

Метод найменших квадратів
Графічно цю задачу можна представити так – у полі розсіювання ( xi, yi) площини хоу необхідно провести пряму так, щоб величина всіх відхилень відповідна умові :
 (9)
(9)
Тому цей метод регресійного аналізу називається методом найменших квадратів (МНК).
Для знаходження коефіцієнтів залежності (8), необхідно знайти часткові похідні по b0 та b1 від функції (9) і прирівняти їх до нуля
 (10)
(10)
Після простих перетворень отримаємо систему нормальних рівнянь:
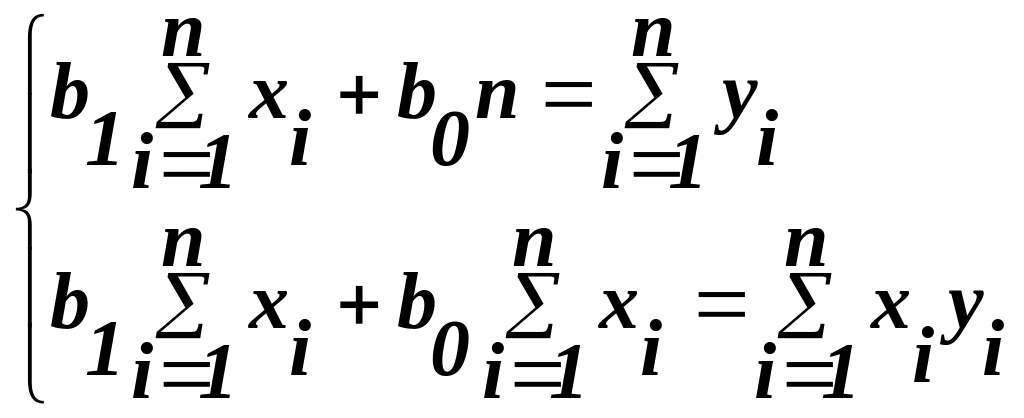
(11)
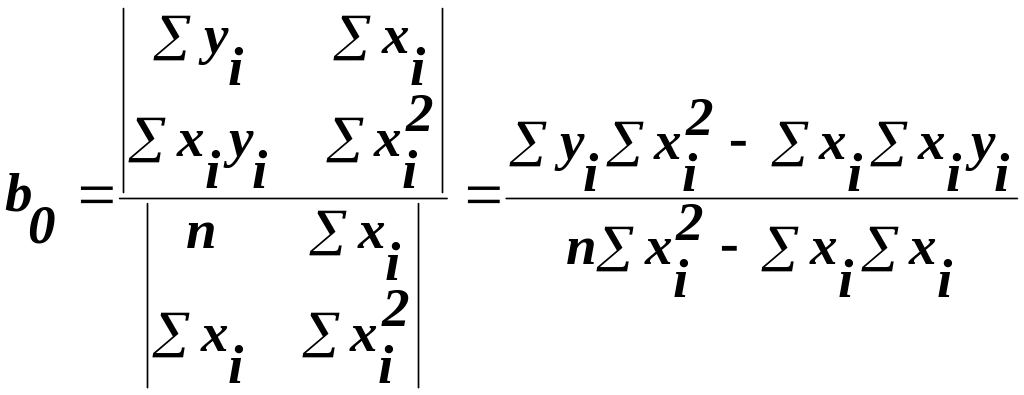 (12)
(12)
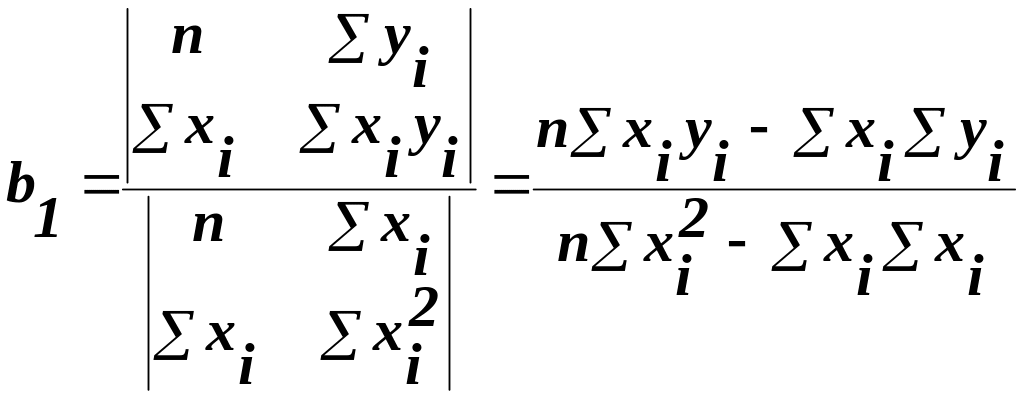 (13)
(13)
Визначивши b0 та b1, можна по (8) обчислити значення регресії для заданої області пояснювальної змінної х.
