

Министерство образования и науки Российской Федерации
Казанский государственный технический университет им.А.Н.Туполева
И.С.Ризаев
СИСТЕМЫ РАСПРЕДЕЛЕННОЙ ОБРАБОТКИ ДАННЫХ
Учебное пособие
Казань 2009
УДК 681.3.06(075.8)
Ризаев И.С. Системы распределенной обработки данных: Учебное пособие. - Казань: 2009. - с.
В учебном пособии дается классификация систем распределенной обработки данных, модели удаленного доступа, архитектура систем управления распределенными базами данных, проблемы параллельных процессов. Также рассматриваются вопросы безопасности данных, средства предоставления привилегий на языке SQL. Язык программирования PL/SQL в среде СУБД ORACLE. Многомерное представление данных и хранилище данных. Язык HTML в системе WWW как средства доступа к информации в глобальной сети Internet.
Пособие ориентировано на студентов, обучающихся по направлению “Информационные системы“.
Введение
Учебно-методический комплекс (УМК) соответствует дисциплине «Системы распределенной обработки данных» инновационного учебного плана по направлению 230200 «Информационные системы». Данная дисциплина читается на 4 курсе и является продолжением и развитием курса «Управление данными» (аналогичный курс «Базы данных» имеется в учебном плане 230100 – Информатика и ВТ), который читается для студентов 2-го курса.
УМК ориентирован на подготовку специалистов по профессиям «Системный архитектор», «Специалист по информационным системам», «Администратор баз данных» в соответствии с квалификационными требованиями стандарта Standart Occupational Classification (SOC).
Предметом данного курса является распределенная обработка данных. Как правило, термины «распределенная обработка» и «параллельная обработка» считаются синонимами. Однако, когда говорят только о параллельной обработке как правило понимают под этим распараллеливание процессов на многопроцессорных машинах. Когда используют термин «распределенная обработка», то обычно понимается процесс распараллеливания процессов в сетях. В настоящее время исследования в области распределенной обработки заключаются в создании и обслуживании распределенных баз данных и проектировании приложений, позволяющих организовать распределенные вычисления.
Основное назначение данного курса - систематическое введение в идеи и методы, используемые в современных системах распределенной обработки данных.
В первой главе рассматриваются методы и подходы к распределенной обработке данных. Рассматривается переход от монопроцессорных машин с фоннеймановской архитектурой к мультипроцессорным машинам, мультимашинная архитектура, как совокупность компьютеров, связанных в сеть. Модели удаленного доступа. Архитектура «клиент-сервер».
Во второй главе приведено описание распределенных БД. Факторы, стимулирующие развитие распределенной обработки данных. Критерии построения РБД. Классификация и стратегия обработки и размещения данных по узлам сети. Свойства, которым по К.Дейту, должны удовлетворять РБД. В качестве основы этого описания были представлены двенадцать целей распределенной базы данных, хотя при этом отмечалось, что их достижение не всегда оправдано.
Рассматривается архитектура системы управления РБД и приводится построения РБД на примере ВУЗа.
Третья глава посвящена проблемам параллельных процессов. Показано, что единицей взаимодействия с базой данных является транзакция. Рассматриваются свойства транзакций, обеспечивающие живучесть баз данных. Конфликты транзакций, возникающие при параллельных процессах и пути их решения. Показано, что для ускорения обработки данных, необходимо, что бы расписание выполнялось параллельно, но при этом результат должен соответствовать последовательному расписанию.
В четвертой главе рассматривается структурированный язык запросов SQL, как продолжение тех вопросов, которые рассматривались ранее на младших курсах в дисциплинах «Управление данными» и «Базы данных». Здесь язык SQL рассматривается в плане его применения в системах MS SQL Server и Oracle, как встроенный язык с использованием понятия курсора.
Пятая глава посвящена мерам безопасности баз данных. В ней рассматриваются причины возможных опасностей и пути устранения. Показано, что для этих целей могут быть использованы пароли, представление данных, предоставление полномочий, введение ограничений целостности и даже кодирование.
В шестой главе приводится информация о таком новом понятии, как хранилище данных. Из-за огромного количества информации очень малая ее часть будет когда-либо увидена человеческим глазом. Надежда, это применение технологий OLAP и Data Mining.
Седьмая глава посвящена применению Web-технологии для доступа к базам данных в Интернете. Рассматриваются средства взаимодействия сценарии и возможные языки сценариев.
