

Вектор независимых
переменных
![]() составлен из двух подвекторов, каждый
из которых имеет собственную смысловую
нагрузку. Компоненты вектора
составлен из двух подвекторов, каждый
из которых имеет собственную смысловую
нагрузку. Компоненты вектора
![]() принято называть атрибутами и понимать
их как показатели, по которым различаются
альтернативы. В свою очередь компоненты
вектора
принято называть атрибутами и понимать
их как показатели, по которым различаются
альтернативы. В свою очередь компоненты
вектора
![]() называют
характеристиками, понимая под ними
описание индивидуальных черт тех лиц,
которые осуществляли выбор альтернатив.
называют
характеристиками, понимая под ними
описание индивидуальных черт тех лиц,
которые осуществляли выбор альтернатив.
Оценка параметров
модели (3.100) не дает однозначного
результата, так вместе с вычисленными
коэффициентами
![]() идентичные
вероятности позволяет получить вектор
идентичные
вероятности позволяет получить вектор
![]() .
Избежать этой неоднозначности позволяет
операция нормализации (стандартизации),
смысл которой в том, чтобы для одного
из вариантов, например
.
Избежать этой неоднозначности позволяет
операция нормализации (стандартизации),
смысл которой в том, чтобы для одного
из вариантов, например
![]() ,
положить
,
положить
![]() .
Тогда оценивается не
.
Тогда оценивается не
![]() функция, а
функция, а
![]() функций одного вида
функций одного вида
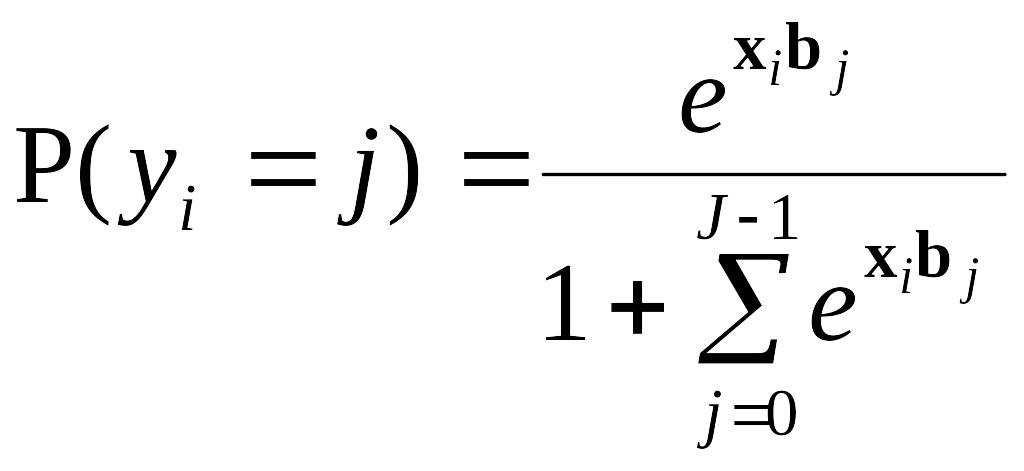 ,
,
![]() ,
(3.101)
,
(3.101)
после чего определяется еще одна функция через значения этих функций путем вычитания их суммы из единицы
 .
(3.102)
.
(3.102)
Это одна из
особенностей построения полиномиальной
логит-модели. В соответствии с этой
особенностью компьютерные пакеты
рассчитывают только коэффициенты первых
![]() зависимостей
зависимостей
![]()
![]() ,
по которым вычисляются в соответствии
с (3.101) первые
вероятностей
,
по которым вычисляются в соответствии
с (3.101) первые
вероятностей
![]() .
Вероятность выбора последнего варианта
.
Вероятность выбора последнего варианта
![]() компьютером не рассчитывается, а
определяется отдельно с помощью (3.102).
компьютером не рассчитывается, а
определяется отдельно с помощью (3.102).
Форма логит-модели,
применяемой для бинарного выбора,
описание которой было приведено выше,
легко получается из полиномиальной при
![]() .
В силу того, что логит-модель является
частным случаем полиномиальной, ее
часто называют биномиальной.
