

12.1 Решаемые задачи
Построение полупроводниковых приборов
Сверхпроводимость, Структурная биология, Разработка фармацевтических препаратов, Генетика человека, Астрономия, Транспортные задачи, Гидро- и газодинамика, Управляемый термоядерный синтез, Эффективность систем сгорания топлива, Разведка нефти и газа, Вычислительные задачи наук о мировом океане, Разпознавание и синтез речи, Разпознавание изображений
Вообще, в развитии вычислительных средств выделяют три основные проблемы: - повышение производительности; - повышение надежности; - покрытие семантического разрыва Этапы развития вычислительных средств принято различать по поколениям машин. Поскольку огромный вклад в развитие вычислительных средств всегда принадлежал технологическим решениям, основополагающей характеристикой поколения машин считалась элементная база. В настоящее время актуальным является переход к новым поколениям вычислительных средств: одним из доминируюших направлений развития суперЭВМ можно назвать вычислительные системы c MIMD-параллелизмом на основе матрицы микропроцессоров. Для создания подобных вычислительных систем, состоящих из сотен и тысяч связанных процессоров, потребовалось преодолеть ряд сложных проблем как в программном обеспечении (языки Parallel Pascal, Modula-2, Ada), так и в аппаратных средствах (эффективная коммутационная среда, высокоскоростные средства обмена, мощные микропроцессоры). Элементная база современных выcокопроизводительных систем характеризуется выcокой степенью интеграции (до 3,5 млн. транзисторов на кристалле) и высокими тактовыми частотами (до 600 МГц) По сложившейся традиции решающая роль отводится технологии производства элементной базы. В то же время становится очевидным, что технологические решения утратили монопольное положение.
12.2 Отличия локальных сетей от глобальных
Протяженность, качество и способ прокладки линий связи.
Сложность методов передачи и оборудования.
Скорость обмена данными. Одним из главных отличий локальных сетей от глобальных является наличие высокоскоростных каналов обмена данными между компьютерами, скорость которых (10,16и100 Мбит/с) сравнима со скоростями работы устройств и узлов компьютера - дисков, внутренних шин обмена данными и т. п.
Оперативность выполнения запросов. Время прохождения пакета через локальную сеть обычно составляет несколько миллисекунд, время же его передачи через глобальную сеть может достигать нескольких секунд. Низкая скорость передачи данных в глобальных сетях затрудняет реализацию служб для режима on-line, который является обычным для локальных сетей.
Разделение каналов. В локальных сетях каналы связи используются, как правило, совместно сразу несколькими узлами сети, а в глобальных сетях - индивидуально.
Масштабируемость. «Классические» локальные сети обладают плохой масштабируемостью из-за жесткости базовых топологий.
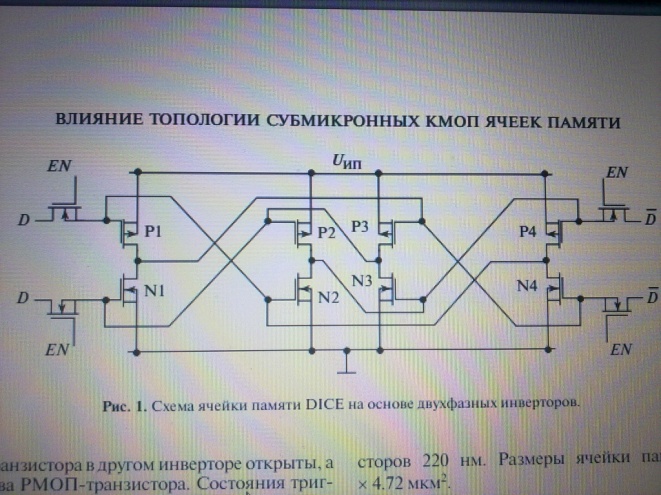
12.3 Ячейка памяти DICE (см. рис. 1) основана на 8-транзисторном КМОП двухфазном D триггере , который состоит из двух двухфазных инверторов на парах транзисторов – один инвертор на транзисторах N1, P1 и N2, P2, а второй – на транзисторах N3, P3 и N4, P4. D триггер может находиться в двух устойчивых состояниях, причем в каждом из этих
состояний два NМОП транзистора в одном из двухфазных инверторов закрыты, два других NМОП транзистора в другом инверторе открыты, а
закрыты два PМОП транзистора. Состояния триггера – логическая “1” и логический “0” определяются состояниями инверторов. При хранении логического “0” или “1” состояния инверторов в D триггере ячейки DICE меняются. В случае ячеек памяти DICE для гарантированного сбоя состояния ячейки необходимо одновременное изменение состояния двух закрытых NМОП транзисторов под ионизирующим воздействием частицы. Устройство ячейки памяти DICE (а фактически D триггера на двухфазных инверторах) позволяет провести эксперимент по оценке влияния воздействия отдельных ядерных частиц на зависимость сбоеустойчивочти КМОП элементов от расстояния
