

Хід роботи
Запустіть програму Open Office.
Відкриється порожня книжка(в іншому випадку створіть нову книжку).
В діапазоні А1:А100 введіть дані спостережень – вибірку (табл.1).
Сортуємо її в порядку зростання.
Таблиця 1
-
99,0
98,0
98,5
101,5
99,5
100,5
99,5
99,0
100,0
100,0
100,5
100,5
100,0
100,5
102,5
102,5
103,5
103,5
102,5
98,5
99,0
99,0
99,0
99,5
102,5
102,5
103,5
100,0
100,5
103,5
103,5
102,5
102,5
102,5
100,5
100,5
100,5
100,0
100,5
102,5
100,0
100,5
100,0
100,0
100,5
102,5
102,5
104,0
102,5
102,5
102,5
100,5
100,5
100,0
100,0
100,0
100,0
101,5
101,0
101,0
101,0
101,0
101,0
103,0
102,0
99,5
102,5
102,0
101,0
101,0
101,0
101,0
101,0
101,0
101,0
101,0
101,5
101,5
101,5
101,5
102,5
102,5
103,0
102,0
102,0
101,5
101,5
101,5
101,5
101,5
101,5
101,5
101,0
101,0
101,0
101,0
102,0
102,5
103,0
103,0
Заповнюємо клітинки діапазону В1:В10 стовпчику В, обчисливши вказані основні числові характеристики:
|
А |
В |
1 |
98 |
Середнє значення |
2 |
98,5 |
101,195 |
3 |
98,5 |
Стандартне відхилення |
4 |
99 |
1,298590922 |
5 |
99 |
min |
6 |
99 |
98 |
7 |
99 |
max |
8 |
99 |
104 |
9 |
99,5 |
Обсяг вибірки |
10 |
99,5 |
100 |
11 |
99,5 |
Кількість інтервалів |
12 |
99,5 |
6 |
13 |
100 |
Нижня межа= xmin |
14 |
100 |
98 |
15 |
100 |
Верхня межа= xmax |
16 |
100 |
104 |
17 |
100 |
Довжина інтервалу |
18 |
100 |
1 |
19 |
100 |
Рівень значущості |
20 |
100 |
0,05 |
21 |
… |
|
Для визначення кількості інтервалів в клітинку В12 вводимо 6 (з умови: ).
Для визначення довжини інтервалів в клітинку В18 вводимо формулу :
=(B16-B14)/B12.
Для задання меж інтервалів вводимо формули:
В клітинку D2: =B6;
В клітинку D3: =D2+$B$18;
В клітинки діапазону D4: D8 копіюємо формулу клітинки D3.
Для заповнення стовпця Емпіричні частоти в клітинку Е2 вводимо формулу
=ЧАСТОТА(A1:A100;D2:D3)
Копіюємо цю формулу в діапазон клітинок Е3:Е8
Для заповнення стовпця Теоретичні частоти в клітинку F2 вводимо формулу
=НОРМРАСП(D2;$B$2;$B$4;ИСТИНА)*$B$10
Копіюємо цю формулу в діапазон клітинок F3:F8
Для заповнення таблиці критерію :
В клітинку Н3 вводимо формулу =E2+E3
В клітинку Н4 вводимо формулу =E4
Копіюємо цю формулу в діапазон клітинок Н5:Н8
В клітинку Н9 вводимо формулу =СЧЁТ(Н3:Н8)
В клітинку І3 вводимо формулу = F 2+ F 3
В клітинку І4 вводимо формулу = F 4
Копіюємо цю формулу в діапазон клітинок І5:І8
Для обчислення Емпіричного значення заповнюємо стовпчик J
В клітинку J 3 вводимо формулу: =(H3-I3)^2/I3
Копіюємо цю формулу в діапазон клітинок J 4: J 8.
В клітинці J 9 обчислюємо: =СУММ(J3:J8)
12. Висновок: заповнюємо стовпчик L
В клітинку L1 вводимо: Емпіричне значення
В клітинку L2 вводимо формулу: = J9;
В клітинку L3 вводимо: Рівень значущості
В клітинку L4 вводимо: 0,05
В клітинку L5 вводимо: Ступенів свободи
В клітинку L6 вводимо формулу: = Н9 -2-1;
В клітинку L7 вводимо: Критичне значення
В клітинку L8 вводимо формулу: =ХИ2ОБР(L4;L6);
В клітинку L4 вводимо: Висновок
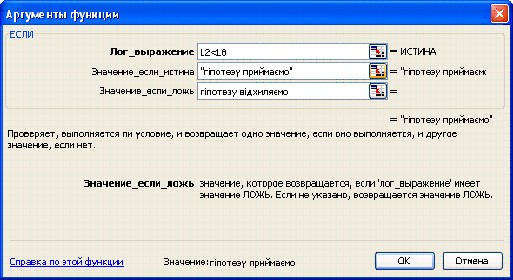
В клітинку L10 вводимо формулу:
=ЕСЛИ(L2<L8;"гіпотезу приймаємо";"гіпотезу відхиляємо").
13. Змінити рівень значущості на 0,01 і 0,1 . Записати висновки.
14. Оформити звіт.