Зауваження. На практиці коефіцієнти b0 та b1 частіше знаходять з використанням коефіцієнтів кореляції та коваріації.
(1.2.) Алгоритм ручного рахунку:
1) знаходимо середні значення масивів Х та У:
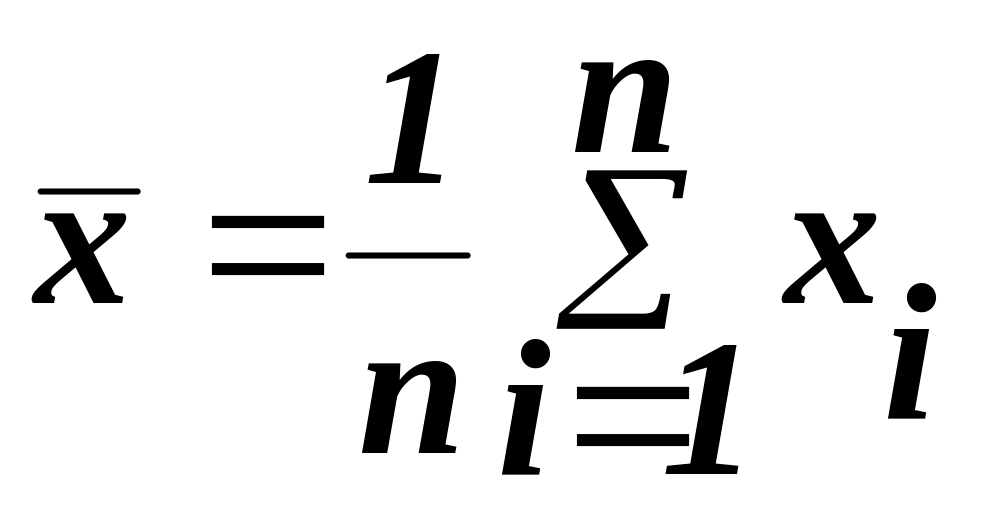 ,
,
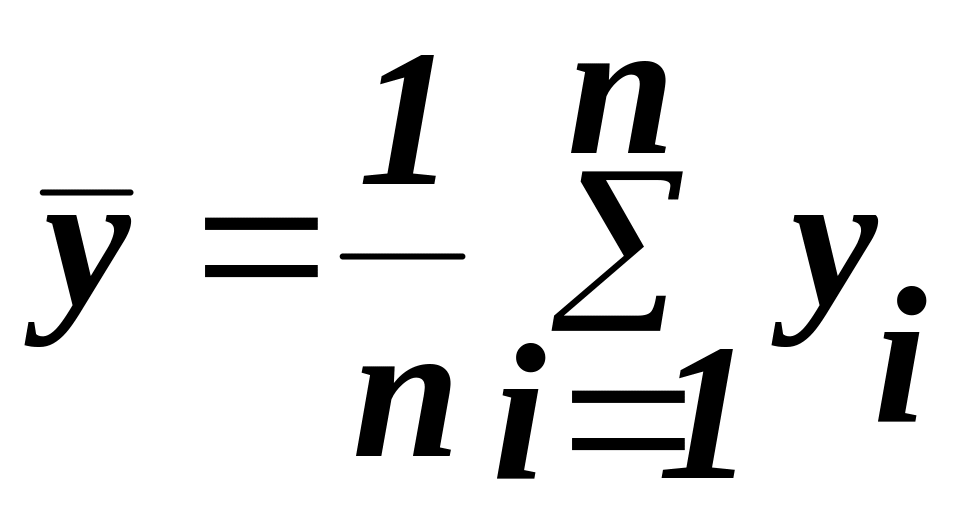 (14)
(14)
2) знаходимо вибіркові відхилення:
 ,
,
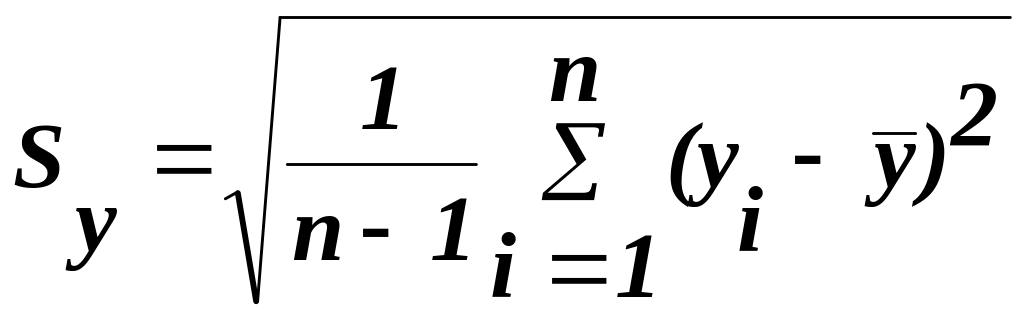 (15)
(15)
3) знаходимо коефіцієнт коваріації:
 (16)
(16)
4) знаходимо коефіцієнт кореляції:
 (17)
(17)
5) знаходимо коефіцієнт рівняння регресії:
