

Затраты на перемещение данных через сеть
Возникают дополнительные задержки, которые связаны с занятостью сети, обеспечивающей передачу данных, и наличием очереди к серверу БД от нескольких абонентов сети на обработку запросов.
Оптимизатор Использует следующую информацию, которая хранится в системных отношениях:
Число кортежей в любом отношении, которое соответствует последнему результату специально выполненного SQL оператора UPDATE STATISTICS.
Число страниц на диске, занятых картежами отношения.
Признаки ограничения уникальности на атрибуты отношения.
Информация об атрибутах, на которых построены индексы. Являются ли они убывающими, возрастающими, кластерными. Кластерный индекс используется для физической сортировки значений отношения в порядке, переписанном индексом.
Число страниц на диске, занятых элементами индекса.
Глубина структуры В-дерева индекса для оценки глубины поиска.
Оптимизатор выполняет следующие действия:
Оценивает фильтры
(определяет долю картежей, проходящих через фильтры, можно ли использовать индексы и как их использовать).
Оптимизатор оценивает селективность каждого из найденных фильтров и использует его в своих расчетах. Селективность – это число между 0 и 1, указывающее долю картежей отношения, которые пройдут через фильтр. Существует соответствие между фильтрами разных типов и значениями селективности. Например выражению 'индексный атрибут IS NULL' соответствует селективность F=1 (число разных ключей в индексе).
Пример: В запросе – фильтр: WHERE O.A=253. Сервер не будет читать картежи отношения 'O', а будет искать значение 253 в индексе построенном на атрибуте 'A' отношения 'O'.
Выбор способа доступа к отношению
(последовательное чтение картежей / чтение индекса, а затем картежей, на которые указывает индекс / создание временного индекса, его чтение, а затем картеж, на который указывает индекс).
Пример: Построен индекс на некотором атрибуте, этот атрибут используется в фильтре. Тогда сервер БД будет выбирать картежи через индекс, и обрабатывать только эти картежи.
Пример: Фильтра нет, то сервер БД будет читать картежи независимо от наличия индекса.
Оптимизатор принимает решение о создании временного индекса в следующих случаях:
Выполняется соединение отношений значительных размеров, а ни одно отношение не имеет индекса на атрибуте соединения.
При генерации картежей в отсортированной или сгруппированной последовательности.
Выбор плана запроса
(при соединении нескольких отношений рассматриваются результирующие пары и выбирается пара, имеющая меньшую стоимость. Затем для результирующего отношения пустая пара с (•) наименьшей стоимости и т.д.).
Если необходимо отобразить результат в отсортированном виде (ORDER BY или GROUP BY), то оптимизатор строит дополнительные временные индексы и добавляет стоимость, связанную с сортировкой.
Т.о. оптимизатор строит план, который имеет наименьшую стоимость работ и передает ее серверу.
Работа сервера с протоколированием плана запроса
SET EXPLAIN ON
Протокол плана записывается в специальный файл, имя и его местоположение зависит от операционной системы.
Отключение протоколирования: SET EXPLAIN OFF
Пример: Объяснение плана запроса:
SELECT C.A, O.B, SUM (I.D.) FROM C,O,I
WHERE C.A=O.A AND O.B=I.B
GROUP BY C.A, O.B
Вычисленная стоимость: 104. Вычисленное число возвращаемых картежей: 2.
Сообщение оптимизатора |
Разъяснение действий оптимизатора |
1) pubs.O : INDEX PATH (1) индексные ключи: B |
Используется индекс, картежи отношения O читаются в порядке следования значений атрибута B |
2) pubs.C : INDEX PATH (1) индексные ключи: A (key-only) исп-ый инд-ый фильтр pubs.C.A = pubs.O.A |
Используется индекс, построенный на атрибуте A. key-only означает, что читается только индекс и проверяется: C.A = O.A, а картежи самого отношения C не читаются |
3) pubs.I : INDEX PATH (1) индексные ключи: B исп-ый инд-ый фильтр: pubs.I.B = pubs.O.B |
Для каждого картежа отношения O, для которого совпадение с картежом отношения C по атрибуту A, осуществляется поиск картежа в отношении I с использованием индекса на атрибут B |
Типовые приемы ускорения выполнения sql-запросов.
Модификация запросов:
1. Исключить или упростить физическую сортировку большого количества кортежей путем создания индексов. (Оптимизатор всегда использует индекс при формировании результирующего отношения, если он имеется, и не выполняет сортировку для выдачи результата в нужном порядке)
2. Устранить последовательный доступ к большим отношениям за счет построения индексов на атрибуте, который используется в соединении отношений (например,C.A=0.A).
3. Использование объединения для исключения последовательного доступа даже при наличии индекса (например, запрос использует последовательный доступ:
SELECT * FROM сотрудник
WHERE (табельный номер=104 AND зарплата>100) OR (зарплата=1300)
Запросы используют индексный способ доступа:
SELECT * FROM сотрудник
WHERE (табельный_номер=104 AND зарплата>100)
UNION
SELECT * FROM сотрудник WHERE зарплата=1300
4. Замена автоматически создаваемых временных индексов на постоянные индексы.
5. Использование составных индексов (например, индекс, построенный на атрибутах a,b,c(в указанном порядке) будет использоваться в следующих случаях:
• для вычисления выражений фильтра, накладываемого на атрибут a;
• для соединения двух отношений по атрибуту a;
• для реализации спецификатора ORDER BY или GROUP BY на атрибутах a; a, b; или a, b, c (но не b; c; a, c или b, c)).
6. Уничтожение и повторное создание индексов в случае нарушения структуры индексных деревьев (проверить можно с помощью спец.утилиты).
7. Исключение коррелированных подзапросов. Пример: выбрать табельные номера и фамилии сотрудников библиотеки с двумя наиболее поздними датами начала работы:
SELECT Табел._номер, Фамилия FROM Сотрудник X
WHERE
(SELECT COUNT (DISTINCT дата_приема_на_работу) FROM Сотрудник Y WHERE Y. Дата_приема_на_работу >X. Дата_приема_на_работу) <2.
8. Исключение сложных с точки зрения реализации шаблонов и фильтров
(например: SELECT * FROM сотрудник
WHERE табел._номер LIKE <<18__>>
Переписать:
SELECT * FROM сотрудник
WHERE табел._номер <= <<1900>>)
9. Исключение из фильтров не начальных символов значения подстроки (например:
SELECT * FROM сотрудник
WHERE фамилия [3, 4] > <<летд>>)
10. Использование временных отношений как источник отсортированных данных для исключения многократных одинаковых сортировок
(например: SELECT a.имя, b.баланс FROM клиент a, платежи b
WHERE a.код = b.код AND b.баланс > 0 AND a.почтовый индекс LIKE <<42_ _ _ _>>
ORDER BY a.имя
Заменяется на 2 запроса:
SELECT a.имя, b.баланс, a.почтовый_индекс FROM клиент a, платежи b
WHERE a.код = b.код AND b.баланс > 0
ORDER BY a.имя
INTO TEMP пользователь_баланс
и
SELECT имя, баланс FROM пользователь_баланс
WHERE почтовый_индекс LIKE <<42 _ _ _ _>>
Способы доступа к записям Хеширование
Сохранение записи – программа хеширования ставит в соответствие значению первичного ключа номер страницы, куда помещается запись.
Синонимы – запись, для которых алгоритм хеширования дает одинаковый результат. Синонимы объединяются в цепной список, начало которого лежит в заголовке страницы.
Пример 2-х цепей синонимов

