

Что должно случиться при попытке обновить потенциальный ключ, на который ссылается внешний ключ?
Ограничить – «ограничить» операцию обновления до тех пор. Когда не будет существовать соответствующих поставок (в противном случае операция запрещается);
Каскадировать – «каскадировать» операцию обновления, обновляя также внешний ключ в соответствующих поставках.
Таким образом , в отношении необходимо не только указать внешний ключ, но и указать правила этого внешнего ключа.
Необходимо знать, что правила внешних ключей следует формировать с учетом внешних связей отношения. На рис.18 показаны три отношения: отношения R3 ссылается на R2, а отношение R2 - на R1.

Рис.18. Цепочка отношений
Если для пары R2R1 установлено правило КАСКАД, а для пары R3R2 – правило ОГРАНИЧЕНИЕ, то СУБД будет фиксировать противоречивость этих правил: с одной стороны допускается каскадное удаление записей из отношений R2, а с другой стороны действует правило типа ОГРАНИЧЕНИЕ, которое запрещает удаление этих записей. Следовательно, не выполняется цепочка операций и база данных остается неизменной.
Null – значения. Часто говорят, что для некоторого человека «Дата рождения неизвестна», «В настоящее время адрес проживания неизвестен» и т.п.
В 1970г. Коддом был сформулирован подход к этой проблеме: для представления отсутствующей информации предложено использовать специальные маркеры, называемые Null – значениями. Это не пробелы или числовые нули, это некоторые маркеры.
Таким образом, реляционная модель поддерживает следующие правила целостности:
Целостность объектов – ни один элемент первичного ключа базового отношения не может быть Null – значением.
Целостность атрибута – значения каждого атрибута берутся из соответствующего домена.
Ссылочная целостность – база данных не должна содержать несогласованных значений внешних ключей.
Корпоративные ограничения. Пользователи сами могут указывать специфические ограничения назначения атрибутов.
2.1. Реляционная алгебра
Реляционное исчисление. В 1970-71 гг. Е.Ф.Кодд опубликовал статьи, в которых ввел в рассмотрение понятие реляционную алгебру и реляционные исчисления.
Реляционная алгебра – это процедурный язык обработки реляционных таблиц. Это означает, что в реляционной алгебре используется пошаговый метод в создании реляционных таблиц, содержащих ответы на запросы.
Реляционное исчисление – это не процедурный язык, т.е. язык позволяющий сформулировать, что нужно сделать, а не как этого добиться.
Операции реляционной алгебры. Операции реляционной алгебры манипулирует реляционными таблицами, для создания новых таблиц, затем полученные новые таблицы, могут использоваться в качестве входных таблиц для новой операции.
Рассмотрим типовые операции:
Объединение отношений.
R:=R1![]() R2
Операция применяется к отношениям одной
или той же арности. Таблицы должны иметь
одни и те же столбцы, т. е. у них совпадают
как количество столбцов, так и области
столбцов. Такие таблицы называют
объединительно
– совместительными (Рис.19).
R2
Операция применяется к отношениям одной
или той же арности. Таблицы должны иметь
одни и те же столбцы, т. е. у них совпадают
как количество столбцов, так и области
столбцов. Такие таблицы называют
объединительно
– совместительными (Рис.19).
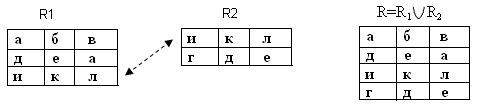
Рис.19. Объединение отношений
R1 – информация о сотрудниках
R2 – информация о сотрудниках (других)
R – информация о всех сотрудниках
Р
 азность
отношений.
азность
отношений.
R:=R1 - R2 Разностью отношений называется множество кортежей, принадлежащих R1 , но не принадлежащих R2 . Идентифицируются строки, которые есть в одной таблице, но отсутствуют в другой.
Находим разность отношений R1 и R2, взятых из предыдущего примера (рис.18).
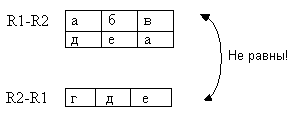
Рис.20. Разность отношений
Декартово произведение отношений.
R:=R1*R2 Если отношение R1 имеет арность К1, а отношение R2 арность К2, то декартовым произведением отношений R1 и R2 является множество кортежей, арности (К1+К2). Причем первые К1 элементов, образующие кортеж, берутся из отношения R1, а последние К2 элементов – из отношения R2 (Рис.19, Рис.20).
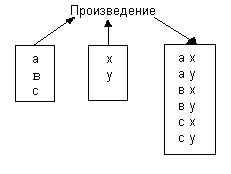
Рис.21. Декартово произведение отношений
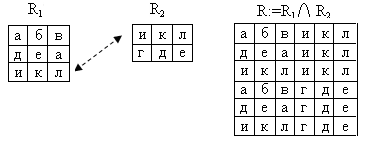
Рис.22. Декартово произведение отношений
П
 ересечение
отношений.
ересечение
отношений.
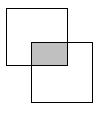
R1 и R2. R:=R1∩R2= R1 - (R1 - R2) Операция пересечения позволяет идентифицировать строки, общие для двух таблиц. Обе таблицы должны быть объединительно-совместимы (рис.21).

Рис.23. Пересечение отношений
Операция выборка.
Это связано с выбором строк на основании некоторого условия.
Н апример:
Выдать всю информацию о торговых агентах
в городе Владимир.
апример:
Выдать всю информацию о торговых агентах
в городе Владимир.
Запрос на SQL:
SELECT * FROM CUSTOMER
WHERE GOROD =’Владимир’
В реляционной алгебре это делается следующим образом:
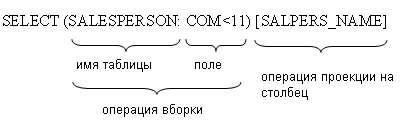
CUSTOMER_VL:=SELECT (CUSTOMER: GOROD=’Владимир’)
Имя CUSTOMER_VL – создано для обозначения результирующей таблицы
SELECT – обозначение операции ВЫБОРКА
( ) – записывается условие выборки
CUSTOMER – имя таблицы
GOROD – поле таблицы
Фраза FROM задает одну или более таблицу, к которым обращается запрос. Фраза SELECT перечисляет столбцы, которые должны войти в результирующую таблицу. Звездочка (*) в команде SELECT означает, что строка берется целиком. Фраза WHERE содержит условие, на основании которого, выбираются строки таблицы (таблиц).
С оздание проекций.
Операция реляционной алгебры создает новую таблицу, путем исключения столбцов из существующей таблицы.
CUSTOMER [NAME, ADR]
SQL:
SELECT <поле1>, < поле2>, < поле3> FROM <имя таблицы>
Возвращает значение указанных столбцов таблицы.
Вывод: если операцию выборки можно представить, как исключение ненужных строк, то операцию проекции – как исключение ненужных столбцов. Полученная таблица называется проекцией исходной таблицы.
Замечание: если две строки таблицы содержат идентичные значения в каждом столбце проекции, то строка войдет в результирующую таблицу только один раз.
Понятие вложенности операций. Это последовательный выбор операций реляционной алгебры, без явного присвоения имени промежуточной таблице результатов.
Например: Кто из торговых агентов получает менее 11% комиссионных?
Соединение.
Используется для связи данных, размещенных в двух таблицах. Одна из наиболее часто используемых операций реляционной алгебры.
Например:
Таблица 3 Клиент
-
Идентификация клиента
Имя клиента
Адрес
100
И – 100
А – 100
101
И – 101
А – 101
105
И – 105
А – 105
110
И – 110
А – 110
Таблица 4 Продажи
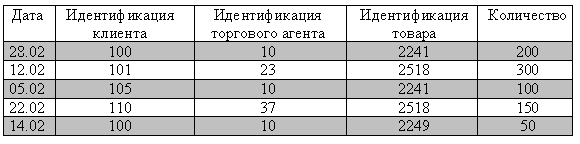
Необходимо получить данные о клиентах, которые производили закупки, через торгового агента с номером 10.
Сначала выбираем продажи, относящиеся к торговому агенту с номером 10. В таблице они выделены. Таких продаж 3. Для этого необходимо использовать операцию выборки, с условием идентификации торгового агента равно 10.
Теперь выполним соединение полученных таблиц, с таблицей клиент, по равенству значений в столбце: Идентификатор клиента. Такими значениями являются: 100, 105, 105.
Создадим произведение этих таблиц; создаем (3+5) столбцов и 4*3 строк.
Из полученной таблицы исключаем все строки, кроме тех, в столбцах которых, с именем идентификатор клиента, имеются одинаковые значения.
Поскольку теперь столбцы, идентификатор клиента, имеют одинаковые значения, то один из них можно удалить. Это операция проекции. В результате этих проекций получаем, так называемое, естественное соединение.
В таблице Продажи мы нашли три строки типа Продажа 10 (10 – идентификатор торгового агента). Каждая из этих строк в столбце Клиент соответствует только одна строка потому, что Идентификация клиента – это внешний ключ в таблице Продажи. Таким образов в таблице естественное соединение будет тоже три строки.
