

6.3.3 Технологии Data Mining
Несмотря на разнообразие бизнес-задач почти все они могут решаться по единой методике. Эта методика, зародившаяся в 1989 г., получила название Knowledge Discovery in Databases (KDD) - извлечение знаний из баз данных. Методика не зависит от предметной области; это набор атомарных операций, комбинируя которые, можно получить нужное решение.
KDD включает в себя этапы (рис.6.15):
подготовки данных,
выбора информативных признаков,
очистки,
построения моделей,
постобработки и интерпретации полученных результатов.
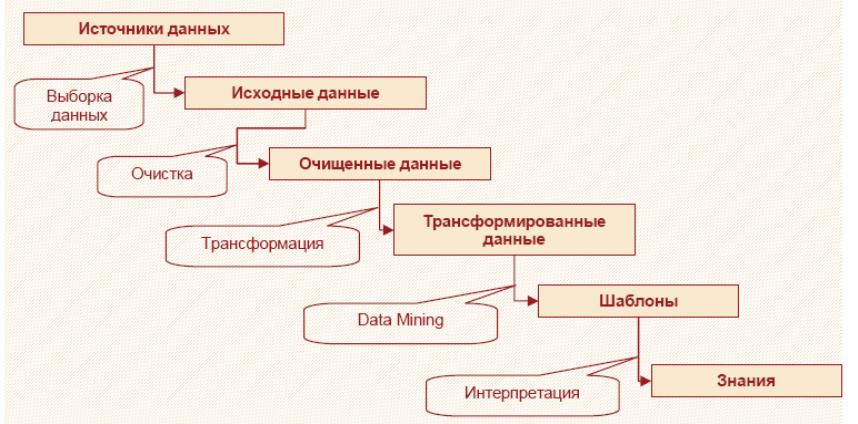
Рис.6.15 – Этапы KDD
Ядром этого процесса являются методы Data Mining, позволяющие обнаруживать закономерности и знания .
Базовые классы Data mining:
Классификация – установление зависимости дискретной выходной переменной – метки класса от входных переменных путем определения класса объекта по его признакам, при этом множество классов, к которым может быть отнесен объект, известно заранее.
Регрессия – это установление зависимости непрерывной выходной переменной от входных переменных, например, прогнозирование временного ряда на основе исторических данных.
Кластеризация – это группировка объектов (наблюдений, событий) на основе данных, описывающих свойства объектов. Число кластеров чаще неизвестно. Объекты внутри кластера должны быть похожими друг на друга и отличаться от других, которые вошли в другие кластеры.
Ассоциация – выявление закономерностей между связанными событиями. Примером такой закономерности служит ассоциативное правило, указывающее, что из события X следует событие Y. Впервые эта задача была предложена для нахождения типичных шаблонов покупок, совершаемых в супермаркетах, поэтому иногда ее называют анализом рыночной корзины (market basket analysis). Если же нас интересует последовательность происходящих событий, то можно говорить о последовательных шаблонах — установлении закономерностей. между связанными во времени событиями. Примером такой закономерности служит правило, указывающее, что из события X спустя время t последует событие Y.
Кроме перечисленных задач, часто выделяют анализ отклонений (deviation detection), анализ связей (link analysis), отбор значимых признаков (feature selection), хотя эти задачи граничат с очисткой и визуализацией данных.
Ввиду того что Data Mining развивается на стыке таких дисциплин, как математика, статистика, теория информации, машинное обучение, теория баз данных, программирование, параллельные вычисления, вполне закономерно, что большинство алгоритмов и методов Data Mining были разработаны на основе подходов, применяемых в этих дисциплинах (рисунок 6.16).
