

Лабораторная работа №2 / Отчет 2-1
.docУфимский Государственный Авиационный Технический Университет
Кафедра ТК
Отчет по лабораторной работе №2
Проектирование лексического анализатора
по курсу «Системное программное обеспечение»
Выполнил:
студент группы Т28-420
Принял: к.т.н.,
ст. преподаватель
Карамзина А.Г.
Уфа-2005
Цель работы: изучение основных понятий теории регулярных грамматик, ознакомление с назначением и принципами работы лексических анализаторов (сканеров), получение практических навыков построения сканера на примере заданного простейшего входного языка.
Задание: написать программу, которая выполняет лексический анализ входного текста в соответствии с заданием и порождает таблицу лексем с указанием их типов и значений. Текст на входном языке задается в виде символьного (текстового) файла.
Входной язык содержит операторы условия типа if … then … else и if … then, разделенные символом ;(точка с запятой). Операторы условия содержат идентификаторы, знаки сравнения <, >, =, десятичные числа с плавающей точкой (в обычной и логарифмической форме), знак присваивания (:=).
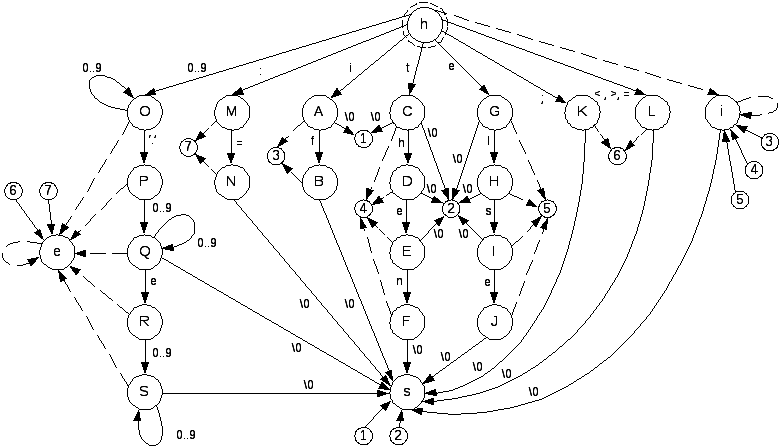
Описание КС - грамматики входного языка
G( {0,1,2,3,4,5,6,7,8,9,e,f,h,i,n,l,s,t,#,’:’,’=’, ‘;’, ‘<‘, ‘>’}, {A,B,C,D,E,F,G,H,I,J,K,L,i,O,P,Q,R,S,e,s}, P,S)
P:
|
A→ i B→Af C→t D→Ch E→De F→En G→e P→O. |
H→Gl I→Hs J→Ie K→; L→ < | > | = M→ : N→ = R→Qe |
O→ 0|1|2|3|4|5|6|7|8|9|O0|O1|O2|O3|O4|O5|O6|O7|O8|O9|
Q→ P0|P1|P2|…|P9|Q0|Q1|Q2|…|Q9|
S→ R0| R1| R2|… R9| S0| S1| S2|…|S9|
i→h*|i*|A*|B*|C*|D*|E*|F*|G*|H*|I*|J*
s→i#|B#|F#|J#|K#|L#|N#|Q#|S#|A#|C#|D#|E#|G#|H#|I#|
i* - множество всех символов
h*- множество всех символов, крoме терминальных символов
A*- множество всех символов, кроме #, f
B*- множество всех символов, кроме #
C*- множество всех символов, кроме #, h
D*- множество всех символов, кроме #, e
E*- множество всех символов, кроме #, n
F*- множество всех символов, кроме #
G*- множество всех символов, кроме #, i
H*- множество всех символов, кроме #, s
I*- множество всех символов, кроме #, e
J*- множество всех символов, кроме #
Листинг программы:
//---------------------------------------------------------------------------
#include <vcl.h>
#include <stdio.h>
#pragma hdrstop
#include "Unit1.h"
//---------------------------------------------------------------------------
#pragma package(smart_init)
#pragma resource "*.dfm"
TForm1 *Form1;
//---------------------------------------------------------------------------
__fastcall TForm1::TForm1(TComponent* Owner)
: TForm(Owner)
{
sgrTable->Rows[0]->Add("Лексема");
sgrTable->Rows[0]->Add("Тип лексемы");
sgrTable->Rows[0]->Add("Цепочка ");
}
//---------------------------------------------------------------------------
String TForm1::Conclude(char X)
{
if(X=='L') return("Знак сравнения");
if(X=='K') return("Разделительный символ");
if(X=='B' || X=='F' || X=='J') return("Оператор условия");
if(X=='Q') return("Десятичное число в обычной форме");
if(X=='S') return("Десятичное число в лог. форме");
if(X=='N') return("Знак присваивания");
else return("Идентификатор");
