

Архитектура многопользовательских субд
В этом разделе приводятся различные типовые архитектурные решения, используемые при реализации многопользовательских СУБД, а именно схемы обычной телеобработки, файловый сервер и технология «клиент/сервер» [10].
Телеобработка
Традиционной архитектурой многопользовательских систем раньше считалась схема, получившая название «телеобработки», при которой один компьютер с единственным процессором был соединен с несколькими терминалами так. как показано на рис. 2.3 [10]. При этом вся обработка выполнялась в рамках единственного компьютера, а присоединенные к нему пользовательские терминалы были типичными «неинтеллектуальными» устройствами, не способными функционировать самостоятельно. С центральным процессором терминалы были связаны с помощью кабелей, по которым они посылали сообщения пользовательским приложениям (через подсистему управления обменом данными операционной системы). В свою очередь, пользовательские приложения обращались к необходимым службам СУБД.
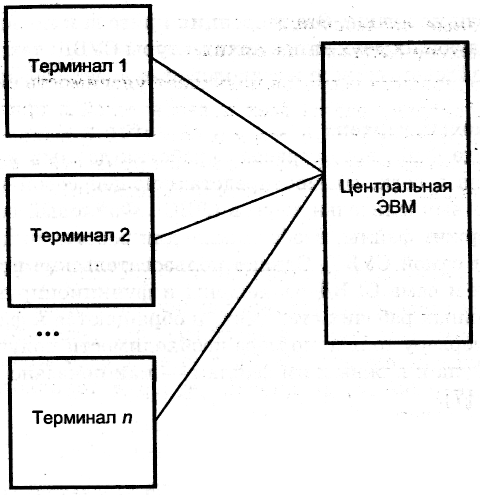
Рис. 2.3. Топология телеобработки
Таким же образом сообщения возвращались назад на пользовательский терминал. Недостатком является то, что при такой архитектуре основная и чрезвычайно большая нагрузка возлагалась на центральный компьютер, который должен был выполнять не только действия прикладных программ и СУБД, но и значительную работу по обслуживанию терминалов (например, форматирование данных, выводимых на экраны терминалов).
В последние годы был достигнут существенный прогресс в разработке высокопроизводительных персональных компьютеров и составленных из них сетей. При этом во всей индустрии наблюдается заметная тенденция к децентрализации (downsizing), т.е. замене дорогих мейнфреймов более эффективными, с точки зрения эксплуатационных затрат, сетями персональных компьютеров, позволяющими получить такие же результаты, если не лучше. Эта тенденция привела к появлению следующих двух типов архитектуры СУБД: технологии файлового сервера и технологии «клиент/сервер».
Файловый сервер
В среде файлового сервера обработка данных распределена в сети, обычно представляющей собой локальную вычислительную сеть (ЛВС). Файловый сервер содержит файлы, необходимые для работы приложений и самой СУБД. Однако пользовательские приложения и сама СУБД размещены и функционируют на отдельных рабочих станциях, и обращаются к файловому серверу только по мере необходимости получения доступа к нужным им файлам – как показано на рис. 2.4 [10].
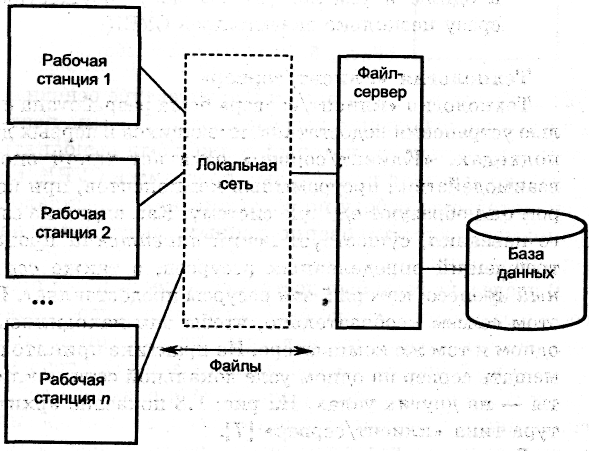
Рис. 2.4. Архитектура .с использованием файлового сервера
Таким образом, файловый сервер функционирует просто как совместно используемый жесткий диск. СУБД на каждой рабочей станции посылает запросы файловому серверу по всем необходимым ей данным, которые хранятся на диске файл-сервера. Такой подход характеризуется значительным сетевым трафиком, что может привести к снижению производительности всей системы в целом.
Архитектура с использованием файлового сервера обладает следующими основными недостатками.
Большой объем сетевого трафика.
На каждой рабочей станции должна находиться полная копия СУБД.
Управление параллельностью, восстановлением и целостностью усложняется, поскольку доступ к одним и тем же файлам могут осуществлять сразу несколько экземпляров СУБД.