

Глоссарий
Автокоррелограмма – численно и графически автокорреляционную функцию (AКФ), иными словами график изменения коэффициента корреляции
Автокорреляция временного ряда – корреляционная зависимость между последовательными уровнями временного ряда т.е. связь между значениями одного и того же случайного процесса X(t) в моменты времени t1 и t2.
Автокорреляция в остатках представляет собой нарушение одной из основных предпосылок МНК – предпосылки о случайности остатков, полученных по уравнению регрессии т.е. влияние фактора времени будет выражено в корреляционной зависимости между значениями остатков ∆t за текущий и предыдущие моменты времени.
Автокорреляционная функция временного ряда – последовательность коэффициентов автокорреляции уровней первого, второго и т.д. порядков.
Аддитивная модель временного ряда – модель, в которой временной ряд представлен как сумма перечисленных компонент, называется аддитивной моделью временного ряда. Это модель вида: Y=T+S+E, где Т – трендовая компонента, S – циклическая компонента, Е – случайная компонента.
Адекватность модели – модель адекватна объекту-оригиналу, если она с достаточной степенью точности приближения отражает закономерности процесса функционирования реального объекта.
Аналитическое выравнивание временного ряда – способ моделирования тенденции временного ряда: построение аналитической функции, характеризующей зависимость уровней ряда от времени, или тренда.
Валидация модели – проверка соответствия данных, полученных в процессе машиной имитации, реальному ходу явлений, для описания которых создана модель. Производится тогда, когда экспериментатор убедился на предшествующей стадии в правильности структуры (логики) модели. Состоит в том, что выходные данные после расчета на компьютере сопоставляются с имеющимися статистическими сведениями о моделируемой системе.
Вариация – колеблемость, многообразие, изменяемость значения признака у отдельных единиц совокупности явлений.
Временной ряд – совокупность значений какого-либо показателя за несколько последовательных моментов или периодов времени.
Возмущение (случайная величина ε) включает влияние не учтенных в модели факторов, случайных ошибок и особенностей измерения.
Гетероскедастичность модели означает, что условие метода наименьших квадратов не соблюдается т.е. для каждого значения фактора xj остатки εi имеют разную дисперсию.
Гомоскедастичность модели означает, что для каждого значения фактора xj остатки εi имеют одинаковую дисперсию.
Группировка – это разбиение совокупности из группы, однородные по какому-либо признаку или объединение отдельных единиц совокупности в группы, однородные по каким-либо признакам.
Дискретная случайная величина – это величина, которая принимает конечное или счетное множество значений и задается законом распределения, который позволяет установить вероятность любого возможного значения случайной величины
Дисперсионным анализ – метод, основанный на сравнении дисперсий
Дисперсия D(х) случайной величины Х характеризует отклонение (разброс, рассеяние, вариацию) значений случайной величины относительно среднего значения и находится по формуле:
![]() ,
где М (Х) – математическое ожидание
случайной величины Х
,
где М (Х) – математическое ожидание
случайной величины Х
Доверительные интервалы определяют пределы, в которых лежат точные значения определяемых показателей с заданной степенью уверенности, соответствующей заданному уровню значимости α. Для расчета доверительных интервалов для параметров a и b уравнения линейной регрессии определяем предельную ошибку для каждого показателя:
![]() ,
,
![]()
Величина t табл представляет собой табличное значение t-критерия Стьюдента под влиянием случайных факторов при степени свободы k = n–2 и заданном уровне значимости α.
Формулы для расчета доверительных интервалов имеют следующий вид:
![]() ,
,
![]()
Долговременные факторы – неслучайные факторы, формирующие тенденцию.
Закон распределения случайной величины – соотношение, устанавливающее связь между возможными значениями случайной величины и соответствующими им вероятностями.
Замещающая переменная – объясняющая переменная, используемая в регрессии вместо трудноизмеримой, но важной переменной.
Зона неопределенности критерия Дарбина-Уотсона – промежуток значений статистики Дарбина-Уотсона, при попадании в который критерий не дает определенного ответа о наличии или отсутствии автокорреляции первого порядка.
Идентификация – это единственность соответствия между приведенной и структурной формами модели.
Необходимое условие идентифицируемости модели:
Чтобы уравнение было идентифицируемо, необходимо, чтобы число экзогенных переменных (D), отсутствующих в данном уравнении, но присутствующих в системе, было равно числу эндогенных переменных в данном уравнении (H) без одного.
