

14. Сред и предельная ошибки выборочного набл.
Каждый вид выборки определяется целями исслед, при которых достигается наименьшая ошибка репрезентативности. Расчет стандартных ошибок разработан математической ст-кой и эти ошибки рассчитываются для двух параметров - выборочной средней и выборочной доли.
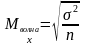
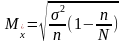
Стандартная ошибка для бесповторного отбора всегда меньше, чем для повторного отбора.
Аналогично для стандартной ошибки доли:
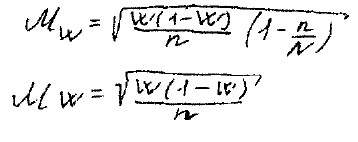
В этих Ф-лах предполагается, что дисперсия относ к ген совок-ти. Как правило, эта велич неизвестна.
Математически доказано, что выборочная дисперсия имеет определённое соотношение с дисперсией ген совок-тью:
![]()
При большом числе наблй n, вся дробь стремиться к 1, поэтому в этих Ф-лах в качестве дисперсии используется выбороч дисперсия.
![]()
Вышеуказанные формулы разработаны для собственного случайного и механического отбора.
Помимо стандартной ошибки репрезентативности необходимо вычислить предельную ошибку выборочной средней и выборочной доли.
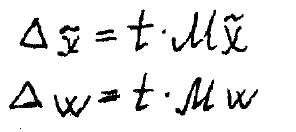
Критерий t - критерий доверия, заданный с определённой вероятностью, согласно интегральной функцией Лапласа.
![]()
На практике при организации выборочного набл возн пробл, что принять в качестве дисперсии. В таких случаях приняты следующие варианты выбора дисперсии:
1. Используя опыт аналогичных наблй, принимают сигму, равную:
![]()
2. Если распределение данных генеральной совок-ти предполагается асимметричным, то сигма будет равна:
![]()
З.Если распределение предполагается умеренно асимметричным (приближение к нормальному распределению), то:
![]()
На подготовительной стадии проведения выборки исследователь задаёт предполагаемые значения доверительной вероятности, стандартные ошибки, и отсюда определяется предполагаемая численность выборки.
![]()
Для бесповторной выборки Ф-ла корректируется на велич Vа генеральной совок-ти.
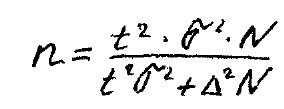
Иногда, вместо значения предельной ошибки выборки задаётся желаемая (предполагаемая) ошибка в виде относительной величы в процентах:
![]()
В таких случаях расчёт Vа выборки имеет другую формулу:
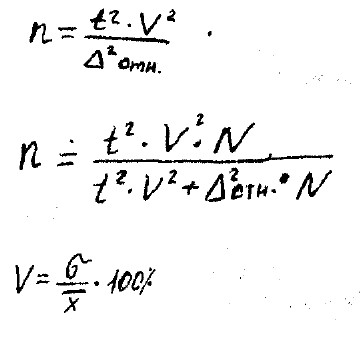
V - коэффициент вариац в процентах.
Как было сказано ранее, выборочное набл может осуществляться по различным схемам. Соответственно, меняется методика расчета стандартных ошибок, что связано с расчётом с дисперсией.

15. Определение необходимой численности выборки.
Обьем выборки определяется след Ф-лами:
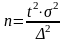 ,
для повторн.
,
для повторн.
Если процентный обьем выборки не превышает 5% от численности ген сов-сти, к след форм-ле можно не переходить, это существенно не скажется на результате
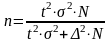 ,
для бесповт.
,
для бесповт.
В
качестве оценок генер дисперсии (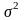 )
можно использовать след соотнош
)
можно использовать след соотнош
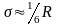 -для
нормального распределения
-для
нормального распределения
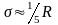 -для
асимметричного распределения.
-для
асимметричного распределения.
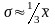
R-размах=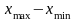
В качестве оценки ген дисперсии доли используют максимально возможную дисперсию альтернативного признака.
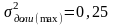
16. Малая выборка
Выборочное набл, которое составляет менее 30 ед., получило назв малой выборки
Необходимость использования малой выборки связана, главным образом, с понятием производственного эксперимента, а так же, зачастую, с невозможностью получить большее число наблй в силу специфики изучаемого явл.
Однако, малая выборка, в отличие от нормальной выборки, связана с особенностями расчета нормальных ошибок и доверительных интервалов.
Дело в том, что при сокращении числа наблй хар-р изучаемых ед. совок-тей резко отличается от нормального распределения Лапласа. Поэтому, английским математиком и ст-ком Госсеном (псевдоним Стьюдент) были разработаны значения t-критерия для нормированных велич, распределение которых при числе наблй от 30-и до 100 приближается к нормальному, а при 100 и более -полностью соответствуют нормальному.
![]()
На основе малой выборки доверительные интервалы можно определить лишь при условии, что генеральная совок-ть имеет нормальное распределение ошибок. Распределение Стьюден-та явл так же симметричным, только более пологим. В этом распределении только один параметр - df -число степеней свободы изучаемого признака.
Для малой выборки это число степеней свободы равно n-1, так как оно представляет то число значений признака, которое необходимо для расчёта средней величы и дисперсии.
![]()
Предельная ошибка равна:
w=t*S