

Лекция 15
Сканер и его программное обеспечение. Системы автоматического ввода текста. Методы распознавания символов.
Слайд 1. Тема
Сканер и его программное обеспечение.
Сканер представляет собой растровое устройство, служащее для преобразования в цифровую форму и ввода в компьютер изображений (рисунков, графики, текста) с оригиналов. Вводимый рисунок или текст может находиться на прозрачной (пленке) или непрозрачной (например, бумаге) основе. В персональных компьютерах наиболее часто используются сканеры планшетного типа. Первый планшетный сканер для ПК был выпущен в 1984 г. фирмой Microtek. Устройство подобного сканера показано на слайде 2.
Слайд 2. Устройство планшетного сканера
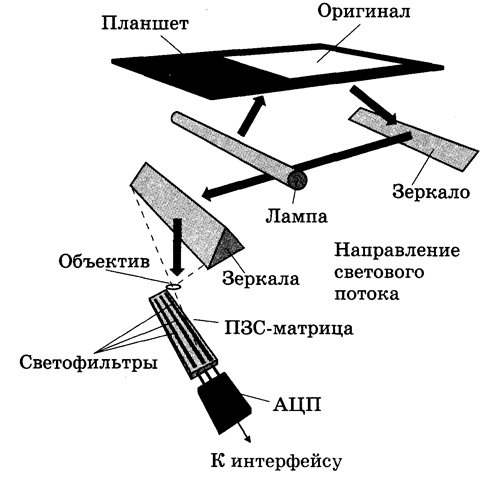
Все подобные сканеры осуществляют сканирование построчно. Сканируемый оригинал помещается на стеклянный стол (планшет), под которым посредством прецизионного шагового двигателя передвигается каретка с люминесцентной лампой с холодным катодом. Она освещает изображение белым светом. Оригинал прижимается к стеклу прижимной крышкой. Отраженный от оригинала свет через систему плоских зеркал попадает в объектив, создающий три уменьшенные копии изображения, а затем на линейку фотоприемников, построчно регистрируя распределение цветов в изображении. В качестве фотоприемников используют ПЗС (приборы с зарядовой связью), преобразующие световой поток в накопленный заряд. ПЗС представляет собой три линейки фотоприемников, перед каждой из которых установлен светофильтр одного из трех основных цветов — красного, зеленого и синего (RGB). Эти ПЗС соединены с ПНК (преобразователь напряжение-код, иначе АЦП), на выходе которого и формируются цифровые коды, соответствующие яркости точек строки сканирования. Оцифрованные значения точек строки запоминаются, изображение смещается относительно линейки ПЗС и происходит оцифровка следующей строки. Каждый пиксел изображения описывается лишь уровнем напряжения на ПЗС, пропорциональным интенсивности попавшего на него света. Разрядностью используемых ПНК определяется точность оцифровки изображения; обычно она не превышает 8 — 10 двоичных разрядов. Благодаря наличию объектива, такой сканер обладает значительной глубиной резкости и высоким оптическим разрешением. Это позволяет сканировать оригиналы различной толщины без потери четкости. После последовательной оцифровки всех строк изображения производится передача данных в компьютер. Количество передаваемых данных зависит от разрешения сканера, размера сканируемой области и глубины цвета — чем выше разрешающая способность сканера, больше размер сканируемой области и глубина цвета, тем больше объем передаваемых данных.
К недостаткам сканеров, построенных на основе ПЗС, можно отнести большое энергопотребление, значительные размеры и длительное время (свыше минуты) разогрева люминесцентной лампы. Кроме того, для питания такой лампы необходим специальный преобразователь. Это привело к появлению сканеров с контактными датчиками. Они дешевле и проще по конструкции. Вместо лампы, системы зеркал, объектива и линеек ПЗС в них используются три светодиода (красный, зеленый и синий), поочередно освещающие оригинал, а также перемещаемая вблизи стекла линейка фотодиодов. Но такие устройства не позволяют сканировать объемные оригиналы, поскольку у них небольшая глубина резкости, кроме того, они уступают сканерам на основе ПЗС по максимальному разрешению и точности передачи оттенков цвета.
Рассмотренные сканеры довольно просты и обладают высокой точностью. Но размер сканируемого изображения в них ограничен — они обеспечивают сканирование книжных и журнальных страниц форматом не более А4 или АЗ, а также сканирование со слайдов и фотопленки.