.
В силу того, что логит-модель является
частным случаем полиномиальной, ее
часто называют биномиальной.
Оценивание
коэффициентов модели осуществляется
путем численного решения уравнений
правдоподобия. Для записи самого
уравнения правдоподобия, а точнее его
логарифмической формы, удобно ввести
переменную
![]() ,
которая принимает значение 1, если в
,
которая принимает значение 1, если в
![]() -ом
наблюдении (
-ым
индивидуумом) был выбран
-ом
наблюдении (
-ым
индивидуумом) был выбран
![]() -ый
альтернативный вариант среди (
)-го,
и 0 в противном случае. Тогда для каждого
только одно из
-ый
альтернативный вариант среди (
)-го,
и 0 в противном случае. Тогда для каждого
только одно из
![]() будет
равно 1.
будет
равно 1.
Используя введенную переменную запишем функцию логарифмического правдоподобия
 .
(3.103)
.
(3.103)
Дифференцируя это
выражение по
![]() ,
получим систему уравнений максимального
правдоподобия
,
получим систему уравнений максимального
правдоподобия
![]()
 =
=
 =
=
= =
=
=![]() ,
,
![]() .
(3.104)
.
(3.104)
Заметим, что в
-ом
блоке уравнений суммирование идет по
всем
,
причем если в
-ом
случае был выбран
-ый
вариант, т.е.
![]() ,
то в квадратных скобках имеем
,
то в квадратных скобках имеем
![]() ,
в противном случае
,
в противном случае
![]() .
.
Решение этой
системы с учетом того, что
осуществляется численно с помощью
метода Ньютона – Рафсона. Компьютерная
реализация устроена таким образом, и
об этом уже говорилось, что нулевые
значения получают параметры той модели,
которая соответствует последней из
указанных альтернатив. Другими словами,
если бы мы захотели, чтобы
![]() ,
а не
,
а не
![]() ,
то данные, соответствующие альтернативе
с номером
,
то данные, соответствующие альтернативе
с номером
![]() ,
должны быть введены последними.
,
должны быть введены последними.
Для реализации метода Ньютона – Рафсона требуется матрица частных производных второго порядка. Кроме того, с помощью этой матрицы определяются характеристики надежности самой модели. Поэтому имеет смысл выписать эту матрицу в общем виде
![]() =
= =
=
= =
=
= =
=
=![]() .
(3.105)
.
(3.105)
В полученном
выражении
![]() принимает значение 1 при
принимает значение 1 при
![]() и 0 в противном случае. Это позволяет
осуществлять селекцию, так как результатом
произведения
и 0 в противном случае. Это позволяет
осуществлять селекцию, так как результатом
произведения
![]() является
является
![]() .
.
Матрица состоит
из
![]() блоков, каждый из которых имеет размер
по числу оцениваемых параметров, т.е.
блоков, каждый из которых имеет размер
по числу оцениваемых параметров, т.е.
![]() ,
где
,
где
![]() –
число объясняющих переменных. Данные
объясняющих переменных должны обеспечивать
обратимость этой матрицы.
–
число объясняющих переменных. Данные
объясняющих переменных должны обеспечивать
обратимость этой матрицы.
Практически нет
строгих ограничений на количество
оцениваемых альтернатив, однако следует
помнить, что каждая новая альтернатива
требует дополнительного введения в
модель
![]() параметра.
параметра.
Коэффициенты
модели трудно интерпретируемы. Нелинейный
характер не позволяет непосредственно
через коэффициенты проследить связь
между уровнем вероятности и атрибутами
(факторами). Поэтому естественно для
этих целей использовать предельный
анализ. Дифференцируя по
![]() -му
атрибуту в
-ой
точке
-ую
вероятность получаем предельный эффект
в виде
-му
атрибуту в
-ой
точке
-ую
вероятность получаем предельный эффект
в виде
 =
=
= =
=
=
= =
=
=![]() .
(3.106)
.
(3.106)
При расчетах по
этой формуле нужно помнить, что вектор
![]() в соответствии с принятым соглашением
нулевой и поэтому первое слагаемое при
определении математического ожидания
коэффициента равно нулю.
