

Индекс - «бинарное дерево»
Любой бинарный алгоритм поиска в упорядоченном файле БД можно представить с помощью соответствующего бинарного дерева [24]. Это бинарное дерево можно реализовать в виде самостоятельного файла (или индекса). При этом операции поиска будут освобождены от необходимости каждый раз вычислять адреса записей (они будут сформированы один раз при начальной загрузке файла БД и при последующих добавлениях в файл новых записей).
На рис. 11.1 представлено бинарное дерево, построенное для файла из 15 записей [24]. Запись бинарного дерева состоит из поля ключа записи и двух полей указателей. Один указатель для левого поддерева, другой – для правого поддерева. Листовые записи бинарного дерева содержат указатели на блоки файла основных записей (файла данных). Для уменьшения количества операций обмена с внешней памятью при выполнении поиска соседние записи в бинарном дереве объединяются в блоки. На слайде объединяемые в один блок записи бинарного дерева очерчены штриховой линией.
Записи бинарного дерева обычно меньше по объему памяти записей основного файла Vз.б.д. < Vз., так как содержат только одно поле данных (поле ключа) и два служебных поля для хранения индексов, то при одинаковых размерах блоков количество записей в блоке бинарного дерева больше, чем в блоке основного файла. Это позволяет еще больше сократить количество обращений к внешней памяти.
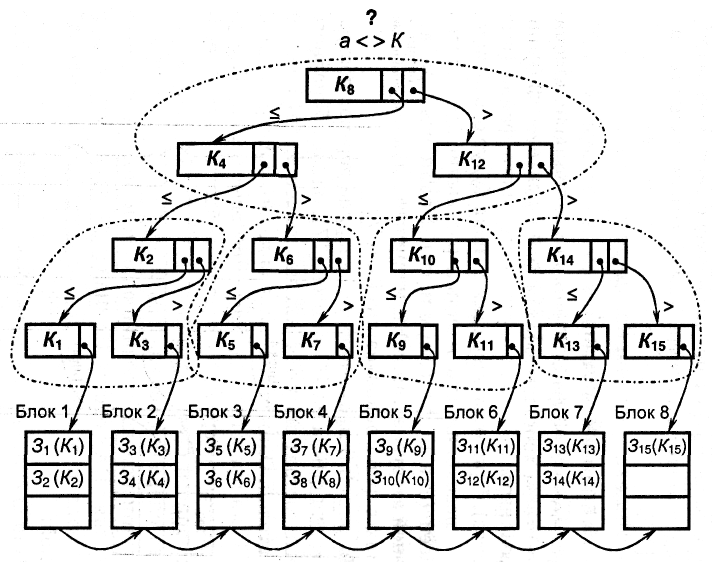
Рис. 11.1. Пример бинарного дерева
Реализация бинарного дерева позволяет сократить время поиска данных по сравнению с бинарным поиском, однако возрастает требуемый объем внешней памяти [24].
Неплотный индекс
Пусть основной файл F упорядочен по полю ключа К. Построим дополнительный файл FD (рис. 11.2) по правилу [24]:
1) записи файла FD имеют формат FD(K, Р), где К – поле, принимающее значение ключа первой записи блока основного файла F; Р – указатель на этот блок;
2) записи файла FD упорядочены по полю К.
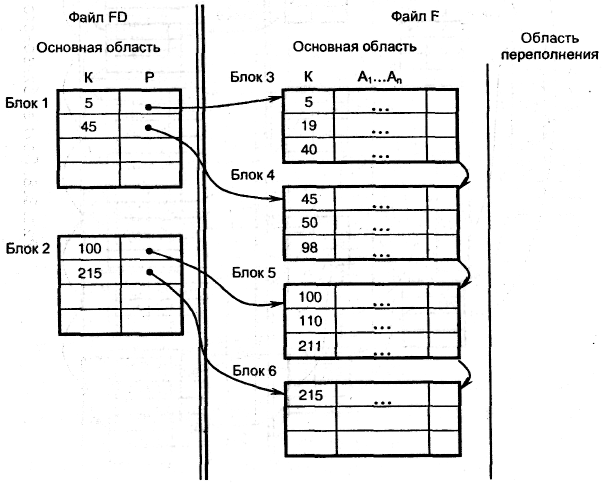
Рис. 11.2. Пример неплотного индекса
Полученный файл FD называется неплотным индексом. Количество записей файла FD равно количеству блоков основного файла F. Для организации файла FD требуется дополнительная внешняя память.
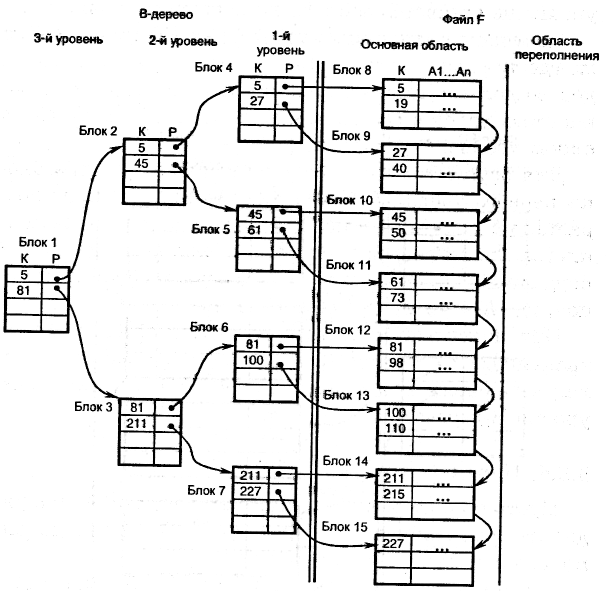
Рис. 11.3. Пример структуры типа В-дерево
Поиск вначале выполняется в индексе для нахождения адреса блока основного файла, а за тем этот блок считывает в оперативную память и в нем, например, с помощью последовательного поиска, определяется требуемая запись.
В-дерево. Так как неплотный индекс упорядочен по ключевому полю, то над ним можно построить еще один неплотный индекс (неплотный индекс неплотного индекса) и т.д., пока на самом последнем, верхнем уровне не останется всего один блок (рис. 11.3).
Полученная структура называется В-деревом порядка т, где т – количество записей в блоке индекса. Такое дерево должно иметь в каждом узле не менее т / 2 зависимых узлов и все листья должны располагаться на одном уровне.
Для осуществления последовательного поиска блоки первого уровня могут быть связаны в цепь по возрастанию значения ключа. Поиск в В-дереве выполняется так же, как и в неплотном индексе. Удачный и неудачный поиск записи в В-дереве требует h обменов, где h – число уровней В-дерева.
При поиске по интервалу значений а ≤ К ≤ b вначале выполняется поиск по К = а в В-дереве, а затем – последовательный поиск по условию К ≤ b в блоках 1-го уровня В-дерева.