между чувствительными областями этих элементов. Повышение сбоеустойчивости ячейки памяти DICE может быть обеспечено использованием конструктивно- топологических решений, в которых зарядочувствительные области каждого инвертора разносятся на максимально допустимое расстояние желательно при минимальных дополнительных затратах площади кристалла.
№13
Основные типы архитектур параллельных ЭВМ. Симметричные мультипроцессорные системы.
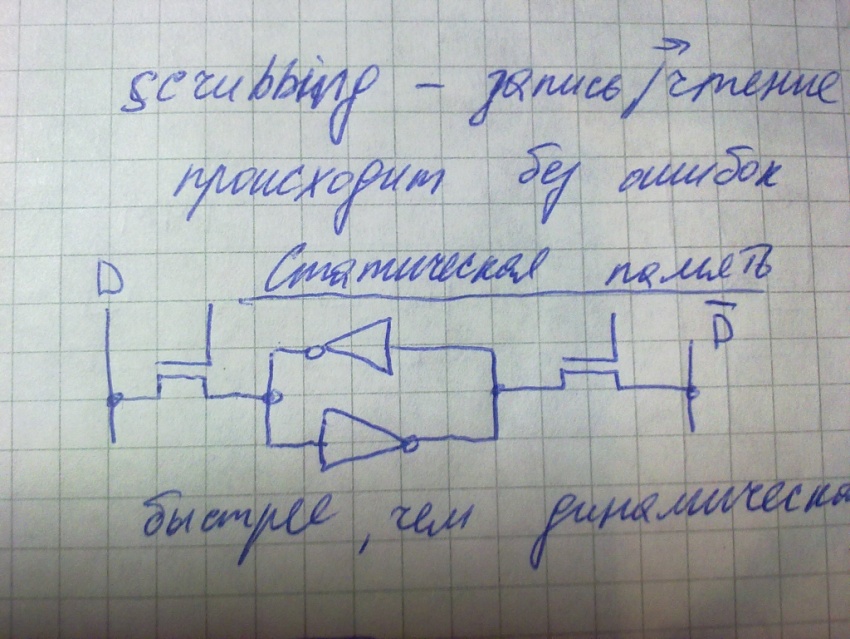
Построение синхронных схем с отключаемым синхросигналом, временная диаграмма функционирования.
Проектирование микросхем Front end и Back end.
1.Архитектура – набор команд, их структура и способ исполнения.
По степени связанности базовых вычислительных устройств(параметр связанности определяется способом размещения памяти и скоростью обмена данными между устройствами и памятью)
3 класса:
Симметричные МП(SMP). Архитектура с разделяемой памятью – вся память системы доступна МП
 Не
более 64 вычислителей. Но: ограничение
адресного пространства; снижение
надежности.
Не
более 64 вычислителей. Но: ограничение
адресного пространства; снижение
надежности.Массивно параллельные процессоры(MPP)
Система с разделенной памятью. Каждый вычислит. узел имеет свою память недоступную др узлам.
+:Простое масштабирование, выше надежность,выше эффективность подсистемы памяти.
 1.latency t1→
→t2
(60нс)
1.latency t1→
→t2
(60нс)
2.
Скорости передачи10ГГц-4х->40Гбит/с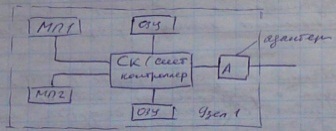
3.Архитектура с неоднородной памятью(NUMA)
Каждый вычислитель имеет свою память с высокой скоростью доступа и пониженную скорость доступа к остальной памяти.
Если
поддерживается когерентность: CC-NUMA
2.
3. Стандартная ячейка состоит из группы транзисторов и соединений между ними, которые реализуют либо некоторую логическую функцию либо элемент хранения. Логическая функциональность ячейки - logical view: поведение ячейки соответствует таблице истинности. Разработчики ячеек используют CAD системы, например, SPICE для симуляции электрического поведения нетлиста, подавая ему на вход различные сигналы и получая вычисленный аналоговый ответ схемы вместе с его временными характеристиками. Разработка физической реализации- layout view. Представление ячейки разделено на базовые слои, которые соответствуют различным структурам транзистора и межсоединений, замыкающих между собой выводы транзисторов.
Front-end включает в себя логические описания (Verilog, VHDL), характеризацию и вспомогательные элементы для функциональной верификации.
Back-end содержит описания, относящиеся в физической имплементации ячеек. LEF (Layout exchange format) условно делится на библиотечную и технологическую части. Библиотечная часть содержит геометрические сведения о внешней физической структуре ячеек. Технологическая часть содержит разнообразные правила проектирования, необходимые для размещения и разводки чипа. Вторая важная деталь back-end наполнения библиотеки стандартных элементов - это нетлисты. Плюсы:простота разработки, уменьшение используемой памяти. Минусы: процесс проектирования не очень гибок, результаты моделирования ИС получаются приблизительными,проект зависит от качества библиотеки.
№14
Системы с неоднородным доступом к памяти.
Традиционный способ построения синхронных схем. Нарисовать принципиальную электрическую схему. Время предустановки и сохранения сигнала.
Этапы разработки микросхем.
1. NUMA (Non-Uniform Memory Access — «неравномерный доступ к памяти» или Non-Uniform Memory Architecture — «Архитектура с неравномерной памятью») — схема реализации компьютерной памяти, используемая в мультипроцессорных системах, когда время доступа к памяти определяется её расположением по отношению к процессору.
Каждый вычислитель имеет свою память с высокой скоростью доступа и пониженную скорость доступа к остальной памяти.

