

"Двусвязный список"
Расскажите о реализации двусвязного списка
Какие структуры для этого требуются?
Модифицируйте его для реализации закольцованности.
Двусвязный спи́сок — структура данных, состоящая из узлов, каждый из которых содержит как собственно данные, так и две ссылки («связки») на следующий и/или предыдущий узел списка. Структуры:
struct ListNode
{
int value;
struct ListNode *prev;
struct ListNode *next;
};
struct List
{
int size;
struct ListNode *head;
struct ListNode *tail;
};
ListNode – данные узла и ссылки на предыдущий и следующий узлы
List – размер, начальный элемент, конечный элемент – для удобства использования операций
В закольцованном списке у последнего элемента списка в поле next хранится head, а у первого элемента в поле previous - tail., это учитывается при описании операций (push, pushb и т.д.)
Или же добавить указатель на первый элемент к последнему элементу, и на последний элемент к первому элементу
Задача сортировки n объектов.
Базовый алгоритм быстрой сортировки. Его производительность в худшем случае.
Что такое стабильная сортировка? Какие сортировки стабильны?
Назовите стандартные реализации сортировок в языке.
Предложите алгоритм нахождения k-й порядковой статистики, основанный на идее алгоритма Quick Sort. Напишите иллюстрирующий код.
Оцените среднее и худшее время работы этого алгоритма.
Quicksort
выбрать элемент, называемый опорным.
сравнить все остальные элементы с опорным, на основании сравнения разбить множество на три — «меньшие опорного», «равные» и «большие», расположить их в порядке меньшие-равные-большие.
повторить рекурсивно для «меньших» и «больших».
Среднее. Даёт в среднем O(n lg n) обменов при упорядочении n элементов. В реальности именно такая ситуация обычно имеет место при случайном порядке элементов и выборе опорного элемента из середины массива либо случайно.
Худший случай. Худшим случаем, очевидно, будет такой, при котором на каждом этапе массив будет разделяться на вырожденный подмассив из одного опорного элемента и на подмассив из всех остальных элементов. Такое может произойти, если в качестве опорного на каждом этапе будет выбран элемент либо наименьший, либо наибольший из всех обрабатываемых. Худший случай даёт O(n²) обменов. Но количество обменов и, соответственно, время работы — это не самый большой его недостаток. Хуже то, что в таком случае глубина рекурсии при выполнении алгоритма достигнет n, что будет означать n-кратное сохранение адреса возврата и локальных переменных процедуры разделения массивов. Для больших значений n худший случай может привести к исчерпанию памяти во время работы алгоритма.
Устойчивая (стабильная) сортировка — сортировка, которая не меняет относительный порядок сортируемых элементов, имеющих одинаковые ключи. Большинство простых методов сортировки устойчивы, большинство сложных — нет.
Стабильные:
Сортировка пузырьком (англ. Bubble sort ) — сложность алгоритма: O(n2); для каждой пары индексов производится обмен, если элементы расположены не по порядку.
Сортировка вставками (Insertion sort) — Сложность алгоритма: O(n2); определяем где текущий элемент должен находиться в упорядоченном списке и вставляем его туда
Сортировка слиянием (Merge sort) — Сложность алгоритма: O(n log n); требуется O(n) дополнительной памяти; выстраиваем первую и вторую половину списка отдельно, а затем — сливаем упорядоченные списки
Merge, heap, bubble, insertion, quick, shell, selection sorts – стандартные реализации сортировок
k-статистика, основанная на QuickSort
int findOrderStatistic(int[] array, int k) { int left = 0, right = array.length; while (true) { int mid = partition(array, left, right); if (mid == k) array[mid]; else if (k < mid) right = mid; else { k -= mid + 1; left = mid + 1; } } }
Среднее O(n) Худшее- O(n^2)
Heap Sort
На основе какой структуры данных реализуется данный алгоритм?
Расскажите сам алгоритм.
Какова сложность алгоритма в среднем? А в худшем случае?
