

5.2Преобразование данных.
Преобразование данных - процесс тесно связанный с организацией вычислительного процесса. Для того, чтобы на выходе получить информационный продукт удовлетворяющий предъявляемым к нему требованиям, исходные данные проходят достаточно сложный путь. Он состоит в основном из достаточно типовых операций над значениями и структурой данных (арифметические операции, преобразование типов данных, логические операции и т.д.). Последовательность и характер выполняемых действий определяется алгоритмом решения задачи, реализованным в случае ЭВМ в виде компьютерной программы или комплекса программ, которые переводятся в машинный код с помощью специальных программ посредников - трансляторов. На физическом уровне за преобразование данных отвечает аппаратный комплекс ЭВМ (процессоры, накопители данных и т.д.).
В случае решения достаточно сложных задач типа задач управления технологическим процессом большую роль в процессе преобразования данных играет оптимизация вычислительных потоков. Управление процедурой преобразования данных сводится в основном к двум задачам: задаче оптимизации вычислительных процессов и исключению повтора одних и тех же действий. Задача оптимизации процесса преобразования данных во многом может быть формализована.
Один из наиболее глубоких подходов к этому вопросу был предложен в 60-х годах 20 века академиком Колмогоровым А.Н.. В отношении алгоритмических задач этот подход основывается на том, что сложность алгоритма определяется количеством используемых в нем переменных и количеством составляющих его операций. Оптимальным считается тот из алгоритмов решения задачи, который имеет наименьшее количество операций и переменных. Относительно компьютерных задач, об оптимальности вычислительных потоков косвенно можно судить по времени решения задачи или по интенсивности использования вычислительных ресурсов. Этот подход можно проиллюстрировать на примере простой задачи. Необходимо найти максимальное из трех чисел М=max(A,B,C). На рисунке 10 приведены блок-схемы трех вариантов решения данной задачи.
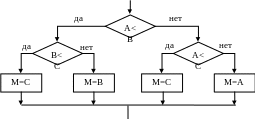
а)
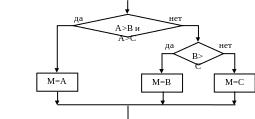
б)
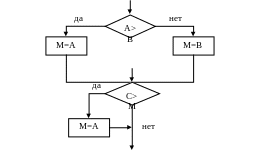
в)
Рисунок 10 Блок схема решения задачи нахождения максимального из трех чисел.
Определим теперь, какой из алгоритмов является оптимальным. В таблице 1 представлены результаты оценки всех трех алгоритмов. Сложив количество минимально и максимально возможного числа операций по каждому алгоритму получим, что минимальное число операций возможно при использовании алгоритма а, который и следует признать оптимальным.
Таблица 1 Количество операций при использовании алгоритмов решения задачи нахождения максимального из трех чисел.
Алгоритм |
Минимальное количество операций |
Максимальное количество операций |
а |
2 сравнения + 1 присваивания |
2 сравнения + 1 присваивания |
б |
2 сравнения + 1 присваивания |
3 сравнения + 1 присваивания |
в |
2 сравнения + 1 присваивания |
2 сравнения + 2 присваивания |
5.3Нетрадиционная обработка данных.
Достаточно часто для оптимизации процесса обработки данных выгодно организовать его нетипичным образом. Чаще всего используют два нетрадиционных подхода к обработке данных: параллельную обработку и конвейерную обработку.
Наиболее эффективно параллельная схема обработки данных может быть реализована в многопроцессорной системе для решения задач, в которых существуют параллельность. Под параллельными понимаются вычислительные задачи, где входные данные одного процесса не должны модифицироваться другим процессом и никакие два процесса не модифицируют общие переменные. В случае наличия в алгоритме задачи параллельных процессов использование параллельной схемы вычисления может привести к значительному сокращению времени ее выполнения.
Конвейерная обработка называется так по аналогии со сборочным конвейером в автомобилестроении. Там изделие последовательно проходит все стадии сборки от начала до конца. В момент, когда одно изделие проходит какой-либо этап сборки, на его место тут же поступает следующее. Таким образом, на конвейере обрабатывается сразу много изделий.
При конвейерной обработке данных используются те же подходы. Только работа ведется не с материальными объектами, а с информационными. Существует два типа конвейеров. Если на конвейере "собирают" похожие, но не полностью идентичные "информационные изделия", такой конвейер называется последовательным. Если же "изделия" полностью аналогичны одно другому, то речь идет о векторном конвейере. Экономия времени достигается за счет более интенсивного использования ресурсов ЭВМ при выполнении задач, содержащих похожий набор действий.