

2.4 Результаты
В результате своей работы лексический анализатор формирует таблицу лексем и таблицу идентификаторов (рис. 7).

 Рис.7
Экранная форма результатов работы
лексического анализатора
Рис.7
Экранная форма результатов работы
лексического анализатора
Построенный лексический анализатор позволяет выделять в тексте исходной программы лексемы следующих типов:
– операторы цикла с перечислением по заданной переменной вида “for <переменная>:=<выражение> to <выражение> do ” либо “ for <переменная>:=<выражение> downto <выражение> do ”;
идентификаторы;
круглые открывающиеся и закрывающиеся скобки;
операторы сравнения “<”, “>”, “=”;
знак присваивания “:=”;
составные операторы “begin” и “end”;
условные операторы “if”, “then” ,“else”;
ключевые слова начала и конца программы “prog” и “end.”;
разделяющий знак “;”;
 логические
операторы “not”,
“and”
и “or”;
логические
операторы “not”,
“and”
и “or”;арифметические операции сложения, вычитания, сдвига влево и вправо;
комментарии любой длины в скобках со звездочками;
константы в двоичной форме.
Если обнаружена неверная лексема лексический анализатор помещает ее в поле ошибочных лексем и продолжает дальнейшую работу, пока не будет достигнут конец файла.
Также заполняется таблица идентификаторов с помощью выбранного метода – метода цепочек.
Проектирование синтаксического анализатора
3.1 Исходные данные
Требуется написать программу, которая выполняет синтаксический разбор цепочки символов по заданной грамматике с построением дерева разбора. На вход синтаксического анализатора поступает информация, содержащаяся в таблице лексем, заполненная на этапе лексического анализа. При наличии во входной цепочке текста, соответствующего заданному языку, программа должна строить и отображать дерево синтаксического разбора. Если же текст во входной цепочке содержит синтаксические ошибки, программа должна выдавать сообщения об ошибке.
Входной язык задан с помощью следующей КС-грамматики:
G({prog, end., if, then, else, begin, end, for ,to, downto, do, and, or, not, =, <,>, (, ), -, +, a, ;, :=,>>,<<}, {S, L, O, B, C, D, E, T}, P,S))
с правилами Р:
S ® prog L end.
L ® O | L ; O | L;
O ® if B then O else O| if B then O| begin L end | for O to T do O| for O downto T do O | a := E
B ® B or C | C
C® C and D | D
D ® E < E | E > E | E = E | not (B)
E ® E – T | E + T| a>>T|a<<T |T
F ® a |(E)
Жирным шрифтом в грамматике и в правилах выделены терминальные символы.
3.2 Построение синтаксического анализатора
Синтаксический анализатор выполняет две основные задачи: проверка правильности конструкций программы, которая представляется в виде уже выделенных слов входного языка, и преобразование её в вид, удобный для дальнейшей семантической (смысловой) обработки и генерации кода. Одним из таких способов представления является дерево синтаксического разбора.
Класс КС-языков допускает распознавание с помощью недетерминированного автомата со стековой (или магазинной) памятью – МП-автомата.
Схема МП-автомата представлена на рисунке 9:

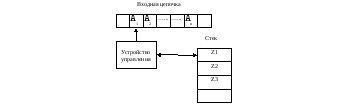
Рис.9 Схема МП-автомата
МП-автоматом выполняется алгоритм «сдвиг-свертка» для грамматики операторного предшествования. Для моделирования его работы необходима входная цепочка символов и стек, в котором автомат может обращаться не только к самому верхнему символу, но и к некоторой цепочке символов на вершине стека. После завершения алгоритма «свиг-свертка» решение о принятии цепочки зависит от содержимого стека. Автомат принимает цепочку, если в результате завершения алгоритма он находится в состоянии, когда в стеке находятся начальный символ грамматики и символ конца строки. Выполнение алгоритма может быть прервано, если на одном из его шагов возникла ошибка.
В курсовом проекте КС-грамматика является грамматикой операторного предшествования. Для построения анализатора на основе этой грамматики, необходимо построить матрицу операторного предшествования. Для этого на первом шаге нужно получить множество крайних левых и крайних правых символов из правил грамматики G. Полученное множество представлено в табл.1.
Таблица 1
Множество крайних левых и крайних правых символов
|
Символы U |
L(U) |
R(U) |
|
F |
(, a |
) , a |
|
E |
E, T, (, a |
T, ) , a |
|
D |
(, not, E, T, a |
E, T, ) , a |
|
C |
C, D, (, not, E, T, a |
D, E, T, ) , a |
|
B |
B, C, D, (, not, E, T, a |
C, D, E, T, ) , a |
|
O |
if, begin, for, a, ( |
O, end, E, ), T, a |
|
L |
O, L, if, begin, for, a, ( |
O, ;, end, E, ), T, a |
|
S |
prog |
end. |
На втором шаге, после многократного анализа, получили множество крайних левых и крайних правых терминальных символов из правил грамматики G. Полученное множество представлено в табл.2.
Таблица 2
Множество крайних левых и крайних правых терминальных символов
|
Символы U |
Lt(U) |
Rt (U) |
|
F |
(, a |
) , a |
|
E |
-, +, (, a |
-, +, <<,>>, ) , a |
|
D |
<, >, =, (, not, -, +, a |
<, >, =, ), -, +, <<, >>,a |
|
C |
and, <, >, =, (, not, -, +, a |
and, <, >, =, ), -, +, <<, >>,a |
|
B |
or, and, <, >, =, (, not, -, +, a |
or, and, <, >, =, ), -, +, <<, >>, a |
|
O |
if, begin, for, a |
else, end, ),do,then, :=, -, +, <<, >>, a |
|
L |
;, if, begin, for, a |
;, else, end, ), :=, -, +, <<, >>, a, do |
|
S |
prog |
end. |
 На
основе грамматики и табл.2 строим
матрицу операторного предшествования.
Матрица операторного предшествования
представлена в приложении B.
Также, для практического использования,
матрицу предшествования дополняем
символами ^н
и ^к
(начало и конец цепочки).
На
основе грамматики и табл.2 строим
матрицу операторного предшествования.
Матрица операторного предшествования
представлена в приложении B.
Также, для практического использования,
матрицу предшествования дополняем
символами ^н
и ^к
(начало и конец цепочки).
Алгоритм разбора цепочек грамматики операторного предшествования игнорирует нетерминальные символы. Поэтому имеет смысл преобразовать исходную грамматику таким образом, чтобы оставить в ней только один нетерминальный символ. Построенная таким образом грамматика называется «остовной» грамматикой.
Основная грамматика, полученная на основе исходной грамматики:
 G({prog,
end.,
if,
then,
else,
begin,
end,
for ,to,
downto, do,
and, or,
not,
=,
<,>,
(,
),
-,
+,
a,
;,
:=,>>,<<},
{E},
P,S))
G({prog,
end.,
if,
then,
else,
begin,
end,
for ,to,
downto, do,
and, or,
not,
=,
<,>,
(,
),
-,
+,
a,
;,
:=,>>,<<},
{E},
P,S))
с правилами Р:
E ® prog E end.
E ® E | E ; E | E;
E ® if E then E else E| if E then E| begin E end | for E to E do E| for E downto E do E | a := E
E ® E or E | E
E® E and E | E
E ® E < E | E > E | E = E | not (E)
E ® E – E | E + E| a>>E|a<<E |E
E ® a |(E)
Результаты
В результате выполнения программы построен синтаксический анализатор на основе грамматики операторного предшествования. Синтаксический анализ позволяет проверять соответствие структуры исходного текста заданной грамматике входного языка. А также синтаксический анализ позволяет обнаруживать любые синтаксические ошибки во входной программе.
После обработки входного файла лексическим анализатором и построения таблицы лексем (рисунок 7), если не возникло лексических ошибок, строится дерево вывода (рис. 8).
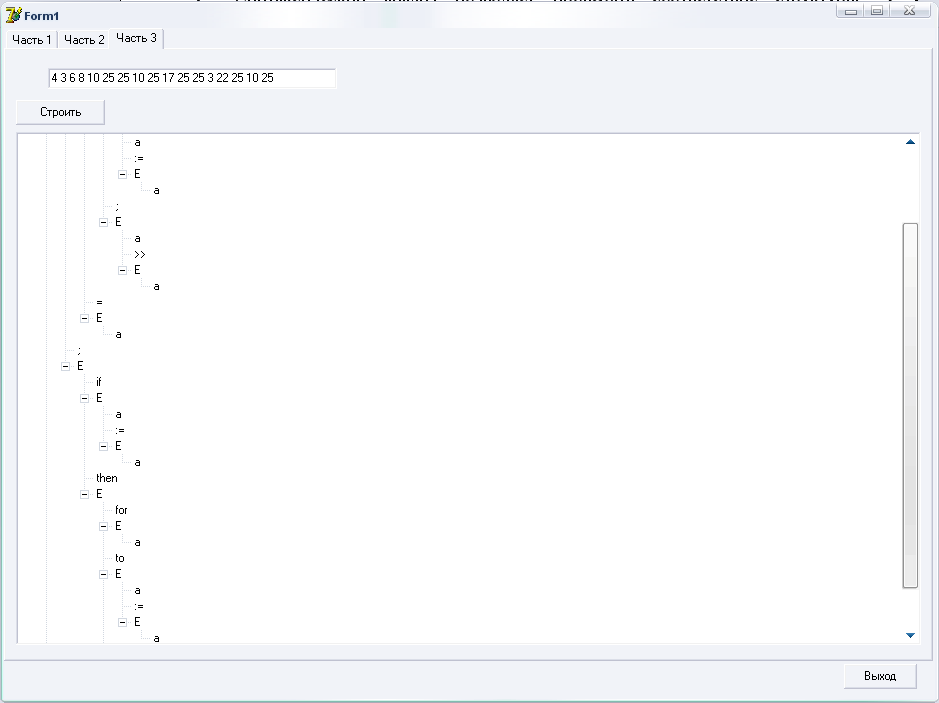
Рис.8 Экранная форма дерева вывода
 При
наличии ошибки пользователю выдается
сообщение (рис. 9).
При
наличии ошибки пользователю выдается
сообщение (рис. 9).

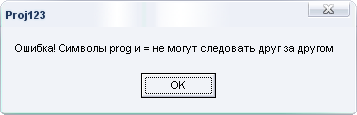
Рис. 9 Экранная форма сообщения о синтаксической ошибке
 Заключение
Заключение
В результате выполнения курсового проекта были сравнены два метода построения таблиц идентификаторов. По результатам этого сравнения (количества коллизий и среднего числа сравнений) наиболее лучшим оказался метод цепочек. На втором этапе был проведен лексический анализ и построены таблица лексем и таблица идентификаторов (методом, выбранным на первом этапе выполнения курсового проекта). На третьем этапе был проведен синтаксический анализ. Результатом работы синтаксического анализа является дерево вывода.