Извлечение записи – программа хеширования вычисляет номер страницы, затем просматривается цепной список.
Индексирование по первичному ключу.
Размещая записи на страницах данных диска, формируется спец. индексные таблицы. Как отыскать запись с ключом 210?
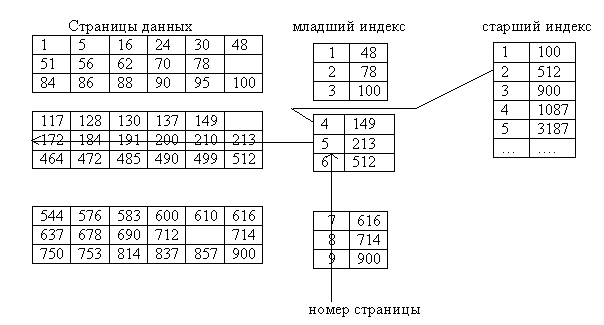
Индексирование по вторичному ключу.
Необходимо выбрать запись по должности и году рождения:
-
Ключ
Ф.И.О.
Должность
Год рождения
1
Иванов И.И
инженер
1947
2
Петров П.П
техник
1945
3
Сидоров С.С
инженер
1965
Варианты выбора:
Последовательный просмотр записей – неэффективно.
Использовать вторичное индексирование, объявив Должность и Год – вторичными ключами:
Строятся 2 индекса:
Алгоритм выполнения запроса: «Найти записи об инженерах с годом рождения не ранее 1960 г.»
Сервер обрабатывает индекс 1. Получается список ключей записей об инженерах. Это: 1 и 3.
Сервер обрабатывает индекс 2. получается список ключей записей о годах. Это: 3.
Сервер строит пересечение этих списков, которое дает в результате список ключей записей, удовлетворяющих запросу: 3.
Если индексирование организовано на основе первичного ключа, то индекс называется первичным или уникальным. Если на основе вторичного ключа, то – вторичным.
Организация индексных таблиц (случай одиночных записей в бд).
Бинарные деревья. Это иерархические структуры, которые по значению ключа позволяют быстро найти запись на диске.
Пример: последовательность загрузки и значения ключей записи:
Номер записи |
Ключ записи |
1 2 3 4 5 6 |
12 8 4 9 6 13
|
Номер записи |
Ключ записи |
7 8 9 10 11 12 |
14 16 100 10 25 31
|
Для такой последовательности записей бинарное дерево:
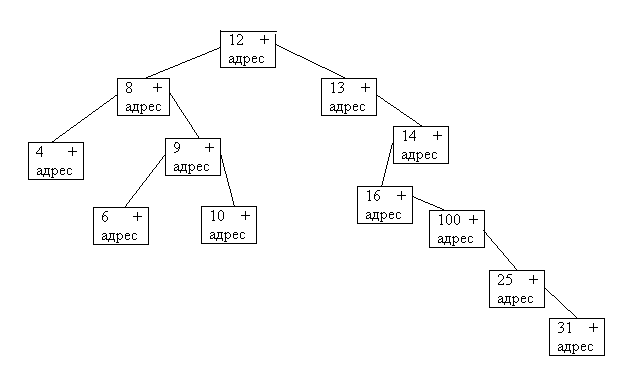
Каждой записи на диске соответствует запись индексного файла: значение ключа записи, адрес записи и 2 адресной ссылки: - на адрес индексной записи с меньшим ключом, а вторая – на адрес индексной записи с большим ключом. При запоминании очередной индексной записи – система определяет логическое расположение, начиная с корневой вершины.
В – деревья.
В-дерево n-го порядка должно удовлетворять след.условиям:
1. Каждая вершина может содержать n –адресных ссылок и n-1 ключей. Ссылка влево от ключа обеспечивает переход к вершине дерева с меньшими по значению ключами, а вправо к вершине с большими ключами.
2. Любая неконечная вершина имеет не менее n/2 подчиненных вершин.
3. Если не конечная вершина содержит к(к<=n) ключей, то ей подчинена (к+1)-вершина на следующем уровне иерархии.
4. Все конечные вершины В-дерева расположены на одном уровне.
Пример построения В-дерева .
(Хранятся два ключа и три адресный ссылки)
Ш
8 . 12
Корневая вершина содержит только 12, затем сдвигается
затем сдвигается вправо, уступая место 8.
Ш
8 .
. 4 . 6
. 9 . 12
 аги
3,4,5 Для 4 нет места, поэтому – деление:
выбирается 8, чтобы 4
аги
3,4,5 Для 4 нет места, поэтому – деление:
выбирается 8, чтобы 4
и 12 попали в две подчиненные вершины (ограничения 2 и
3). На шагах 4,5 – перемещаются ключи.
. 8 . 12 .
Ш
. 4 . 6
. 9 . .
. 13 . 14