Отримуємо підсумкову таблицю:
|
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
|
1 |
99 |
Середнє значення |
|
Межі інтервалів |
Емпіричні частоти |
Теоретичні частоти |
|
Таблиця критерію |
|
Емпіричне значення |
|||
2 |
98 |
101,195 |
|
98 |
1 |
0,693990292 |
|
Емпіричні частоти |
Теоретичні частоти |
ХІ-квадрат |
|
7,149158134 |
|
3 |
98,5 |
Стандартне відхилення |
|
99 |
8 |
4,548589395 |
|
9 |
5,24258 |
2,692989 |
|
Рівень значущості |
|
4 |
101,5 |
1,299 |
|
100 |
24 |
17,87267577 |
|
24 |
17,87268 |
2,100642 |
|
0,05 |
|
5 |
99,5 |
min |
|
101 |
54 |
44,03181021 |
|
54 |
44,03181 |
2,25666 |
|
Ступенів свободи |
|
6 |
100,5 |
98 |
|
102 |
72 |
73,23390711 |
|
72 |
73,23391 |
0,02079 |
|
3 |
|
7 |
99,5 |
max |
|
103 |
94 |
91,77307228 |
|
94 |
91,77307 |
0,054038 |
|
Критичне значення |
|
8 |
99 |
104 |
|
104 |
100 |
98,4614965 |
|
100 |
98,4615 |
0,02404 |
|
7,814727764 |
|
9 |
100 |
Обсяг вибірки |
|
|
|
|
|
6 |
|
7,149158 |
|
Висновок |
|
10 |
100 |
100 |
|
|
|
|
|
|
|
|
|
гіпотезу приймаємо |
|
11 |
100,5 |
Кількість інтервалів |
|
|
|
|
|
|
|
|
|
|
|
12 |
100,5 |
6 |
|
|
|
|
|
|
|
|
|
|
|
13 |
100 |
Нижня межа xmin |
|
|
|
|
|
|
|
|
|
|
|
14 |
100,5 |
98 |
|
|
|
|
|
|
|
|
|
|
|
15 |
102,5 |
Верхня межа xmax |
|
|
|
|
|
|
|
|
|
|
|
16 |
102,5 |
104 |
|
|
|
|
|
|
|
|
|
|
|
17 |
103,5 |
Довжина інтервалу |
|
|
|
|
|
|
|
|
|
|
|
18 |
103,5 |
1 |
|
|
|
|
|
|
|
|
|
|
|
19 |
102,5 |
Рівень значущості |
|
|
|
|
|
|
|
|
|
|
|
20 |
98,5 |
0,05 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Індивідуальне завдання. Виконати відповідне варіанту завдання (перевірити гіпотезу про нормальний розподіл середньої тривалості життя).
Лабораторна робота № 20
Тема
Перевірка гіпотез про розподіл . Критерій Колмогорова.
Мета
Уміти проводити перевірку гіпотез про нормальний розподіл генеральної сукупності за критерієм Колмогорова.
Теоретичні відомості
Опрацювати матеріал Лекції № 5 “ Статистична перевірка гіпотез про розподіл ”.
· СЧЁТ (COUNT) − підраховує кількість клітинок усередині діапазону.
Синтаксис: COUNT(діапазон)
діапазон – це діапазон, в якому потрібно підрахувати кількість клітинок.
· МАКС (MAX) − повертає найбільше значення з набору значень.
Синтаксис: MAX(число1;число2;...)
Число1, число2, ... – це від 1 до 30 чисел, серед яких потрібно знайти найбільше.
· СРЗНАЧ (AVERAGE) — повертає середнє арифметичне аргументів.
Синтаксис: AVERAGE(число1;число2;...)
Число1, число2, ... – це від 1 до 30 аргументів, для яких обчислюється середнє.
· СТАНДОТКЛОН (STDEV) - обчислює стандартне відхилення на основі вибірки.
Синтаксис: STDEV(число1;число2; ...)
Число1, число2, ... – це від 1 до 30 числових аргументів, які відповідають вибірці з генеральної сукупності.
· НОРМАЛИЗАЦИЯ(NORMALIZE) - Повертає нормалізоване значення для розподілу, який характеризується середнім и стандартним відхиленням.
Синтаксис: НОРМАЛИЗАЦИЯ(x;среднее;стандартное_откл)
x — значення, що нормалізується.
Среднее — середнє арифметичне розподілу.
Стандартное_откл — стандартне відхилення розподілу.
· НОРМРАСП(NORMDIST) - Повертає нормальну функцію розподілу для вказаного середнього і стандартного відхилення. Ця функція має дуже широке коло застосувань в статистиці, включи перевірку гіпотез.
Синтаксис: НОРМРАСП(x;среднее;стандартное_откл;интегральная)
x — значення, для якого будується розподіл.
Среднее — середнє арифметичне розподілу.
Стандартное_откл — стандартне відхилення розподілу.
· КОРЕНЬ(SQRT) - Повертає позитивне значення квадратного кореня.
Синтаксис: КОРЕНЬ(число)
Число — число, для якого обчислюється квадратний корінь.
· ЕСЛИ(IF) Повертає одне значеня, якщо задана умова при обчисленні дає значення ИСТИНА, та інше значення, якщо ЛОЖЬ.
Функція ЕСЛИ використовується при перевірці умов для значень і формул.
Синтаксис: ЕСЛИ(лог_выражение;значение_если_истина ;значение_если_ложь)
Лог_выражение — це довільне значення або вираз, який набуває значення ИСТИНА або ЛОЖЬ.
Значение_если_истина — це значення , яке повертається, якщо лог_выражение дорівнює ИСТИНА. Значение_если_истинаможе бути формулою.
Значение_если_ложь — це значення , яке повертається, якщо лог_выражение дорівнює ЛОЖЬ. Значение_если_ложь може бути формулою.