

2.2 Принципы работы лексического анализатора
Лексический
анализатор –
это часть компилятора, которая читает
литеры программы на исходном языке и
строит из них слова (лексемы) исходного
языка. На вход лексического анализатора
поступает текст  исходной
программы, а выходная информация
передастся для дальнейшей
обработки
компилятором на этапе синтаксического
анализа и разбора.
исходной
программы, а выходная информация
передастся для дальнейшей
обработки
компилятором на этапе синтаксического
анализа и разбора.
Лексема (лексическая единица языка) – это структурная единица языка, которая состоит из элементарных символов языка и не содержит в своем составе других структурных единиц языка. Лексемами языков программирования являются идентификаторы, константы, ключевые слова языка, знаки операций и т. п.
В основном лексические анализаторы выполняют исключение из текста исходной программы комментариев и незначащих пробелов, а также выделение лексем следующих типов: идентификаторов, строковых, символьных и числовых констант, знаков операций, разделителей и ключевых (служебных) слов входного языка.
Результатом работы лексического анализатора является перечень всех найденных в тексте исходной программы лексем. Этот перечень представляется в виде таблицы, называемой таблицей лексем.
Язык описания констант и идентификаторов в большинстве случаев является регулярным, то есть может быть описан с помощью регулярных грамматик. Распознавателями для регулярных языков являются конечные автоматы (КА).
Любой КА может быть задан с помощью пяти параметров: М(Q, V,δ,q0,F),
где: Q – множество состояний автомата;
V – конечное множество допустимых входных символов;
d – функция переходов автомата;
q0Î Q – начальное состояние автомата;
FÍQ – множество конечных состояний автомата.
Алгоритм работы простейшего лексического анализатора:
просматривается входной поток символов программы на исходном языке до обнаружения очередного символа, ограничивающего лексему;
 для
выбранной части входного потока
выполняется функция распознавания
лексемы;
для
выбранной части входного потока
выполняется функция распознавания
лексемы;при успешном распознавании информация о выделенной лексеме заносится в таблицу лексем, и алгоритм возвращается к первому этану;
при неуспешном распознавании лексемы, она помещается в поле ошибочных лексем, и делается попытка распознать следующую лексему (идет возврат к первому этану алгоритма).
Работа лексического анализатора продолжается до тех пор, пока не будут просмотрены все символы программы на исходном языке из входного потока.
2.3 Схема распознавателя
Распознаватель – это специальный алгоритм, который позволяет определить принадлежность цепочки символов заданному языку.
Схема распознавателя представлена на рисунке 6:
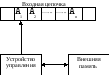
Рис.6 Схема распознавателя
Во входном языке константы заданы в двоичной форме. Двоичная константа должна содержать только цифры 1 и. Имена идентификаторов должны содержать только английские буквы и цифры.
Грамматика входного языка в форме Бэкуса-Наура:
 Для
удобства введем дополнительные
обозначения:
Для
удобства введем дополнительные
обозначения:
|
^–знак пробела d1 – все буквы алфавита, кроме е d2 – все буквы алфавита, кроме l d3 – все буквы алфавита, кроме s d4 – все буквы алфавита, кроме t d5 – все буквы алфавита, кроме h d6 – все буквы алфавита, кроме n d7 – все буквы алфавита, кроме i d8 – все буквы алфавита, кроме f d9-– все символы, кроме ‘=’ d10 – символы <, >, =, : , ; , d11 – любой символ,кроме <, >, =, : , ;
|
|
Конечный детерминированный автомат M’({ S,SD1,SD2,SD_PR,SD_L, RC, ID, F, PRISV, A, IF, B, B1, B2, THEN, C, C1, C2, ELSE, OS, RAZD, J, J1, END, TO, K, K1, K2, K3, K4, DOWN, L, L1, FOR, M, DO, BIN, ZAK, OTKR, OTKR1, ZAKR, ZAKR1, PROG, PROG1, PROG2, PROG3, G, OR, F, F1, NOT, D, D1, AND, PL, MIN, I, I1, I2, I3, BEGIN },{0..9, a..z, ; , <, >, +, -, >>,<<, (, ), *, : , =, ^ },d,H,{S}), который распознает язык, заданный этой грамматикой, представлен приложении Б. Начальным состоянием автомата является состояние H, конечным S. Поскольку КА работает с непрерывным потомком лексем, перейдя в конечное состояние, он тут же должен возвращаться в начальное, чтобы распознавать очередную лексему. Поэтому в моделируемой программе эти два состояния объединяются. В автомат введено особое состояние E, обозначающее состояние «ошибка». В это состояние КА переходит всегда, когда получает на вход символ, по которому нет переходов из текущего состояния.