![]()
![]() (18)
(18)
6) знаходимо теоретичні значення змінної У:
![]() (19)
(19)
7)
знаходимо
середнє відхилення, смугу відхилення
та інтервал довір’я:
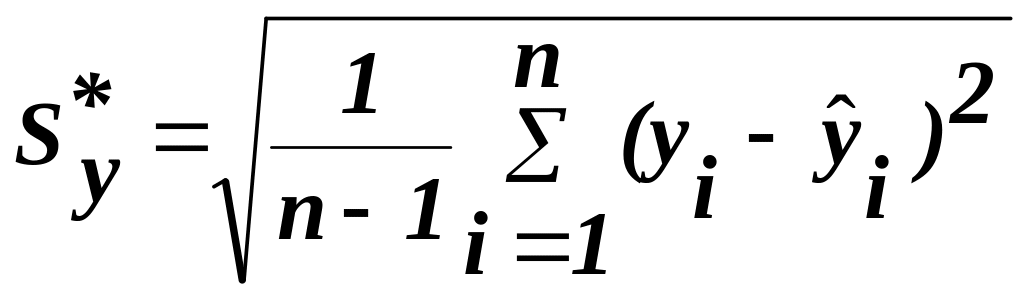 (20)
(20)
![]() - смуга;
- смуга; ![]() (21)
(21)
(1.3.) Лінеаризації у випадку криволінійних залежностей
На практиці дуже часто зв’язок між двома параметрами носить нелінійний(криволінійний) характер. У більшості випадків за допомогою простих перетворень можна нелінійну залежність до лінійної, тобто провести лінеаризацію.