В восьмой главе рассматривается распределенная СУБД ORACLE. Системная глобальная область – SGA. Программная область - PGA. Табличные пространства. Структурированный язык запросов SQL. Основные операторы. Запросы. Операторы DML. Стандартные функции. Встроенный SQL. Оптимизация запросов. Процедурный язык PL/SQL ORACLE. Среда программирования. Команды управления в PL/SQL. Процедуры и функции. Выполнение запросов в ORACLE. Схема взаимодействия клиентских приложений с машиной
1. Методы распределенной обработки данных
Прогресс в области средств вычислительной техники предоставил широкие возможности в области средств управления и обработки данных.
В целях увеличения вычислительных возможностей и для достижения большего параллелизма по сравнению с мультипрограммированием, предлагаемым операционными системами, на классические монопроцессорные машины с фон-неймановской архитектурой были установлены дополнительные процессоры. Системы, разработанные для мультипроцессорных машин, называются параллельными операционными системами (Parallel Operating Systems). Мультипроцессорные машины подразделяются на два семейства: - жестко связанные или жестко соединенные мультипроцессоры (tightly coupled), в которых процессоры связаны через общую память (рис.1.1.); - слабо связанные или слабо соединенные мультипроцессоры (loosely coupled), в которых процессоры связаны через средство связи (как правило, шину), отличное от общей памяти (рис.1.2.).
Необходимо отметить, что эти виды архитектуры могут сочетаться между собой: каждый процессор может обладать локальной памятью и делить с остальными общую память. Кроме того, в настоящее время процессоры обладают одним или двумя уровнями кэширования...
 Рис1.1.
Жестко связанные мультипроцессоры
Рис1.1.
Жестко связанные мультипроцессоры
 Рис
1.2.Слабо связанные процессы
Рис
1.2.Слабо связанные процессы
Появление сетей, предназначенных для взаимной связи различных компьютеров, привело к разработке средств, а затем и операционных систем, позволяющих осуществлять управление, так называемой, мультимашинной архитектурой (рис.1.3.), то есть совокупности полносоставных компьютеров (процессоры, память, вводы-выводы...), связанных в сеть. В этом случае речь идет о распределенных вычислительных системах.
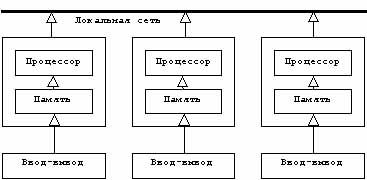 Рис
1.3.Мультимашинная организация
Рис
1.3.Мультимашинная организация
Следует отметить большое сходство между мультимашинной организацией и архитектурой слабо связанных мультипроцессоров; в обеих структурах процессоры связаны через канал связи, а не через общую память. Различия заключаются в следующем: - в случае распределенных систем (мультимашинная архитектура) связь между процессорами осуществляется относительно медленно (сеть), а системы независимы; - в случае параллельных систем (мультипроцессорная архитектура) связь осуществляется быстро (шина), а системы относительно сильно связаны между собой.
Возможность взаимодействия подразумевает понятие "открытых систем", то есть систем, способных к коммуникации в неоднородной среде.
Распределенная обработка данных, таким образом, представляет собой программу, выполнение которой осуществляется несколькими системами, объединенными в сеть. Как правило, расчетная часть программы выполняется на мощном процессоре, а визуальное отображение выводится на рабочей станции с улучшенной эргономичностью. Разделение опирается на модель "клиент-сервер".
1.1. Цели распределенной обработки данных
Целью распределенной обработки данных является оптимизация использования ресурсов и упрощение работы пользователя. Что достигается за счет следующих методов или средств;
- Оптимизация использования ресурсов.
Термин ресурс, в данном случае используется в самом широком смысле: мощность обработки (процессоры), емкость накопителей (память или диски), графические возможности (2-х или 3-х мерный графический процессор, в сочетании с растровым дисплеем и общей памятью), периферийные устройства вывода на бумажный носитель (принтеры, плоттеры). Эти ресурсы редко бывают собраны на одной машине: Одна ЭВМ обладает мощными расчетными возможностями, но не имеет графических возможностей, а также возможностей эффективного управления данными. Отсюда принцип совместной работы различных систем, используя лучшие качества каждой из них, причем пользователь имеет их в распоряжении при выполнении только одной программы.
- Упрощение работы пользователя.
Действительно, распределенная обработка данных позволяет: - повысить эффективность посредством распределения данных и видов обработки между машинами, способными наилучшим образом управлять ими; - предложить новые возможности, вытекающие из повышения эффективности; - повысить удобство пользования. Пользователю более нет необходимости разбираться в различных системах и осуществлять перенос файлов.