 аги
6,7
Шаг 6 требует новое деление. 12 –
перемещается
аги
6,7
Шаг 6 требует новое деление. 12 –
перемещается
на верхний уровень.13.14 – в новую вершину.
Ш
. 12 . .
. 8 . .
. 14 . .
. 4 . 6 .
. 9 . 10 .
. 13 . .
. 16 . 100 .



 аги
8,9,10 Шаг 8 – требует деления. 16.100 – запи
аги
8,9,10 Шаг 8 – требует деления. 16.100 – запи
сываются в новую вершину, 10 – в
старую.
Ш
. 12 . .
. 8 . .
. 14 . 25 .
. 4 . 6 .
. 9 . 10
. 13 . .
. 16 . .
. 31 . 100

 аги
11, 12 Шаг 11 – требует деления
аги
11, 12 Шаг 11 – требует деления
Все конечные вершины находятся на одном уровне – дерево сбалансированное.с увеличением порядка Б – дерева сокращается число его уровней, а => и время просмотра.
Технология взаимодействия объектов и программ.
СОМ (Component Object Model – компонентная модель объектов) – технология Microsoft.
1. Программа клиент и СОМ – объекты располагаются на одном компьютере и запускаются в одном процессе (пример: программа Delphi использует компоненты ActivX).
Процесс клиента:
СОМ – сервер (DLL
– библиотека)