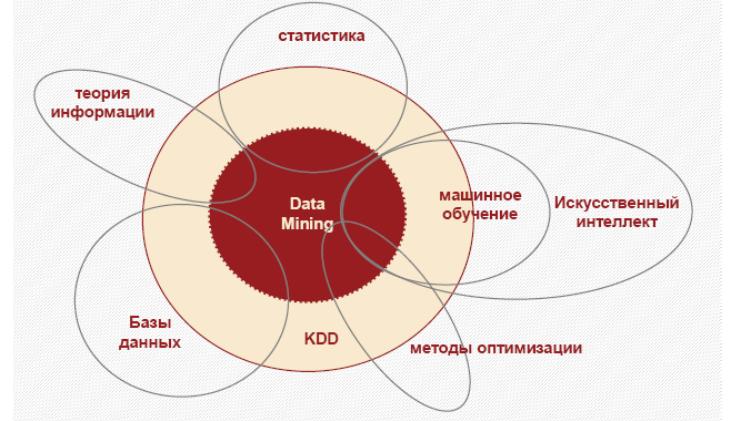 Рис.6.16
– Мультидисциплинарный характер Data
Mining
Рис.6.16
– Мультидисциплинарный характер Data
Mining
К методам и алгоритмам Data Mining относятся следующие: искусственные нейронные сети, деревья решений, символьные правила, методы ближайшего соседа и k-ближайшего соседа, метод опорных векторов, байесовские сети, линейная регрессия, корреляционно-регрессионный анализ; иерархические методы кластерного анализа, неиерархические методы кластерного анализа, в том числе алгоритмы k-средних и k-медианы; методы поиска ассоциативных правил, в том числе алгоритм Apriori; метод ограниченного перебора, эволюционное программирование и генетические алгоритмы, разнообразные методы визуализации данных и множество других методов.
Рисунок 6.17 иллюстрирует некоторые популярные бизнес-задачи, которые решаются алгоритмами Data Mining.
Рынок программного обеспечения KDD и Data Mining делится на несколько сегментов (рис.6.18).
Статистические пакеты с возможностями Data Mining и настольные Data Mining пакеты ориентированы в основном на профессиональных пользователей.
Их отличительные особенности:
слабая интеграция с промышленными источниками данных;
бедные средства очистки, предобработки и трансформации данных;
отсутствие гибких возможностей консолидации информации, например, в специализированном хранилище данных;
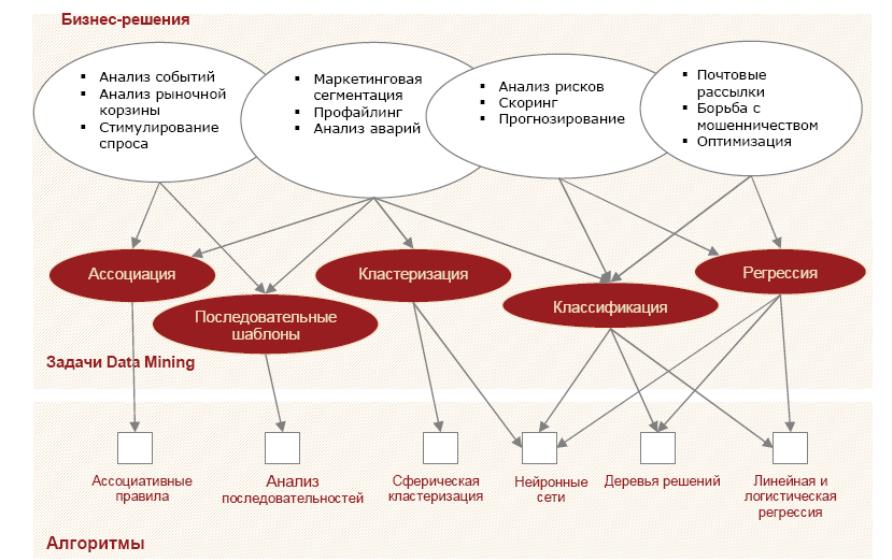
Рис.6.17 – От бизнес-решений к алгоритмам Data Mining
конвейерная (поточная) обработка новых данных затруднительна или реализуется встроенными языками программирования и требует высокой квалификации;
из-за использования пакетов на локальных рабочих станциях обработка больших объемов данных затруднена.
Плюсом статистических пакетов является их широкая распространенность.
