

14)Суть мнк для построения множественного линейного уравнения регрессии.
Самым распространенным методом оценки параметров уравнения множественной линейной регрессии является метод наименьших квадратов (МНК). Напомним, что его суть состоит в минимизации суммы квадратов отклонений наблюдаемых значений зависимой переменной Уj от ее значений У, получаемых по уравнению регрессии.
Для отражения того факта, что реальные значения зависимой переменной не всегда совпадают с ее условными математическими ожиданиями и могут быть различными при одном и том же значении объясняющей переменной (наборе объясняющих переменных), фактическая зависимость должна быть дополнена некоторым слагаемым, которое, по существу, является СВ и указывает на стохастическую суть зависимости. Из этого следует, что связи между зависимой и объясняющей(ими) переменными выражаются соотношениями
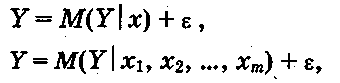
(4.4)
называемыми регрессионными моделями (уравнениями).
15)Статистическая значимость коэффициентов регрессии.
Как и в случае парной регрессии, статистическая значимость коэффициентов множественной линейной регрессии с т объясняющими переменными проверяется на основе t-статистики:
![]() (6.33)
(6.33)
имеющей
в данной ситуации распределение Стьюдента
с числом степеней
свободы
=
n
— m—
1
(n
— объем выборки). При требуемом
уровне значимости наблюдаемое значение
![]() -статистики
сравнивается
с критической точкой
-статистики
сравнивается
с критической точкой
![]() распределения Стьюдента.
распределения Стьюдента.
Если
![]() ,
то коэффициент
,
то коэффициент
![]() считается
статистически
значимым.
считается
статистически
значимым.
В
противном случае (![]() )
коэффициент
считается статистически
незначимым (статистически близким к
нулю). Это
означает, что фактор Xj
линейно
не связан с зависимой переменной У.
Его наличие среди объясняющих переменных
не оправдано
со статистической точки зрения. Не
оказывая сколь-нибудь
серьезного влияния на зависимую
переменную, он лишь искажает
реальную картину взаимосвязи. Поэтому
после установления
того факта, что коэффициент
статистически незначим,
рекомендуется исключить из уравнения
регрессии переменную
Xj.
Это
не приведет к существенной потере
качества модели,
но сделает ее более конкретной.
)
коэффициент
считается статистически
незначимым (статистически близким к
нулю). Это
означает, что фактор Xj
линейно
не связан с зависимой переменной У.
Его наличие среди объясняющих переменных
не оправдано
со статистической точки зрения. Не
оказывая сколь-нибудь
серьезного влияния на зависимую
переменную, он лишь искажает
реальную картину взаимосвязи. Поэтому
после установления
того факта, что коэффициент
статистически незначим,
рекомендуется исключить из уравнения
регрессии переменную
Xj.
Это
не приведет к существенной потере
качества модели,
но сделает ее более конкретной.
Зачастую строгая проверка значимости коэффициентов заменяется простым сравнительным анализом.
Если
![]() (
(
![]() )то
коэффициент статистически незначим.
)то
коэффициент статистически незначим.
Если
![]() то
коэффициент относительно значим. В
данном случае рекомендуется воспользоваться
таблицей
критических точек распределения
Стьюдента (приложение
2).
то
коэффициент относительно значим. В
данном случае рекомендуется воспользоваться
таблицей
критических точек распределения
Стьюдента (приложение
2).
Если
2 <
![]()
![]() 3, то коэффициент значим. Это утверждение
является
гарантированным при
3, то коэффициент значим. Это утверждение
является
гарантированным при
>
20 и
![]() > 0,05 (приложение 2).
> 0,05 (приложение 2).
Если
![]() ,
то коэффициент считается сильно значимым.
Вероятность
ошибки в данном случае при достаточном
числе наблюдений
не превосходит 0,001.
,
то коэффициент считается сильно значимым.
Вероятность
ошибки в данном случае при достаточном
числе наблюдений
не превосходит 0,001.
16)Интервальные оценки коэффициентов регрессии
По
аналогии с парной регрессией после
определения
точечных оценок
коэффициентов
![]() -
(j
=0,1,…,m)
теоретического
уравнения регрессии могут быть рассчитаны
интервальные
оценки указанных коэффициентов. Для
построения интервальной
оценки коэффициента
строится
-статистика
-
(j
=0,1,…,m)
теоретического
уравнения регрессии могут быть рассчитаны
интервальные
оценки указанных коэффициентов. Для
построения интервальной
оценки коэффициента
строится
-статистика
![]() (6.26)
(6.26)
имеющая распределение Стюдента с числом степеней свободы v= n — т — 1 (n— объем выборки, т - количество объясняющих переменных в модели)
Пусть необходимо построить 100(1 — )%-й доверительный интервал для коэффициента Тогда по таблице критических точек распределения Стьюдента по требуемому уровню значимости а и числу степеней свободы находят критическую точку Удовлетворяющую условию
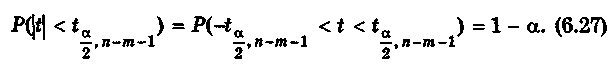
Подставляя (6.26) в (6.27), получаем
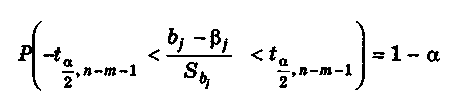
или после преобразования
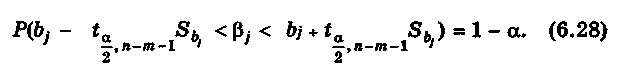
Напомним,
что
![]() рассчитывается
по формуле
рассчитывается
по формуле
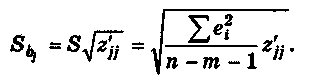
Таким образом, доверительный интервал, накрывающий с надежностью (1 – ) неизвестное значение параметра , определяется неравенством

Отметим, что по аналогии с парной регрессией (может быть построена интервальная оценки для среднего значения предсказания:
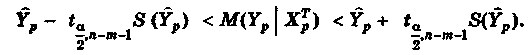
В матричной форме это неравенство имеет вид:
