

6. Поиск в сбалансированном дереве.
В большинстве случаев индекс строится в виде многоуровневого дерева. Дерево из трех уровней, представленное на рис.1, является полностью сбалансированным, т.е. заняты все элементы всех узлов. При поиске сначала просматривается узел самого высокого уровня, который ссылается на узлы следующего уровня. Узел второго уровня ссылается на самый нижний уровень. Поиск каждого узла может производиться при помощи, например, блочного поиска.
Древовидная организация индекса, подобная изображенной на рис.1, требует больше памяти, чем одноуровневый индекс, поскольку наибольший (или наименьший) ключ каждого узла повторяется и в узле более высокого уровня. Но поиск в таком дереве может требовать меньшего числа испытаний, чем в большинстве других методов, и при этом сокращается число обращений к внешней памяти. Важно выбрать оптимальное число уровней и оптимальное число элементов в одном узле.
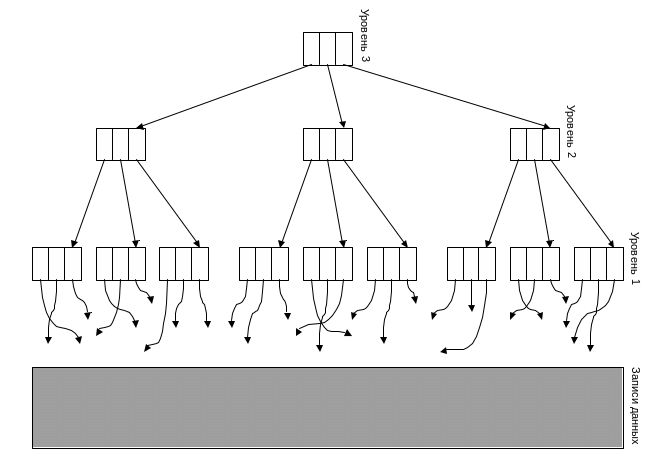
Рис.1. Полностью сбалансированное индексное дерево.
7. Перемешивание.
В данном методе ключ поиска преобразуется в псевдослучайное число, которое используется для определения адреса записи. Алгоритм преобразования значения ключа называется функцией хеширования. Значением функции хеширования является, как правило, не адрес записи, а адрес блока, в котором находится запись. Непосредственный адрес находится путем просмотра записей внутри блока.
Суть метод состоит в следующем: непосредственная область размещения данных делится на участки одинаковой длины, называемые слотами. Все слоты нумеруются натуральными числами 1,2. …, k. При внесении записей в БД по ключу записи с помощью функции хеширования вычисляется номер слота, куда надо поместить запись. Если слот еще не заполнен до конца, то запись добавляется в начало свободного участка. Из-за неравномерности значений функции хеширования некоторые участки окажутся заполненными раньше. В этих случаях запись помещается в область переполнения.
При поиске записи по ключу вычисляется номер участка, просматриваются его записи, и в случае отсутствия записи в слоте, ее поиск продолжается в области переполнения.
8. Комбинация вышеперечисленных способов.
Часто вместо одного из способов, перечисленных выше, используется их комбинация. Например, с помощью индекса определяется ограниченная область поиска, затем эта область просматривается последовательно, либо осуществляется двоичный поиск. С помощью алгоритма прямой адресации можно определить нужный раздел индекса, что избавляет от поиска во всем индексе.
Резюме:
Если для адресации файла используется индекс, компьютер производит поиск в индексе, а не в файле. При этом значительно экономится время, но требуется память для хранения индекса.
Если записи файла упорядочены по ключу, индекс обычно содержит не ссылки на каждую запись, а ссылки на блоки записей, внутри которых можно выполнить поиск или сканирование.
Ссылки на блоки записей, а не на отдельные записи в значительной степени уменьшают размер индекса. Но и в этом случае индекс может оказаться слишком большим для поиска и поэтому используется индекс индекса. В больших файлах может быть больше двух уровней индекса.
Для ускорения поиска сегменты нижнего уровня индекса могут находиться среди записей данных, на которые они указывают. Например, в файле на диске обычно имеется индекс дорожек на каждом цилиндре, содержащий ссылки на записи, хранящиеся на этом цилиндре.
Индексно – последовательные файлы представляют собой наиболее распространенный вид адресации файлов.
Произвольный (непоследовательный) файл можно индексировать точно так же, как и последовательный файл. Но при этом требуется индекс больших размеров, так как он должен содержать по одному элементу для каждой записи файла, а не для блока записей. В нем должны содержаться полные действительные (или относительные) адреса, в то время как в индексе последовательного файла адреса могут содержаться в усеченном виде, так как старшие знаки последовательных адресов будут совпадать.
Индексно – последовательный файл более экономичен, чем произвольный в отношении размера индекса и в отношении времени для поиска в нем. Произвольные файлы в основном используются для обеспечения возможности адресации записей файла с несколькими ключами.
Краткий обзор способов адресации файлов
Способ |
Замечания |
Последовательное сканирование |
Пригоден только при пакетной обработке последовательного файла. |
Блочный поиск |
Рекомендуется только для поиска в индексе |
Двоичный поиск |
Не рекомендуется, если требуется значительное время на перемещение механизма доступа. |
Индексно-последо-вательный файл |
Наиболее распространенный метод. Достоинства: эффективное использование памяти, записи расположены в порядке возрастания или убывания ключа; удобен для пакетной обработки. Недостатки: требуются особые методы для включения и удаления записей, неэффективен при включении больших групп записей. |
Индексно-произвольный файл |
Включение записей осуществляется просто. Физическая последовательность может определяться различными факторами, например, оптимизацией времени доступа. Полезен для адресации записей с несколькими ключами. |
Ключ эквивалент-ный адресу |
Малая гибкость. Ограниченная область применения. |
Перемешивание |
Полезный и эффективный способ. Обеспечивает более быстрый поиск, чем индексирование; операции включения и удаления записей осуществляются легко. Менее эффективное, чем при индексировании использование памяти. Метод неэффективен при пакетной обработке данных. |
$8. Индексно-произвольная и индексно-последовательная организация данных. Организация областей переполнений.
Рассмотрим методы индексно-произвольной и индексно-последовательной организации более подробно. При работе с файлами используют два основных вида обработки: последовательная обработка, при которой записи обрабатываются в последовательности их размещения на запоминающем устройстве; произвольная обработка, при которой записи обрабатываются в произвольной последовательности. В зависимости от того, какой режим работы преобладает выбирают способ организации данных. Если записи неупорядочены, то можно добавлять записи, не заботясь о сохранении порядка. Однако, индексные файла в этом случае содержат ссылки на каждую запись данных, и размер индекса существенно больше, чем в случае последовательной организации. При последовательном расположении данных больше времени тратится на операцию включения новых записей. Эта операция становится более эффективной, если файл данных заполняется с пропусками, предназначенными для будущего включения новых записей. Метод, основанный на включении пропусков в файл данных, называется методом распределенной свободной памяти. Хотя применение этого метода позволяет избежать записей переполнения, необходимо время о времени производить операции реорганизации файла с целью восстановления резервных позиций.
Другой способ обработки новых записей основан на выделении специальной области, называемой областью переполнения. Новая запись помещается в эту область, а в основной области помещается ссылка а ее адрес. Если включается группа новых записей, то они упорядочиваются в линейную цепь (кольцо), в которой каждая запись содержит ссылку на последующую, а последняя запись не содержит ссылки, либо содержит ссылку на первый элемент (голову) списка. При поиске записи сначала производится поиск в основной области, а затем поиск в области переполнения по цепочке указателей. Такой метод называется методом выделенной области переполнения.