

Организация баз данных с помощью хеширования. Влияние на эффективность хеширования размеров блока, плотности заполнения и выбора алгоритма хеширования.
В данном методе ключ поиска преобразуется в псевдослучайное число, которое используется для определения адреса записи. Алгоритм преобразования числового значения ключа в номер блока для размещения записи называется функцией хеширования. Непосредственный адрес находится путем просмотра записей внутри блока.
Суть метод состоит в следующем: непосредственная область размещения данных делится на участки одинаковой длины, называемые слотами. Все слоты нумеруются натуральными числами 1,2. …, k. При внесении записей в БД по ключу записи с помощью функции хеширования вычисляется номер слота, куда надо поместить запись. Если слот еще не заполнен до конца, то запись добавляется в начало свободного участка. Из-за неравномерности значений функции хеширования некоторые участки окажутся заполненными раньше. В этих случаях запись помещается в область переполнения.
При поиске записи по ключу вычисляется номер участка, просматриваются его записи, и в случае отсутствия записи в слоте, ее поиск продолжается в области переполнения.
Рассмотрим основные факторы, влияющие на эффективность перемешивания:
Размер участка записей (слота);
Плотность заполнения;
Алгоритм преобразования ключа в адрес;
Организация работы с областями переполнения;
Размер участка записей
Размер участка записей выбирается таким образом, что он может содержать одну или несколько записей. Алгоритм перемешивания распределяет записи по участкам подобно тому, как рулетка направляет шарики в гнезда. Промоделируем распределение записей по первичным участкам на примере рулетки.
Предположим, что в рулетке находится 100 шариков, которые будут направлены рулеткой в гнезда. Допустим, что можно изменять размер гнезд (размер участков). Установим следующее правило: если шарик, направленный рулеткой попадает в заполненное гнездо, он отправляется в область переполнения.
Пусть первоначально имеется 100 гнезд вместимостью по 1 шарику. После распределения шаров значительное число шаров окажется в области переполнения. Если взять другой крайний случай когда вся область состоит из одного участка размера 100, то ни один шарик не уйдет в область переполнения. Если же, например, имеется 10 участков по 10 шаров, то лишь небольшая часть шаров попадет в область переполнения. Зависимость процента шаров, попадающих в область переполнения, от размера участка показана на рисунке:
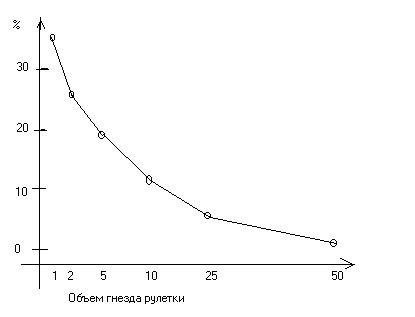
Плотность заполнения.
Число записей, направленных в область переполнения, зависит от плотности заполнения первичных участков. По определению, плотность заполнения равна отношению общего числа записей к размеру области, выделенной под первичные участки. Если размер области равен числу записей, то полученное распределение описывается вышеприведенной зависимостью. Если же, например, объем выделенной области больше объема, занимаемого БД, то число попадающих в область переполнения, значительно уменьшается. Можно рассчитать зависимость объема области переполнения от размера участков и плотности заполнения. Например, если мы хотим, чтобы область переполнения не превышала 1% от общего числа записей, то можно при 70 %-плотности заполнения выбрать размер участков, равных 20 записям.
В тех случаях, когда оптимальное использование памяти более важно, чем скорость доступа, можно увеличить плотность заполнения до 90%.
Основные алгоритмы перемешивания.
Процедура преобразования ключа в адрес обычно выполняется в три этапа:
1. Если ключ – не числовой, то он преобразуется в соответствующее числовое представление таким образом, чтобы исключить потерю информации, содержащейся в ключе. Буквенные символы должны переводится в цифровой код. Можно, например, каждой букве сопоставить 5-битовый код (2^5=32), и кодировать слово, как набор 5-битовых последовательностей.
2. Ключи в цифровом или битовом представлении затем преобразуются в совокупность произвольно распределенных чисел, значения которых имеют тот же порядок, что и значения адресов основной области памяти. Желательно, чтобы набор ключей был распределен как можно равномернее в диапазоне возможных значений.
3. Полученные числа умножаются на константу, что позволяет их вместить в диапазон значений. Например, если после операции 2 мы получим всевозможные 4-значные числа, а число участков равно 7000, то коэффициент выравнивания надо взять равным 0,7, тогда возможные значения адресов первичных участков будут находиться в диапазоне от 0 до 6999.
Ниже мы рассмотрим основные алгоритмы перемешивания.
1. Метод квадратов.
(Числовой) ключ возводится в квадрат. После этого из полученного результата выделяется число, состоящее из центральных цифр. Для получения номера участка достаточно умножить полученное число на выравнивающий коэффициент.
Пример. Число участков n=7000, а значение ключа k=172 148. Квадрат ключа равен – 29 634 933 904. Четыре центральные цифры составляют 3493. Номер участка равен 3493*0,7 =2445