

1. Организация таблицы идентификаторов
1.1. Исходные данные
На входе имеется набор идентификаторов, которые организуются в таблицу идентификаторов по одному из двух методов:
Простое рехэширование.
Метод цепочек.
Должна быть предусмотрена возможность осуществления многократного поиска идентификатора в этой таблице. Список идентификаторов задан в виде текстового файла. Длина идентификатора ограничена 32 символами.
Требуется, чтобы программа подсчитывала число коллизий и среднее количество сравнений, выполняемых при поиске идентификатора.
1.2. Назначение таблиц идентификаторов
Проверка правильности семантики и генерация кода требуют знания характеристик идентификаторов, используемых в программе на исходном языке. Эти характеристики выясняются из описаний и из того, как идентификаторы используются в программе и накапливаются в таблице символов, или таблице идентификаторов. Любая таблица идентификаторов состоит из набора полей, количество которых равно числу идентификаторов программы. Каждое поле содержит в себе полную информацию о данном элементе таблицы. Под идентификаторами подразумеваются константы, переменные, имена процедур и функций, формальные и фактические параметры.
В данной работе сравниваются два метода организации таблицы идентификаторов: метод простого рехэширования и метод цепочек.
Данные методы основаны на хеш-адресации, то есть на использовании значения, возвращаемого хеш-функцией, в качестве адреса ячейки из некоторо-
го массива данных.
Хеш-функция вычисляется путем выполнения
над цепочкой символов некоторых простых
арифметических и логических  операций.
Самой простой хеш-функцией для символа
являетсяASCII-код символа.
операций.
Самой простой хеш-функцией для символа
являетсяASCII-код символа.
В данной курсовой работе принята хэш-функция суммаASCII-кодов первых двух символов цепочки.
При хэш-адресаци возможна ситуация, когда двум или более идентификаторам соответствует одно и то же значение хэш-функции. Такая ситуация называется коллизией. Сравниваемые в данной работе методы организации таблицы идентификаторов простого рехэширования и метод цепочек отличаются по способу разрешения коллизий. Ниже каждый метод рассмотрен подробнее.
1.3. Метод простого рехэширования
Согласно данному методу, если для элемента А адрес п() = h(A), указывает на уже занятую ячейку, то есть в случае возникновения коллизии, необходимо вычислить значение функции n1 = h1(A) и проверить занятость ячейки по адресу n1. Если и она занята, то вычисляется значение h2(A). И так до тех пор, пока либо не будет найдена свободная ячейка, либо очередное значение hi(A) не совпадет с h(A). В последнем случае считается, что таблица идентификаторов заполнена и места в ней больше нет выдается сообщение об ошибке размещения идентификатора в таблице.
Согласно методу простого рехэширования, hi(A) = (h(A)+i) mod Nm, где Nm максимальное значение хэш-функции.
В данной курсовой работе принята хэш-функция суммаASCII-кодов первых двух символов цепочки, максимальное значение хэш-функции равно 512.
Поскольку при заполнении таблицы идентификаторов основными операциями являются добавление элемента в таблицу и поиск элемента в ней, на рис. 1 и рис. 2 представлены блок-схемы этих операций для рассматриваемого метода.
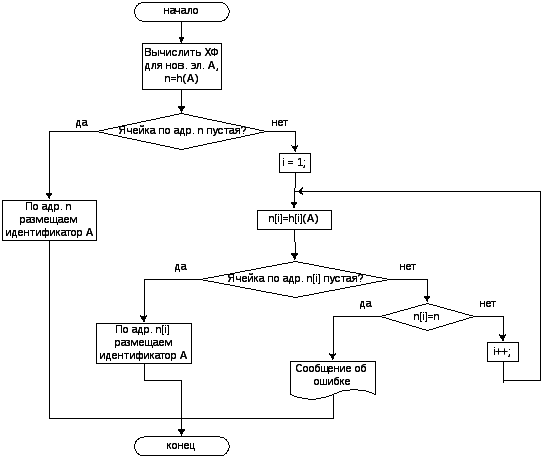
Рис. 1. Блок-схема добавления элемента в таблицу идентификаторов по методу простого рехэширования


Рис. 2. Блок-схема алгоритма поиска элемента в таблице идентификаторов, организованной по методу простого рехэширования