в соответствии с принятым соглашением
нулевой и поэтому первое слагаемое при
определении математического ожидания
коэффициента равно нулю.
Таким образом,
предельный эффект, получаемый при
изменении
-го
атрибута (
-ой
независимой переменной) представляет
собой произведение вероятности
![]() на разность коэффициента стоящего перед
-ой
переменной и средней величиной этого
коэффициента. Предельный эффект зависит
от атрибута, причем механизм этой
зависимости реализуется через вероятность
и через среднюю величину коэффициента,
при определении которой задействована
та же самая вероятность. При высокой
вероятности, также как и при малой,
предельный эффект незначительный. Это
объясняется тем, что при больших
на разность коэффициента стоящего перед
-ой
переменной и средней величиной этого
коэффициента. Предельный эффект зависит
от атрибута, причем механизм этой
зависимости реализуется через вероятность
и через среднюю величину коэффициента,
при определении которой задействована
та же самая вероятность. При высокой
вероятности, также как и при малой,
предельный эффект незначительный. Это
объясняется тем, что при больших
![]() ,
в средней величине коэффициента
,
в средней величине коэффициента
![]() доминирует величина
доминирует величина
![]() и
разность между ними близка к нулю. При
малых значениях
разность большая, но значение самой
вероятности близко к нулю, а следовательно,
и величина предельного эффекта небольшая.
Обобщая, можно утверждать, что
и
разность между ними близка к нулю. При
малых значениях
разность большая, но значение самой
вероятности близко к нулю, а следовательно,
и величина предельного эффекта небольшая.
Обобщая, можно утверждать, что
![]() в двух случаях: когда
в двух случаях: когда
![]() и когда
и когда
![]() .
Своего максимального значения он
достигает, когда вероятность близка к
0,5, т.е. имеет место ситуация с самым
большим уровнем неопределенности при
выборе
-го
варианта. Это естественно, так как именно
в этой ситуации наиболее ценной является
любая информация, уточняющая наше
представление о выборе альтернатив.
.
Своего максимального значения он
достигает, когда вероятность близка к
0,5, т.е. имеет место ситуация с самым
большим уровнем неопределенности при
выборе
-го
варианта. Это естественно, так как именно
в этой ситуации наиболее ценной является
любая информация, уточняющая наше
представление о выборе альтернатив.
Фактически предельный эффект является функцией с помощью которой можно ранжировать атрибуты по степени их влияния на выбор конкретного варианта. Кроме того, для каждого атрибута с помощью предельного эффекта можно определить тот вариант, на выбор которого изменение данного атрибута влияет сильнее всего. Безусловно, подобный анализ интересен, однако он не дает прямого ответа на главный вопрос: «Как изменится неопределенность выбора при изменении атрибута?» Ответ можно получить, если использовать энтропийный показатель для оценки уровня неопределенности ситуации множественного выбора.
Обычно интерес вызывает анализ конкретной ситуации. Пусть это ситуация с номером . Тогда неопределенность выбора в -ой ситуации можно определить с помощью выражения
![]() .
(3.107)
.
(3.107)
Если вероятность
изменяется на величину предельного
эффекта
![]() ,
то естественно изменяется и величина
энтропийного показателя
,
то естественно изменяется и величина
энтропийного показателя
![]() .
(3.108)
.
(3.108)
При
![]() ,
увеличение соответствующего атрибута
снижает уровень неопределенности
множественного выбора в
-ой
ситуации на величину
,
увеличение соответствующего атрибута
снижает уровень неопределенности
множественного выбора в
-ой
ситуации на величину
![]() .
Если неравенство в противоположную
сторону, то тоже самое изменение атрибута
увеличивает уровень неопределенности.
.
Если неравенство в противоположную
сторону, то тоже самое изменение атрибута
увеличивает уровень неопределенности.
Величину
![]() будем называть предельным
информационным эффектом,
имея в виду с одной стороны содержательный
смысл этой величины, а с другой – механизм
ее определения через предельный эффект
атрибута. Понять в каких ситуациях
следует ожидать отрицательное значение
предельного информационного эффекта,
а в каких положительное весьма сложно.