}
String TForm1::Analiz(char *wInput)
{
int i = 0;
String Way= "h";
char State = 'h';
do {
switch (State) {
case 'h':
switch (wInput[i]) {
case 'i' : State = 'A'; break;
case 't' : State = 'C'; break;
case ':' : State = 'M'; break;
case 'e' : State = 'G'; break;
case ';' : State = 'K'; break;
case '>' : State = 'L'; break;
case '<' : State = 'L'; break;
case '=' : State = 'L'; break;
case '0' : State = 'O'; break;
case '1' : State = 'O'; break;
case '2' : State = 'O'; break;
case '3' : State = 'O'; break;
case '4' : State = 'O'; break;
case '5' : State = 'O'; break;
case '6' : State = 'O'; break;
case '7' : State = 'O'; break;
case '8' : State = 'O'; break;
case '9' : State = 'O'; break;
default : State = 'i'; break;
}; Way=Way + State; break;
case 'A':
switch (wInput[i]) {
case 'f' : State = 'B'; break;
case '\0' : State = 's'; break;
default : State = 'i'; break;
}; Way=Way + State; break;
case 'B':
switch (wInput[i]) {
case '\0' : State = 's'; break;
default : State = 'i'; break;
}; Way=Way + State; break;
case 'C':
switch (wInput[i]) {
case 'h' : State = 'D'; break;
case '\0' : State = 's'; break;
default : State = 'i'; break;
}; Way=Way + State; break;
case 'D':
switch (wInput[i]) {
case 'e' : State = 'E'; break;
case '\0' : State = 's'; break;
default : State = 'i'; break;
}; Way=Way + State; break;
case 'E':
switch (wInput[i]) {
case 'n' : State = 'F'; break;
case '\0' : State = 's'; break;
default : State = 'i'; break;
}; Way=Way + State; break;
case 'F':
switch (wInput[i]) {
case '\0' : State = 's'; break;
default : State = 'i'; break;
}; Way=Way + State; break;
case 'G':
switch (wInput[i]) {
case 'l' : State = 'H'; break;
case '\0' : State = 's'; break;
default : State = 'i'; break;
}; Way=Way + State; break;
case 'H':
switch (wInput[i]) {
case 's' : State = 'I'; break;
case '\0' : State = 's'; break;
default : State = 'i'; break;
}; Way=Way + State; break;
case 'I':
switch (wInput[i]) {
case 'e' : State = 'J'; break;
case '\0' : State = 's'; break;
default : State = 'i'; break;
}; Way=Way + State; break;
case 'J':
switch (wInput[i]) {
case '\0' : State = 's'; break;
default : State = 'i'; break;
}; Way=Way + State; break;
case 'K':
switch (wInput[i]) {
case '\0' : State = 's'; break;
default : State = 'e'; break;
}; Way=Way + State; break;
case 'L':
switch (wInput[i]) {
case '\0' : State = 's'; break;
default : State = 'e'; break;
}; Way=Way + State; break;
case 'i':
switch (wInput[i]) {
case '\0' : State = 's'; break;
default : State = 'i'; break;
}; Way=Way + State; break;
case 'M':
switch (wInput[i]) {
case '=' : State = 'N'; break;
default : State = 'e'; break;
}; Way=Way + State; break;
case 'N':
switch (wInput[i]) {
case '\0' : State = 's'; break;
default : State = 'e'; break;
}; Way=Way + State; break;
case 'O':
switch (wInput[i]) {
case '0' : State = 'O'; break;
case '1' : State = 'O'; break;
case '2' : State = 'O'; break;
case '3' : State = 'O'; break;
case '4' : State = 'O'; break;
case '5' : State = 'O'; break;
case '6' : State = 'O'; break;
case '7' : State = 'O'; break;