D+1=H – уравнение идентифицируемо;
D+1H – уравнение неидентифицируемо;
D+1H – уравнение сверхидентифицируемо.
Достаточное условие идентифицируемости модели:
Уравнение идентифицируемо, если по отсутствующим в нем экзогенным и эндогенным переменным можно из коэффициентов при них в других уравнениях системы получить матрицу, определитель которой не равен нулю, а ранг матрицы не меньше, чем число эндогенных переменных в системе без одного.
Индекс – это относительная величина сравнения сложных совокупностей, показывающая во сколько раз уровень изучаемого явления в данных условиях (во времени или в пространстве) отличается от уровня того же явления в других условиях.
Интервальный прогноз заключается в построении доверительного интервала прогноза, т. е. нижней и верхней границ уpmin , уpmax интервала, содержащего точную величину для прогнозного значения
![]()
Категория – событие, про которое для каждого наблюдения можно определенно сказать – произошло оно в этом наблюдении или нет.
Ковариация (или корреляционным моментом) Cov (x,y) случайных величин X и Y – математическое ожидание произведения отклонений этих величин от своих математических ожиданий.
Коллинеарность переменных означает, что две переменные находятся между собой в линейной зависимости, если rxixj ≥ 0,7
Коррелированные величины – величины, связанные друг с другом корреляционной связью.
Корреляция – термин, происходящий от английского correlation – соотношение, соответствие (взаимосвязь, взаимозависимость); состоит в том, что средняя величина одного из признаков изменяется в зависимости от значения другого.
Коэффициент вариации случайной величины x – мера относительного разброса случайной величины. Показывает, какую долю среднего значения случайной величины составляет ее средний разброс.
Коэффициент
детерминации (R2)–
характеризует долю дисперсии
результативного признака y, объясняемую
дисперсией, в общей дисперсии
результативного признака. Этот коэффициент
изменяется в пределах от 0 до 1,
![]() Чем ближе R2
к 1, тем качественнее регрессионная
модель, то есть исходная модель хорошо
аппроксимирует исходные данные.
Чем ближе R2
к 1, тем качественнее регрессионная
модель, то есть исходная модель хорошо
аппроксимирует исходные данные.

Коэффициент корреляции величин x и y (rxy)– оценивает тесноту связей изучаемых явлений и находится по формуле:
![]()
![]()
Если: rxy = -1, то наблюдается строгая отрицательная связь;
rxy = 1, то наблюдается строгая положительная связь;
rxy = 0, то линейная связь отсутствует.
Коэффициент регрессии – показывает, насколько в среднем изменяется значение результативного признака при изменении факторного на единицу собственного измерения.
Коэффициент частной корреляции – измеряет влияние на результат фактора xi при неизменном уровне других факторов:
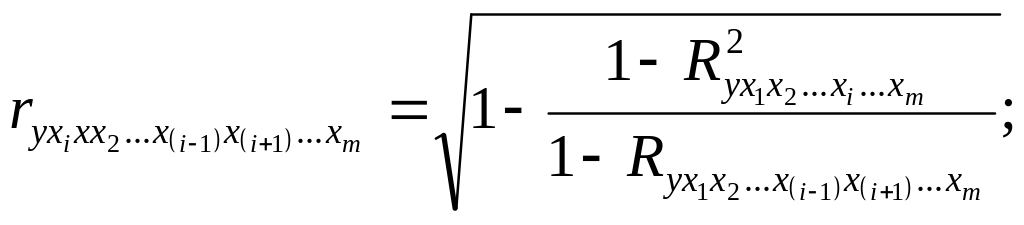
где:
![]() – множественный
коэффициент детерминации всего комплекса
m факторов с результатом;
– множественный
коэффициент детерминации всего комплекса
m факторов с результатом;
![]() – тот
же показатель детерминации, но без
введения в модель фактора xi.
– тот
же показатель детерминации, но без
введения в модель фактора xi.
Коэффициенты «чистой» регрессии – параметры а1 , а2 , аm, характеризующие среднее изменение результата с изменением соответствующего фактора на единицу при неизменном значении других факторов, закрепленных на среднем уровне.
