

Курсовые проекты / лабы мои / 2 / отчёт2СПОмая
.docМинистерство образования РФ
Уфимский Государственный Авиационный Технический Университет
Кафедра ТК
Лабораторная работа №2
“ Проектирование лексического анализатора ”
Выполнили:
ст.гр УТС-411
Беляев В. В.
Проверил: доц. каф. ТК
Карамзина А. Г.
Уфа 2007
Цель работы: изучение основных понятий теории регулярных грамматик, ознакомление с назначением и принципами работы лексических анализаторов (сканеров), получение практических навыков построения сканера на примере заданного простейшего входного языка.
Вариант8:
Входной язык содержит операторы цикла типа for (...;...;...) do, разделенные символом ;(точка с запятой). Оператор цикла идентификаторы, знаки сравнения <,>,= , римские числа, знака присваивания (:=).
КС-грамматика входного языка в форме Бэкуса-Наура:
Условные обозначения:
d – все цифры и буквы алфавита, кроме V, X, I
d1 – все буквы алфавита, кроме f
d2 - все буквы алфавита, кроме o
d3 - все буквы алфавита, кроме r
d4 - все буквы алфавита, кроме d
d5 - все буквы алфавита, кроме o
d6- все символы
d7 – символы <, >, =, : , ;
d8 – любой символ, кроме <, >, =, : , ;
^-знак пробела
G({0..9, a..z, ; , : , = , ^ , < , > , V,X,I}, {H, ZZ, L, N, Z1, O2, O1, E, F1, K1, F2, K2, K3, D2, Z2, D1, T1, I },P,S)
P:
H®H^
N®HV|HX|HI
L®H;
O1®H)
O2®H(
F1®H:
F2®F1=
Z2®H=
ZZ®H>
Z1®H<
K1®Hf
K2®K1o
K3®K2r
D1®Hd
D2®D1o
I®Nd|K1d1|K2d2|K3d3|D1d4|D2d5| E®Z2d6|Z1d8|Z2d8|F1d8|F2d8|K1d7|K2Dd7|K3d7|D1d7|D2d7|Nd7|O1d6|O2d6|E^|
S®F2^|Z2^|ZZ^|Z1^|O2^O1^|I ^|D2^|K3^|N^|L^
Листинг программы:
unit Unit2;
interface
uses
Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms,
Dialogs, ComCtrls, StdCtrls, Grids, ExtCtrls;
type
TAutoState = ( AUTO_H, AUTO_ZZ,AUTO_L,AUTO_N,AUTO_Z1,AUTO_O2,AUTO_O1,AUTO_E,AUTO_F1,AUTO_K1, AUTO_F2,AUTO_K2,AUTO_K3,AUTO_D2,AUTO_Z2, AUTO_D1,AUTO_T1,AUTO_I );
TForm1 = class(TForm)
OpenDialog1: TOpenDialog;
PageControl1: TPageControl;
TabSheet1: TTabSheet;
Button2: TButton;
Memo1: TMemo;
TabSheet2: TTabSheet;
StringGrid1: TStringGrid;
Button3: TButton;
Panel1: TPanel;
Memo2: TMemo;
Label2: TLabel;
Label1: TLabel;
Button1: TButton;
Button4: TButton;
Label3: TLabel;
procedure Button2Click(Sender: TObject);
procedure FormCreate(Sender: TObject);
procedure Button3Click(Sender: TObject);
procedure Button4Click(Sender: TObject);
procedure Button1Click(Sender: TObject);
private
{ Private declarations }
public
{ Public declarations }
end;
var
Form1: TForm1;
implementation
{$R *.dfm}
procedure TForm1.Button2Click(Sender: TObject);
var a:integer;
begin
if OpenDialog1.Execute then Memo1.Lines.LoadFromFile(OpenDialog1.FileName) ;
a:=memo1.lines.count;
label3.Caption:='Всего строк в Файле : '+ inttostr(a);