Таблица 5 Естественное соединение
Дата |
Идентиф. торг. агента |
Идентиф. товара |
кол-во |
Идентиф. клиента |
Имя клиента |
Адрес |
28.02 |
10 |
2241 |
200 |
100 |
И – 100 |
А – 100 |
05.02 |
10 |
2241 |
100 |
105 |
И – 105 |
А – 105 |
14.02 |
10 |
2249 |
50 |
100 |
И – 100 |
А – 100 |
Естественное соединение - это операция соединения, связывающая таблицу, когда их общие столбцы имеют равные значения.
Естественное соединение обозначают следующим образом:
JOIN (<имя таблицы 1>, < имя таблицы 2>)
Эти таблицы должны иметь одно или несколько полей.
Кроме естественного соединения, существует внешнее соединение, которое обозначается так:
OUTERJOIN (<имя таблицы 1>, < имя таблицы 2>)
Расширенное естественное соединение гарантирует, что каждая запись из обеих исходных таблиц, будет представлена в таблице соединений, хотя бы один раз.
Оно выполняется в два этапа: сначала выполнятся естественное соединение, а затем, если какая-либо строка одной из исходных таблиц, не подходит ни к какой строке второй таблице, она включается в таблицу соединений, а все дополнительные столбцы, заполняются пустыми значениями.
Тэта – соединение.
Пример. Дана таблица SALESPERSON (торговый агент). Одни торговые агенты являются менеджерами (управляющими). Подобные ситуации встречаются в рекурсивном отношении.
Таблица 6 SALESPERSON

Запрос: идентифицировать торговых агентов, чьи менеджеры получают комиссионные более 11%. Все данные находятся в одной таблице Торговый агент. Однако такой запрос нельзя выполнить простой операцией выборки, т.к. размер комиссионных в записи относится к торговому агенту, а не к его менеджеру.
Мы должны присоединить запись о менеджере к записи о торговом агенте, т.е. должны соединить таблицу саму с собой. Тогда размер комиссионных менеджера будет стоять в той же строке, что и имя торгового агента. Мы можем легко завершить запрос.
Пример. Первая строка таблицы содержит информацию об Иванове. Идентификатор его менеджера равен 27. Это Чернов. Размер его комиссионных равен 15%. Следовательно торговый агент Иванов должен быть включен в результат запроса, но не Чернов.
Решение задачи:
Сначала создаются две копии этой таблицы. Затем они соединяются по результатам столбцов «Идентификатор торгового агента» и «Идентификатор менеджера».
Затем выборка > 11%, потом проекция со столбцом фамилии, а затем возможна проекция на определенные столбцы.
SP1:=SALESPERSON
SP2:=SALESPERSON
A:=JOIN(SP1,SP2: SP1.MANAGER_ID=SP2.SALPERS_ID)
Кроме знака =, в условии могут использоваться ≠, <, >, ≤, ≥.
Дополнительный пример: Дана таблица SALESPERSON (торговый агент), в которой среди других столбцов присутствует столбец комиссионных (COMM_%).
Таблица 7
… |
10 11 9 13 10 15 12 11 10 |
… |
Ответим на вопрос: Каков максимальный размер комиссионных?
Кажется, что у нас вроде бы нет способа сравнить все значения в столбце размера комиссионных, чтобы определить какое из них максимально. Однако, Тэта - соединение сравнивает по крайней мере две строки. Воспользуемся им и свяжем таблицу саму с собой.
A:= SALESPERSON[COMM_%]
B:=A
C:=JOIN(A,B:A. COMM_%>B. COMM_%)
Получим таблицу 8
A. COMM_% |
B. COMM_% |
10 11 11 13 13 13 13 15 15 15 15 15 12 12 12 |
9 10 9 10 11 9 12 10 11 9 12 13 10 11 9 |
Левый столбец содержит все варианты значения комиссионных, кроме минимального – 9.
Правый столбец содержит все варианты значений, кроме максимального – 15.
Вычтем правый столбец из множества комиссионных.
D:=C[B. COMM_%]
Получим максимальное значение – E=15.
E:=A-D
8. Деление.
Предположим, что нам известны и доступны две таблицы: «ТОВАРЫ» и «ПРОДАЖИ».
Таблица 9 Товары
Идентиф. товара |
Название |
Цена |
1035 |
Свитер |
… |
2241 |
Лампа |
… |
2249 |
… |
… |
2518 |
… |
… |
Необходимо выполнить следующий запрос: Перечислить торговых агентов, которые продали каждый из этих товаров хотя бы один раз.
Ответ на этот запрос можно получить выполнив операцию деления.
Шаг1. Создаем проекцию по полю Идентификатор товара
Таблица 10 PR1
Идентиф. товара |
1035 |
2241 |
2249 |
2518 |
Шаг2. Создаем таблицу, содержащую информацию о результатах продаж. Это делается проектированием таблицы ПРОДАЖИ на столбцы: Идентификатор товара и Идентификатор торгового агента.
Таблица 11 PR2
Идентиф. торгового агента |
Идентиф. товара |
10 |
2241 |
23 |
2518 |
23 |
1035 |
39 |
2518 |
37 |
2518 |
10 |
2249 |
23 |
2249 |
23 |
2241 |
Операция даления производится следующим образом:
A:=PR2/PR1
Анализ:
Торговый агент 10 продал только две разновидности.
Торговый агент 23 продал все четыре разновидности.
Торговый агент 39 продал одну разновидность.
Торговый агент 37 продал тоже одну разновидность.
Таким образом, ответ: Торговый агент 23. Ответ
Идентиф. тор. агента |
23 |
Операция деления является обратной операцией произведения:
![]()
![]()
![]()
![]()
Присвоение.
Присвоение – операция реляционной алгебры, дающая имя таблице.
A:= SELECT(SALESPERSON: COMM_%>1),
где А – имя новой таблицы.
Реляционное исчисление. Исчисление представляет собой просто систему обозначений для определения необходимого отношения. Формулировка запроса в терминах исчисления носит описательный характер, а алгебраическая формулировка – предписывающий. Система должна сама решить, что необходимо соединять, проецировать и т.д.
Результатом каждого запроса в реляционном исчисление является реляционная таблица, которая задается целевым списком и определяющим выражением.
Целевой список определяет атрибуты таблицы решения. Определяющее выражение – это условие, на основании которого отбираются значения из базы данных.
Вслед за публикациями Кодда появились реализации реляционных языков. В частности SQL – Structured Query Language – язык структурированных запросов (текстовый язык).
QBE – Query-by-Example – запрос по образцу (графический язык).
SQL и QBE были разработаны фирмой IBM в семидесятые годы.
В 1981 году IBM выпустила СУБД SQL/DS поддерживающую SQL.
В 1982 году IBM выпустила СУБД – DB2.
В 1986 году был принят первый стандарт ANSI для SQL.
В 1992 – стандарт пересмотрен.
В настоящее время существует несколько СУБД, которые поддерживают язык SQL: Sybase SQL Server, Microsoft SQL Server и др.
Значительная часть языка SQL основана на реляционном исчислении.
SQL включает помимо средств запросов:
определение таблиц;
обновление БД;
определение представлений;
задание привилегий доступа и т.п.
Определение таблицы
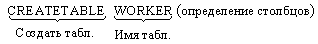
В определении каждого столбца дается его имя, тип данных, значение по умолчанию, а также относящиеся к нему ограничения.
Манипуляция данными
Простые запросы обращаются только к одной таблице.
SELECT NAME – перечисляются столбцы
FROM WORKER – к какой таблице обращен запрос
WHERE TYPE – условие запроса
Последовательность обработки: FROM, WHERE, SELECT.
Многотабличные запросы. Хотя значительная часть SQL основана на реляционном исчислении, но связывание данных разных таблиц осуществляется аналогично тому, как делает операция соединения реляционной алгебры.

Рис.24. Пример многотабличных запросов
Вопрос: Каковы специальности рабочих, назначенных на задание 10?
SELECT TYPE
FROM WORKER, ASSIGNMENT
WHERE WORKER. WORKER_ID= ASSIGNMENT. WORKER_ID
AND BLDG_ID=10
Рассмотрим этапы обработки.
Обрабатывается фраза FROM, в которой указаны две таблицы, поэтому система создает декартово произведение строк этих таблиц. Создается одна большая промежуточная таблица.
Система применяет команду WHERE. Первое условие означает, что в любой выбранной строке значения WORKER_ID должны совпадать. Все остальные строки исключаются из декартова произведения. Затем подключается дополнительное условие: BLDG_ID=10.
Обрабатывается SELECT.
Операция изменения данных
INSERT– вставить
Пример:
INSERT INTO ASIGNMENT (WORKER_ID, BLDG_ID, START_DATE)
VALUES (1284, 485, 13.05.03)
UPDATE – изменить
DELETE – удалить
Операция реляционной алгебры, реализованная в SQL
UNION – оператор объединения
Пример:
TABLE <имя 1_таблицы> UNION TABLE <имя 2_таблицы>
INTERSECT – пересечение
Пример:
TABLE <имя 1_таблицы> INTERSECT TABLE <имя 2_таблицы>
EXCEPT – разность
JOIN – соединение таблиц
В результирующей таблице сначала располагаются общие столбцы, затем столбцы первой таблицы, затем оставшиеся столбцы второй таблицы.