Коэффициенты эластичности – параметры b1, b2 , bm, показывающие на сколько % изменится в среднем результат при изменении соответствующего фактора на 1% и при неизменности действия других факторов.
Критерий Дарбина-Уотсона – метод обнаружения автокорреляции первого порядка с помощью статистики Дарбина-Уотсона.
Критерий Стьюдента (t-критерий) применяется для оценки статистической значимости коэффициентов линейной регрессии и линейного коэффициента парной корреляции rxy. Согласно t-критерию выдвигается гипотеза Н0 о случайной природе показателей, т. е. о незначимом их отличии от нуля. Далее рассчитываются фактические значения критерия tфакт для оцениваемых коэффициентов регрессии и коэффициента корреляции rxy путем сопоставления их значений с величиной стандартной ошибки
![]()
![]()
![]()
Сравнивая фактическое и критическое (табличное) значения t-статистики tтабл и tфакт принимают или отвергают гипотезу Но.
tтабл – максимально возможное значение критерия под влиянием случайных факторов при данной степени свободы k = n–2 и уровне значимости α.
Критерий Фишера (F – критерий) заключается в проверке гипотезы Но о статистической незначимости уравнения регрессии. Для этого выполняется сравнение фактического Fфакт и критического (табличного) Fтабл значений F-критерия Фишера. Fфакт определяется из соотношения значений факторной и остаточной дисперсий, рассчитанных на одну степень свободы:

где n – число единиц совокупности; m – число параметров при переменных. Для линейной регрессии m = 1 .
Для
нелинейной регрессии вместо
![]() используется
.
используется
.
Fтабл – максимально возможное значение критерия под влиянием случайных факторов при степенях свободы k1 = m, k2 = n – m – 1 (для линейной регрессии m = 1) и уровне значимости α.
Если Fтабл Fфакт, то Н0 -гипотеза о случайной природе оцениваемых характеристик отклоняется и признается их статистическая значимость и надежность. Если Fтабл Fфакт, то гипотеза Но не отклоняется и признается статистическая незначимость, ненадежность уравнения регрессии.
Лаг – число периодов, по которым рассчитывается коэффициент автокорреляции.
Лаговые переменные – временные ряды самих факторных переменных, сдвинутые на один или более моментов времени.
Линеаризация – приведение нелинейных функций в линейную зависимость.
Линейная модель – модель, отображающая состояние или функционирование системы таким образом, что все взаимозависимости в ней принимаются линейными.
Лишняя переменная – объясняющая переменная, включенная в модель множественной регрессии, в то время, как по экономическим причинам ее присутствие в модели не нужно.
Математическое ожидание М(Х) дискретной случайной величины х – сумма произведений всех ее значений на соответствующие им вероятности.
Метод Кокрана-Оркатта – компьютерный итерационный метод устранения автокорреляции первого порядка
Метод наименьших квадратов – метод оценивания параметров линейной регрессии, минимизирующий сумму квадратов отклонений наблюдений зависимой переменной от искомой линейной функции. МНК позволяет получить такие оценки параметров, при которых сумма квадратов отклонений фактических значений результативного признака у от теоретических значений ух при тех же значениях фактора x минимальна
Множественная регрессия – регрессия между переменными y и x1, x2, . . . , хm то есть модель вида: y=f(x1, x2, . . . , хm)+ε, где:
y – зависимая переменная (результативный признак),
x1, x2, . . . , хm – независимые, объясняющие, переменные (признак-факторы),
ε – возмущение или стохастическая переменная, включающая влияние неучтенных в модели факторов.
Модель – объект любой природы, который создается исследователем с целью получения новых знаний об объекте-оригинале и отражает только существенные (с точки зрения разработчика) свойства оригинала.
Модель идентифицируема – если все ее структурные коэффициенты определяются однозначно, единственным образом по коэффициентам приведенной формы модели, то есть если число параметров структурной формы модели равно числу параметров приведенной формы модели.
Модель
множественной регрессии –
линейная модель зависимости между
переменными:
![]() ,
содержащая более двух переменных.
,
содержащая более двух переменных.
Модель
множественной регрессии без свободного
коэффициента –
линейная модель зависимости между
переменными:
![]() ,
не содержащая коэффициента
,
не содержащая коэффициента
Модель неидентифицируема – если число структурных коэффициентов больше числа приведенных коэффициентов и следовательно, структурные коэффициенты не могут быть оценены через коэффициенты приведенной формы модели
Модель сверхидентифицируема – если число структурных коэффициентов меньше числа приведенных коэффициентов и следовательно, на основе приведенных коэффициентов можно получить два или более значений одного структурного коэффициента.
