при сборке, не требуя вмешательства администратора.
В ходе эксплуатации сложных информационных систем администратором осуществляется настройка и оптимизация параметров оборудования ИС с целью эффективного использования системных ресурсов для обеспечения необходимого уровня качества обслуживания пользователей без необходимости расширения или реконфигурации системы. Потребность в таких действиях обусловлена тем, что логическая и физическая структура ИС постоянно меняется, так как разработчики устанавливают новое программное обеспечение в систему, добавляются новые пользователи и приложения, изменяются данные внутри БД и т. п.
Условную схему сущностей, в цепочке управления производительностью можно представить следующим образом (см. рис. 1.6).

Рис. 1.6. Условная схема сущностей, в цепочке управления производительностью
Источники нагрузки – это иерархия объектов, имеющая сложные взаимосвязи, включающие пользователей, географически или структурно обособленные подразделения организации, задачи, пакеты, SQL запросы и другие составляющие объектной системы. Источники нагрузки являются инициаторами изменения состояния ресурсов.
Сетевая (транспортная) инфраструктура ИС – совокупность оборудования и программного обеспечения, которая создает среду для процесса обмена информацией и для работы бизнес-приложений
Поскольку речь идет об управлении производительностью, т. е. о параметре, выражаемом в объеме работы за единицу времени, то мерой изменения ресурсов, является время.
Таким образом, управление производительностью есть управление:
источниками нагрузки;
ресурсами;
транспортной инфраструктурой;
аппаратно-программными компонентами ИС.
Управление источниками нагрузки может включать в себя управление пользователями и задачами.
Например, можно запретить (определенным пользователям) запускать ресурсоемкие задачи в часы пиковых нагрузок. Такое управление может включать рекомендацию оптимизировать задачу (текст программы), запрос.
Настройка SQL запросов (построение индексов, реорганизация запросов), перестройка структуры базы данных: рациональное размещение объектов базы данных на устройствах хранения, реорганизация структуры базы данных с соответствующими изменениями в прикладном коде или еще каким-то образом сократить потребление ресурсов
Управление ресурсами включает в себя:
управление процессорной производительностью (рекомендация увеличить число процессоров или их производительность),
управление быстродействием дисковой подсистемы,
управление оперативной памятью (рекомендация увеличить объем памяти, тем самым, например, расширив возможности кеширования),
управление быстродействием сетевых средств.
При определении причины недостаточной производительности или ее снижения сначала нужно выяснить, является ли она постоянной или временной. К примеру, всегда ли приложение работает непроизводительно или только во время периода пиковой нагрузки?
Если верно первое, то имеет место статическое снижение производительности, если второе – динамическое.
Динамическое снижение производительности обычно вызвано недостатком следующих ресурсов, к примеру пропускной способности разделяемой сети или циклов процессора хоста, и проблемы, с ними связанные, возникают, как правило, в разделяемых областях инфраструктуры: в сети или на серверах. При этом сетевые проблемы проявляются в сегментах сети или, что происходит заметно чаще, на промежуточных маршрутизаторах, коммутаторах или шлюзах. Серверные проблемы связаны с нехваткой таких ресурсов, как емкость памяти, мощность процессора или скорость обмена с диском. Динамическое падение производительности происходит в тех случаях, когда потребности в ресурсах превосходят возможности имеющихся ресурсов.
Правильное размещение в сети контрольно-измерительных средств позволяет довольно быстро диагностировать и установить причину возникновения динамического снижения производительности, поскольку оно связано с очевидным недостатком ресурсов.
Статическое снижение производительности устранить сложнее, так как очевидных ограничений на ресурсы в этом случае нет. Данные проблемы вызваны в основном недостатками архитектуры. К примеру, сеть не имеет необходимой пропускной способности, клиенты и серверы обладают недостаточной памятью, мощности процессора не хватает, а скорость внутренней шины обмена с диском низка. Неправильное размещение приложений и чрезмерный объем кода графического интерфейса, элементов данных и исполняемых модулей также могут относиться к изъянам архитектуры.