Совместное использование SQL с языками обработки данных. Существуют способы, позволяющие интегрировать SQL – выражения в программах, написанные на на традиционных языках. Для этого используют встроенный SQL. В базовый язык можно «погружать» SQL – выражения.
Используются выражения – флаги, которые означают, что строки между ними – SQL – программа.
Представление данных. Это окно, через которое видна часть базы данных. Представления данных полезны для поддержания конфиденциальность путем ограничения доступа к определенным частям базы данных. Мы можем создать представление данных, показывающее всю информацию о работнике, кроме его оклада.
CREATE VIEW WORKER1
AS SELECT WORKER_ID, WORKER_NAME
FROM WORKER
Система на самом деле не создает значения данных для отношения WORKER1 до тех пор, пока к нему не обратятся. Таким образом, данные в представлении копируются из соответствующих таблиц при обращении к представлению.
Представления данных можно использовать в запросах (также как если бы это были таблицы).
Система сначала порождает данные представления, а затем применяет к ней запрос.
Метаданные. В реляционной системе информация, описывающая БД (это метаданные, т.е. данные о данных) поддерживается в виде таблиц как и все другие данные. К этим системным таблицам можно обращаться с помощью языка SQL.
3. Предметная область банка данных
Предметная область банка данных изучается путем выполнения обследования предприятия. На этапе обследования определяется сфера использования информационной системы. Определяются границы, формулируются цели проектирования информационных систем. После этого приступают к сбору сведений по нескольким направлениям:
Выявление производственных функций
выявление функций управления.
Производственная функция, пример использования:
Покупать товары с целью пополнения запасов на складе.
Комплектовать товары со склада, в соответствии с заказом.
Доставлять товары заказчикам и т. п.
Вывод: Стабильная БД может быть создана только в том случае, если ее структура основана на связях, образованных производственными функциями.
Способы выявления производственных функций. Рассылка каждому руководителю подразделения вопросников, примерно такого содержания:
Наименование работы для каждого из подчиненных
Производственные функции, выполняемые на каждом рабочем месте.
Краткое описание каждой производственной функции.
После этого составляется список работ по подразделениям, выявляются все производственные функции, по каждой производственной функции отбирают для собеседования 1-2 человека.
Проведение собеседований. Цели проведения собеседований.
Идентификация каждой производственной функции.
Идентификация данных, требуемых для выполнения этих функций.
Идентификация правил, инструкций, которые определяют когда, как и по каким правилам выполняется каждая функция.
Идентификация инструментов, с помощью которых выполняется каждая функция.
Результаты собеседований необходимо задокументировать (Рис.25).
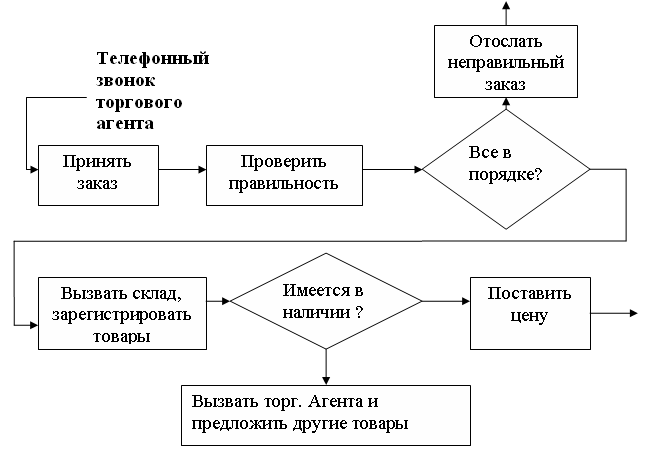
Рис.25. Документирование результатов
Выявление функций управления. На этапе выявления функций, связанных с контролем, правильностью выполнения некоторых операций или планирования, и необходимые для этого данные.
Например: функция «покупать товары» с целью пополнения заказов нВ складе, относится к производственным функциям. Функция «определить оптимальное количество товаров и время их закупки» относится к функции управления.
3.1. Методология функционального моделирования (idef0)
IDEF – интегральное определение данных.
Создатели методологии ставили целью разработки графического языка и набора процедур для анализа некоторой системы, прежде чем можно ее реализовать.
IDEF0 применяется на различных этапах создания системы, ее можно использовать на этапе разработки технического задания некоторой системы.
Более часто эта методология используется на начальных этапах разработки системы. На начальных этапах еще многое не известно и много допускается ошибок. Результатом применения методологии является модель. Модель состоит из совокупности диаграмм, которые состоят из блоков, фрагментов текста и т.п.
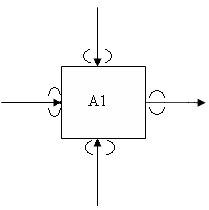
Блоки модели. На диаграмме все функции системы изображены в виде блоков (Рис.26), которые связаны между собой дугами или стрелками. Место соединения дуги с блоком, определяет тип интерфейса. Различают следующие варианты интерфейса:
Управляющие производством данные (функции), должны входить в блок сверху.
Материалы или информация, которые подвергаются производственным операциям, показываются с левой стороны блока.
Результаты операций – с правой стороны блока
Механизмы (люди, машины, системы, компьютеры), которые осуществляют операцию, входят в блок снизу.
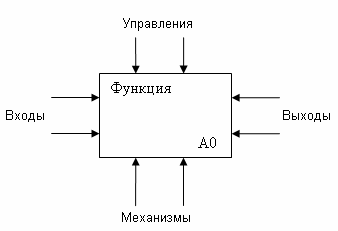
Рис.26. Пример блока модели
Название функции записывается внутри блока. Оно должно содержать глагольный оборот. Например: собрать блок, прикрепить деталь, измерить напряжение, разработать проект и т. п. Функции не должны выражаться существительным! Каждый блок должен иметь номер, который изменяется от 1 до 6 (7). Диаграмма, как правило, должна содержать не менее трех блоков.
Дуги. Дуги – материальные объекты или информация, которая нуждается или которая производит функция. Каждая дуга должна иметь метку, в виде оборота существительного. Например: заготовка(ки), обработка детали и т. п. Дуги с одним свободным концом представляют данные, источники которых находятся вне диаграммы. Внутри диаграммы блоки соединяются между собой дугами.
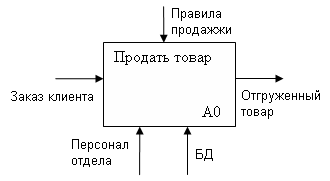
Рис.27. Пример дуг
Типы связей.
Прямая связь по входу.
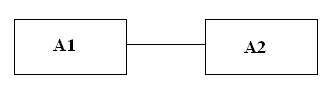
Рис.27.
Прямая связь по управлению.
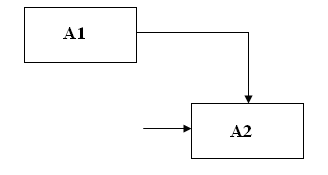
Рис.28.
Функция А2 не может быть выполнена, пока не будут доступны данные, произведенные блоком А1. Например, пока не будет разработан дальнейший план действий.
Прямая связь по механизму.
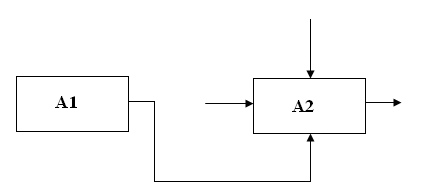
Рис.29.
Обратная связь по выходу.
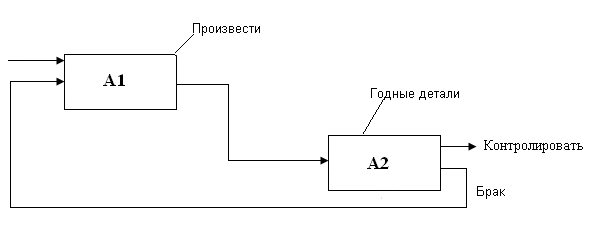
Рис.30.
Обратная связь по управлению.
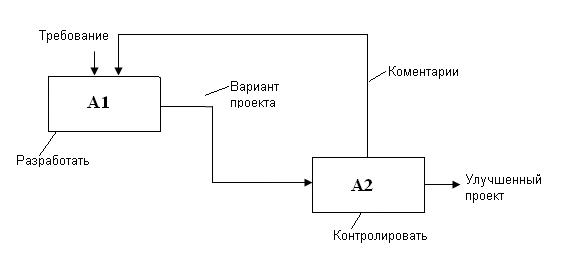
Рис.31.
Иерархия диаграмм. Модель IDEF0 состоит из серии диаграмм. Первоначально диаграмма является наиболее общим и абстрактным описанием всей системы. Первоначальная диаграмма может быть превращена в более подробную диаграмму. Каждая детализированная диаграмма является декомпозицией определенного блока из более общей диаграммы. Более общая диаграмма называется родительской. Более подробная – дочерней.
Моделирование начинается с построения контекстной диаграммы, она содержит контекстный блок, который обозначается А0. Она изображается на первой странице модели Р1 (Рис.32).