Модели временных рядов – модели, построенные по данным, характеризующим один объект за ряд последовательных моментов (периодов)
Моделирование – процесс построения, изучения и применения моделей.
Мультиколлинеарность – высокая взаимная коррелированность объясняющих переменных.
Мультипликативная модель временного ряда – модель вида: Y=T*S*E. Эта модель предполагает, что каждый уровень временного ряда может быть представлен как произведение трендовой (Т), сезонной (S) и случайной (Е) компонент.
Набор категорий – конечный набор взаимоисключающих событий, полностью исчерпывающий все возможности.
Непрерывная случайная величина – это величина, которая принимает все значения из некоторого конечного или бесконечного промежутка и характеризуется плотностью вероятности (плотностью распределения) f(x) – непрерывной функцией, позволяющей вычислить вероятность попадания величины X на интервал (a,b)
Несмещенность оценки – означает, что математическое ожидание остатков равно нулю.
Нестационарный однородный ряд – временной ряд x(t), у которого случайный остаток L (t), получающийся вычитанием из ряда x(t) егог неслучайной составляющей f (t), представляет собой стационарный в широком смысле временной ряд.
Нормальная случайная величина – случайная величина, подчиняющаяся нормальному распределению.
Нестрогая линейная зависимость между переменными – ситуация, когда теоретическая корреляция двух переменных близка к 1 или -1
Общая сумма квадратов отклонений (Sобщ):
![]()
Остаточная сумма квадратов отклонений (S ост) наблюдаемых значений группы от своего группового среднего характеризует рассеяние внутри групп и находится по формуле:
![]()
Отсутствующая переменная – необходимая по экономическим причинам объясняющая переменная, отсутствующая в модели.
Панельные данные – данные нескольких одновременных временных рядов.
Парная регрессия – регрессия между двумя переменными y и x, то есть модель вида: y=f(x)+ε, где:
y – зависимая переменная (результативный признак),
x – независимая, объясняющая, переменная (признак– фактор),
ε – возмущение или стохастическая переменная, включающая влияние неучтенных в модели факторов.
Плоскость
регрессии
– m-мерная
плоскость
![]() в (m+1)-мерном
пространстве
в (m+1)-мерном
пространстве
Полигон распределения вероятностей – ломанная получаемая соединением точек, отложенных значений по оси абсцисс – значения случайных величин, по оси ординат – соответствующие их вероятности.
Полная коллинеарность – явление, когда строгая линейная зависимость между переменными приводит к невозможности применения МНК.
Поправка Прайса-Уинстена – метод спасения первого наблюдения в автокорреляционной схеме первого порядка.
Предопределенные переменные модели – все экзогенные переменные модели и лаговые эндогенные переменные.
Приведенная форма модели – система линейных функций эндогенных переменных от экзогенных:
Y1=δ11x1 +δ12x2 +…+ δ1mxm ;
Y2=δ21x1 +δ 22x2 +…+ δ2mxm ;
………………………………..
Yn=δn1x1 + δn2x2 +…+ δnmxm .
где δij – коэффициенты приведенной формы модели.
Результативный признак – признак, изменяющийся под действием факторных признаков.
Сезонные фиктивные переменные – совокупность фиктивных переменных, предназначенная для обозначения различных лет, времен года, месяцев и т.п.
Система взаимозависимых уравнений (система совместных одновременных уравнений) – система в которой одни и те же зависимые переменные в одних уравнениях входят в левую часть, а в других уравнениях – в правую, то есть система вида:
Y1= b12y2 + b13 y3 +…+ b1n yn + a11 x1 + a12 x2 +…+ a1m xm +ε1;
Y2= b21 y1 +b23 y3 +…+ b2n yn + a21 x1 + a22 x2 +…+ a2m xm +ε2 ;
…………………………………………………………….
Yn= bn1 y1 + bn2 y2 +…+ bnn-1 yn-1 + an1 x1 + an2 x2 +…+ anm xm +εn.