(1.4.) Визначення параметрів парної лінійної регресії для згрупованих даних
Для кореляційної таблиці, яку розглянули раніше, мають місце наступні співвідношення:
![]()
![]() (23)
(23)
![]()
![]() (24)
(24)
Середні
значення
![]() та
та
![]() визначаються, як середні зважені за
серединами інтервалів:
визначаються, як середні зважені за
серединами інтервалів:
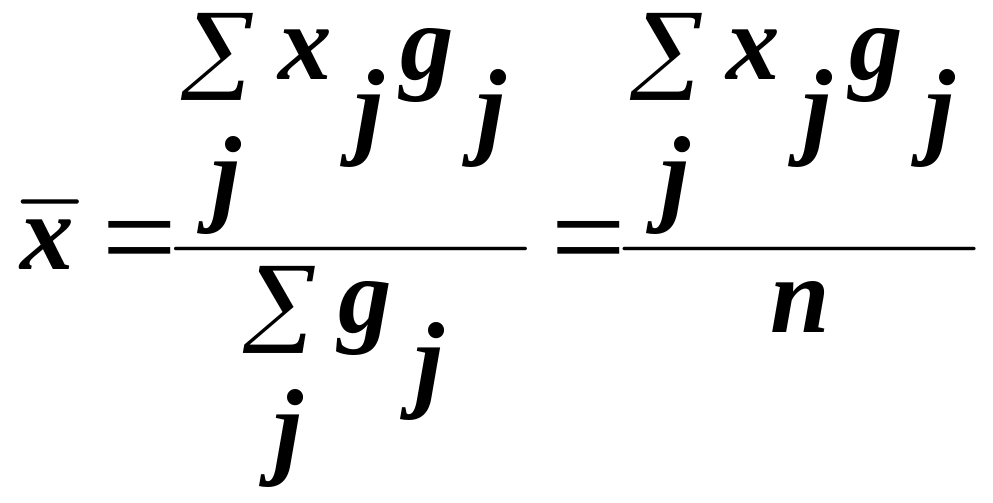 (25)
(25)
 (26)
(26)
Шляхом заміни в (12) і (13) окремих значень хі та уі серединами інтервалів, що зважені за відповідними частотами, отримаємо формули для обчислення оцінок параметрів за згрупованими дуними:
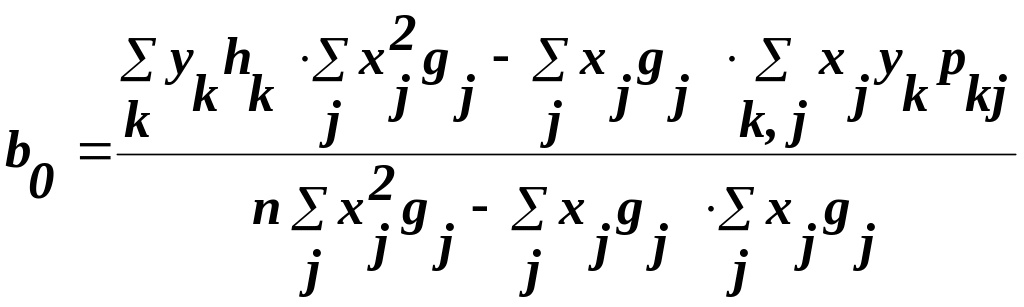 (27)
(27)
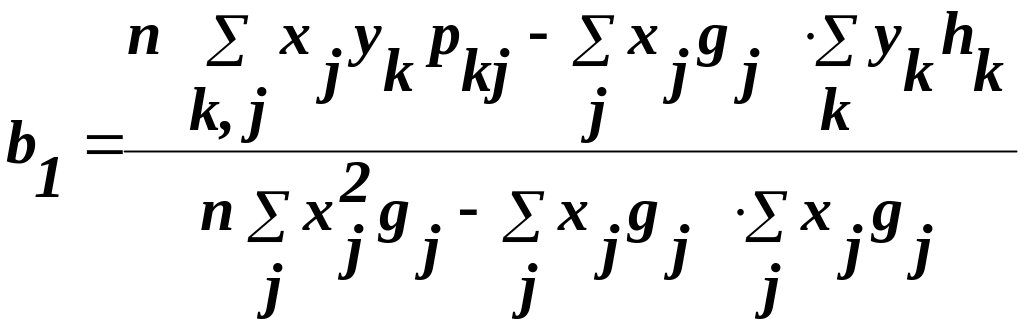 (28)
(28)
Множинна лінійна регресія
При існуванні лінійного співвідношення між змінними, загальний вираз рівняння множинної регресії (1) записується у вигляді:
![]() (29)
(29)
Підставляючи (34) в (30) маємо:
![]()
або (35)
![]()
З системи нормальних рівняннь отримуємо b0 та b1:
 (36)
(36)
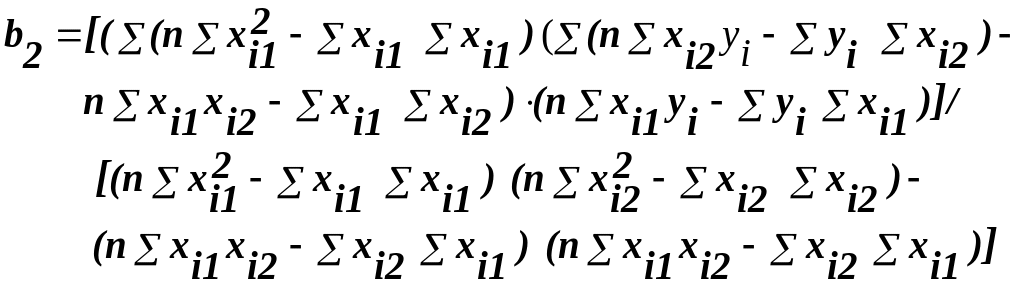 (37)
(37)
Загальна процедура проведення регресійного аналізу включає в себе наступні етапи:
Формулювання економічної проблеми.
