

4. Кодирование сообщений при передаче по каналу без помех возможность оптимального (эффективного) кодирования
Под кодированием будем понимать отображение состояний некоторой системы (источника сообщений) с помощью состояний сложного сигнала, который представляет собой последовательность из п элементарных сигналов. Множество У состояний элементарного сигнала образует алфавит кода размера ту. При ту=2 элементарный сигнал имеет два состояния, которые обозначим через 1 и 0. Состояние сложного сигнала описывается последовательностью из нулей и единиц, которая называется кодовым словом. Если кодовые слова имеют разную длину, то код называется неравномерным, а если одинаковую, то код называется равномерным .
Пусть источник
сообщений вырабатывает последовательность
из k
букв, причем xi
буква в этой последовательности
появляется пi
раз. Каждой букве
![]() поставим
в соответствие кодовое слово с длиной,
равной li
(посимвольное кодирование). Тогда длина
соответствующей последовательности
из кодовых слов будет равна
поставим
в соответствие кодовое слово с длиной,
равной li
(посимвольное кодирование). Тогда длина
соответствующей последовательности
из кодовых слов будет равна
![]()
Это равенство можно представить в виде
![]()
При неограниченном увеличении числа букв К в последовательности относительная частота появления xi буквы с вероятностью, равной единице, совпадает со значением вероятности pi появления этой буквы. Поэтому с вероятностью, равной единице, выполняется равенство
![]()
где
![]() —
по определению средняя длина кодового
слова. Длина последовательности кодовых
слов L
является случайной величиной, но
значительные отклонения ее от среднего
значения
—
по определению средняя длина кодового
слова. Длина последовательности кодовых
слов L
является случайной величиной, но
значительные отклонения ее от среднего
значения
![]() маловероятны при неограниченном
возрастании К.
маловероятны при неограниченном
возрастании К.
Таким образом,
источник сообщений с вероятностью,
равной единице, вырабатывает типичные
последовательности, длина которых мало
отличается от их среднего значения К
![]() .
.
Поскольку время
передачи сообщений определяется длиной
L
, то
имеется возможность его сокращения за
счет уменьшения средней длины кодового
слова
![]() .
Задача
оптимального кодирования заключается
в определении однозначно декодируемых
кодовых слов с такими длинами, при
которых их средняя длина минимальна.
.
Задача
оптимального кодирования заключается
в определении однозначно декодируемых
кодовых слов с такими длинами, при
которых их средняя длина минимальна.
Префиксные коды
При неравномерном коде в длинной последовательности кодовых слов не всегда удается определить начало и конец переданной буквы.
Однако однозначное декодирование всегда имеет место в случае применения кодов, обладающих свойством префикса (приставки). Код обладает свойством префикса, если ни одно кодовое слово не является началом (приставкой) какого-либо другого кодового слова.









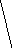
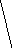
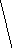
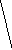
 Все множество
кодовых слов, максимальная длина которых
не превосходит число, равное
l,
геометрически удобно изобразить в виде
узлов дерева (рис.
2). Дерево
представляет собой множество точек
(узлов), соединенных отрезками, которые
называются ребрами дерева. Из каждого
узла выходят my
ребер, каждое из которых изображает
соответствующий символ алфавита
кода. Слова, состоящие всего из одной
буквы, изображаются узлами первого
порядка. Их число равно my.
Слова, состоящие из двух букв, изображаются
узлами второго порядка и т. д. Причем
узлов (слов) К-го
порядка в
my
раз больше, чем узлов (К-1)-го
порядка, поскольку каждый узел предыдущего
порядка порождает my
узлов
следующего порядка. Конкретный вид
кодового слова определяется по
изображающему его узлу как последовательность
ребер (букв), которые соединяют основание
дерева с указанным узлом. В случае
префиксных кодов на пути, соединяющем
основание дерева с изображающим узлом,
не может быть промежуточных изображающих
узлов.
Все множество
кодовых слов, максимальная длина которых
не превосходит число, равное
l,
геометрически удобно изобразить в виде
узлов дерева (рис.
2). Дерево
представляет собой множество точек
(узлов), соединенных отрезками, которые
называются ребрами дерева. Из каждого
узла выходят my
ребер, каждое из которых изображает
соответствующий символ алфавита
кода. Слова, состоящие всего из одной
буквы, изображаются узлами первого
порядка. Их число равно my.
Слова, состоящие из двух букв, изображаются
узлами второго порядка и т. д. Причем
узлов (слов) К-го
порядка в
my
раз больше, чем узлов (К-1)-го
порядка, поскольку каждый узел предыдущего
порядка порождает my
узлов
следующего порядка. Конкретный вид
кодового слова определяется по
изображающему его узлу как последовательность
ребер (букв), которые соединяют основание
дерева с указанным узлом. В случае
префиксных кодов на пути, соединяющем
основание дерева с изображающим узлом,
не может быть промежуточных изображающих
узлов.
3






2


1
Рис. 2 Полное троичное (mx=3) кодовое дерево третьего
порядка (l=3): 1, 2, 3 - узлоы первого, второго, третьего порядков
Поскольку с помощью дерева (рис. 2) можно изобразить все кодовые слова с длиной, меньшей или равной l, то оно называется полным деревом порядка l с алфавитом объема ту.