Гораздо проще вычислить
как разность между значениями,
определяемыми в соответствии с (3.108) и
(3.107). И все же рассмотрим механизм
формирования величины предельного
информационного эффекта
будем называть предельным
информационным эффектом,
имея в виду с одной стороны содержательный
смысл этой величины, а с другой – механизм
ее определения через предельный эффект
атрибута. Понять в каких ситуациях
следует ожидать отрицательное значение
предельного информационного эффекта,
а в каких положительное весьма сложно.
Гораздо проще вычислить
как разность между значениями,
определяемыми в соответствии с (3.108) и
(3.107). И все же рассмотрим механизм
формирования величины предельного
информационного эффекта
![]()
![]()
![]()
![]() .
(3.109)
.
(3.109)
Полученная величина
должна быть отрицательной, чтобы
увеличение соответствующего атрибута
снизило неопределенность ситуации
множественного выбора. Знак полученного
выражения зависит от
![]() .
Причем одновременно для всех
предельный эффект
не
может иметь один и тот же знак, так как
в его составе сомножитель равный
отклонению
.
Причем одновременно для всех
предельный эффект
не
может иметь один и тот же знак, так как
в его составе сомножитель равный
отклонению
![]() .
.
Для каждой -ой ситуации множественного выбора можно записать
![]()
![]()
![]() ,
(3.110)
,
(3.110)
где
![]() – множество тех вариантов, для которых
имеет отрицательный (положительный)
знак. Следовательно, знак
определяется
знаком верхних слагаемых, если они по
величине превосходят нижние и наоборот,
если не превосходят. Значения этих сумм
различны для разных
,
а это значит, что в одних ситуациях
предельный эффект будет направлен на
снижение неопределенности, а в других
– на повышение.
– множество тех вариантов, для которых
имеет отрицательный (положительный)
знак. Следовательно, знак
определяется
знаком верхних слагаемых, если они по
величине превосходят нижние и наоборот,
если не превосходят. Значения этих сумм
различны для разных
,
а это значит, что в одних ситуациях
предельный эффект будет направлен на
снижение неопределенности, а в других
– на повышение.
В моделях множественного выбора энтропийный анализ играет важную роль, так как лицу, принимающему решение на основе результатов моделирования, необходима оценка уровня неопределенности смоделированной ситуации и возможные варианты ее снижения.
3.5.2. Модели множественного выбора в задачах оценки инвестиционных проектов. Рассмотрим прикладные возможности модели множественного выбора на следующем примере.
ОАО «Жемчужина» приняло решение об открытии нескольких точек общественного питания, предварительно получив разрешение на строительство одной из этих точек в центре г. Воронежа, второй – в городском районе, удаленном от центра, и третьей – на Ростовской автотрассе (недалеко от города). В каждом из указанных мест можно реализовать один из трех вариантов: открыть или ресторан, или кафе, или бистро. В свою очередь, на эффективность выбранного варианта влияют различные факторы, среди которых можно выделить наиболее существенные, связанные с выбором типа кухни (национальной, традиционной и смешанной), ориентации на потенциальных посетителей (имеющих высокие, средние и ниже среднего доходы), а также максимальным количеством обслуживаемых одновременно клиентов.
Руководству ОАО «Жемчужина» необходимо для каждого места, отведенного под строительство, выбрать вариант, который с наименьшим риском обеспечит прибыльное долговременное функционирование соответствующей точки общественного питания. Для объективной оценки риска было решено изучить все аспекты, связанные с этим бизнесом в г. Воронеже.
Компания «Реформа», специализирующаяся на маркетинговых исследованиях, предоставила ОАО «Жемчужина» данных о наиболее успешных ресторанах, кафе и бистро, функционирующих на территории г. Воронежа. Данные представлены в табл. 3.13.