Зачастую для определения источника статических или архитектурных недостатков необходим сложный анализ, поскольку установленные датчики не всегда правильно указывают причину низкой производительности. В частности, с одной стороны, мониторы производительности, отслеживающие сетевой трафик или загрузку процессора на сервере, не обнаруживают перегрузки, а с другой – приложение не отвечает требованиям пользователей к производительности. Приложение, например, может производить слишком большое число обменов по сети в рамках одной транзакции или чересчур много небольших транзакций, связанных с чтением/записью на диск. Как только определено, в чем состоит проблема, необходимо решить, поможет ли модернизация оборудования (затратный вариант), или придется изменить архитектуру приложения.
Для того чтобы принять правильное решение о модернизации системы, системному администратору необходимо проанализировать производительность системы. Конечными узлами сети являются компьютеры, и от их производительности и надежности во многом зависят характеристики всей сети в целом. Именно компьютеры являются теми устройствами в сети, которые реализуют протоколы всех уровней, начиная от физического и канального (сетевой адаптер и драйвер) и заканчивая прикладным уровнем (приложения и сетевые службы операционной системы). Следовательно, оптимизация компьютера включает две достаточно независимые задачи:
Во-первых, выбор таких параметров конфигурации программного и аппаратного обеспечения, которые обеспечивали бы оптимальные показатели производительности и надежности этого компьютера как отдельного элемента сети. Такими параметрами являются, например, тип используемого сетевого адаптера, размер файлового кэша, влияющий на скорость доступа к данным на сервере, производительность дисков и дискового контроллера, быстродействие центрального процессора и т. п.
Во-вторых, выбор таких параметров протоколов, установленных в данном компьютере, которые гарантировали бы эффективную и надежную работу коммуникационных средств сети. Поскольку компьютеры порождают большую часть кадров и пакетов, циркулирующих в сети, то многие важные параметры протоколов формируются программным обеспечением компьютеров, например начальное значение поля TTL (Time-to-Live) протокола IP, размер окна неподтвержденных пакетов, размеры используемых кадров.
Тем не менее, выполнение вычислительной задачи может потребовать участия в работе нескольких устройств. Каждое устройство использует определенные ресурсы для выполнения своей части работы. Плохая производительность обычно является следствием того, что одно из устройств требует намного больше ресурсов, чем остальные. Чтобы исправить положение, вы должны выявить устройство, которое расходует максимальную часть времени при выполнении задачи. Такое устройство называется узким местом (bottleneck). Например, если на выполнение задачи требуется 3 секунды и 1 секунда тратится на выполнение программы процессором, а 2 секунды – на чтение данных с диска, то диск является узким местом.
Определение узкого места – критический этап в процессе улучшения производительности. Замена процессора в предыдущем примере на другой, в два раза более быстродействующий процессор, уменьшит общее время выполнения задачи только до 2,5 секунд, но принципиально исправить ситуацию не сможет, поскольку узкое место устранено не будет. Если же приобрести диск и контроллер диска, которые будут в два раза быстрее прежних, то общее время уменьшится до 2 секунд.
Если быстродействие системы не может удовлетворить предъявляемым требованиям, исправить положение можно следующими способами:
обеспечить систему достаточным ресурсом памяти. Объем памяти – один из основных факторов, влияющих на производительность;
устранить некоторые проблемы, созданные как пользователями (одновременный запуск слишком большого количества заданий, неэффективные методы программирования, выполнение заданий с избыточным приоритетом, а также объемных заданий в часы пик), так и самой системой (квоты, учет времени центрального процессора);
организовать жесткие диски и файловые системы так, чтобы сбалансировать нагрузку на них и таким образом максимально повысить пропускную способность средств ввода-вывода;
осуществлять текущий контроль сети, чтобы избежать ее перегрузки и добиться низкого коэффициента ошибок. Сети UNIX/Linux можно контролировать с помощью программы netstat. В сетевых операционных системах семейства Windows можно использовать утилиту PerformanceMonitor;
откорректировать методику компоновки файловых систем в расчете на отдельные диски;
выявить ситуации, когда система совершенно не соответствует предъявляемым к ней требованиям.