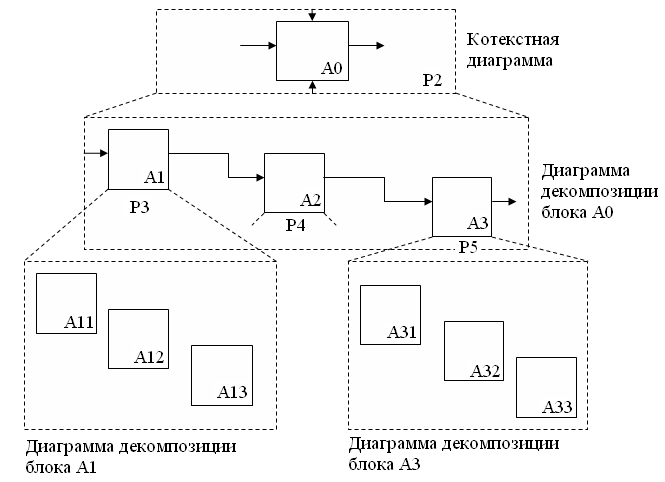
Рис.32. Иерархия диаграмм
Обозначения на рисунке 32:
Р2 – страница 2
Р3 – страница 3 и т.д.
A – Activity
А31– порядковый номер на диаграмме декомпозиции
номер декомпозируемого блока
Дерево узлов.
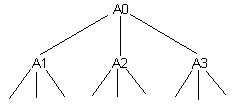
Рис.33. Дерево узлов
Кодирование граничных дуг. Граничные дуги кодируются с помощью ICOM кода. В процессе декомпозиции метки дуг, выходящие за пределы диаграммы, мигрируют на дочернюю диаграмму. Каждая метка соприкасается с ICOM кодом (I1, O1, M1 и т. д.). Может оказаться, что метки и соответствующие ICOM коды не видны на экране дисплея. В этом случае, используя способы прокрутки, надо их найти. После этого метки, которые мигрируют на диаграмму, необходимо подключить к соответствующему блоку дочерней диаграммы.
Туннельные дуги.
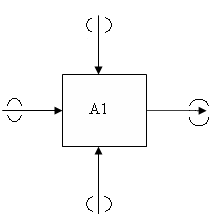
Две круглые скобки на свободном конце дуги означают, что эта дуга отсутствует на родительской диаграмме, и она не имеет ICOM кода.
( ) – обозначение туннеля.
Рис.34.
Две круглые скобки на конце, где дуга присоединяется к блоку означает, что эта дуга не появится на диаграмме декомпозиции, а ее ICOM код в дальнейшим не отслеживается.
Рис.35.
Внесение информации о функции в глоссарий. В тот момент, когда в функциональный блок вводится текст, информация об этой функции вносится в глоссарий.
Чтобы внести в глоссарий дополнительную информацию о функции, выделите нужный функциональный блок и выберите команду Glossary Entry (Элемент глоссария) из меню Glossary. Откроется диалоговое окно, которое изображено на рис.36.

Рис.36. Внесение информации о функции в глоссарий
Введите описание функции в поле Definition (Описание). Если функция является частью какой-либо структуры (организации, процесса и т.п.), введите ее наименование в поле Organization (Организация). В дополнение к полям ввода данных в этом диалоговом окне перечисляются входы (Inputs), Управляющие воздействия (Controls), выходы (Outputs) и механизмы (Mechanisms), т. е. ICOM – объекты для данной функции. Дважды щелкнув мышью на имени ICOM – объекта, вы можете открыть диалоговое окно для данного объекта. Когда функция уничтожается, информация о ней удаляется из глоссария.
Внесение информации об ICOM – метках в глоссарий. В тот момент, когда метка присоединяется к сегменту или когда источником или адресатом дуги является метка, эта метка вносится в глоссарий ICOM – объекта.
Чтобы внести в глоссарий дополнительную информацию о метке, присоединенной к сегменту дуги, выделите эту метку и выберите команду Glossary Entry (Элемент глоссария) из меню Glossary. Откроется диалоговое окно, которое изображено на рис.37.
Рис.37. Внесение информации об ICOM – метках в глоссарий
Введите описание ICOM – метки в поле Definition (Описание). Если для ICOM – объекта определены и (или) количество, введите соответствующие значения в поля Type (Тип) и Quantity (Количество).
Кроме полей ввода данных, в диалоговом окне представлена информация о классе объекта (ICOM Class), источнике (Source) и адресате дуги (Destination), представленной данным ICOM – объектом.
Если метка отсоединена от дуги, то ее значение остается в глоссарии до тех пор, пока она не будет уничтожена.
Особенности построения функциональной модели. Контекст – очерчивает границы модели с ее внешним окружением по средствам описания внешних интерфейсов, т. е. Входов, выходов, управлений и механизмов.
Точка зрения – на одну и туже систему, можно посмотреть с различных точек зрения. Например, на какую-то торговую организацию можно посмотреть глазами поставщика товаров, заказчика товара, глазами управляющего этой организации, глазами персонала.
Точка зрения должна определить, что можно увидеть в модели, и под каким углом зрения.
Цель – определить для чего нужна проектируемая система и с какой целью она функционирует.
Построение контекстной диаграммы. Контекстная диаграмма строится после внимательного чтения текстового описания деятельности организации. Например (Рис.38), Торговая фирма приобрела у своих поставщиков разнообразные товары, по сравнительно низким ценам, поскольку объемы сделок достаточно велики, прибыль фирмы образуется за счет перепродажи тех же товаров, розничная продажа по более высоким расценкам, хотя и меньшими партиями, эти розничные торговцы, являются клиентами фирмы.
Моделирование начинается с построения контекстной диаграммы, содержащей один блок. Этому блоку должно быть присвоено имя, которое должно охватывать всю сферу деятельности системы.
Назовем ее «Продажи товаров», но продать товары можно лишь после их закупки и хранения на складе, следовательно название не верное. Подбираем более общее название «Деятельность предприятия торговли». После этого определяем внешний интерфейс.
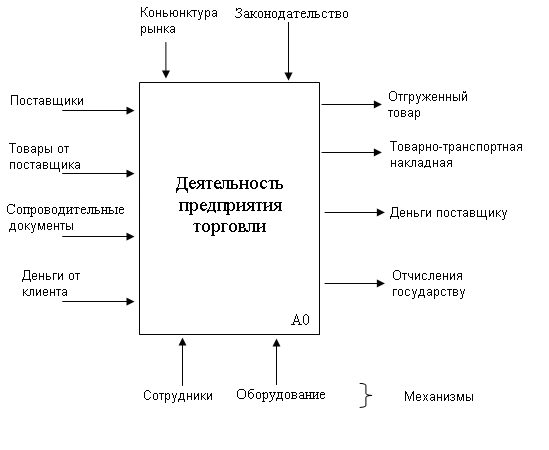
Рис.38. Детализация диаграммы А0
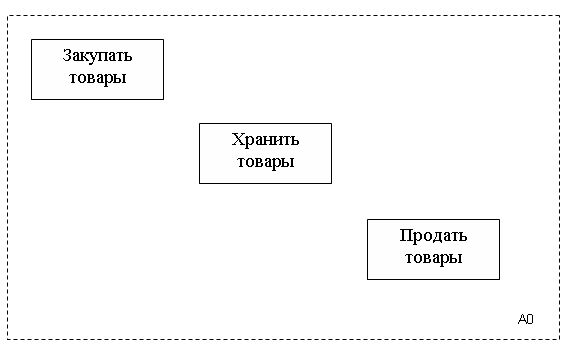
Рис.39. Детализация блока А0
Организация связей между страницами модели. Постановка задачи: после щелчка мышью по какому-либо объекту диаграммы IDЕF0 должен быть выполнен переход на другую страницу, на которой смысл этого объекта выясняется более подробно. Затем необходимо выполнить обратный переход на какую-либо диаграмму.
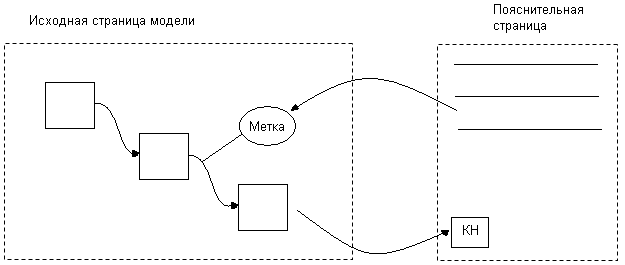
Рис.40. Организация связей между страницами модели
Создание новой страницы Create / New Page. Обычными средствами создаются новые объекты. Результаты сохраняются на диске.
Возврат на исходную страницу: Select / Page; Показывается список страниц, следует выбрать нужную страницу и перейти на нее.
Связывание метки модели с пояснительной страницей.
3.1. Выделяем метку в исходной модели
3.2. Выполняем команды Modify / Attach – показывается список страниц, и щелкаем по присоединенной, связываем таблицы.
Переход на пояснительную таблицу.
Создание кнопки для обратного перехода. Поместим на пояснительную страницу, кнопку обратного перехода (название).
Связывание кнопки с исходной страницей
Выделить созданную кнопку.
Выполнить команду Design / Attach
Окончательная проверка правильности перехода.
Разрыв связей между страницами. Если связь выполнена не верно, или ее нужно разорвать.
Выделить объект, связь которого со страницей необходимо разорвать.
Выполнить команду Modify или Design / Detach.
