

Лекция 7. Даталогические модели данных
Модель данных – фиксированная система понятий и правил для представления структуры данных, состояния и динамики проблемной области в базах данных [17]. Как правило, задается языком определения данных и языком манипулирования данными. Примерами модели данных, получившими широкое распространение, являются модели данных сетевая, иерархическая, реляционная и др.[2].
Модель данных состоит из трех компонент [15].
1. Структура данных для представления точки зрения пользователя на базу данных.
2. Допустимые операции, выполняемые на структуре данных. Они составляют основу языка данных рассматриваемой модели данных. Одной лишь хорошей структуры данных недостаточно. Необходимо иметь возможность работать с этой структурой при помощи различных операций языка определения данных и языка манипулирования данными. Богатая структура данных ничего не стоит, если нет возможности оперировать ее содержимым.
3. Ограничения для контроля целостности. Модель .данных должна быть обеспечена средствами, позволя ющими сохранять ее целостность и защищать ее.
Схема – это средство, с помощью которого определяется модель данных приложения. В действительности схема содержит не только модель данных: в ней присутствует также некоторая семантическая информация, относящаяся к конкретному приложению. В модели данных можно определить, например, что база данных будет хранить информацию об организациях и служащих. Однако, тот факт, что данный служащий не может работать более чем в одной организации, отражает семантику приложения. Это семантическое ограничение должно выполняться для каждого отдельного экземпляра записи базы данных об этом служащем. Поддержка ограничений заданной модели данных в базе данных также является частью функций СУБД по обеспечению защиты и целостности.
Прежде, чем перейти к детальному и последовательному изучению реляционных систем БД, целесообразно ознакомиться с ранними СУБД [11]. В этом есть смысл по трем причинам: во-первых, эти системы исторически предшествовали реляционным, и для правильного понимания причин повсеместного перехода к реляционным системам нужно знать хотя бы что-нибудь про их предшественников; во-вторых, внутренняя организация реляционных систем во многом основана на использовании методов ранних систем; в-третьих, некоторое знание в области ранних систем будет полезно для понимания путей развития постреляционных СУБД.
Иерархическая модель
Иерархическая БД состоит из упорядоченного набора деревьев; более точно, из упорядоченного набора нескольких экземпляров одного типа дерева.
Тип дерева состоит из одного «корневого» типа записи и упорядоченного набора из нуля или более типов поддеревьев (каждое из которых является некоторым типом дерева). Тип дерева в целом представляет собой иерархически организованный набор типов записи [11].
Пример типа дерева (схемы иерархической БД) представлен на рис. 7.1.
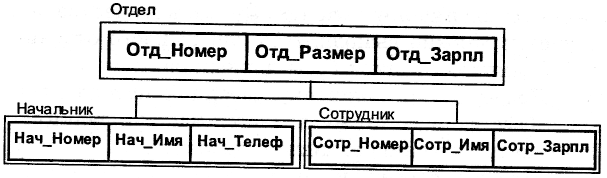
Рис. 7.1. Пример схемы иерархической БД
На рис. 7.1. ОТДЕЛ является предком для НАЧАЛЬНИК и СОТРУДНИКИ, а НАЧАЛЬНИК и СОТРУДНИКИ - потомки ОТДЕЛ. Между типами записи поддерживаются связи.
База данных с такой схемой могла бы выглядеть следующим образом (рис. 7.2, показан один экземпляр дерева) [11].
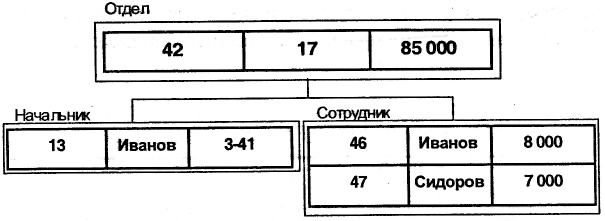
Рис. 7.2. Реализация иерархической БД
Все экземпляры данного типа потомка с общим экземпляром типа предка называются близнецами. Для БД определен полный порядок обхода - сверху-вниз, слева-направо.
Примерами типичных операторов манипулирования иерархически организованными данными могут быть следующие [11].
Найти указанное дерево БД (например, отдел 42).
Перейти от одного дерева к другому.
Перейти от одной записи к другой внутри дерева (например, от отдела – к первому сотруднику).
Перейти от одной записи к другой в порядке обхода иерархии.
Вставить новую запись в указанную позицию.
Удалить текущую запись.
Автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя. Заметим, что аналогичное поддержание целостности по ссылкам между записями, не входящими в одну иерархию, не поддерживается.
В иерархических системах поддерживалась некоторая форма представлений БД на основе ограничения иерархии. Примером представления приведенной выше БД может быть следующая иерархия (рис. 7.3) [11].
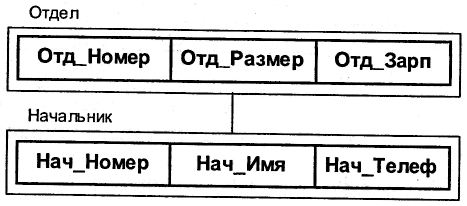
Рис. 7.3. Пример схемы иерархической БД
Экземпляр дерева базы данных не обязательно должен содержать все свои сегменты. При необходимости можно добавлять или удалять экземпляры типов записей в соответствии с требованиями приложения.
Иерархическая структура реализует отношение ОДИН-КО-МНОГИМ между исходным и порожденным типами записей. Это отображение полностью функционально, т.к. дерево не может содержать порожденный узел без исходного узла (за исключением «корня»). Следовательно, отображения ОДИН-К-ОДНОМУ и ОДИН-КО-МНОГИМ могут непосредственно представляться иерархическими структурами. Однако для представления отображения МНОГИЕ-КО-МНОГИМ необходимо дублирование деревьев, а значит, реализация сложных связей требует больших затрат памяти.
Другой проблемой иерархий является невозможность хранения в БД порожденного узла без соответствующего исходного, т.е. в этом случае необходимо ввести пустой исходный узел. Соответственно удаление данного исходного узла влечет удаление всех порожденных узлов (поддеревьев), связанных в ним. Эти ограничения создают проблемы применения иерархической модели для некоторых приложений.