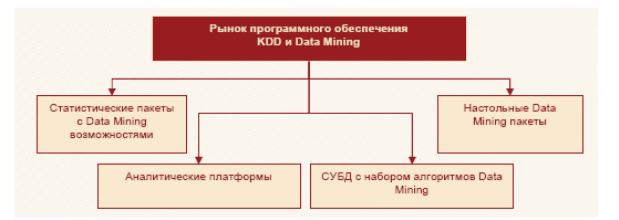
Рис.6.18 – Классификация ПО в области KDD и Data Mining
Настольные Data Mining пакеты могут быть ориентированы на решение всех классов задач Data Mining или какого-либо одного, например кластеризации или классификации. Вместе с тем эти пакеты предоставляют богатые возможности в плане алгоритмов, что достаточно для решения исследовательских задач. Существует немало свободно распространяемых настольных пакетов Data Mining с открытыми исходными кодами.
Однако создание эффективных прикладных решений промышленного уровня с помощью таких пакетов затруднено, поэтому в бизнес-аналитике, как правило, используются СУБД с элементами Data Mining и аналитические платформы.
Практически все крупные производители СУБД включают в состав своих продуктов средства для анализа данных и поддержку хранилищ данных.
Отличительные особенности СУБД с элементами Data Mining:
высокая производительность;
алгоритмы анализа данных по максимуму используют преимущества СУБД;
жесткая привязка всех технологий анализа к одной СУБД;
сложность в создании прикладных решений, поскольку работа с СУБД ориентирована на программистов и администраторов баз данных.
В отличие от СУБД с набором алгоритмов Data Mining, аналитические платформы изначально ориентированы на анализ данных и предназначены для создания готовых решений.
В аналитической платформе, как правило, всегда присутствуют:
гибкие и развитые средства консолидации, включающие богатые механизмы интеграции с промышленными источниками данных;
инструменты очистки и преобразования структурированных данных и их последующее хранение в едином источнике в многомерном виде — в хранилище данных;
модели, описывающие выявленные закономерности, правила и прогнозы, которые также хранятся в специальном источнике данных — репозитарии моделей.
На рисунке 6.19 изображена типовая схема системы на базе аналитической платформы.
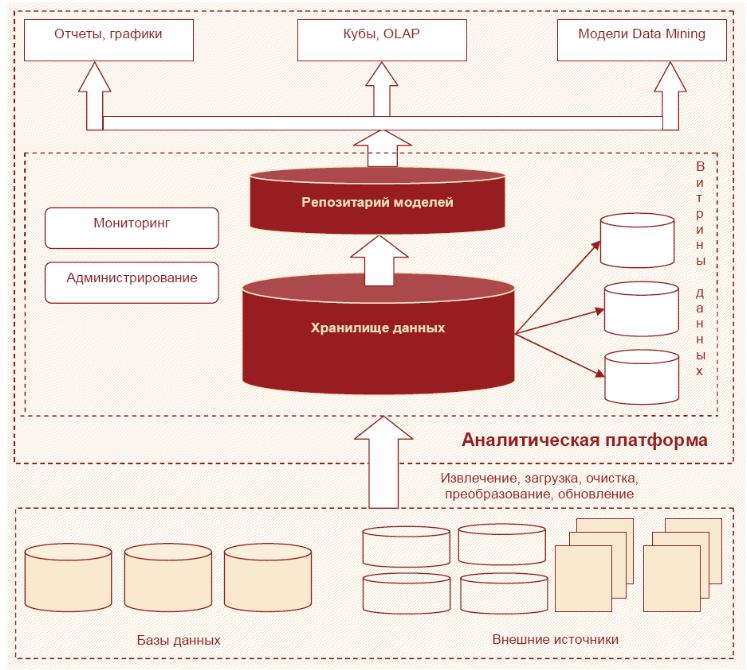
Рис.6.19 – Аналитическая платформа
В процессе консолидации данных решаются следующие задачи (рис.6.20):
выбор источников данных;
разработка стратегии консолидации;
оценка качества данных;
обогащение;
очистка;
перенос в хранилище данных (ХД).