Удаление страниц.
Меню Edit / Delete:
This Page Only – удалить только текущую страницу.
This Page and Sub pages – Удалить текущую страницу и все подстраницы.
Коллективная работа над моделью. Можно включить IDЕF0 – подмодели в другую IDFЕ0, сохраняя при этом целостную иерархию программ.
Это позволяет коллективу разработчиков эффективно работать вместе при создании объединенных больших моделей.
На рисунке приведен пример декомпозиции контекстной диаграммы. Эта работа выполняется руководителем группы моделирования. После этого руководитель распределяет работы, связанные с моделированием, между отдельными исполнителями. Рассмотрим последовательность действий второго, которому поручили декомпозицию блока А2.
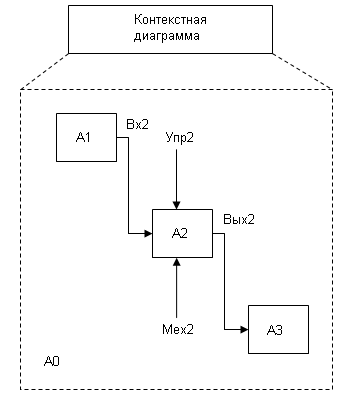
Рис.41. Пример коллективной работы над моделью
Создание страницы с определенным пользователем номером узла.
Создание нового файла File / New окно Select New Page Type.
Выбирается из списка Methodology пункт IDF0 Leaf.
Вводится в поле номер декомпозируемого блока (А2).
В разделе Browse … выбрать None → OK/
Создать подмодель (Рис.42).
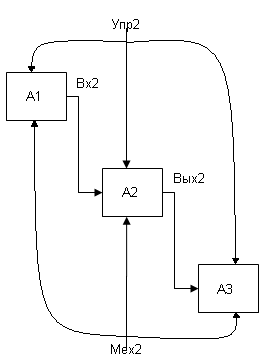
Рис.42. Подмодель
Важно, чтобы портовые узлы подмодели, совпадали с портовыми узлами декомпозируемого блока. Название узлов лучше копировать.
Записать модель в файл PMod. IDD.
Открыть основной файл
Объединить основные модели и подмодели.
Открыть основной файл.
File / Import. Выбирается нужный файл с расширением .IDD. Появляется диалоговое окно.
4. Инфологическое проектирование бд
Модель «Сущность - связь». Эта модель предложена ученым П. Ченом его статье Модель «Сущность - связь» - шаг к единому пониманию данных. В модели используется представление в соответствии с которым «реальный мир» состоит из «сущностей» и «связей».
Сущность (Entity) – это «предмет», который может быть идентифицирован некоторым способом, отличающим его от других «предметов». Конкретный человек, компания или работа являются примерами сущности.
Связь (Relationship) – это ассоциация, устанавливаемая между сущностями.
БД предприятия содержит информацию о сущностях и связях, которые представляют интерес для предприятия.
Модель изображается в виде диаграммы (Diagrams).
У различных авторов эти модели обозначаются как ER – модели, ER – диаграммы, ERD – диаграммы. В настоящее время правила построения ER – моделей изложены в методологии (стандарте) IDEF1X.
4.1. Методология idef1x
Методология IDEF1X применяется для построения информационной модели, которая представляет структуру информации, необходимой для поддержки функций производственной системы.
Построение IDEF1X-модели тесно связано с понятием управления данными, того, чтобы управлять данными, необходимо понимать их основные характеристики и организацию с целью дальнейшей интерпретации этих данных.
Методология IDEF1X была разработана в США и теперь используется в правительственных, аэрокосмических и финансовых учреждениях, а также в большом числе частных компаний.
Методология IDEF1X определяет стандарты терминологии, используемой при информационном моделировании, и графического изображения типовых элементов на диаграммах.
IDEF1X использует подход сущностей - отношений к семантическому моделированию данных. Разработка IDEF1X базируется на понятиях сущности-отношения по методу П.Чена, объединенных с понятиями реляционной теории Т.Кодда.
Компонентами IDEF1 Х-модели являются сущности, отношения и атрибуты.
Сущности. Семантика сущностей. Сущность представляет множество реальных или абстрактных предметов (людей, объектов, мест, событий, состояний, идей, пар предметов и т.п.), обладающих общими атрибутами. Отдельный элемент этого множества называется экземпляром сущности. Реально существующий объект или предмет может быть представлен в нескольких сущностях модели данных. Например, Иванов может быть, экземпляром каждой из сущностей СЛУЖАЩИЙ и ПОКУПАТЕЛЬ. Кроме того, экземпляр сущности может представлять комбинацию существующих объектов. Например, Александр и Мария могут быть экземпляром сущности СУПРУЖЕСКАЯ_ПАРА.
Сущность является независимой от идентификаторов или просто независимой, если каждый экземпляр сущности может быть однозначно идентифицирован без определения его отношений с другими сущностями. Сущность называется зависимой от идентификаторов или просто зависимой, если однозначная идентификация экземпляра сущности зависит от его отношения к другой сущности.
Синтаксис сущностей. Сущность изображается прямоугольником. Если сущность зависима от идентификаторов, то углы блока закругляются. Каждой сущности присваивается уникальное имя и номер, разделяемые косой чертой и помещаемые над блоком. Номер сущности - положительное целое число. Именем сущности является грамматический оборот существительного (существительное, у которого могут быть прилагательные и предлоги), описывающий представляемое сущностью множество предметов.
Существительное должно употребляться в единственном, а не во множественном числе. На диаграмме сущность должна быть представлена только один раз.
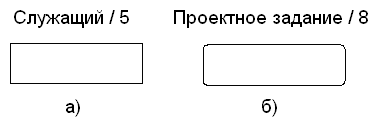
Рис.43. Изображение сущности:
а) независимая сущность;
б) зависимая сущность.
Правила, связанные с сущностями. Каждая сущность должна иметь уникальное имя. Сущность обладает одним или несколькими атрибутами, которые либо принадлежат сущности, либо наследуются через отношение (внешние ключи).
Сущность обладает одним или несколькими атрибутами, которые однозначно идентифицируют каждый экземпляр сущности (первичные и альтернативные ключи).
Каждая сущность может обладать любым количеством отношений с другими сущностями модели.
Если внешний ключ целиком используется в качестве первичного ключа или его части, то сущность является зависимой от идентификатора.
Семантика отношений связи. Специфическое отношение связи или просто отношение связи, называемое также отношение родитель-потомок, это ассоциация или связь между сущностями, при которой каждый экземпляр одной сущности, называемой родительской сущностью, ассоциирован с произвольным (в том числе нулевым) количеством экземпляров второй сущности, называемой сущностью-потомком, а каждый экземпляр сущности-потомка ассоциирован в точности с одним экземпляром сущности-родителя (Рис.44).
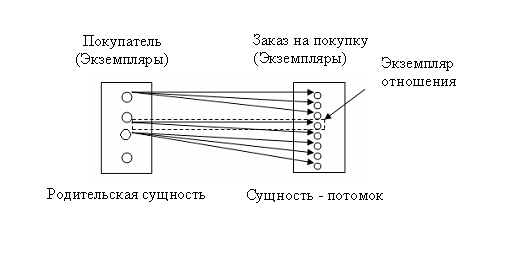
Рис.44. Диаграмма экземпляров сущностей
Если экземпляр сущности-потомка однозначно определяется своей связью с сущностью-родителем, то отношение называется идентифицирующим отношением. Например, если с каждым проектом связано одно или более заданий и задания однозначно идентифицируются только в пределах своего проекта, то между сущностями ПРОЕКТ и ЗАДАНИЕ будет существовать идентифицирующее отношение.
Если каждый экземпляр сущности-потомка может быть однозначно идентифицирован без знания связанного с ним экземпляра сущности-родителя, то отношение называется неидентифицирующим отношением. Например, хотя между сущностями ПОКУПАТЕЛЬ и ЗАКАЗ_НА_ПОКУПКУ может существовать отношение зависимого существования, заказы на покупку могут однозначно идентифицироваться номером заказа на покупку без идентификации ассоциированного покупателя.
Отношение связи дополнительно определяется с помощью указания мощности отношения. А именно определяется, какое количество экземпляров сущности-потомка может существовать для каждого экземпляра сущности-родителя.
В IDEF1X используется несколько вариантов указания мощность отношения.
Синтаксис отношения связи. Специфическое отношение связи изображается линией, проводимой между сущностью-родителем и сущностью-потомком с точкой на конце линии у сущности-потомка. Мощность по умолчанию - «ноль, один или много». Буква Р (positive) означает мощность «один или много» и помещается около точки. Буква Z (zero), помещенная около точки, означает мощность «ноль или один». Если мощность в точности равна некоторому числу N, это число (целое, положительное) помещается около точки (Рис.45).
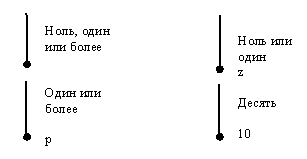
Рис.45. Изображение отношений связи
Идентифицирующее отношение между сущностью-родителем и сущностью-потомком изображается сплошной линией (Рис.46,а). При этом атрибуты первичного ключа сущности-родителя наследуются атрибутами первичного ключа сущности-потомка.
