

1.4. Простой список
Простой список является простейшим способом организации ТИ. Он состоит в том, что добавление элементов ведется в порядке их поступления. Поиск в этом случае требует сравнения с каждым элементом ТИ, пока не будет найден подходящий. Для ТИ, содержащей n элементов, в среднем будет выполнено n/2 сравнений. Если n велико, то способ не является эффективным.
Поскольку при заполнении таблицы идентификаторов основными операциями являются добавление элемента в таблицу и поиск элемента в ней, на рис. 3 и рис. 4 представлены блок-схемы этих операций для рассматриваемого метода.
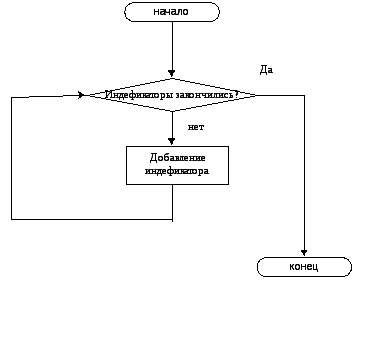
Рис. 3. Блок-схема добавления элемента в таблицу идентификаторов в простой список
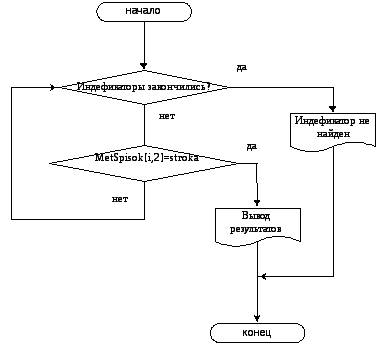
Рис. 4. Блок-схема алгоритма поиска элемента в таблицу идентификаторов, организованной по методу простого списка
1.5. Результаты
Для сравнения метода простого рехеширования и простого списка выбран текстовый файл, содержащий 35 строк.
В результате работы программы получены следующие данные, которые представлены в табл. 1 и программа на рис.5.
Таблица 1
|
|
Метод простого рехеширования |
Простой список |
|
Коллизий |
11 |
- |
|
Сравнений |
1 |
5 |
|
Среднее число сравнений |
0,01 |
0,07 |
На основе полученных
результатов можно сделать следующие
вывод ы.
ы.
Недостатки метода простого рехеширования:
элементы могут попадать в ячейки с адресами, которые потом будут совпадать со значениями хеш-функции, что приводит к возникновению дополнительных коллизий;
среднее время на размещение элемента и на поиск элемента в таблице зависит от заполненности таблицы идентификаторов и качества используемой хеш-функции;
требование неполного заполнения таблицы ведет к неэффективному использованию объема доступной памяти.
Достоинством метода простого рехеширования является то, что он позволяет добиться неплохих результатов для эффективного поиска элемента в таблице (лучших, чем метод бинарного дерева).
Достоинства простого списка:
нет необходимости заполнять пустыми значениями таблицу идентификаторов (это можно сделать только для хеш-таблицы), то есть память используется более экономно;
 элементы не могут
попадать в ячейки с адресами, которые
потом будут совпадать со значениями
хеш-функции, то есть коллизии не будут
возникать;
элементы не могут
попадать в ячейки с адресами, которые
потом будут совпадать со значениями
хеш-функции, то есть коллизии не будут
возникать;
время на размещение элемента и на поиск элемента в таблице не зависит от среднего числа коллизий, возникающих при вычислении хеш-функции.
Недостатком метода простого списка является большое время поиска.
Простое рехеширования является более эффективным методом организации таблицы идентификаторов. Именно он и будет в дальнейшем использован для хранения информации об идентификаторах в курсовой работе.
