

19 Усовершенствованные алгоритмы сортировки. Сортировка Шелла. Сортировка Шелла
На первом проходе группируются и сортируются все элементы, отстающие друг от друга на 4 позиции. Этот процесс называется 4-сортировка. Далее объединяются и сортируются элементы отстоящие друг от друга на 2 позиции. Это 2-сортировка. Наконец, на 3м проходе все элементы сортируются обычной сортировкой (или 1 сортировкой).
На каждом шаге сортировки либо участвует сравнительно мало элементов, либо они уже хорошо упорядочены и требует мало пересылок. Программа должна разрабатываться вне связи с конкретной последовательностью приращений h1, h2, …, ht, ht = 1, hi+1<hi Каждая h сортировка программируется как сортировка простыми включениями, при этом, для того, чтобы условие окончания поиска места включения было простым использованием барьер.
Каждая h-сортировка требует собственного барьера, поэтому массив надо дополнить одной компонентой a0, а h1 т.е. массив заменяется как a: array [-h1 .. n] of item
Затраты, которые требуются для сортировки n элементов, пропорциональны n. Это значительно лучше по сравнению с простыми алгоритмами сортировки, хотя известны и лучшие алгоритмы.
Procedure shell;
Const t = 4;
var i, j, k, s: index; x: item; m: 1..t;
h: array[1..t] of integer;
begin
h[1]:=9; h[2] := 5; h[3]:=3; h[4]:=1;
for m:=1 to t do begin
k:=h[m]; s:=-k; {место барьера}
for i:=k+1 to n do begin
x := a[i]; j := i - k;
if s=0 then s :=-k;
s:=s+1; a[s] :=x;
while x<a[j] do begin;
a[j+k] := a[j]; j := j - k;
end;
a[j+k] := x;
end;
end;
end;
Сортировка с разделением (quick sort)
Основана на методе пузырька. Основана на том факте, что обмены необходимо проводить на больших расстояних. Предположим, даны n элементов, с ключами, расположенными в обратном порядке. Их можно рассортировать, выполнив всего n/2 обменов, поменяв местами самый левый и самый правый и т.д. к середине (это возможно, если известно, что элементы уже расположены в обратном порядке)
Рассмотрим следующий алгоритм: Выберем случайным образом некоторый элемент массива (X). Просмотрим массив, двигаясь слева направо, пока не найдем элемент ai>x , а затем просмотрим его справа налево, пока не найдем aj < x . Поменяем их местами и продолжим процесс просмотра с обменом, пока оба просмотра не встретятся где-то в середине массива.
Наша цель не только разделить массив на 2 части, но и отсортировать его. Разделив массив, надо сделать тоже самое с полученными частями, затем с частями этих частей, пока каждая часть не будет содержать 1 элемент.
Анализ быстрой сортировки : в лучшем случае число сравнений n*log n, число обменов – (n / 6) * log n. Но при небольших n эффективность невелика. В наихудшем случае, когда в качестве x выбирается наибольшее значение в подмассиве, эффективность становится порядка n*n. (В отличие от пирамидальной сортировки, у которой даже в наихудшем случае эффективность n*log n).
20 Ссылочные типы. Динамические структуры данных
Статическими величинами называются такие, память под которые выделяется во время компиляции и сохраняется в течение всей работы программы. В Pascal существует способ выделения памяти под данные, который называется динамическим. Раздел оперативной памяти, распределяемый статически, называется статической памятью; динамически распределяемый раздел памяти называется динамической памятью (динамически распределяемой памятью).
Р
 абота
с динамическими величинами связана с
использованием еще одного типа данных
— ссылочного
типа.
Величины, имеющие ссылочный тип, называют
указателями.
Указатель
содержит адрес поля в динамической
памяти, хранящего величину определенного
типа. Сам указатель располагается в
статической памяти. Адрес
величины
— это номер первого байта поля памяти,
в котором располагается величина. Размер
поля однозначно определяется типом.
Величина ссылочного типа (указатель)
описывается в разделе описания переменных
следующим образом:
абота
с динамическими величинами связана с
использованием еще одного типа данных
— ссылочного
типа.
Величины, имеющие ссылочный тип, называют
указателями.
Указатель
содержит адрес поля в динамической
памяти, хранящего величину определенного
типа. Сам указатель располагается в
статической памяти. Адрес
величины
— это номер первого байта поля памяти,
в котором располагается величина. Размер
поля однозначно определяется типом.
Величина ссылочного типа (указатель)
описывается в разделе описания переменных
следующим образом:
Var <идентификатор> : ^<имя типа>;
Память под динамическую величину, связанную с указателем, выделяется в результате выполнения стандартной процедуры NEW. (NEW(<указатель>);) В качестве ссылочного выражения можно использовать указатель; ссылочную функцию (т.е. функцию, значением которой является указатель); константу Nil. Nil — это зарезервированная константа, обозначающая пустую ссылку. В Паскале имеется стандартная процедура, позволяющая освобождать память от данных, потребность в которых отпала. DISPOSE(<указатель>);
Списки
Схематически связанный список выглядит так:
З
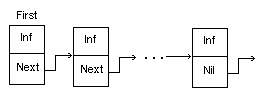 десь
Inf — информационная часть звена списка,
Next — указатель на следующее звено
списка; First — указатель на заглавное
звено списка.
десь
Inf — информационная часть звена списка,
Next — указатель на следующее звено
списка; First — указатель на заглавное
звено списка.
Е
 сли
указатель ссылается только на следующее
звено списка (как показано на рисунке),
то такой список называют однонаправленным,
если на следующее и предыдущее звенья
— двунаправленным
списком.
Если указатель в последнем звене
установлен не в Nil, а ссылается на
заглавное звено списка, то такой список
называется кольцевым.
сли
указатель ссылается только на следующее
звено списка (как показано на рисунке),
то такой список называют однонаправленным,
если на следующее и предыдущее звенья
— двунаправленным
списком.
Если указатель в последнем звене
установлен не в Nil, а ссылается на
заглавное звено списка, то такой список
называется кольцевым.
Выделим типовые операции над списками:
1 Добавление звена в начало списка
Procedure V_Nachalo(Var First : U; X : BT);
Var Vsp : U;
Begin
 New(Vsp); Vsp^.Inf := X;
Vsp^.Next := First; First := Vsp;
New(Vsp); Vsp^.Inf := X;
Vsp^.Next := First; First := Vsp;
End;
2. Удаление звена из начала списка
Procedure Iz_Nachala(Var First : U; Var X : BT);
Var Vsp : U;
Begin
Vsp := First; First := First^.Next; X := Vsp^.Inf; Dispose(Vsp);
End;
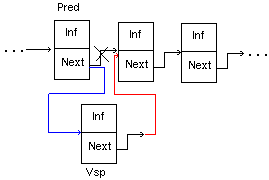
3. Добавление звена в произвольное место списка, отличное от начала (после звена, указатель на которое задан)
Procedure V_Spisok(Pred : U; X : BT);
V
 ar
Vsp : U;
ar
Vsp : U;
Begin
New(Vsp); Vsp^.Inf := X;
Vsp^.Next := Pred^.Next;
Pred^.Next := Vsp;
End;
4. Удаление звена из произвольного места списка, отличного от начала (после звена, указатель на которое задан)
Стек — динамическая структура данных, представляющая из себя упорядоченный набор элементов, в которой добавление новых элементов и удаление существующих производится с одного конца, называемого вершиной стека. По определению, элементы извлекаются из стека в порядке, обратном их добавлению в эту структуру, т.е. действует принцип "последний пришёл — первый ушёл".