СОМ - объект
Программа - клиент
Интерфейс СОМ объекта идентификатор и набор параметров, описывающих методы, события и свойства.
2. Программа клиент и программа, содержащая объекты, располагаются на одном компьютере и запускаются в разных процессах (пример: таблицы Excel вставлены в документы Word).
Процесс клиента
СОМ – сервер
(процесс программы)
Stub


Proxy
СОМ
Объект
Программа клиент
Между программой клиентом и объектом располагаются два посредника:
Proxy (уполномоченный) и Stub (заглушка).
Технология взаимодействия:
Клиент обращается к интерфейсу объекта и перемещает параметры вызова в стек.
Proxy перехватывает обращение, упаковывает параметры вызова в пакет СОМ и направляет в Stub другого процесса.
Stub распаковывает параметры. Помещает в стек и делает вызов нужного метода объекта.
Метод выполняет в собственном адресном пространстве и результат возвращает обратно.
3. Программа клиент и программа, содержащая объекты, располагаются на разных компьютерах.
Процесс клиента
DCOM
Процесс другого компьютера
Proxy
Программа клиент
Stub
DCOM
СОМ – сервер (программа, содержащая
объекты или СОМ – объект в DLL
– библиотеке)



DCOM (Distributed COM ) – распределенный вариант СОМ.
CORBA (Common Object Require Broker Architecture – архитектура с поставщиком требуемых общих объектов) – технология группы OMG.
Процесс клиента
Сетевое окружение
клиент
Stub
Smart Agent
Сервер объектов
BOA




Машина сервер
 Протокол UDP
Протокол UDP
UDP

Stub (заглушка) – объект – посредник; ORB (Object Require Broker – брокер требуемого объекта); Smart Agent – «умный» агент; BOA (Basic Object Adapter – базовый объектный адаптер; Skeleton (скелет) – особый объект сервера.
Технология взаимодействия:
клиент обращается к Stub, как если бы это был сам объект.
Stub транслирует этот вызов объекту ORB, который посылает в сеть широковещательное сообщение.
Откликается один из объектов Smart Agent, установленный в сетевом окружении клиента.
Smart Agent формирует сетевой каталог, в котором зарегистрированы известные ему серверы объектов. Он отыскивает нужный сетевой адрес сервера и передает запрос объекту ORB на машине сервера.
Адаптер BOA передает данные Skeleton.
Skeleton помещает параметры вызова в стек адресного пространства объекта и реализует собственно вызов.
Сравнение технологий СОМ и CORBA.
Весь интерфейс Windows построен на СОМ технологии. Спектр применения СОМ значительно шире, чем у CORBA. Рекомендована для работы в распределенной среде, работающей под Windows.
CORBA значительно сложнее СОМ, как в понимании деталей ее работы, так и практической реализации. Рекомендована для работы в кросс – платформенной (неоднородной) среде, требующей высокой надежности.
Перспективы: WEB – технологии – центральная роль в корпоративных разработках.
Хранилища данных (Data Warehouse) и оперативный анализ данных (On Line Analytical Processing).
Корпоративная система
Назначения: создание, корректировка
и Назначение: изучение
больших объемов
хранение данных, необходимых в
взаимосвязанных данных при
помощи быстрого
оперативной технологической
интерактивного отображения
информации на
деятельности специалистов
разных уровнях детализации
с различных точек
зрения для принятия управленческих
решений.
Оперативные системы.
Системы поддержки принятия
решений
Банк агрегированных
данных,
Хранимых во времени
Банк оперативных данных




Современные Системы Поддержки Принятия Решений (сппр) используют:
Хранилища данных – агрегированные данные из различных источников.
Оперативный склад данных – буфер между источниками данных и хранилищем, в котором данные преобразуют в единые форматы, очищаются, объединяются и синхронизируются, при необходимости аккумулируются, если период пополнения данных в хранилище дни или недели.
Оперативный склад содержит:
Только текущие значения детальных данных, соответствующие данным оперативных систем.
Частота обновления склада зависит от регламента загрузки данных в склад.
Витрины и киоски данных.
Маленькие хранилища, которые создаются с целью информационного обеспечения аналитических задач подразделений компании, формируются из центрального хранилища. Витрина содержит меньше данных, охватывает несколько предметных областей и имеет более короткую историю.
Метаданные.
Описание на определенных языках для разработчиков и пользователей информации о хранилище: структуре данных, о процессах трансформации и т. д. Например: для пользователей на определенном языке описывается семантика, состав и периодичность пополнения хранилища из источников. А для разработчиков – ERD – диаграммы, правила трансформации и интерфейс доступа к данным источников.
Структура системы поддержки принятия решений (СППР)
Состав модулей СППР.