Напишите код для бинарного поиска.
На основе двоичной кучи: Двои́чная ку́ча, пирами́да[1], или сортиру́ющее де́рево — такое двоичное дерево, для которого выполнены три условия:
Значение в любой вершине не меньше, чем значения её потомков.
Каждый лист имеет глубину (расстояние до корня) либо d либо d-1. Иными словами, если назвать слоем совокупность вершин, находящихся на определённой глубине, то все слои, кроме, быть может, последнего, заполнены полностью.
Последний слой заполняется слева направо.
Сортировка пирамидой использует сортирующее дерево. Сортирующее дерево — это такое двоичное дерево, у которого выполнены условия:
Каждый лист имеет глубину либо d, либо d − 1, d — максимальная глубина дерева.
Значение в любой вершине больше, чем значения её потомков.
Удобная структура данных для сортирующего дерева — такой массив Array, что Array[1] — элемент в корне, а потомки элемента Array[i] — Array[2i] и Array[2i+1].
Алгоритм сортировки будет состоять из двух основных шагов:
1. Выстраиваем элементы массива в виде сортирующего дерева:
![]()
![]()
при
![]() .
.
Этот шаг требует O(n) операций.
2. Будем удалять элементы из корня по одному за раз и перестраивать дерево. То есть на первом шаге обмениваем Array[1] и Array[n], преобразовываем Array[1], Array[2], … , Array[n-1] в сортирующее дерево. Затем переставляем Array[1] и Array[n-1], преобразовываем Array[1], Array[2], … , Array[n-2] в сортирующее дерево. Процесс продолжается до тех пор, пока в сортирующем дереве не останется один элемент. Тогда Array[1], Array[2], … , Array[n] — упорядоченная последовательность.
Сложность гарантированно O(n log n)
Бинарный поиск:
int binsearch(int *a, int v, int l, int h)
{
int mid;
if (h<l)
return -1;
mid=(l+h)/2;
if (a[mid]>v)
return binsearch(a, v, l, mid-1);
else
if (a[mid]<v)
return binsearch(a, v, mid+1, h);
else
return mid;
}
Binary Search Tree
Что такое граф, дерево?
Что такое бинарное дерево?
Опишите Binary Search Tree. В чем его отличие от кучи?
Как его можно реализовать?
Граф — это совокупность узлов и ребер, соединяющих эти узлы. Дерево — структура данных, эмулирующая древовидную структуру в виде набора связанных узлов. Является связанным графом, не содержащим циклы.
Двои́чная ку́ча или сортиру́ющее де́рево — такое двоичное дерево, для которого выполнены три условия:
Значение в любой вершине не меньше, чем значения её потомков.
Каждый лист имеет глубину либо d либо d-1. Иными словами, если назвать слоем совокупность вершин, находящихся на определённой глубине, то все слои, кроме, быть может, последнего, заполнены полностью.
Последний слой заполняется слева направо.
Двоичное дерево поиска — это двоичное дерево, для которого выполняются следующие свойства:
О
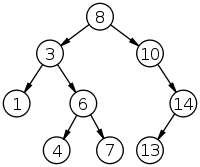 ба
поддерева — левое и правое, являются
двоичными деревьями поиска.
ба
поддерева — левое и правое, являются
двоичными деревьями поиска.
У всех узлов левого поддерева произвольного узла X значения ключей меньше, нежели значение ключа узла X.
У всех узлов правого поддерева произвольного узла X значения ключей больше, нежели значение ключа узла X.
struct TreeNode { ElementType Element; SearchTree Left; SearchTree Right; };
SearchTree Insert( ElementType X, SearchTree T ) { if( T == NULL ) { T = malloc( sizeof( struct TreeNode ) ); if( T == NULL ) FatalError( "Out of space!!!" ); else { T->Element = X; T->Left = T->Right = NULL; } } else if( X < T->Element ) T->Left = Insert( X, T->Left ); else if( X > T->Element ) T->Right = Insert( X, T->Right ); return T; }