На даному етапі формулюються гіпотези про залежність економічних явищ. Потім залежність кількісно оцінюється за допомогою методів регресійного аналізу, а саме яку форму і який вид може дана залежність.
Ідентифікація змінних.
Визначають найбільш оптимальну кількість змінних, і класифікують їх на залежні і пояснювальні змінні.
Збір статичних даних.
Приймається рішення про проведення досліджень за всією генеральною сукупністю чи за її вибіркою. Після цього приступають до збору даних для кожної змінної, включеної в аналіз.
Специфікація функції регресії.
На цьому етапі дослідження, висувається конкретна гіпотеза про форму зв’язку.
Оцінка функції регресії.
Визначаються числові значення параметрів регресії. Крім того, обчислюється ряд статичних показників, що характеризують точність регресійного аналізу.
Оцінка точності регресійного аналізу.
На цьому етапі повинні бути зроблені висновки про точність результатів.
Економічна інтерпретація.
Результати регресійного аналізу порівнюються з гіпотезами, що були сформульовані на першому етапі дослідження, і оцінюється їх правдоподібність з економічної точки зору.
Передбачення невідомих значень залежної змінної(прогноз).
Прогноз отримують шляхом підстановки в регресій не рівняння, з чисельно оціненими параметрами, значень пояснювальної змінної.
Перевірка лінійної регресії.
Позначимо
через
![]() частинне середнє, що відповідає j-тому
значенню пояснювальної змінної:
частинне середнє, що відповідає j-тому
значенню пояснювальної змінної:
 (47)
(47)
де
![]() - число значень y,
що відносяться до xjk
(
- число значень y,
що відносяться до xjk
(![]() );
);
![]() .
Знайдемо тепер середній квадрат відхилень
yij
від їх частинних середніх.
.
Знайдемо тепер середній квадрат відхилень
yij
від їх частинних середніх.
 (48)
(48)
Показник (48) є мірою розсіювання дослідних даних навколо своїх частинних середніх, тобто мірою, що не залежить від вибраного вигляду регресії. В якості міри розсіювання дослідних даних навколо емпіричної регресійної прямої вибирається середній квадрат відхилень:
 (49)
(49)
Обидва
показники
![]() є незалежними статистичними оцінками
однієї і тієї ж дисперсії
є незалежними статистичними оцінками
однієї і тієї ж дисперсії
![]() .
Якщо
.
Якщо
![]() не набагато більше
не набагато більше
![]() ,
то в якості гіпотетичної залежності
може бути взята лінійна.
,
то в якості гіпотетичної залежності
може бути взята лінійна.
Якщо в генеральній сукупності існує лінійна регресія і умовні розподіли змінної y хоч би приблизно нормальні, то відношення середній квадратів
 (50)
(50)
має
F
розподіл з
![]() і
і
![]() степенями вільності.
степенями вільності.
Значення
F
пораховане за формулою (50) порівняне з
критичним
![]() знайденим за таблицею F-розподілу
при заданому рівні значущості
знайденим за таблицею F-розподілу
при заданому рівні значущості
![]() і
і
![]() степенями вільності. Якщо
степенями вільності. Якщо
![]() ,
то різниця між обома середніми квадратами
відхилень статистично незначна і вибрана
нами лінійна регресійна залежність
може бути прийнята, як правдоподібна і
як таке, що не протиречить дослідним
даним.