Т а б л и ц а 3.13
Данные о функционировании предприятий общественного питания г. Воронежа
№ |
Тип предприятия |
Место расположения |
Тип кухни |
Уровень дохода посетителей |
Максимальное число одновременное обслуживаемых клиентов |
|
|
|
|
|
|
-1- |
-2- |
-3- |
-4- |
-5- |
-6- |
1. |
ресторан |
центр |
традиционная |
высокий |
60 |
-1- |
-2- |
-3- |
-4- |
-5- |
-6- |
2. |
ресторан |
район города |
национальная |
высокий |
45 |
3. |
кафе |
центр |
смешанная |
средний |
20 |
4. |
бистро |
автотрасса |
национальная |
ниже среднего |
15 |
5. |
кафе |
автотрасса |
национальная |
высокий |
35 |
6. |
кафе |
район города |
традиционная |
средний |
60 |
7. |
ресторан |
район города |
традиционная |
высокий |
50 |
8. |
кафе |
центр |
традиционная |
ниже среднего |
15 |
9. |
ресторан |
автотрасса |
национальная |
высокий |
50 |
10. |
кафе |
район города |
традиционная |
высокий |
30 |
11. |
кафе |
район города |
смешанная |
средний |
10 |
12. |
ресторан |
центр |
смешанная |
средний |
40 |
13. |
ресторан |
автотрасса |
традиционная |
высокий |
45 |
14. |
кафе |
автотрасса |
смешанная |
высокий |
35 |
15. |
бистро |
автотрасса |
смешанная |
ниже среднего |
20 |
16. |
ресторан |
центр |
национальная |
средний |
35 |
17. |
бистро |
район города |
национальная |
средний |
25 |
18. |
кафе |
район города |
национальная |
высокий |
25 |
19. |
ресторан |
район города |
традиционная |
высокий |
60 |
20. |
бистро |
автотрасса |
традиционная |
средний |
20 |
21. |
бистро |
центр |
смешанная |
ниже среднего |
10 |
Задача состоит в выборе варианта для каждого отведенного под строительство места, обладающего наименьшим риском получения отрицательного результата. Для решения поставленной задачи можно использовать модель множественного выбора.
Для числового представления исходных данных введем коды, представленные в табл. 3.14.
Т а б л и ц а 3.14
Таблица условных кодов
-
Тип предприятия общественного питания:
0 – ресторан;
1 – кафе;
2 – бистро.
Тип кухни:
1 – смешанная;
2 – традиционная;
3 – национальная.
Место расположения:
1 – центр города;
2 – городской район, удаленный от центра
3 – автотрасса.
Уровень дохода потенциальных потребителей:
1 – высокий;
2 – средний;
3– ниже среднего.
Используя введенные коды, сформируем таблицу данных для построения модели (см. табл. 3.15).
В результате выполнения необходимых действий в пакете STATISTICA были получены расчетные характеристики мультиномиальной логит-модели. модели, которые отражены в табл. 3.15 – 3.17.
Т а б л и ц а 3.15
Числовое представление исходных данных
№ |
|
|
|
|
|
№ |
|
|
|
|
|
1. |
0 |
1 |
2 |
1 |
60 |
12. |
0 |
1 |
1 |
1 |
40 |
2. |
0 |
2 |
3 |
1 |
45 |
13. |
0 |
3 |
2 |
1 |
45 |
3. |
1 |
1 |
1 |
2 |
20 |
14. |
1 |
3 |
1 |
1 |
35 |
4. |
2 |
3 |
3 |
3 |
15 |
15. |
2 |
3 |
1 |
3 |
20 |
5. |
1 |
3 |
3 |
1 |
35 |
16. |
0 |
1 |
3 |
2 |
35 |
6. |
1 |
2 |
2 |
2 |
60 |
17. |
2 |
2 |
3 |
2 |
25 |
7. |
0 |
2 |
2 |
3 |
50 |
18. |
1 |
2 |
3 |
1 |
25 |
8. |
1 |
1 |
2 |
3 |
15 |
19. |
0 |
2 |
2 |
1 |
60 |
9. |
0 |
3 |
3 |
1 |
50 |
20. |
2 |
3 |
2 |
2 |
20 |
10. |
1 |
2 |
2 |
1 |
30 |
21. |
2 |
1 |
1 |
3 |
10 |
11. |
1 |
2 |
1 |
2 |
10 |
|
|||||
Т а б л и ц а 3.15