Система независимых уравнений – система, в которой каждая зависимая переменная y рассматривается как функция одного и того же набора факторов x то есть система вида:
Y1=a11 x1 + a12 x2 +…+ a1m xm +ε1;
Y2=a21 x1 + a22 x2+…+ a2m xm +ε2 ;
………………………………..
Yn=an1 x1 + an2 x2 +…+ anm xm +εn.
Система рекурсивных уравнений – система, в которой зависимая переменная одного уравнения выступает в виде фактора x в другом уравнении, то есть система вида:
Y1=a11 x1 + a12 x2 +…+ a1m xm +ε1;
Y2= b21 y1 +a21 x1 + a22 x2 +…+ a2m xm +ε2 ;
Y3= b31 y1 + b32 y2+a31 x1+ a32 x2 +…+ a3m xm +ε3 ;
……………………………………………………………..
Yn= bn1 y1 + bn2 y2 +…+ bnn-1 yn-1 + an1 x1 + an2 x2 +…+ anm xm +εn.
Систематическая вариация – вариация, порождаемая существенными факторами, носит систематический характер, т.е. наблюдается последовательное изменение вариантов признака в определенном направлении
Случайная величина – величина, измеряемая в исследуемых экспериментах, исходы которых заранее неизвестны и зависят от случайных причин.
Случайной вариацией – вариация, обусловленная случайными факторами
Спецификация моделей – один из этапов построения экономико-математической модели, на котором на основании предварительного анализа рассматриваемого экономического объекта или процесса в математической форме выражаются обнаруженные связи и соотношения, а значит, параметры и переменные, которые на данном этапе представляются существенными для цели исследования.
Спецификация переменных – выбор необходимых для регрессии переменных и отбрасывание лишних переменных.
Средний коэффициент эластичности Э показывает, на сколько процентов в среднем по совокупности изменится результат у от своей величины при изменении фактора х на 1 % от своего значения.
Среднее квадратическое отклонение (среднее линейное отклонение) показывает, на сколько в среднем отклоняются конкретные варианты признака от среднего значения. Они выражаются в тех же единицах измерения, что и признак (в метрах, тоннах, рублях и т.д.). Среднее квадратическое отклонение часто используется в качестве единицы измерения отклонений от средней арифметической. В зарубежной литературе этот показатель называется нормированным, или стандартизированным, отклонением.
Средняя ошибка аппроксимации характеризует среднее относительное отклонение расчетных значений от фактических:
![]()
Построенное уравнение регрессии считается удовлетворительным, если значение A не превышает 10–12 %.
Средние коэффициенты эластичности показывают, на сколько процентов в среднем по совокупности изменится результат у от своей величины при изменении фактора х на 1 % от своего значения при неизменных значениях других факторов.
Стандартизованные коэффициенты регрессии (βi) показывают, на сколько сигм (средних квадратических отклонений) изменится в среднем результат, если соответствующий фактор хi изменится на одну сигму при неизменном среднем уровне других факторов.
Стандартное отклонение случайной величины x ( σx ) – мера разброса случайной величины вокруг среднего значения.
![]()
Стандартные ошибки параметров линейной регрессии и коэффициента корреляции определяются по формулам

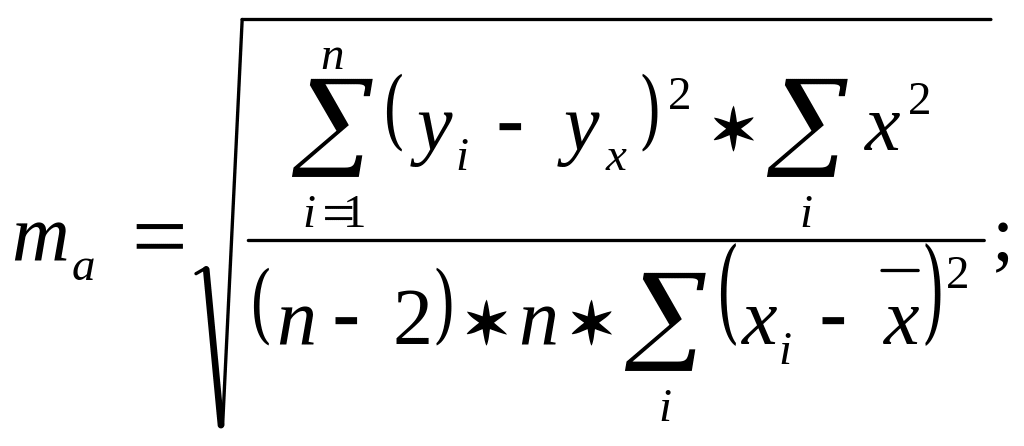
![]()
Стационарные временные ряды – ряды величин x(t), имеющие постоянное среднее значение и колеблющиеся вокруг этого среднего с постоянной дисперсией.