,
то різниця між обома середніми квадратами
відхилень статистично незначна і вибрана
нами лінійна регресійна залежність
може бути прийнята, як правдоподібна і
як таке, що не протиречить дослідним
даним.
Якщо
![]() ,
то різниця між обома середніми квадратами
відхилень суттєві і гіпотезу про лінійну
залежність між змінними прийняти не
можна. Існує інші критерії перевірки
гіпотези про лінійність регресії.
,
то різниця між обома середніми квадратами
відхилень суттєві і гіпотезу про лінійну
залежність між змінними прийняти не
можна. Існує інші критерії перевірки
гіпотези про лінійність регресії.
Розв’язок задач у випадку порушення класичних припущень(мультиколінеарність)
При вивченні матричної лінійної регресії часто зустрічаються з наявністю лінійного зв’язку між всіма чи деякими пояснювальними змінними. Це явище називається мультиколінеарністю.
Для вимірювання стохастичної мультиколінеарності можна використати коефіцієнт множинної детермінації. При відсутності кореляції між пояснювальними змінними, тобто при відсутності мультиколінеарності, коефіцієнт множинної детермінації дорівнює сумі відповідних коефіцієнтів парної детермінації:
![]() (51)
(51)
При наявності мультиколінеарності співвідношення (1) не виконується. Тому в якості міри мультиколінеарності можна запропонувати різницю:
![]() (52)
(52)
Чим менша ця різниця, тим менша мультиколінеарність.
Інший показник розроблений А.Е.Хорлом. Він базується на використанні для вимірювання мультиколінеарності чисельника формули коефіцієнта множинної детермінації. А саме, що його можна представити наступним чином:
![]()
для
![]() ,
,
![]() (53)
(53)
Вираз
![]() (54)
(54)
є
чисельником
формули
коефіцієнта парної кореляції між
змінними
![]() та
та
![]() .
При відсутності колінеарності загального
показника мультиколінеарності можна
використовувати різницю М2:
.
При відсутності колінеарності загального
показника мультиколінеарності можна
використовувати різницю М2:
![]() (55)
(55)
Також в якості показника мультиколінеарності можна також використати вираз (52), розділивши його на
 (56)
(56)
Чим більше М3, тим інтенсивніша мультиколінеарність.
Відомий показник мультиколінеарності, отримують з формули (5). Розділивши праву і ліву частини формули на
 ,
отримаємо:
,
отримаємо:
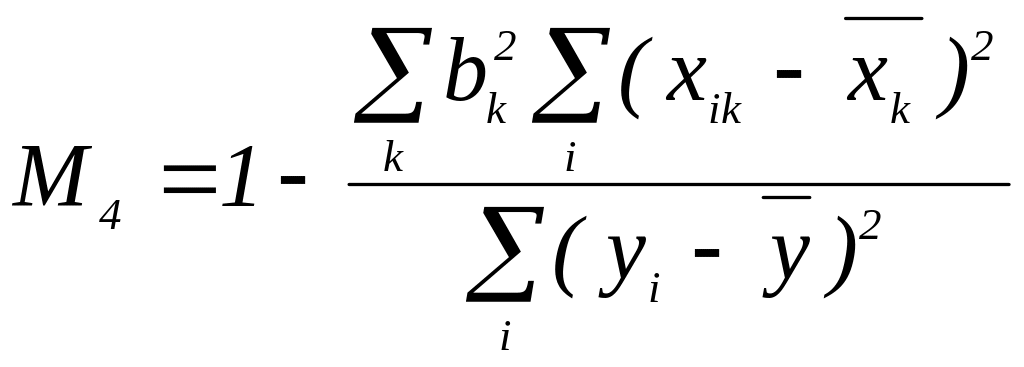 (57)
(57)
Розроблені ряд методів виключення чи зменшення мультиколінеарності:
виключення змінних;
лінійне перетворення змінних;
виключення тренду;
використання попередньої інформації;
покрокова регресія;
метод головних компонентів.
Якщо зменшити мультиколінеарність не вдається, то до оцінок коефіцієнтів регресії і до значень регресії треба відноситись з великою обережністю.