Анализ производительности обычно проводится на основе накопленной статистической информации таких параметров:
как время реакции системы;
пропускная способность реального или виртуального канала связи между двумя конечными абонентами сети;
интенсивность трафика в отдельных сегментах и каналах сети;
вероятность искажения данных при их передаче через сеть;
коэффициент готовности сети или ее определенной транспортной службы и др.
Производительность сети может измеряться с помощью показателей двух типов: временных, оценивающих задержку, вносимую сетью при выполнении обмена данными и время необходимое для исполнения запроса, и показателей пропускной способности, вычисляющих количество информации, переданной по сети в единицу времени.
Время реакции (отклика). В качестве временной характеристики производительности сети зачастую используется такой показатель как время реакции (отклика).
Время реакции любой информационной системы складывается из продолжительности следующих процессов:
организация доступа к информационному приложению (сервису или ресурсу) в виде запроса на его выполнение;
доставка и реализация запроса путем запуска приложения;
поиск необходимой информации и выполнение приложения (обработка запроса);
формирование отклика в виде результата выполненного приложения и доставка его адресату.
На рис. 1.7 схематично изображено существо этого показателя. Так здесь время реакции Tp определяется как интервал между моментом t1 возникновением запроса пользователя к какому-либо приложению или сервису и моментом времени t2 получением ответа на этот запрос.

Рис. 1.7. Схема реакции интервала между запросом и ответом
В простейшем случае его количественное значение можно вычислить, используя следующее несложное выражение.
Tp = t2 – t1 .
Очевидно, что значение этого показателя зависит от типа сервиса, к которому обращается пользователь, от того, какой пользователь и к какому серверу обращается, а также от текущего состояния других элементов системы и сети – загруженности сегментов, через которые проходит запрос, загруженности сервера и т. п.
Пропускная способность. Основная задача, для решения которой строится любая сеть, как транспортная подсистема ИС – передача информации между компьютерами с необходимой скоростью. Поэтому критерии, связанные с пропускной способностью сети или ее части, хорошо отражают качество выполнения сетью ее основной функции.
На рис. 1.8 показаны временные диаграммы необходимой пропускной способности для различных видов передаваемой информации. Диапазон значений пропускной способности составляет от сотен килобит/c до десятков Гбит/c.
Существует большое количество вариантов определения критериев этого вида. Эти варианты могут отличаться друг от друга: выбранной единицей измерения количества передаваемой информации, характером учитываемых данных – только пользовательские данные или же пользовательские данные вместе со служебными, количеством точек измерения передаваемого трафика, способом усреднения результатов на сеть в целом и т. п.
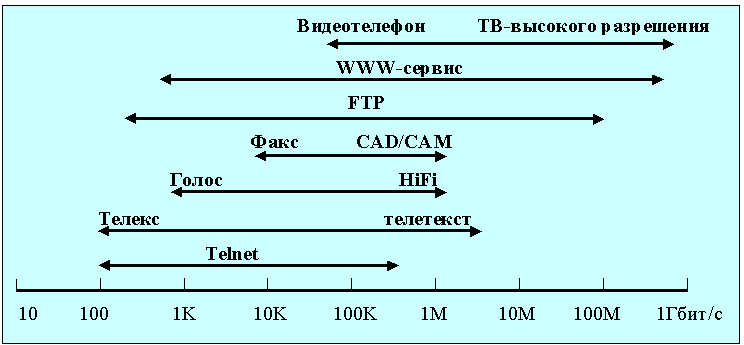
Рис. 1.8. Требования к пропускной способности канала для различных видов сервиса
Измеренные значения производительности необходимы как для оперативного управления системой, так и для планирования развития ИС.