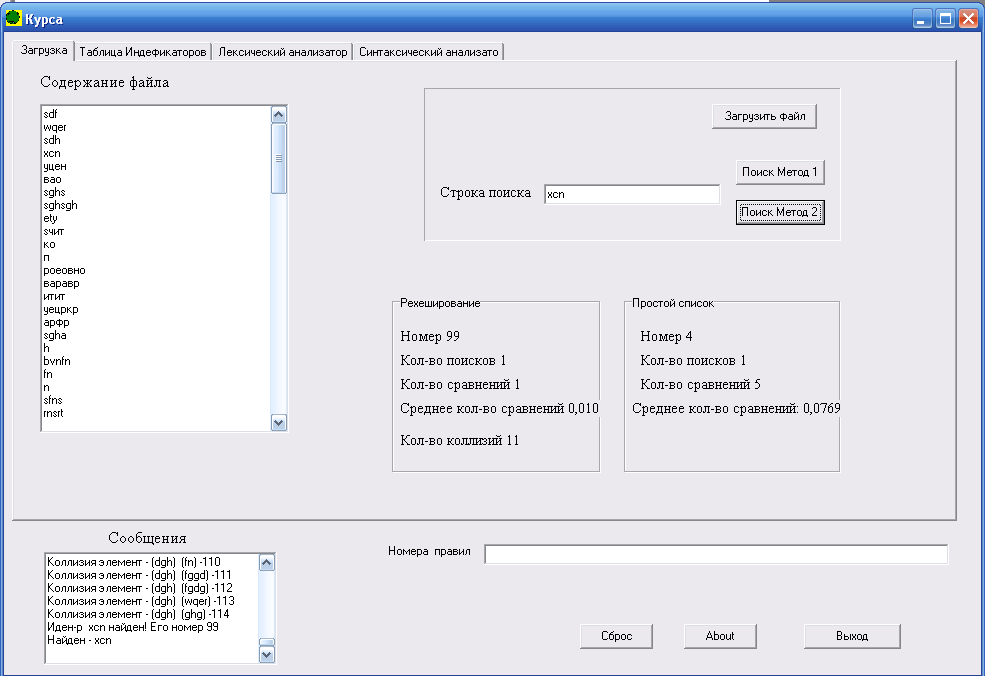
Рис. 5 Экранная форма организации таблиц идентификаторов
2. Проектирование лексического анализатора
2.1. Исходные данные
 Для
выполнения данной части курсовой работы
требуется написать программу, которая
выполняет лексический анализ входного
текста в соответствии с заданием и
порождает таблицу лексем с указанием
их типов и значений. Текст на входном
языке задан в виде текстового файла.
Программа должна выдавать сообщения о
наличие во входном тексте ошибок, которые
могут быть обнаружены на этапе лексического
анализа. Программа должна допускать
наличие комментариев неограниченной
длины во входном файле.
Для
выполнения данной части курсовой работы
требуется написать программу, которая
выполняет лексический анализ входного
текста в соответствии с заданием и
порождает таблицу лексем с указанием
их типов и значений. Текст на входном
языке задан в виде текстового файла.
Программа должна выдавать сообщения о
наличие во входном тексте ошибок, которые
могут быть обнаружены на этапе лексического
анализа. Программа должна допускать
наличие комментариев неограниченной
длины во входном файле.
В соответствии с заданием должны распознаваться:
ключевые слова : «prog», «end.», «begin», «end», «if», «then», «else»,
«while», «do», «and», «or», «not»;
идентификаторы: любые последовательности латинских символов и цифр; идентификатор должен начинаться с символа;
константы: двоичное представление числа;
знаки операций: «=», «<», «>», «–», «+», «*», «/»;
оператор присваивания: «:=»;
разделитель: «;»;
комментарии, заключенные в «{», «}».
Принципы работы лексического анализатора
Поскольку в данной курсовой работе входной язык является регулярным и может быть задан с помощью регулярной грамматики, распознавателем для него будет служить конечный автомат.
Конечный автомат задается пятеркой: M=(Q,V,d,q0,F),
где:
Q - конечное множество состояний автомата;
V – конечное множество допустимых входных символов;
d – множество функций перехода автомата;
q0Î Q - начальное состояние автомата;
FQ - множество конечных состояний автомата.
Работа автомата
выполняется по тактам. На каждом очередном
такте i
автомат,
находясь в некотором состоянии qiQ,
считывает очередной символ vV
из входной цепочки символов и изменяет
свое состояние на qi+1=(qi,v),
после чего указатель в цепочке входных
символов передвигается на следующий
символ и начинается такт i+1.
Так продолжается до тех пор, пока цепочка
входных символов  не
закончится. Конец цепочки символов
часто помечают особым символом.
