

Модель внешней памяти
Данные хранятся во внешней памяти на магнитных дисках, магнитных лентах и т.д., а их обработка выполняется в оперативной памяти. Поэтому при обработке некоторые порции данных пересылаются из внешней памяти в оперативную либо наоборот [24].
При больших объемах данных в БД может потребоваться несколько томов внешней памяти. Однако обмен между внешней и оперативной памятью выполняется небольшими порциями данных – обычно объемом не более нескольких сотен байт. С этой целью внешняя память разбивается на части, называемые блоками или страницами. Данные пересылаются блоками. Операцию пересылки еще называют обменом данными между внешней и оперативной памятью. Такой обмен называется чтением блока, а в обратном направлении – записью блока.
При чтении блока, последний помещается в оперативной памяти в специально отведенный (буферный) участок памяти. Может отводиться участок под несколько буферов (буферный пул). Чем больше буферный пул, тем эффективнее обработка данных. При считывании другого блока из внешней памяти в тот же самый буфер предыдущее содержимое буфера теряется. При внесении изменений в блок вначале блок считывается в буфер, затем выполняются изменения и далее блок записываются во внешнюю память.
Для организации каждого файла в зависимости от его размера во внешней памяти ему выделяется от одного до п блоков, где размещаются записи файла. Предположим, что в одном блоке размещаются записи только одного файла. В зависимости от соотношения объемов записей и блоков может оказаться, что в одном блоке размещается либо одна, либо несколько записей файла, либо одна запись размещается в нескольких блоках. Обычно запись занимает несколько десятков байт.
Каждый байт в блоке пронумерован: О, 1, 2, ..., х. Номер байта блока, с которого начинается запись, определяет относительный адрес записи файла в блоке.
В качестве адресов записей файла во внешней памяти используют: машинный адрес, относительный адрес, ключ записи [24].
В качестве относительного адреса записи файла используют ее номер по порядку (внутрисистемный номер) в файле либо комбинацию таких составляющих адреса, как номер блока и относительный адрес в блоке, либо номер блока и значение ключа. В последнем случае, после считывания блока в буфер оперативной памяти, доступ к записи в буфере осуществляется в помощью какого-либо метода поиска записей в файле по значению ключа.
При чтении записи из блока, который уже находится в буфере, обмен с внешней памятью не выполняется. Во многих системах при вводе записи ей присваивается уникальный системный идентификатор – ключ базы данных.
Запись обычно состоит из:
1) служебных полей, в которых хранятся указатели, реализующие связи с другими записями, и другая информация, необходимая для организации управления файлом,
2) полей хранимых данных.
Записи могут быть фиксированной и переменной длины. Записи размещаются в блоках плотно, без промежутков, последовательно одна за другой. В блоке часть памяти отводится также для служебной информации о блоке: относительные адреса свободных участков памяти, указатели на следующий блок и т.д.
Если файл базы данных состоит из записей фиксированной длины, то в одном блоке может разместиться k записей:
![]() (10.5)
(10.5)
где – обозначает целую часть числа; Vбл. и Vз. – соответственно объем блока и записи в байтах.
Однако обычно блоки заполняются не полностью, например, наполовину. В дальнейшем эта область заполняется при расширении (увеличении) записей, хранящихся в блоке, или при поступлении в систему новых записей, которые в соответствии со значениями их ключей или по другим условиям необходимо поместить в одном блоке с уже хранящимися записями.
Для хранения поступающих данных, которые должны были бы попасть в этот блок, выделяется дополнительный блок памяти в области переполнения. Записи, которые должны были размещаться в одном блоке, связываются специальными указателями в одну цепь.
Процесс выделения дополнительных блоков в области переполнения можно было бы не ограничивать, если бы при этом не снижалась эффективность (по временному критерию) обработки хранимых данных. Поэтому периодически файл реорганизуется: при необходимости файлу добавляется требуемой количество блоков в основной области памяти и выполняется требуемая перекомпоновка записей. При этом исходят из расчета, чтобы можно было освободить область переполнения, а все записи разместить в блоках основной области, причем, в каждом блоке разместить записи последовательно и в таком количестве, чтобы r-я часть блока осталась незаполненной. В этом случае требуемое количество блоков
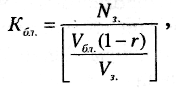 (10.6)
(10.6)
где r < 1 – незаполненная часть блока; Nз. – количество записей в файле.
Считается, что все блоки каждого файла пронумерованы: 1, 2, ..., β, ..., N и система определяет требуемый блок по имени файла и номеру блока. Если файл состоит из записей фиксированной длины, записи организованы последовательно и имеют внутри файла системный номер, то по этому номеру вычисляют номер блока, в котором находится запись:
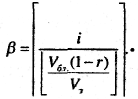 (10.7)
(10.7)
Среднее время выполнения операций обмена зависит от типа устройства внешней памяти (от его характеристик) и от размера блока:
![]() (10.8)
(10.8)
где to – среднее время выполнения операции обмена; tp – время считывания, приведенное к одному байту (т.е. время считывания одного байта); tподг. – время подготовки устройства к выполнению операции обмена.
Время поиска данных в файле
![]() (10.9)
(10.9)
где tп – время выполнения операции поиска; tс – среднее время выполнения в процессоре одной операции сравнения; Хо – количество операций обмена; Хс – количество операций сравнения.
Если tc << to, то время поиска в основном определяется временем, затрачиваемым на обмен с внешней памятью. Поэтому при составлении алгоритмов поиска данных в файле стремятся к сокращению количества операций обмена.
На скорость поиска данных в файле наибольшее влияние оказывают следующие характеристики файла и технических устройств внешней памяти, использованных для его организации [24]:
объем блока;
объем байта;
количество записей в блоке файла пз.бл.;
количество записей в блоке индекса;
количество блоков в файле данных nбл.ф.;
доля резервируемой части блока r (при начальной организации данных в файле);
длина поля, отведенного для указателя;
количество записей в файле пз.ф.;
число полей в записи nп.з.;
размер записи Vз.;
длина ключевого поля в записи;
число записей файла, удовлетворяющих условию поиска Q;
среднее число блоков переполнения на один блок файла;
среднее время обмена to.
На рис. 10.7 изображен файл со следующими характеристиками: nз.ф. = 10; nз.бл. = 4; r = 0,5. Записи файла описываются схемой: F(А1, А2, А3, А4), т.е. nп.з. = 4. При начальной загрузке при таких характеристиках для организации файла требуется 5 блоков.

Рис. 10.7. Пример организации файла при начальной загрузке