Подсистема загрузки данных

Задачи модулей – начальная загрузка ретроспективных данных и регламентное пополнение хранилища данными из источников.
Подсистема обработки запросов и представления данных.
Решает следующие задачи:
Формирование регламентированной отчетности (запросы предопределены)
Формирование нерегламентированных запросов (каждый последующий запрос и вид представления определяется результатами предыдущих запросов)
Формирование дополнительных знаний (сложные алгоритмы поиска закономерностей, прогнозирования различных ситуаций)
Подсистема администрирования хранилища.
Решает следующие задачи:
Администрирование оперативного склада. Если необходим ручной ввод, сверка, корректировка данных в оперативном складе.
Администрирование хранилища данных. Поддержка архитектуры хранилища, обеспечение бесперебойной работы, защита и восстановление данных
Администрирование доступа к данным. Разграничение доступа к данным и защита данных от несанкционированного доступа.
Администрирование метаданных
Методика построения сппр
Постановка задачи. (Цель – получение модели данных и описание процедур обработки данных)
Системно-аналитическое обследование
А) Проводится интервью разработчиков с лицами, ответственными за принятие управленческих решений.
Б) Уточняется организационная структура и фиксируются организационные и функциональные рамки проекта.
В) Выявляются недостатки существующих систем
Г) Формализуются информационные потоки предприятия с учетом функциональных решений.
Д) Сбор отчетных материалов.
1.2. Техническое задание.
Определяет требования к заданию СППР порядок этого создания.
1.2.1. Определяются задачи, которые необходимо реализовать на стадии разработки:
а) сбор данных
б) преобразование данных (очистка, согласование, унификация, агрегирование)
в) хранилище данных (промежуточное накопление исторических данных)
г) представление данных потребителям
д) сопровождение метаданных.
1.2.2. Определяется информационное обеспечение системы.
Существует 5 классов данных – источноки данных, оперативный склад данных, хранилище данных, витрины данных, хранилище метаданных.
Разработка информационного обеспечения.
2.1 Определяется состав показателей, их иерархий и измерений для представления данных конечным пользователем:
а) измерение, их иерархии, уровни детализации
Пример: временное изменение – день, неделя, месяц.
б) базовые показатели, их измерения, правило агрегирования.
Пример: доход от продаж – суммирование цена продукции – среднее или максимальное или минимальное значение за период агрегации.
в) производные показатели и формулы их вычисления на основе базовых показателей.
2.2. Определение структуры оперативного склада данных и транзактного файла на основе анализа информации источников данных, алгоритмов их преобразования и периодичности загрузки данных.
2.3. Выявление данных для хранилища, которые отсутствуют в источниках.
Разработка ПО.
Общие ПО:
ПО промежуточного слоя: сетевые протоколы, драйверы.
Серверное ПО (серверы реляционных БД, серверы многомерных БД, серверы приложений – поисковые, аналитические обработки, добычи знаний и др.)
Специальные ПО:
ПО подсистем загрузки данных (из источников и ручного)
ПО администрирования
ПО обработки запросов и представления данных.
Определение технического обеспечения.
Серверное ПО на UNIX или NT платформах. Клиентское ПО – ПК пользователей. Сегменты хранилища и витрины могут располагаться на нескольких компьютерах.
Реализация проекта
Создание БД и ПО, тестирование и доработка, разработка документации и учебные материалы для пользователей, разработка плана внедрения.
Внедрение.
Установка системы у заказчика, загрузка хранилища данными, опытная эксплуатация.
Эксплуатация.
Свойства хранилища и витрин данных.
Предметная ориентация. Предназначена для представления данных, связанных с одним организационным процессом.
Интеграция данных. Данные при записи в хранилище образуются; согласовываются имена, единицы измерения, способы кодирования и др.
Не разрушаемость. Загруженные данные не изменяются.
Длительность хранения. Хранение до 10 лет.
Многомерная модель данных.
а) реляционное представление б) двумерное представление
Модель Месяц Объем Июнь Июль Август
Жигули Июнь 12 Жигули 12 24 5
Жигули Июль 24 Волга 0 19 0
Жигули Август 5 Москвич 2 18 0
Волга Июль 19
Москвич Июнь 12
Москвич Июль 18
Витрины, как многомерные модели данных

Измерения могут иметь иерархическую структуру.
Например трехуровневая иерархия.
П