2. Простейшая схема синхронизации асинхронных сигналов:

Традиционная схема:


Время предустановки сигнала A относительно сигнала B — это интервал между началами обоих сигналов.
Время сохранения — интервал между окончанием сигнала A и окончанием сигнала B.. Этот интервал необходимо обеспечить для уменьшения вероятности появления ошибки при чтении «неустановившейся» информации.
3.
постановка задачи
построение развернутой блок-схемы устройства
выбор элементной базы и построение полной принципиальной
расчет параметров всех элементов устройства
разработка конструктивного исполнения, сборка и настройка устройства
Билет № 15 (1.MPP, 2.Заглушка, 3.Задача)
MPP (massive parallel processing) – массивно-параллельная архитектура. Главная особенность такой архитектуры состоит в том, что память физически разделена. В этом случае система строится из отдельных модулей, содержащих процессор, локальный банк операционной памяти (ОП),коммуникационные процессоры (роутеры) или сетевые адаптеры, иногда – жесткие диски и/или другие устройства ввода/вывода. Прямой доступ к банку ОП из данного модуля имеют только процессоры (ЦП) из этого же модуля. Доступ к памяти других узлов реализуется обычно с
помощью механизма передачи сообщений. Модули соединяются специальными коммуникационными каналами.
Главные преимущества MPP (по сравнению с SMP):
простое масштабирование
выше надежность
выше эффективность подсистемы памяти
Недостатки:
отсутствие общей памяти заметно снижает скорость межпроцессорного обмена, поскольку нет общей среды для хранения данных, предназначенных для обмена между процессорами. Требуется специальная техника программирования для реализации обмена сообщениями между процессорами;
каждый процессор может использовать только ограниченный объем локального банка памяти;
вследствие указанных архитектурных недостатков требуются значительные усилия для того, чтобы максимально использовать системные ресурсы. Именно этим определяется высокая цена программного обеспечения для массивно-параллельных систем с раздельной памятью.
МП1
Узел 1
А(адаптер)
ОЗУ
ОЗУ
СК(сист.контроллер)
МП2






 остав
узла: Типы
связи узлов:
остав
узла: Типы
связи узлов:
Точка-точка:
Узел2
Узел1

Коммутатор:
Коммут.
У1

У2
Сложные архитектуры(кольцо):
У3
У2
А
А
У4
У5
У1
А
А







А
Клиентская заглушка представляет собой компонент, размещаемый на той же машине, где находится компонент-клиент. Удаленный вызов процедуры клиентом реализуется как обычный, локальный вызов определенной функции в клиентской заглушке. При обработке этого вызова клиентская заглушка выполняет следующие действия:
Определяется физическое местонахождение в системе сервера, для которого предназначен данный вызов. Это шаг называется привязкой (binding) к серверу. Его результатом является адрес машины, на которую нужно передать вызов.
Вызов процедуры и ее аргументы упаковываются в сообщение в некотором формате, понятном серверной заглушке (см. далее). Этот шаг называется маршалингом (marshaling).
Полученное сообщение преобразуется в поток байтов (это сериализация, serialization ) и отсылается с помощью какого-либо протокола, транспортного или более высокого уровня, на машину, на которой помещен серверный компонент.
После получения от сервера ответа, он распаковывается из сетевого сообщения и возвращается клиенту в качестве результата работы процедуры.
В результате для клиента удаленный вызов процедуры выглядит как обращение к обычной функции.
Серверная заглушка располагается на той же машине, где находится компонент-сервер. Она выполняет операции, обратные к действиям клиентской заглушки — принимает сообщение, содержащее аргументы вызова, распаковывает эти аргументы при помощи десериализации (deserialization) и демаршалинга (unmarshaling), вызывает локально соответствующую функцию серверного компонента, получает ее результат, упаковывает его и посылает по сети на клиентскую машину.
Таким образом обеспечивается отсутствие видимых серверу различий между удаленным вызовом некоторой его функции и ее же локальным вызовом.
 3.
3.