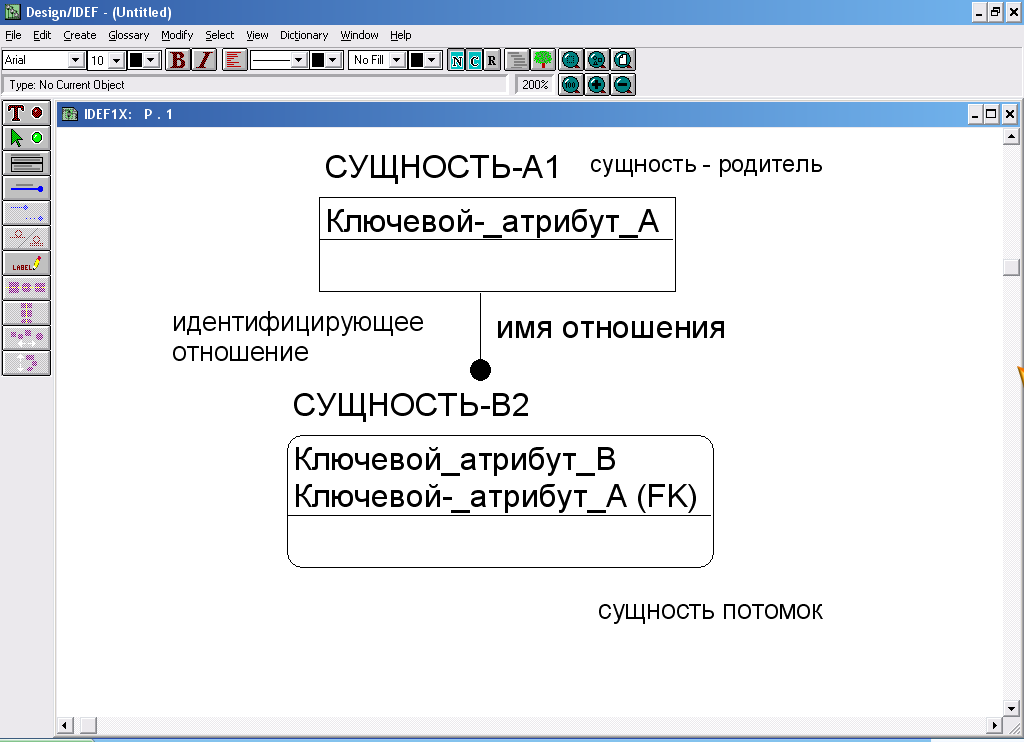
Рис.46,а. Пример идентифицирующего отношения

Рис.46,б. Пример неидентифицирующего отношения
Пунктирная линия изображает неидентифицирующее отношение между сущностью-родителем и сущностью-потомком (Рис.46,б). Атрибуты первичного ключа сущности-родителя мигрируют в область неключевых атрибутов сущности-потомка.
Отношению дается имя, выраженное грамматическим оборотом глагола и помещаемое возле линии отношения. Имя каждого отношения между двумя сущностями должно быть уникальным, но имена отношений в модели не обязательно должны быть уникальными. Имя отношения в большинстве случаев формируется с точки зрения родителя. Например, утверждение «Проект состоит из одного или более заданий» может быть выведено из отношения, изображающего ПРОЕКТ а качестве сущности-родителя, ЗАДАНИЕ - в качестве сущности-потомка с символом мощности Р, СОСТОИТ_ИЗ - в качестве имени отношения.
Правила отношений. Специфическое отношение всегда имеет место между двумя сущностями, сущностью-родителем и сущностью-потомком.
Экземпляр сущности-потомка всегда должен быть связан в точности с одним экземпляром сущности-родителя.
Экземпляр сущности-родителя может быть связан с любым числом (от нуля и более) экземпляров сущности-потомка.
В идентифицирующем отношении сущность-потомок всегда является зависимой от идентификаторов сущностью.
Сущность может быть связана с любым количеством других сущностей, как в качестве потомка, так и качестве родителя.
Состав предприятия описывающего отношение связи двумя сущностями:
Имя сущности-родителя;
Имя отношения связи;
Мощность отношения:
Имя сущности - потомка.
Например, «Врач участвовал в 0,1 или нескольких приемах больного» (Рис.47)
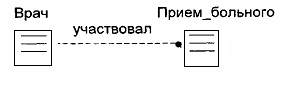
Рис.47. Чтение отношения связи
Отношения категоризации. Предположим, что, необходимо описать сущность СЛУЖАЩИЙ. Среди служащих имеются две группы:
Служащие почасовики;
Штатные служащие;
Известно, что заработанная плата штатных служащих определяется окладом, а заработанная плата почасовиков зависит от числа отработанных часов.
В таблице 12 показан один из вариантов организации таблицы, соответствующей сущности СЛУЖАЩИЙ.
Таблица 12 СЛУЖАЩИЙ
Табельный номер |
Фамилия |
Дата рождения |
Телефон |
Отработано часов |
Оклад |
1 2 3 4 |
Иванов Петров Сидоров Воронов |
20.06.1940 10.08.1949 25.07.1963 29.01.1946 |
226937 227038 755033 753821 |
100
150 |
5000
4000 |
Колонки «Отработано часов» и «Оклад» этой таблицы оказываются частично заполнены данными. Это приводит к неэффективному использованию памяти компьютера. Использование отношений категоризации позволяет избавиться от этого недостатка.
Семантика отношений категоризации. Некоторые существующие объекты являются категориями других реально существующих объектов, поэтому сущности могут быть категориями других сущностей. Например, для общей сущности СЛУЖАЩИЙ можно указать две сущности-категории: ШТАТНЫЙ_СЛУЖАЩИЙ и СЛУЖАЩИЙ_ПОЧАСОВИК (Рис.48). Сущности-категории вводятся, например, для отражения особенностей выплаты заработной платы различным категориям служащих.
Отношение полной категоризации - отношение между двумя или более сущностями, в котором каждый экземпляр одной сущности, называемой общей сущностью, связан в точности с одним экземпляром одной и только одной из других сущностей, называемых сущностями-категориями.
Каждый экземпляр общей сущности и связанный с ним экземпляр одной из категорных сущностей изображают один и тот же предмет реального мира и поэтому обладают одним и тем же уникальным идентификатором.
Сущности-категории, связанные с одной общей сущностью, всегда являются взаимоисключающими, т.е. экземпляр общей сущности может соответствовать экземпляру только одной сущности-категории. Из этого следует, например, что служащий не может быть одновременно и штатным и почасовиком.
IDEF1X допускает, однако, существование неполного множества категорий. Если существует экземпляр общей сущности, не связанный ни с каким экземпляром из сущностей-категорий то такое отношение называется отношением неполной категоризации.
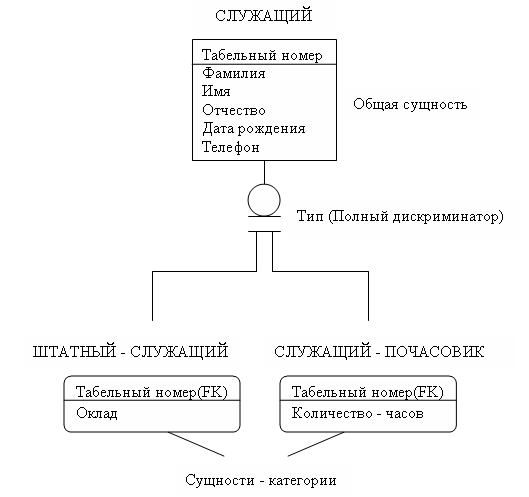
Рис.48. Отношение категоризации
Значение некоторого атрибута в экземпляре общей сущности определяет, с какой из возможных сущностей категории он связан. Этот атрибут называется дискриминатором отношения категоризации. В примере дискриминатором является атрибут ТИП.
Синтаксис отношений категоризации. Отношение категоризации изображается линией, ведущей из общей сущности к подчеркнутому кругу. Отдельные линии ведут от подчеркнутого круга к каждой из сущностей-категорий. Для сущности-категории мощность не указывается, поскольку она всегда равна нулю или единице. Сущности-категории всегда зависимы от идентификаторов.
Если круг подчеркнут дважды, это указывает на полноту множества сущностей-категорий (Рис.48). Если круг подчеркнут один раз, это указывает на неполноту множества категорий. Имя атрибута общей сущности, используемое в качестве дискриминатора, записывается рядом с кружком.
Отношение категоризации не именуется, но может звучать, как «может быть».
Общая сущность и каждая сущность-категория должны иметь одинаковые ключевые атрибуты.
Правила отношений категоризации. Сущность категория может иметь только одну общую сущность. Сущность-категория может быть общей сущностью в другом отношении категоризации.
Атрибуты первичного ключа сущности-категории должны совпадать с атрибутами первичного ключа общей сущности.