 роизводитель
автомобилей
роизводитель
автомобилей
Марка авто1 . . . Марка авто3




Модель 11 … Модель 1К Модель 31 … Модель3N
Показателей может быть несколько, поэтому для идентификации ячейки многомерной модели необходимо указать все измерения и показатель.
Средства построения аналитических систем.
DTS – служба импорта, экспорта (из источников поддерживающих OLEDB, ODBC текстовых ASCII-файлов), преобразование данных, перемещение данных между двумя любыми источниками поддерживающими стандарты OLEDB.
Repository – склад для хранения метаданных (средство для описания данных, находящихся в хранилище)
Decision Support Services – службы поддержки принятия решений (инструменты, позволяющие представить информацию из хранилища в виде многомерных кубов и проводить анализ данных).
Созданы специальные компоненты СУБД разработчиков Subase, Oracle.
Критерий выбора средства
Построение аналитических систем.
Полнота (возможности программных продуктов для создания приложений, готовые приложения для аналитического анализа)
Способность компании – разработчика обеспечить техническую поддержку и обучение пользователей.
Интегрировать (способность разработанных приложений взаимодействовать с уже используемыми приложениями)
Неограниченность (обеспечение стабильной работы приложения при значительном расширении числа пользователей и объемов данных).
Публикация бд в Интернет Характеристика Internet
Основными видами услуг, предоставленных пользователям при подключении к Internet, является:
─ электронная почта
─ телеконференция (обмен текстовой информацией. Информация становится доступной любому пользователю, обратившемуся в данную телеконференцию).
─ система эмуляции удалённого терминала (протокол, позволяющий одному компьютеру использовать ресурсы удалённого компьютера. Имеет клиент. и сервер. части).
─ поиск и передача двоичных файлов (протокол и ПО, позволяющие передавать файлы произв. формата м/у компьютерами). Имеет клиент. и сервер. части.
─ поиск и передача текстовых файлов с помощью системы меню (Gopher).
─ поиск и передача документов с помощью гипертекстовых ссылок (www).
Определения
Web-страница представляет собой документ в формате HTML, XML, шаблоны в форматах ASP, HTM и др.
Web-приложение представляет собой набор Web-страниц сценариев и др. программных средств, расположенных на одном или нескольких компьютерах и объединенных для выполнения прикладных задач.
Web-приложения публикующие базы данных в Internet, представляют отдельный класс Web-приложений.
Обозреватель (browser) – программа-навигатор, обеспечивающая доступ к ресурсам Internet.
Протоколы
HTTP - протокол передачи данных гипертекста между обозревателем и сервером.
TCP/IP – универсальный независимый от платформы протокол передачи данных по сети Internet. TCP разбивает файлы на пакеты, добавляет в каждый адрес получателя и порядковый номер пакета в группе пакетов. На компьютере получателя TCP собирает файл из пакетов, проверяет их целостность и м. послать запрос на повторную передачу.
Принципы работы в Internet
- Web-приложение выполняется на стороне Web-сервера в Web-узлах сети Internet.
- Web-сервер обрабатывает запросы обозревателя на получение Web-страниц и отсылает результат в формате Web-документов.
- Обмен данными в сети осуществляется на аппаратном уровне на основе протокола логического уровня HTTP и TCP/IP.
Web-сервер находится в пассивном состоянии, если формируемый документ содержит статическую информацию и отсутствуют средства ввода и передачи запросов к серверу.
Web-сервер находится в активном состоянии, если документ содержит динамически формируемую информацию или когда в обозреватель загружены различные интерактивные элементы формы. Активный Web-сервер реализуется с помощью модулей расширения Web-сервера.
Технология работы приложения в сетях Intranet
Сеть Intranet представляет собой выделенную часть сети Internet, в которой выполняется Web-приложение (информационная система). К сети можно подключиться с удаленного компьютера Internet-сети, для этого необходимо специальный сервер удаленного доступа и специальное ПО на уделенном компьютере.
Принципы построения Intranet-сетей:
Серверы составляют иерархическую структуру. На верхнем уровне – сервер с информацией, необходимой для всех клиентов, на нижних – специализированные серверы.
Использование “двусторонней обратной связи” с клиентами сети для обработки запросов.
Использование группового способа общения и разграничения доступа к информации для пользователей вне группы (на основе использования маршрутизаторов).
Функции Web-сервера в Intranet
Получение запроса от Web-обозревателя
Преобразование этих запросов с помощью модулей расширения сервера
Передача результатов Web-обозревателю
Преимущества применения архитектуры Web-приложений в сетях Intranet по сравнению с технологией “клиент-сервер”:
Стандартизация пользовательского интерфейса
Удобство администрирования
Удешевление установки и лицензирования клиентских компьютеров.
Технология работы Web-приложения с модулями
Обозреватель передает URL Web-серверу.
Web-сервер загружает HTML-страницу.
Если страница содержит интерактивный элемент, то после ввода в него информации, обозреватель обращается с запросом к серверу.
Web-сервер обрабатывает запрос, вызывает и загружает соответствующий модуль расширения сервера, передает ему параметры запроса для формирования Web-документа с использованием различных HTML и HTX шаблонов.
Документ отсылается Web-обозревателю в формате протокола HTTP.
Интерфейс cgi
CGI – стандартный протокол взаимодействия между Web-сервером и модулями расширения.
Обмен информацией между сервером и модулями расширения осуществляется с помощью стандартных потоков ввода/вывода, передача управляющих параметров может организовываться через переменные окружения ОС или через параметры URL-адреса модуля расширения.