Для сканирования изображений большего размера применяют лентопротяжные и барабанные сканеры. В лентопротяжных сканерах происходит перемещение изображения относительно неподвижного источника света и линейки ПЗС. В барабанных сканерах оригинал помещают на барабан, при вращении которого и перемещении лампы с фотоприемником производится последовательное поточечное сканирование. Помимо таких сканеров, в настоящее время выпускаются и портативные ручные, не имеющие механического привода перемещения сканирующей головки. Пользователь должен вручную перемещать такой сканер по сканируемому документу. В сканерах для прозрачных оригиналов (слайдов и негативов) система подсветки и сканирующий блок расположены по разные стороны оригинала, а особенности сканируемых документов заставляют применять ПЗС с высокой плотностью размещения элементов.
Одной из важнейших характеристик сканера служит максимальное разрешение, т. е. предельное число точек на единице длины (обычно в качестве такой единицы служит дюйм), которое может быть распознано оптической системой. В современных сканерах линейки ПЗС или контактных датчиков имеют 300, 600, 1200 и 2400 элементов, приходящихся на один дюйм, однако на разрешение влияют и многие другие факторы — качество оптической системы, уровни шумов ПЗС, равномерность освещения и т. п. Поэтому реальное разрешение сканера обычно меньше плотности размещения элементов в ПЗС.
Помимо оптического разрешения, важной характеристикой сканера является механическое разрешение, т. е. число элементарных перемещений каретки, приходящееся на один дюйм планшета. Механическое разрешение зависит от точности системы перемещения сканера — дискретности шагового двигателя, точности редуктора и т. д. В современных сканерах механическое разрешение составляет от 300 до 1200 элементов на дюйм.
Глубина цвета получаемого в результате сканирования изображения зависит от разрядности ПНК. Обычно в характеристиках сканеров указывают суммарную разрядность всех трех ПНК (от 24 до 48 бит), предназначенных для цветовых каналов, например в 24-разрядном сканере установлено три восьмиразрядных преобразователя, каждый из которых различает по 256 градаций основного цвета (общее число оттенков составляет около 16 млн).
Для сканеров существуют программные методы, с помощью которых «повышают» разрешение и глубину цвета. Программы могут быть встроенными, а также размещаться на отдельном сервере. Если программы встроенные, то нет необходимости в отдельном управляющем компьютере, сканер будет работать даже при выходе из строя локальной сети. Если же программы находятся на сервере, то необходим обмен информационными и управляющими блоками данных. Такой подход позволяет добиться большей гибкости при сканировании документов.
Вначале для каждого выпускаемого промышленностью сканера программное обеспечение было специфическим, что затрудняло работу с новыми устройствами. Необходимо было иметь системы распознавания текста, пакеты обработки растровых изображений и подобные программы, пригодные для любых моделей сканеров. Поэтому были разработаны программные интерфейсы TWAIN, WIA, ISIS и другие, позволяющие прикладным программам стандартным образом взаимодействовать с драйверами устройств.
Далее – некоторых алгоритмах распознавания символов текстовой информации.
Системы автоматического ввода текста
Существует большое число различных устройств и сопутствующих программ, предназначенных для автоматического ввода текстовой информации, или читающих автоматов (ЧА). По сути, система автоматического ввода текста представляет собой сканер со специальным программным обеспечением, способный «читать» и распознавать отдельные символы. Для чтения документов и преобразования их в пригодный для редактирования вид наиболее распространено оптическое распознавание символов (OCR) — изображение текста считывается посредством сканера, а затем текст распознается программой читающего автомата. Но OCR-программы не позволяют распознавать текст с точностью более 95 — 96%, и даже система, обладающая точностью 99%, совершает одну ошибку на каждые правильно распознанные 100 символов. При средней длине слова в семь символов это означает, что одна ошибка приходится на 10 — 15 слов. Тем не менее программы автоматического распознавания и ввода текста получили широкое распространение.
В основу автоматических систем оптического распознавания текста, ранее называвшихся оптическими читающими автоматами, положен принцип, согласно которому напечатанный на бумаге текст переносится в память компьютера в растровом виде. Это графическое изображение текста может быть прочитано человеком, но не может обрабатываться программами компьютера посимвольно. Для преобразования такой растровой картинки в функциональный текст необходимо выделить и распознать каждый отдельный символ, а затем для обработки в компьютере представить его в виде одного из кодов ASCII или Unicode.