Строгая линейная зависимость между переменными – ситуация, когда выборочная корреляция двух переменных равна 1 или -1
Точечный
прогноз
заключается в получении прогнозного
значения уp,
которое определяется путем подстановки
в уравнение регрессии
![]() соответствующего (прогнозного) значения
xp.
соответствующего (прогнозного) значения
xp.
Трендовая модель – динамическая модель, в которой развитие моделируемой экономической системы отражается через тренд ее основных показателей (в частности, тренд средних величин этих показателей, их дисперсии, минимальных или максимальных уровней).
Уровень значимости α – вероятность отвергнуть правильную гипотезу при условии, что она верна. Обычно величина α принимается равной 0,05 или 0,01.
Устойчивость модели – свойство модели, характеризующее ее способность обеспечить результаты расчетов (выходные данные), отклоняющиеся от идеальных данных на допустимо малую величину. При этом в качестве идеальных подразумеваются выходные данные, получаемые в таких условиях, когда модель реализует записанные в ней математические зависимости абсолютно без помех; соответственно, реальные выходные данные получаются в условиях определенных возмущающих воздействий.
Факторная сумма квадратов отклонений (Sфакт) групповых средних от общей средней характеризует рассеяние между группами и находится по формуле:
![]()
Факторный признак – это признак, оказывающий влияние на изменение результативного.
Фиктивная переменная – переменная, принимающая в каждом наблюдении только два значения: 1– «да» или 0 – «нет».
Фиктивная переменная взаимодействия – фиктивная переменная, предназначенная для установления влияния на регрессию одновременного наступления нескольких независимых друг от друга событий, каждое из которых описывается своей фиктивной перменной.
Функциональные модели – один из двух основных типов экономико-математических моделей (при их квалификации по способам выражения соотношений между внешними условиями, внутренними параметрами и искомыми характеристиками моделируемого объекта) наряду со структурными моделями. Функциональная модель описывает поведение системы безотносительно к ее внутренней структуре.
Частота – абсолютное число, показывающее, сколько раз (как часто) встречается в совокупности то или иное значение признака или, что то же самое, сколько единиц в совокупности обладают тем или иным значением признака.
Член временного ряда – наблюдение экономического показателя одного объекта в некоторый момент времени.
Экзогенные переменные в модели – переменные, задаваемые «извне», автономно от модели, управляемые и планируемые.
Эконометрика – «экономика» + «метрика». Это наука об измерении и анализе экономических явлений, о количественных выражениях тех связей и соотношений, которые раскрыты и обоснованы экономической теорией. Это сплав четырех компонент: экономической теории, статистических и математических методов, компьютерных вычислений.
Эконометрическая модель – вероятностно – статистическая модель, описывающая механизм функционирования экономической или социально-экономической системы.
Экономико-математическое моделирование – описание экономических процессов и явлений в виде экономико-математических моделей. (Иногда тем же термином обозначают также реализацию экономико-математической модели на ЭВМ).
Экономическая интерпретация модели – основные выводы и заключения на основе расчета и анализа частных коэффициентов эластичности, частных и множественного коэффициентов детерминации, Q-коэффициента.
Экономический смысл параметров уравнения линейной парной регрессии: Параметр b показывает среднее изменение результата y с изменением фактора x на единицу. Параметр a=y, когда x=0. Если x не может быть равен 0, то a не имеет экономического смысла. Интерпретировать можно только знак при а: если а0, то относительное изменение результата происходит медленнее, чем изменение фактора, то есть вариация результата меньше вариации фактора: VyVx, и наоборот.
Эндогенные переменные модели – переменные, значения которых формируются в процессе и внутри функционирования анализируемой социально – экономической системы в существенной мере под воздействием экзогенных переменных и во взаимодействии друг с другом. В эконометрическом моделировании являются предметом объяснения.
Эталонная категория – категория, с которой сравниваются другие категории.