Основные недостатки этого подхода заключаются в следующем: - зависимость от характеристик и доступности сети. Программа не сможет работать, если сеть повреждена. Если сеть перегружена, эффективность уменьшается, а время реакции систем увеличивается. - проблемы безопасности. При использовании нескольких систем увеличивается риск, так как появляется зависимость от наименее надежной машины сети.
C другой стороны, преимущества весьма ощутимы: - распределение и оптимизация использования ресурсов. Это основная причина внедрения распределенной обработки данных; - новые функциональные возможности и повышение эффективности при решении задач; - гибкость и доступность. В случае поломки одной из машин, ее пытаются заменить другой, способной выполнять те же функции.
Распределение и параллелизм
Следует отметить, что распределение (или разделение) не является синонимом параллелизма. Распределение видов обработки состоит в том, чтобы поручить их машинам, которые наилучшим образом, приспособленным к этому. Параллелизм подразумевает понятие одновременности обработки. Распределение позволяет иногда проводить параллельную обработку.
Прозрачность
Прозрачностью называется возможность доступа к ресурсам или услугам, не зная их местонахождения. С точки зрения прикладного программиста, речь идет о возможности использования одинаковых примитивов доступа, независимо от местонахождения службы или необходимого ресурса. У пользователя имеется только один прикладной интерфейс, и он видит перед собой только один компьютер. С более концептуальной точки зрения, прозрачность определяется как возможность видеть систему как единый организм, а не как собрание независимых друг от друга объектов. Различают несколько разновидностей прозрачности, в частности: - прозрачность доступа: к локальным или удаленным объектам можно обращаться посредством одинаковых операций; - прозрачность местонахождения: объекты должны быть доступны без необходимости знать их физическое местоположение; - прозрачность одновременности доступа: несколько пользователей должны иметь возможность одновременного доступа к данным, без нежелательных последствий; - прозрачность копирования: должна существовать возможность копировать данные из файлов или из других объектов в целях повышения эффективности или обеспечения доступности незаметно для пользователей; - прозрачность при неисправностях: пользователи или прикладные программы должны иметь возможность завершить свои задания, даже в случае неисправностей аппаратной или программной части; - прозрачность при динамических изменениях конфигурации: система может динамически менять свою конфигурацию, в целях повышения эффективности и в зависимости от нагрузки.
1.2. Модель "КЛИЕНТ-СЕРВЕР"
Клиентом называется объект, запрашивающий доступ к службе или ресурсу. Сервер - это объект несущий службу или обладающий ресурсом.
Клиент и сервер могут находиться на одной и той же машине (использование локальных механизмов коммуникации) или на двух разных машинах (использование сетевых средств). В рамках нашего исследования, клиентом и сервером являются два процесса UNIX, связанные между собой через механизм IPC (Interprocess Communication), локальный или сетевой (рис.1.4.).
 Рис
1.4. Модель клиент-сервер
Рис
1.4. Модель клиент-сервер
Клиент и сервер не играют в данном случае симметричную роль. Процесс-сервер инициализируется и, затем, переходит в состояние ожидания запросов от возможных клиентов. Как правило, процесс-клиент запускается в интерактивном режиме и посылает запросы серверу. Сервер исполняет полученный запрос, причем это может подразумевать диалог с клиентом, а может, и нет. Затем сервер вновь переходит в состояние ожидания других клиентов.
Различают два типа процессов-серверов: - итеративные серверы: процесс-сервер сам обрабатывает ответ. Этот тип сервера используется в случае, если время обработки весьма непродолжительно или если сервер используется единственным клиентом; - параллельные серверы: процесс-сервер вызывает для обработки вызова клиента другой процесс. Этот процесс создается системным вызовом fork (). Порождающий процесс не блокируется по окончании выполнения порожденного процесса и может, таким образом, ждать другие запросы.
С каждым сервером связан служебный (сервисный) адрес. Клиент посылает запросы по этому адресу. В зависимости от вида осуществляемой обработки данных, различают серверы без состояния (stateless) и серверы с состоянием (statefull). Сервер без состояния не сохраняет о своих клиентах никакой информации. Сервер с состоянием сохраняет информацию о состоянии своих клиентов после каждого запроса. В случае разрыва связи, повторный запуск проще у серверов без состояния, но иногда это может привести к случайным срабатываниям.