Преобразование текста, прочитанного в растровом виде читающим автоматом, в функциональный вид, пригодный для обработки в компьютере, называют распознаванием.
Слайд 3. Этапы распознавания текста
Процесс распознавания предполагает выполнение нескольких этапов:
осмотр и выделение изображения каждого отдельного символа;
составление описания выделенного изображения символа;
непосредственное распознавание символа, достигаемого сравнением его описания с эталонными описаниями.
Рассмотрим все эти этапы по порядку. Для осмотра символа вначале необходимо выполнить ряд вспомогательных операций – выравнивание строки документа относительно направления осмотра, нормирование размеров изображений символов, центрирование и т. п. Все эти операции производятся программно в процессе предварительной обработки, но могут выполняться и вручную. Операция выравнивания строки относительно направления осмотра выполняется путем выделения нижних элементов всех символов строки и последующего усреднения их положения. Если же используются специальные формуляры, то эта операция упрощается из-за наличия прямых линий, параллельных строкам текста. Для выравнивания строки на визитных карточках и прочих малоформатных документах пользуются их кромками. При распознавании обычных шрифтов необходимо производить нормализацию их размеров и центрировать изображение. Эти операции несколько упрощаются при использовании специальных шрифтов, например стилизованных или нормализованных.
В процессе осмотра производится выделение каждого символа (вокруг символа должно быть «пустое» пространство), а затем осуществляется его дискретизация. Для этого в процессе развертки каждый символ как бы покрывается прямоугольной сеткой. Этот процесс можно сравнить с проецированием изображения символа на сетчатку человеческого глаза. Размер ячеек этой сетки определяется разрешающей способностью читающего автомата. Каждой ячейке ставится в соответствие число, характеризующее интенсивность отраженного от этой ячейки света. Если принять всего два уровня отраженного света — «0» (участок фона) и «1» (участок изображения), то длина полученного описания равна числу ячеек сетки. Это служит первичным описанием изображения символа.
Такое первичное описание символа содержит очень большой объем информации и не очень информативно. Поэтому возникает необходимость выделения из этого описания более информативных, так называемых вторичных признаков. Это геометрические и топологические признаки. К геометрическим признакам можно отнести вертикальные или горизонтальные штрихи в изображении символа (например, в очертании буквы «П»), дуги с выпуклостью вправо или влево (например, в очертании цифр «6» или «9»), штрихи под или над строкой (как в буквах «р» или «h»). К топологическим признакам относят замкнутые контуры нулевой (например, как в букве «О») или первой связности (в цифре «8» из-за наличия пересечения), узлы различной кратности (например, в изображении буквы «А» два нижних конца представляют узлы первой кратности, верхняя часть — узел второй кратности, а точки соединения с горизонтальным штрихом — узлы третьей кратности). Вторичные признаки должны однозначно определять каждый символ, быть инвариантными к его размерам и ориентации на листе бумаги, а также быть нечувствительными к небольшим полиграфическим дефектам. Геометрические признаки не инвариантны к размеру, наклону и центрированию символа, хотя и малочувствительны к полиграфическим дефектам, а топологические признаки инвариантны к размерам и ориентации символа, но зависят от дефектов изображения. Кроме того, они не позволяют различать открывающую «(» и закрывающую «)» скобки, цифры «6» и «9» и т. д. Поэтому всегда вторичное описание символа представляет собой перечисление в определенном порядке как геометрических, так и топологических признаков.
Для распознавания символа необходимо в памяти компьютера хранить эталонные описания всех распознаваемых символов — каждому такому описанию должен быть поставлен в соответствие код символа, являющийся именем этого описания. В процессе распознавания производится сравнение вторичного описания символа с эталонными описаниями всех распознаваемых символов, и вычисляются некоторые меры сходства. В качестве распознанного символа принимается тот, для которого эта мера оказалась наибольшей. Такая последовательность действий по определению мер сходства и выявлению максимального значения носит название алгоритма распознавания. В первых читающих автоматах для реализации этого алгоритма использовались специальные аппаратно-программные средства, но в настоящее время этот алгоритм реализуется самим компьютером. Различные типографские дефекты и плохое качество бумаги не позволяют получить полное совпадение эталонного и вторичного описаний символа. Если мера сходства для какого-либо из эталонных описаний символов в процессе распознавания оказалась значительно больше, чем для других, то именно этот символ и принимается в качестве распознаваемого. Но если меры сходства для двух или нескольких символов оказываются близкими, то распознать предъявленный символ не представляется возможным.