Считается также, что перед тактом 1
автомат находится в начальном состоянии
q0.
не
закончится. Конец цепочки символов
часто помечают особым символом.
Считается также, что перед тактом 1
автомат находится в начальном состоянии
q0.
Графически автомат отображается нагруженным однонаправленным графом, в котором вершины представляют состояния, дуги отображают переходы из одного состояния в другое, а символы нагрузки (пометки) дуг соответствуют входному символу. Если функция перехода предусматривает переход из состояния q в q’ по нескольким символам, то между ними строится одна дуга, которая помечается всеми символами, по которым происходит переход из q в q’.
Схема распознавателя
Граф конечного автомата, используемого для распознавания входных цепочек языка, представлен в приложении Б и схема распознавателя на рис.6.
Начальное состояние автомата на рисунке обозначено <<Н>>. В случае ошибочной входной цепочки автомат попадает в состояние ошибки <<E>>. При этом работа автомата останавливается.
Кроме того, типичными для автомата являются состояния <<I>> (переменная) и <<G>> (константа). Остальные состояния автомата определяются допустимыми для компилятора исходного языка лексемами.
 Каждый
переход в конечное состояние <<S>>
сообщает о конце текущей входной цепочки.
В этом случае производится анализ
распознанной цепочки и перезапуск
автомата для очередной входной цепочки
символов. Заметим также, что возможна
повторная обработка некоторых символов
входной цепочки символов. Это необходимо
в тех случаях, когда символ, приведший
к переходу автомата в конечное состояние,
является началом следующей цепочки
символов.
Каждый
переход в конечное состояние <<S>>
сообщает о конце текущей входной цепочки.
В этом случае производится анализ
распознанной цепочки и перезапуск
автомата для очередной входной цепочки
символов. Заметим также, что возможна
повторная обработка некоторых символов
входной цепочки символов. Это необходимо
в тех случаях, когда символ, приведший
к переходу автомата в конечное состояние,
является началом следующей цепочки
символов.
Схема распознавателя представлена на рис 6:
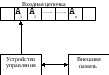
Рис.6 Схема распознавателя
Результаты
На основе сравнения методов организации таблиц идентификаторов, проведенного в первой части курсовой работы, выбран метод простое рехэширования. На основе таблицы идентификаторов, заполненной по методу простого рехеширования, организована таблица лексем. На рис. 7 и рис. 8 представлены таблица лексем и таблица идентификаторов, соответственно построенные при обработке следующего текстового файла.

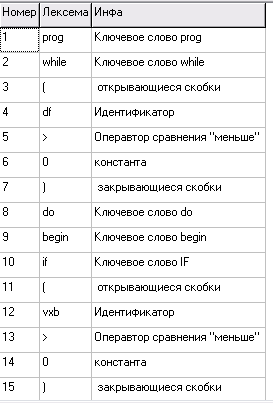
Рис. 7. Результат работы лексического анализатора таблица лексем

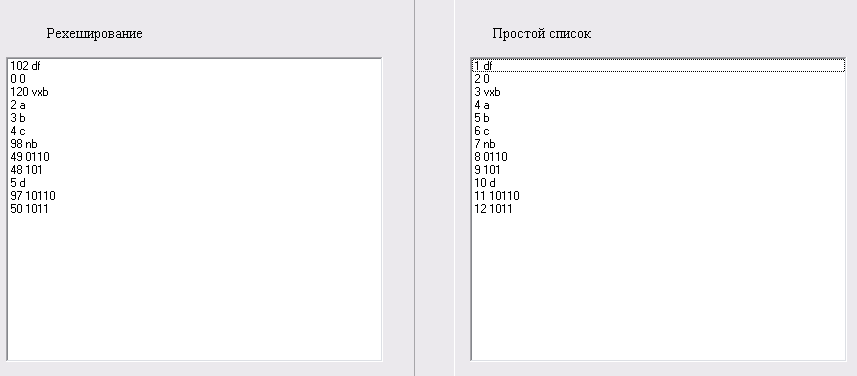
Рис. 8. Результат работы лексического анализатора таблица иденфикаторов