Все экземпляры сущности - категории имеют одно и то же значение дискриминатора (Рис.49)
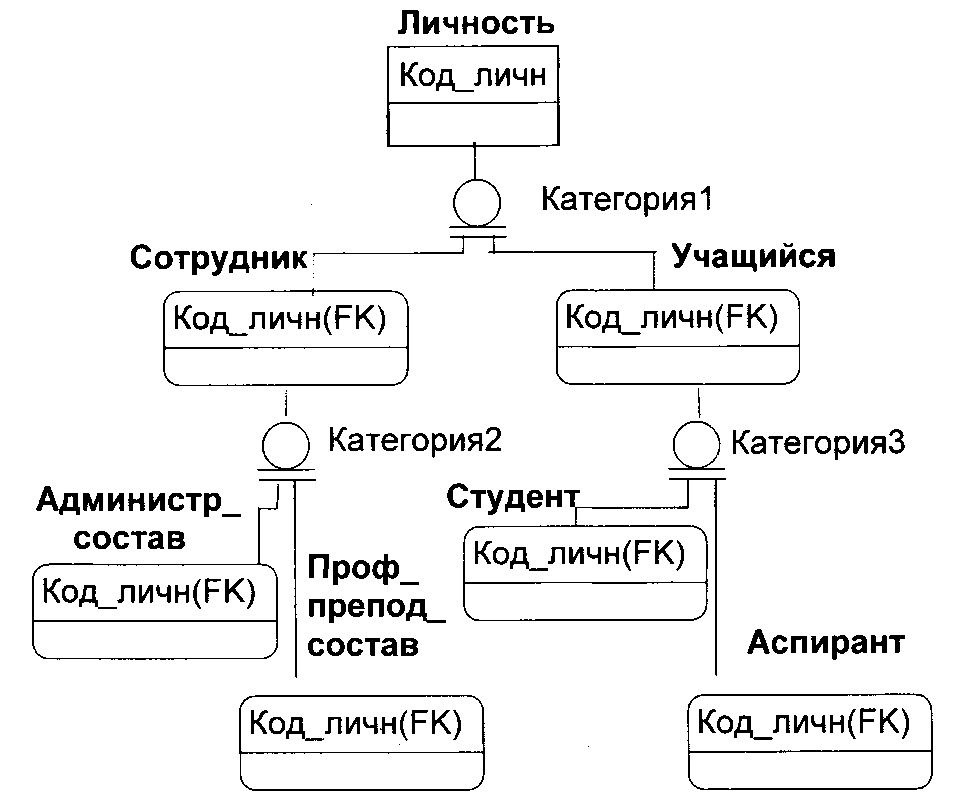
Рис.49. Многократное использование символа категории
Неспецифические отношения. Отношение родитель - потомок и отношение категоризации рассматриваются как специфические отношения. Однако при первоначальной разработке модели часто полезно устанавливать неспецифическое отношение между двумя сущностями.
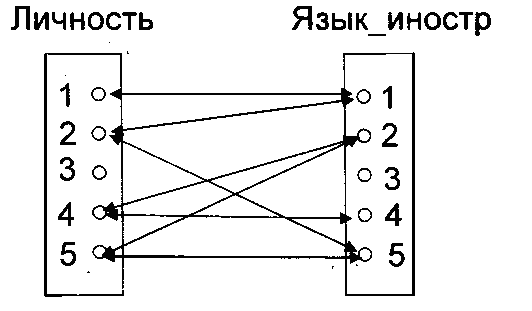
Рис.50. Диаграмма экземпляров неспецифического отношения
Неспецифическое отношение, называемое также отношением много ко многому, это связь между двумя сущностями, при которой каждый экземпляр первой сущности связан с произвольным (в том числе и нулевым) количеством экземпляров второй сущности, а каждый экземпляр второй сущности связан с произвольным (в том числе и нулевым) количеством экземпляров первой сущности (Рис.51).
Рис.51. Изображение неспецифического отношения в ER-модели
Неспецифическое отношение изображается линией, соединяющей две связанные сущности и имеющей точки на обоих концах. Мощность может указываться на обоих концах отношения. Неспецифическому отношению дается двойное имя (Рис.51).
При дальнейшей разработке неспецифические отношения заменяются на специфические путем введения третьей сущности, называемой сущностью-пересечением или ассоциативной сущностью.
На рисунке 52 показан пример замены неспецифического отношения между сущностями ЛИЧНОСТЬ и ЯЗЫК_ИНОСТРАННЫЙ двумя специфическими отношениями с третьей сущностью ЗНАНИЕ_ЯЗЫКА.
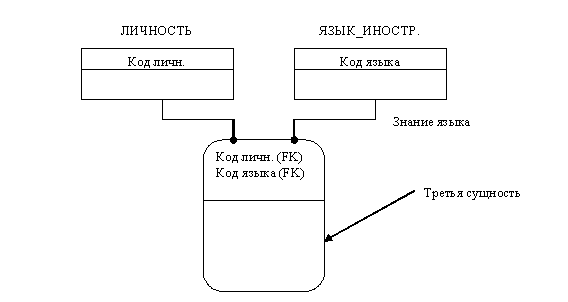
Рис.52. Замена неспецифического отношения на специфические
Третья сущность может содержать свои ключевые и неключевые атрибуты (Рис.53).
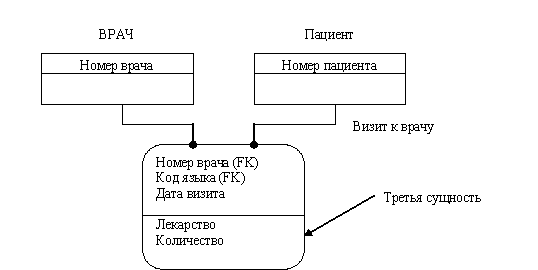
Рис.53. Назначение дополнительных атрибутов в сущности – пересечении
Атрибуты. Семантика атрибутов. Атрибут представляет тип характеристик или свойств, ассоциированных со множеством реальных или абстрактных объектов. Экземпляр атрибута определяется типом характеристики и ее значением, называемым значением атрибута.
Сущность должна обладать атрибутом или комбинацией атрибутов, чьи значения однозначно определяют каждый экземпляр сущности. Эти атрибуты образуют первичный ключ сущности. Например, первичным ключом сущности СЛУЖАЩИЙ является атрибут ТАБЕЛЬНЫЙ_НОМЕР, тогда как атрибуты ФАМИЛИЯ, ТЕЛЕФОН и т.д. будут другими (неключевыми) атрибутами.
В дополнение к «собственным» атрибутам сущности, атрибут может «наследоваться» сущностью через специфическое отношение или отношение категоризации, в котором сущность является сущностью-потомком. Например, если каждый служащий приписан к какому-нибудь отделу, то атрибут НОМЕР_ОТДЕЛА может быть атрибутом сущности СЛУЖАЩИЙ, наследуемым через отношение сущности СЛУЖАЩИЙ к сущности ОТДЕЛ.
Синтаксис атрибутов. Каждый атрибут идентифицируется уникальным именем, выражаемым грамматическим оборотом существительного. Существительное должно быть в единственном числе. Каждый атрибут внутри блока сущности занимает одну строку. Атрибуты, определяющие первичный ключ, размещаются наверху списка и отделяются горизонтальной чертой.
Первичные и альтернативные ключи. Семантика первичных и альтернативных ключей. Возможный ключ сущности — это один или несколько атрибутов, чьи значения однозначно определяют каждый экземпляр сущности. Например, ТАБЕЛЬНЫЙ_НОМЕР однозначно определяет экземпляр сущности СЛУЖАЩИЙ (Рис.54).
Каждая сущность должна обладать хотя бы одним возможным ключом. В некоторых случаях сущность может иметь более одного атрибута, однозначно идентифицирующих экземпляры сущности.
При существовании нескольких возможных ключей один из них выбирается в качестве первичного ключа, а остальные - как альтернативные ключи.
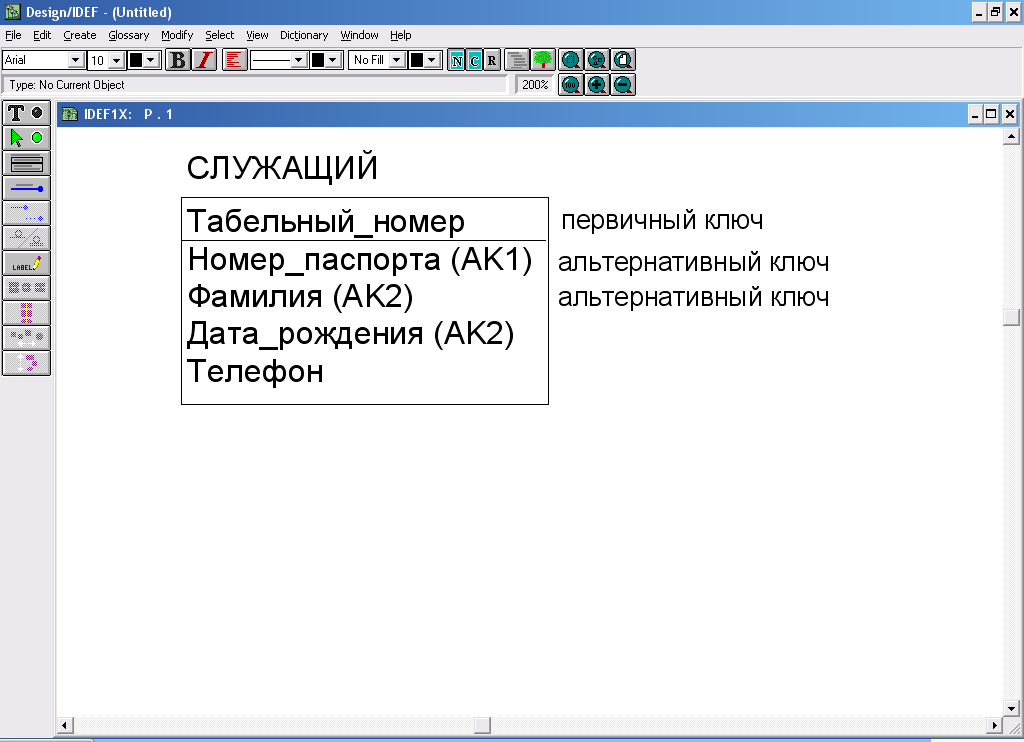
Рис.54. Ключевые и неключевые атрибуты сущности СЛУЖАЩИЙ
Синтаксис первичных и альтернативных ключей. Определяющие первичный ключ атрибуты размещаются наверху списка атрибутов в, блоке сущности и отделяются от других атрибутов горизонтальной чертой (Рис.54).