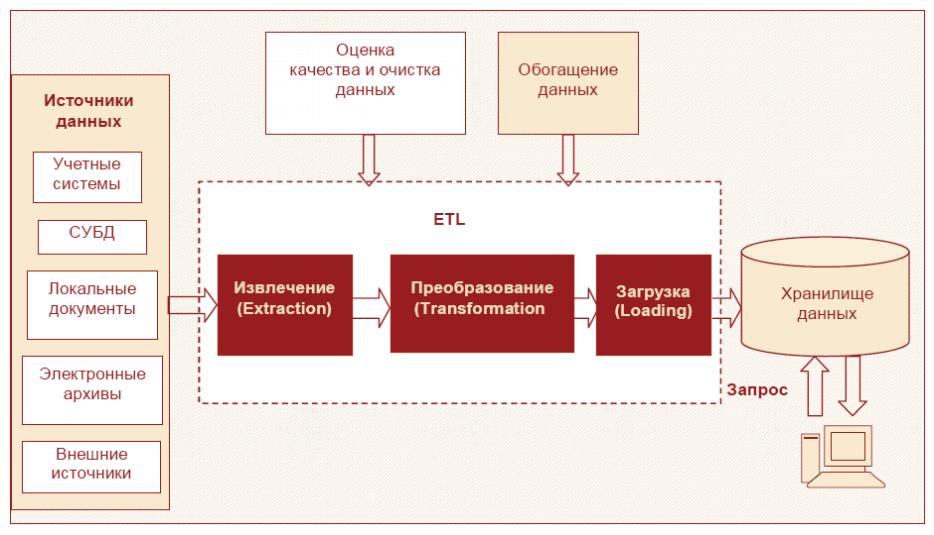
Рис.6.20 – Аналитическая платформа
Сначала осуществляется выбор источников, содержащих данные, которые могут иметь отношение к решаемой задаче, затем определяются тип источников и методика организации доступа к ним.
В связи с этим можно выделить три основных подхода к организации хранения данных:
Данные, хранящиеся в отдельных (локальных) файлах, например в текстовых файлах с разделителями, документах Word, Excel и т. д. Такого рода источником может быть любой файл, данные в котором организованы в виде столбцов и записей. Столбцы должны быть типизированы, то есть содержать данные одного типа, например только текстовые или только числовые. Преимущество таких источников в том, что они могут создаваться и редактироваться с помощью простых и популярных офисных приложений, работа с которыми не требует от персонала специальной подготовки. К недостаткам следует отнести то, что они далеко не всегда оптимальны с точки зрения скорости доступа к ним, компактности представления данных и поддержки их структурной целостности.
Базы данных (БД) различных СУБД, таких как Oracle, SQL Server, Firebird, dBase, FoxPro, Access и т. д. Файлы БД лучше поддерживают целостность структуры данных, поскольку тип и свойства их полей жестко задаются при построении таблиц. Однако для создания и администрирования БД требуются специалисты с более высоким уровнем подготовки, чем для работы с популярными офисными приложениями.
Специализированные хранилища данных (ХД) являются наиболее предпочтительным решением, поскольку их структура и функционирование специально оптимизируются для работы с аналитической платформой. Большинство ХД обеспечивают высокую скорость обмена данными с аналитическими приложениями, автоматически поддерживают целостность и непротиворечивость данных. Главное преимущество ХД перед остальными типами источников данных – наличие семантического слоя, который дает пользователю возможность оперировать терминами предметной области для формирования аналитических запросов к хранилищу.
При разработке стратегии консолидации данных необходимо учитывать характер расположения источников данных – локальный, когда они размещены на том же ПК, что и аналитическое приложение, либо удаленный, если источники доступны только через локальную или глобальную компьютерные сети.
Другой важной задачей, которую требуется решить в рамках консолидации, является оценка качества данных с точки зрения их пригодности для обработки с помощью различных аналитических алгоритмов и методов. Если в процессе оценки качества будут выявлены факторы, которые не позволяют корректно применить к данным те или иные аналитические методы, необходимо выполнить соответствующую очистку данных. Обогащение необходимо применять в тех случаях, когда данные содержат недостаточно информации для удовлетворительного решения определенной задачи анализа. Обогащение данных позволяет повысить их информационную насыщенность и, как следствие, значимость для решения аналитической задачи.
В основе процедуры консолидации лежит процесс ETL (extraction, transformation, loading). Процесс ETL решает задачи извлечения данных из разнотипных источников, их преобразования к виду, пригодному для хранения в определенной структуре, а также загрузки в соответствующую базу или хранилище данных.
Основные критерии оптимальности с точки зрения консолидации данных:
обеспечение высокой скорости доступа к данным;
компактность хранения;
автоматическая поддержка целостности структуры данных;
контроль непротиворечивости данных.