

6.4 Методы ускоренного доступа к данным
6.4.1 Интерполяционный поиск записи в массиве
Ускорение доступа к данным достигается применением принципиально иных методов размещения информации и её поиска либо путем создания массивов вспомогательной информации о хранимых данных. Эти же методы необходимы при организации доступа к информации по нескольким ключевым атрибутам одновременно.
Доступ к требуемым записям может осуществляться не только путем сравнения искомого значения ключа с ключами записей, извлекаемых из массива по определенному алгоритму (как это было в вышерассмотренных методах обработки данных), но и в результате вычисления местоположения требуемой записи. Сами записи могут быть упорядочены алгоритмом сортировки либо используется специальная расстановка записей. В первом случае специфический метод доступа, реализующий вычисление местоположения требуемой записи, называется интерполяционным поиском.
Рассмотрим последовательный массив. Значения ключевого атрибута А(i) для l < i < M будем интерполировать с помощью линейной функции, которую построим по двум точкам (1, А(1)) и (М, А(М)). Для произвольной точки (i, А(i)) в соответствии с линейной интерполяцией справедливо выражение
 .
.
При вычислении номера записи с ключевым признаком q значение q подставляется вместо А(i) и требуемый номер записи получается из выражения
 .
(6.1)
.
(6.1)
Поскольку реальное распределение значений ключа в отсортированном массиве лишь приближенно соответствует линейной функции, интерполяционный поиск необходимо завершить последовательным поиском значения q, начиная с i-й записи (i получено по формуле 6.1).
Следующая группа методов ускорения поиска использует специальную расстановку записей в памяти компьютера, которая, вообще говоря, нарушает типичную при последовательной организации данных упорядоченность записей по значениям ключевого атрибута. Расстановка записей происходит в соответствии с так называемой адресной функцией (ее синонимы — «рандомизирующая функция» и «хэш-функция»). Применяемые при этом методы организации данных часто называются методами рандомизации.
6.4.2 Адресные функции
Возможность определения места хранения данных используется также при размещении данных согласно адресной функции. Упорядоченность записей по значениям ключа в этом случае, вообще говоря, не соблюдается.
Адресной функцией называется зависимость i = f (А), где i — номер (адрес) записи; А — значение ключевого атрибута.
Адресная функция может вырабатывать одинаковое значение i для значений ключей, принадлежащих разным записям, которые в данном случае называются синонимами.
К адресной функции f предъявляются следующие требования:
она должна быть задана аналитически и вычисляться достаточно быстро;
ключевые атрибуты, подчиняющиеся произвольному распределению, функция должна перерабатывать в равномерно распределенные номера записей;
число записей-синонимов не должно превышать 10—20 % от общего числа записей.
Известно достаточно много адресных функций, хорошо соответствующих этим требованиям.
I. Адресная функция i = А – с
Простейшая адресная функция имеет вид:
i = А – с,
где с — константа.
Необходимо определить минимальное значение ключевого атрибута Аmin и максимальное значение Аmax. Тогда с = Аmin – 1. Необходимый участок памяти для данных должен иметь размер [Аmax – Аmin + 1] — запись. Записи-синонимы связываются в цепочки с помощью адресов связи, они занимают дополнительную (резервную) память.
Рассмотрим пример размещения записей с ключами 26, 23, 25, 21, 24, 21, 28, 24 согласно адресной функции i = А – с.
с = Аmin – 1 = 21 – 1 = 20; i = А – 20.
Необходимый размер записей будет равен
[Аmax – Аmin + 1] = 28 – 21 + 1 = 8 записей.
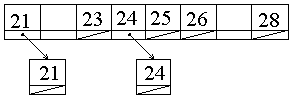
Рис. 6.13 — Пример организации записей в соответствии с адресной функцией вида i = А – с
При доступе к записи с ключом q (во время выполнения операций поиска, удаления и добавления новой записи) вычисляется i = f (А) = q – с и производится обращение к i-й записи (если она имеется или вычисляется её адрес и происходит добавление новой записи в основной или резервной памяти). При необходимости (выполнении операций поиска или удаления) с помощью адресов связи извлекаются все записи-синонимы.
Недостатком адресной функции вида i = А – с является большой объем неиспользуемой памяти, если Аmax – Аmin много больше, чем количество записей М исходного массива.
II. Адресная функция i = ОСТ (А/т)
Указанного выше недостатка (большой объем неиспользуемой памяти) лишена адресная функция вида
i = ОСТ (А/т),
где т — целое число; ОСТ — остаток от деления А на т.
Значение m принимается равным простому числу, которое непосредственно больше либо меньше числа записей М:
m = М 1.
Выделяются две зоны памяти — основная и резервная. Основная зона содержит т записей. Резервная зона предназначена для размещения записей-синонимов. При формировании данных согласно адресной функции сначала производится заполнение основной зоны. Если при этом позиция основной зоны, полученная при вычислении, уже занята, то текущая запись помещается в резервную зону и адресуется из позиции основной зоны. В дальнейшем при такой ситуации наращивается цепочка записей в резервной зоне. Например, для массива с ключами 15, 10, 20, 16, 25, 8, 13, 6, 12, 9, 28, 10, 17, 6, 23, 16, 18, 8 получить адресную функцию вида i = ОСТ (А /m).
M = 18, пусть m =17, тогда i = ОСТ (А/17).
Резервная зона заполняется последовательно (рис. 6.14). При поиске значения, например: q = 6, вычисляется i = ОСТ (6/17) = 6 и далее последовательно сравниваются 6 и q в основной зоне, 6 и q, 23 и q в резервной зоне. Для обнаружения искомого ключа потребовались одно деление и три сравнения, поскольку всегда необходимо просматривать цепочку в резервной зоне до конца.
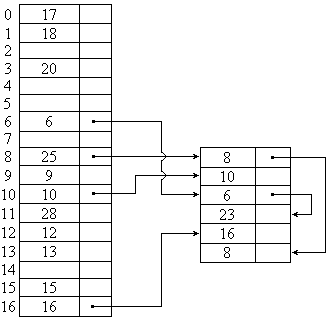
Рис. 6.14 — Пример организации записей в соответствии
с адресной функцией i = ОСТ (А/m)
Для ускорения поиска записей в массиве используется дополнительная информация, организованная в виде массива индексов.