end;
procedure TForm1.FormCreate(Sender: TObject);
begin
StringGrid1.Cells[0,0]:='Номер';
StringGrid1.Cells[1,0]:='Лексема';
StringGrid1.Cells[2,0]:='Инфа';
end;
procedure TForm1.Button3Click(Sender: TObject);
var
ind,pos,dl,i,j,i1,fl,zn:integer;
st,str,stroka:string;
sost:TAutoState;
begin
for i:=0 to 2 do
for i1:=1 to 999 do
StringGrid1.Cells[i,i1]:='';
i1:=Memo1.Lines.Count;
ind:=1;
pos:=1;
for i:=1 to i1 do
begin
str:='';
stroka:=Memo1.Lines[i-1];
stroka:=stroka+' ';
dl:=Length(stroka);
sost:=AUTO_H;
fl:=0;
zn:=0;
for j:=1 to dl do
begin
st:=stroka[j];
case sost of
AUTO_H:
case stroka[j] of
';': begin sost:=AUTO_L;str:=str+st; end; {1}
'I','X','V': begin sost:=AUTO_N;str:=str+st; end; {1}
'>': begin sost:=AUTO_ZZ;str:=str+st; end; {1}
'<': begin sost:=AUTO_Z1; str:=str+st end; {1}
'=': begin sost:=AUTO_Z2; str:=str+st end; {1}
':': begin sost:=AUTO_F1;str:=str+st; end; {1}
'(': begin sost:=AUTO_O2;str:=str+st; end; {1}
')': begin sost:=AUTO_O1;str:=str+st; end; {1}
'd': begin sost:=AUTO_D1;str:=str+st; end; {1}
'f': begin sost:=AUTO_K1;str:=str+st; end; {1}
'.': begin sost:=AUTO_T1;str:=str+st; end;
'a'..'c','e','g'..'z': begin sost:=AUTO_I;str:=str+st; end;
' ': begin sost:=AUTO_H;str:=''; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_L: {;}
case stroka[j] of
' ': begin sost:=AUTO_H;fl:=1;zn:=1; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_N: {римские буквы}
case stroka[j] of
'X','I','V': begin sost:=AUTO_N; str:=str+st; end;
' ': begin sost:=AUTO_H; fl:=1; zn:=12; end;
'a'..'h','j'..'u','w','y','z': begin sost:=AUTO_H;fl:=1;zn:=5;str:=str+st; end;
else begin sost:=AUTO_E; str:=str+st; end;
end;
AUTO_O2: {(}
case stroka[j] of
' ': begin sost:=AUTO_H; fl:=1; zn:=2; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_O1: {)}
case stroka[j] of
' ': begin sost:=AUTO_H;fl:=1;zn:=3; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_F1:
case stroka[j] of {:=}
'=': begin sost:=AUTO_F2;str:=str+st; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_F2:
case stroka[j] of {:=}
' ': begin sost:=AUTO_H;fl:=1;zn:=4; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_K1: {for}
case stroka[j] of
'a'..'n','p'..'z','0'..'9',' ': begin sost:=AUTO_I;str:=str+st; end;
'o': begin sost:=AUTO_K2;str:=str+st; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_K2: {for}
case stroka[j] of
'a'..'q','s'..'z','0'..'9',' ': begin sost:=AUTO_I;str:=str+st; end;
'r': begin sost:=AUTO_K3;str:=str+st; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_K3: {for}
case stroka[j] of
'a'..'z','0'..'9': begin sost:=AUTO_I;str:=str+st; end;
' ': begin sost:=AUTO_H; fl:=1; zn:=11; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_I:
case stroka[j] of
'a'..'z','0'..'9': begin sost:=AUTO_I;str:=str+st; end;
' ': begin sost:=AUTO_H;fl:=1;zn:=5; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_ZZ: {<,>,=}
case stroka[j] of
' ': begin sost:=AUTO_H;fl:=1;zn:=6; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_Z1:
case stroka[j] of
' ': begin sost:=AUTO_H;fl:=1;zn:=7; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_Z2:
case stroka[j] of
' ': begin sost:=AUTO_H;fl:=1;zn:=8; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_D1: {DO}
case stroka[j] of
'a'..'n','p'..'z','0'..'9',' ': begin sost:=AUTO_I;str:=str+st; end;
'o': begin sost:=AUTO_D2;str:=str+st; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_D2:
case stroka[j] of
'a'..'z','0'..'9': begin sost:=AUTO_I;str:=str+st; end;
' ': begin sost:=AUTO_H;fl:=1;zn:=10; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_T1:
case stroka[j] of
' ': begin sost:=AUTO_H;fl:=1;zn:=9; end;
'.': begin sost:=AUTO_T1; str:=str+st; end;
else begin sost:=AUTO_E;str:=str+st; end;
end;
AUTO_E: begin
if stroka[j]<>' 'then
begin
sost:=AUTO_E;
str:=str+st;
end
else
begin
sost:=AUTO_H;
Memo2.Lines.Append(str);
str:='';
end;
end;
end;
if fl=1 then
begin
StringGrid1.Cells[0,ind]:=IntToStr(ind);
StringGrid1.Cells[1,ind]:=str;
case zn of
1: StringGrid1.Cells[2,ind]:='Разделяюший знак';
2: StringGrid1.Cells[2,ind]:='Круглые открывающиеся скобки';
3: StringGrid1.Cells[2,ind]:='Круглые закрывающиеся скобки';
4: StringGrid1.Cells[2,ind]:='Знак присваивания';
5: StringGrid1.Cells[2,ind]:='Идентификатор';
6: StringGrid1.Cells[2,ind]:='>';
7: StringGrid1.Cells[2,ind]:='<';
8: StringGrid1.Cells[2,ind]:='=';
9: StringGrid1.Cells[2,ind]:='Точка ';
10: StringGrid1.Cells[2,ind]:='Оператор "DO" ';
11: StringGrid1.Cells[2,ind]:='Оператор "for"';
12:StringGrid1.Cells[2,ind]:='Римские цифры';
end;
str:='';
ind:=ind+1;
fl:=0;
end;
end;
end;
label2.Caption:='Число лексем '+IntToStr(ind-1); {Число лексем }
end;
procedure TForm1.Button4Click(Sender: TObject);
var i,i1:integer;
begin
for i:=0 to 2 do
for i1:=1 to 999 do
StringGrid1.Cells[i,i1]:='';
Memo1.Clear;
Label2.Caption:= 'Кол-во Лексем: 0 ';
Memo2.Clear;
Label3.Caption:= 'Всего строк в файле: 0 '
end;
procedure TForm1.Button1Click(Sender: TObject);
begin
Close;
end;
end.
Результаты работы:

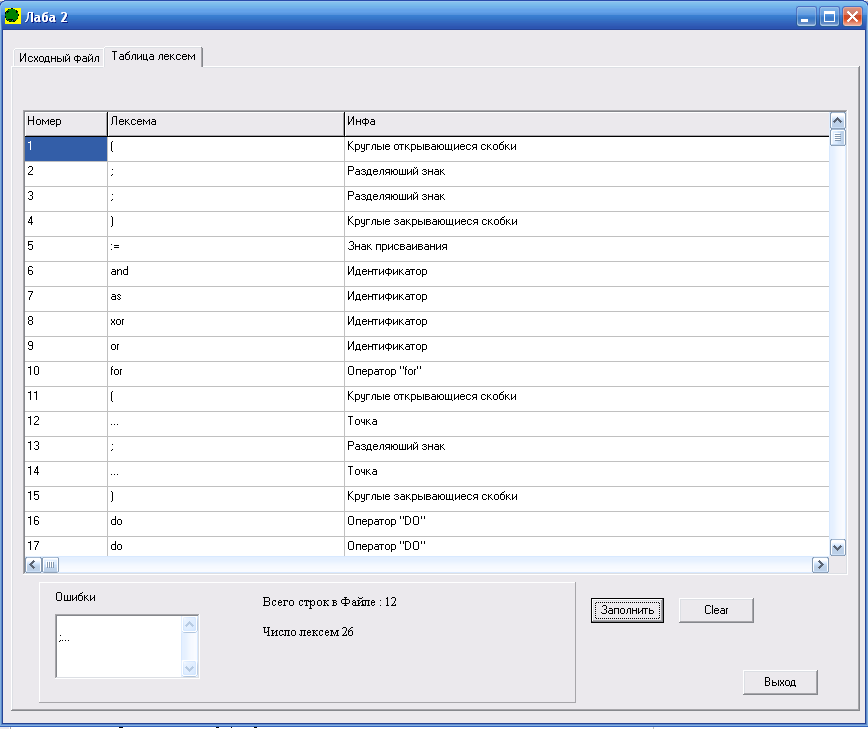
Вывод: в ходе проделанной работы были изучены основные понятия теории регулярных грамматик; был построен лексический анализатор, который позволяет выделить во входном тексте нужные лексемы; неверные лексемы анализатор помещает в поле ошибочных лексем, и продолжает работу пока не будет, достигнут конец файла.