Схема взаимодействия CGI
Пользователь вводит данные в специальную форму
Обозреватель формирует HTTP-запрос
Сервер в зависимости от метода в HTTP-запросе формирует параметры для CGI
CGI модуль генерирует HTML-документ.
Пример сценария cgi.
Задача: показать GIF– изображение всякий раз при выполнении сценария.
Пример. Сценарий написанный на языке PERL состоит из следующих разделов.
#!/usr/local/bin/perl – спец. компонент, в кот. указан путь к интерпретатору яз. PERL.
$gif=”/file/path/your.gif”;переменной $gif присвоить полный путь к изображению
Print “content type:Image/gif\n\n”; строка заголовка MIME- типа сообщается серверу, что он получит от сценария графический файл. оператор print выводит на сервер информацию, заключенную в кавычки. Символы \n– переход на новую строку. Создается пустая строка, указывающая серверу, что заголовок MIME заканчивается и начинается файл GIF.
тип MIME– многоцелевое расширение почтового стандарта Интернета – определяет протокол передачи почтовых сообщений, используемых взамен стандартного.
Open(IMAGE,$gif);создается файловая переменная IMAGE, кот. используется для связывания сценария с файлом, указываемый в переменной $gif.
Hie(<Image>){print$_;}– цикл, посылающий все содержимое GIF файла на сервер.
Close(IMAGE); записывается GIF файл по окончании пересылки изображения.
Exit; сценарий завершен.
Средства написания CGI моделей расширения: среды C++Dulder, Delphi, java, PERL, PHP.
Способы запуска модуля:
задание URL адреса модуля CGI в строке адреса обозревателя
выбор пользователем ссылки, атрибут “ACTION” содержит URL адрес
Переменные окружения.
Переменные окружения используются в CGI модуле для получения от WEB сервера, параметрах HTTP запроса и др. информации. Например, если используется метод GET, то в QUERY-STRING помещаются передаваемые данные пользователем. Если POST в переменных окружения CONTENT_TYPE и CONTENT_LENGTH содержится тип и длина передаваемой информации соответственно, сами данные передаются через стандартный входной поток.
Пример других переменных окружения.
SERVER_NAME –символическое имя или адрес, на кот. запущен WEB сервер (задается URL при обращении к этому серверу).
SERVER_SOFTWARE– название и версия WEB сервера, разделенный символом «/».
GATEWAY_INTERFACE– версия CGI интерфейса.
SERVER_PROTOCOL– название и версия протокола передачи данных, используемого на сервере, разделенный символом «/».
REMOTE_ADDRESS– IP адрес клиента.
REMOTE_HOST– символическое имя удаленной машины, с кот. произведен запрос.
Недостатки и достоинства использования cgi модулей.
Недостатки
В случае параллельной обработки нескольких запросов сервер запускает отдельный процесс для обработки каждого запроса это приводит к повышению загрузки WEB сервера.
При увеличении исполняемого CGI модуля сильно увеличивается время отклика сервера на запрос обозревателя (требуется время для загрузки модуля с диска в памяти) это приводит к невысокой скорости обработки запросов.
Достоинство: Надежность.
Интерфейс Win cgi(реализация интерфейсаCgi для осWindows 3.1).
Сервер передает данные Win CGI программ через INI файл Windows в формате «параметр-значение». Программа Win CGI читает этот файл и получает все данные, передаваемые ей из формы обозревателем. Выходной поток данных перенаправляется модулем в спец.файл.
INI файл Windows состоит из нескольких специальных секций, в кот. находятся различные параметры в виде текстовых строк.
Обозреватель автоматически заполняет INI файл информацией о:
Типе доступа
Составных элементах URL–запроса, с помощью кот. WINCGI был загружен, включая параметры запроса– сами данные.
Сервер добавляет:
Информацию о сервере
Путь к файлу, в кот. помещаются данные после выполнения модуля и кот. сервер использует для формирования HTML документа
Интерфейс isapi/insapi.
ISAPI/INSAPI разработаны соответственно фирмами Microsoft и Netscape. Более перспективный интерфейс для разработки модулей.
Модули расширения реализуются в виде DLL библиотеки.
Загрузка Isapi модулей расширения осуществляется также как и CGI модулей.
Обмен информацией между серверами и модулем расширения осуществляется с помощью специальных объектов:
Request – с его помощью сервер передает параметры запроса модулю расширения.
Response – с его помощью сервер получает сформированный ЦУи документ.
Достоинства и недостатки использования ISAPI – модулей.
Запуск ISAPI–модуля
выполняется сервером в ответ на первый
запрос обозревателя. При обработке
последующих запросов к ISAPI модулю сервер
использует уже загруженный экземпляр
динамической библиотеки
![]() экономия ресурсов сервера и увеличение
скорости обработки запросов.
экономия ресурсов сервера и увеличение
скорости обработки запросов.
Недостаток: разработчик должен соблюдать особые меры по обеспечению устойчивости модуля к сбоям. При возникновении ошибки ISAPI модуля может произойти аварийное завершение всего WEB сервера (для CGI модуля будет завершен только процесс).
Isapi фильтры.
Фильтры ISAPI являются программами, кот. вызываются при получении сервером запроса HTTP.
Отличие фильтров от модулей заключается в том, что они запускаются в ответ на события сервера, а не по запросу обозревателя.
Фильтр ISAPI может быть связан с конкретным событием сервера и вызывается при каждом возникновении такого события. Например, фильтр может получать уведомление о каждом событии чтения или записи и информировать данные, возвращаемые клиенту.
ISAPI фильтры позволяют осуществлять сбор статистической информации об использовании ресурсов сервера и т.д. если сервер на запрос HTTP генерирует событие, для которой зарегистрирован фильтр, то фильтр будет получать содержащиеся в запросе данные вне зависимости от того, адресован ли запрос к файлу CGI модулю или ISAPI модулю.
Архитектура WEB приложения, использующего банк данных.
Рассмотрим простой источник б/д без СУБД:

