

1.3 Метод простого рехэширования
Для организации таблицы идентификаторов
по методу рехэширования необходимо
определить все хэш-функции
![]() для всех
для всех![]() Чаще всего функции
Чаще всего функции![]() определяют как некоторую модификацию
хэш-функцииh. Например,
самым простым методом вычисления функции
определяют как некоторую модификацию
хэш-функцииh. Например,
самым простым методом вычисления функции![]() является ее организация в виде
является ее организация в виде
![]() (1)
(1)
где
![]() — некоторое вычисляемое целое число,
а
— некоторое вычисляемое целое число,
а![]() —
максимальное значение из области
значений хэш-функцииh.
В данной работе положим
—
максимальное значение из области
значений хэш-функцииh.
В данной работе положим![]() .
Тогда получаем формулу
.
Тогда получаем формулу
![]() (2)
(2)
В этом случае при совпадении значений
хэш-функции для каких-либо элементов
поиск свободной ячейки в таблице
начинается последовательно от текущей
позиции, заданной хэш-функцией
![]() .
.
Блок-схема метода простого рехэширования представлена на рисунке 1.1.

Рис. 1.1 – Блок-схема метода простого рехэширования; а) – Блок-схема алгоритма простого рехэширования;б) – Блок-схема функции поиска идентификатора;
в) – Блок-схема функции добавления идентификатора
1.4 Метод цепочек
Блок-схема метода цепочек списка представлена на рисунке 1.2

Рис. 1.2 – Блок-схема метода цепочек; а) – Блок-схема алгоритма метод цепочек;
б) – Блок-схема функции добавление идентификатора;в) – Блок-схема функции поиска идентификатора
1.5 Результат выполнения программы
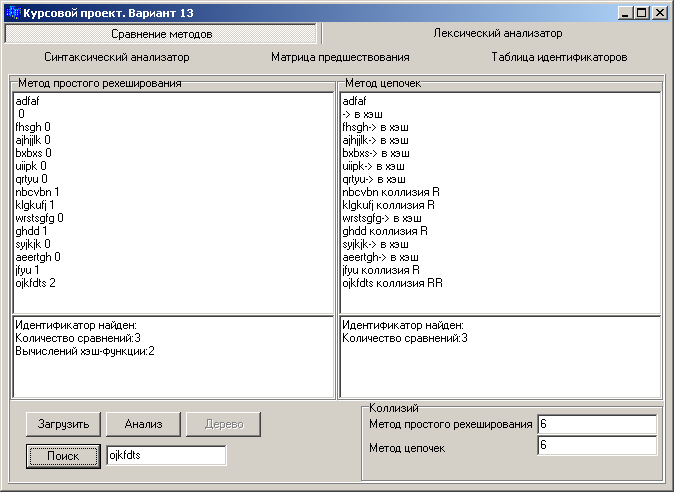
Рис. 1.3 – Результаты сравнения методов организации таблицы идентификаторов
При поиске идентификаторов в таблицах организованных методом простого рехэширования и методом цепочек было установлено, что количество сравнений в обоих методах одинаково. Но в отличие от метода простого рехэширования, в методе цепочек не нужно вычислять хэш-функцию при возникновении коллизии, поэтому метод цепочек можно признать наиболее эффективным.
1.6 Вывод
Для сравнения методов организации таблицы идентификаторов был разработан модуль, иллюстрирующий их работу.
Было выявлено, что метод цепочек является более эффективным, чем метод простого рехэширования, так как алгоритм, основанный на методе цепочек не требует вычисления хэш-функции идентификатора при возникновении коллизии.
В дальнейшем для заполнения таблицы идентификаторов исходной программы будем использовать метод цепочек.
2 Проектирование лексического анализатора
2.1 Исходные данные
Текст на входном языке задается в виде символьного (текстового) файла. Программа должна выдает сообщения о наличие во входном тексте ошибок, которые могут быть обнаружены на этапе лексического анализа.
Предусмотрены следующие варианты операторов входной программы:
оператор присваивания вида <переменная>:=<выражение>;
условный оператор вида if <выражение>then<оператор>
либо if<выражение>then<оператор>else<оператор>;
составной оператор вида begin...end;
оператор цикла while<выражение>do<оператор> ;
операции сложения (+), вычитания (-), умножение (*), деление(/);
операции сравнения «меньше» (<), «больше» (>), «равно» (=);
логические операции and, or, not;
операндами в выражениях могут выступать идентификаторы и константы;
все идентификаторы должны восприниматься как переменные.
2.2 Назначение лексического анализатора
Лексический анализатор (или сканер) – это часть компилятора, которая читает литеры программы на исходном языке и строит из них слова (лексемы) исходного языка. На вход лексического анализатора поступает текст исходной программы, а выходная информация передается для дальнейшей обработки компилятором на этапе синтаксического анализа и разбора.
В основном лексические анализаторы выполняют исключение из текста исходной программы комментариев и незначащих пробелов, а также выделение лексем следующих типов: идентификаторов, строковых, символьных и числовых констант, ключевых (служебных) слов входного языка.