case '8' : State = 'O'; break;
case '9' : State = 'O'; break;
case 'n' : State = 'O'; break;
case '.' : State = 'P'; break;
default : State = 'e'; break;
}; Way=Way + State; break;
case 'P':
switch (wInput[i]) {
case '0' : State = 'Q'; break;
case '1' : State = 'Q'; break;
case '2' : State = 'Q'; break;
case '3' : State = 'Q'; break;
case '4' : State = 'Q'; break;
case '5' : State = 'Q'; break;
case '6' : State = 'Q'; break;
case '7' : State = 'Q'; break;
case '8' : State = 'Q'; break;
case '9' : State = 'Q'; break;
default : State = 'e'; break;
}; Way=Way + State; break;
case 'Q':
switch (wInput[i]) {
case '0' : State = 'Q'; break;
case '1' : State = 'Q'; break;
case '2' : State = 'Q'; break;
case '3' : State = 'Q'; break;
case '4' : State = 'Q'; break;
case '5' : State = 'Q'; break;
case '6' : State = 'Q'; break;
case '7' : State = 'Q'; break;
case '8' : State = 'Q'; break;
case '9' : State = 'Q'; break;
case '\0': State = 's'; break;
case 'e' : State = 'R'; break;
default : State = 'e'; break;
}; Way=Way + State; break;
case 'R':
switch (wInput[i]) {
case '0' : State = 'S'; break;
case '1' : State = 'S'; break;
case '2' : State = 'S'; break;
case '3' : State = 'S'; break;
case '4' : State = 'S'; break;
case '5' : State = 'S'; break;
case '6' : State = 'S'; break;
case '7' : State = 'S'; break;
case '8' : State = 'S'; break;
case '9' : State = 'S'; break;
default : State = 'e'; break;
}; Way=Way + State; break;
case 'S':
switch (wInput[i]) {
case '0' : State = 'S'; break;
case '1' : State = 'S'; break;
case '2' : State = 'S'; break;
case '3' : State = 'S'; break;
case '4' : State = 'S'; break;
case '5' : State = 'S'; break;
case '6' : State = 'S'; break;
case '7' : State = 'S'; break;
case '8' : State = 'S'; break;
case '9' : State = 'S'; break;
case '\0' : State = 's'; break;
default : State = 'e'; break;
}; Way=Way + State; break;
case 'e': break;
}
}while (wInput[i++]!='\0');
return Way;
}
void __fastcall TForm1::Button1Click(TObject *Sender)
{
FILE *input;
char *temp;
String Way;
int i=1;
temp = new char[20];
if(OpenDialog1->Execute())
{
input = fopen(OpenDialog1->FileName.c_str(),"r");
while (!feof(input))
{
fscanf(input,"%s",temp);
Way = Analiz(temp);
if( Way[strlen(Way.c_str())]!='e' )
{
sgrTable->Rows[i]->Add(temp);
sgrTable->Rows[i]->Add(Conclude(Way[strlen(Way.c_str())-1]));
sgrTable->Rows[i]->Add(Way);
i++;
}
}
sgrTable->RowCount = i;
}
}
//---------------------------------------------------------------------------
void __fastcall TForm1::Button2Click(TObject *Sender)
{
Close();
}
//---------------------------------------------------------------------------
Файл input.txt:
if x = 2 then y := 10 else
z := 5.10e2 ;
if p > 2 then z := 5.10 ;
z < l ;
Результаты выполнения работы
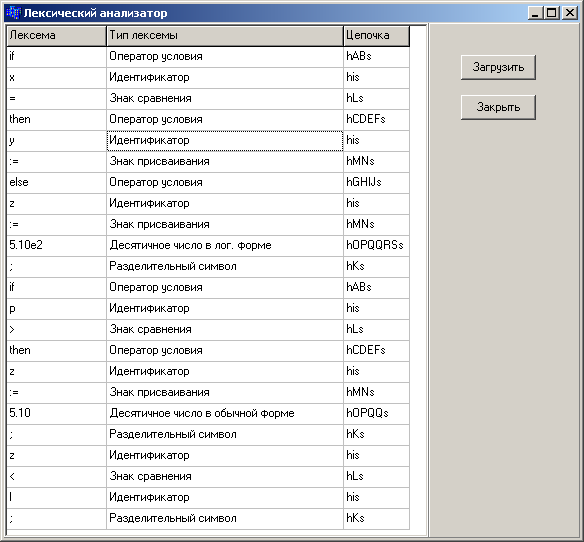
Результаты работы:
Вывод: В результате проделанной работы были изучены основные понятия теории регулярных грамматик, назначения и принципы работы лексических анализаторов (сканеров). Были получены практические навыки построения сканера на примере заданного простейшего входного языка.