Способы публикации б/д
Статическая публикация: подготовка Web-страниц, содержащей информацию из б/д, осуществляется с помощью обычных приложений. Эти Web-страницы формируются и хранятся на сервере задолго до доступления запроса пользователя на их получение.
Динамич. Публикация- Web-страницы создаются после получения запроса пользователя на Web-сервере. Поступивший запрос Web-сервер программе расширению, которая формирует требуемый документ, и затем Web-сервер отсылает его обратно обозревателю.
Доступ к может осуществляться разл. Способами и на основе разл. технологий. Если технология ASP-страниц, то применяется несколько уровней интерфейсов. Объектная модель ADO, объектный интерфейс-OLE-DB, интерфейс ODBC. Из модуля ISA PI, разработанного в среде DELPHI, для доступа к б/д может использоваться один посредник- драйвер BDE, входящий в стандарт модулей расширения сервера.
Технологоя работы Web-приложения, использующего б/д.
Обозреватель отсылает URL-адр. главной страницы Web-приложения Web-сверху.
Обработав URL запроса, Web-сервер высылает главную страницу приложения Web-обозревателю в формате HTML.
После того, как пользователь выбрал ссылку, обозреватель отсылает URL Web-серверу.
Для обработки запроса сервер вызывает требуемый модуль расширения и передает ему параметры URL-запроса.
Модуль расширения сервера формирует SQL- запрос к б/д. Выполняется SQL- запрос.
Результаты выполнения SQL- запроса передаются модулю расширения Web-сервера для формирования HTML-страницы(при этом используются различные HTML-страницы).
HTML-страница передает Web-обозревателю.
Недостатки 2-ухуровневых Web-приложений.
Повышается нагрузка на Web-сервер
-обработка URL-запросов,
-извлечение информации из б/д,
-обработка инф-ции для формирования HTML-страниц
Вся эта работа выполняется сервером и его модулями расширения.
Низкий уровень безопасности
-невозможно обеспечить требуемый уровень защиты инф-ции в б/д от сбоев во время обращения к б/д из модуля расширения сервера.