Каждому альтернативному ключу присваивается уникальный целый номер. Этот ключ указывается с помощью размещения справа от каждого атрибута ключа заключенных в скобки букв АК с номером альтернативного ключа. Отдельный атрибут может входить в качестве компоненты в более чем один альтернативный ключ.
Внешние ключи. Семантика внешних ключей. Если между двумя сущностями имеется специфическое отношение связи или категоризации, то атрибуты, входящие в первичный ключ родительской или общей сущности, наследуются в качестве атрибутов сущностью-потомком или категорией сущностью соответственно. Эти наследуемые атрибуты называются внешними ключами. Например, на рис.55 сущности ШТАТНЫЙ_СЛУЖАЩИЙ и СЛУЖАЩИЙ_ПОЧАСОВИК наследуют атрибут (внешний ключ) ТАБЕЛЬНЫЙ_НОМЕР.
Наследуемый атрибут может использоваться в сущности в качестве части или целого первичного ключа, альтернативного ключа или неключевого атрибута.
Если все атрибуты первичного ключа сущности-родителя наследуются в качестве части первичного ключа сущности-потомка, то отношение называется идентифицирующим.
Если какой-нибудь из наследуемых атрибутов не является частью первичного ключа, то отношение называется неидентифицирующим.
В некоторых случаях сущность-потомок может иметь несколько отношений с одной и той же сущностью-родителем. Первичный ключ сущности-родителя появится для каждого отношения в качестве наследуемых атрибутов в сущности-потомке. Для каждого факта наследования первичного ключа должно назначаться имя роли.
Синтаксис внешних ключей. Внешний ключ изображается с помощью помещения внутрь блока сущности-потомка имен наследуемых атрибутов, после которых следуют буквы FK в скобках (FK).
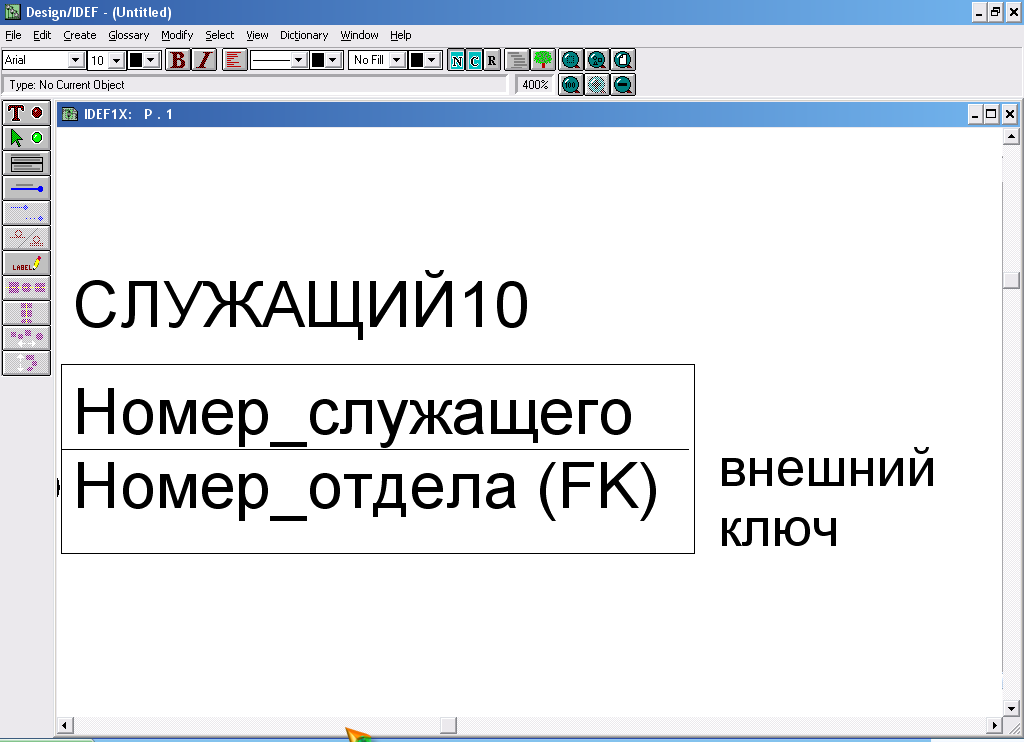
Рис.55,а. Пример изображения внешних ключей
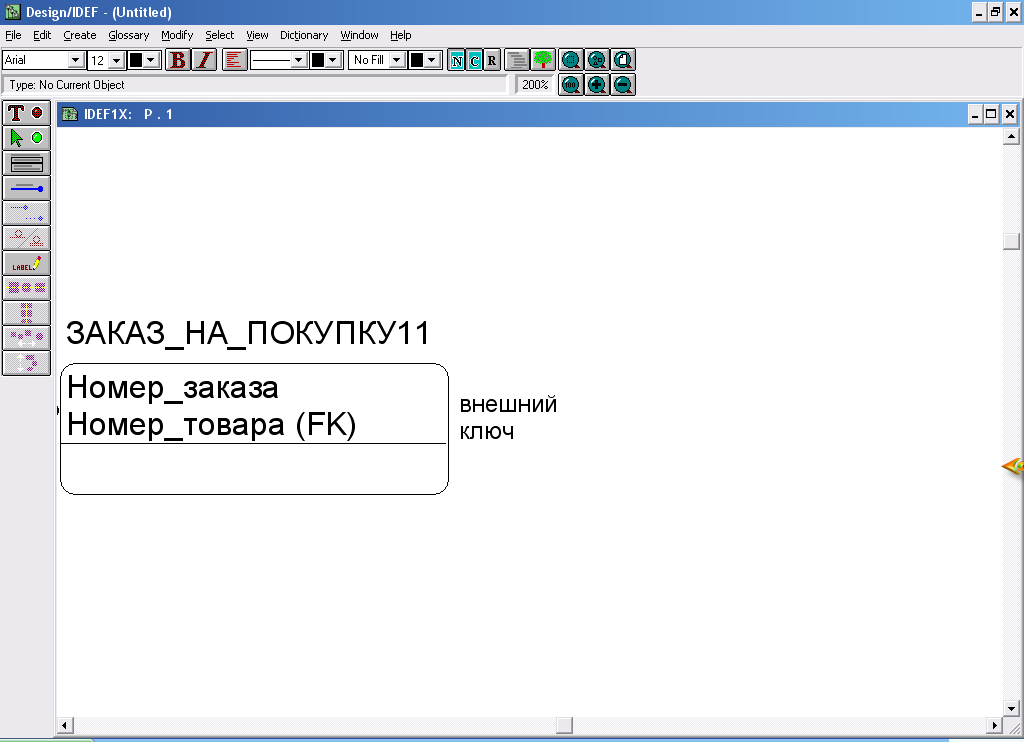
Рис.55,б.
Если наследуемый атрибут не принадлежит первичному ключу сущности-потомка, то он изображается ниже горизонтальной линии (рис.56а). Если наследуемый атрибут принадлежит первичному ключу сущности-потомка, то он помещается выше линии, а сущность изображается блоком с закругленными углами (рис. 56,б).
Наследуемые атрибуты могут быть также частью альтернативного ключа.
5. Рекурсивное отношение
Рекурсивное отношение – это отношение, связывающее сущность саму с собой.
Рекурсивный внешний ключ – внешний ключ, ссылающийся на свою собственную реляционную таблицу.
Рассмотрим таблицу СОТРУДНИК, в которой содержатся сведения о сотрудниках и их руководителях. Например, сотрудник с номером 1311 является руководителем сотрудника 1412. сотрудники Сидоров и Чернов не имеют руководителей (Рис.56).
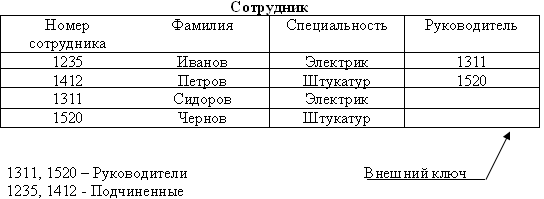
Рис.56. Пример рекурсивного отношения
Значения чисел колонки «Руководитель» выбирается из множества значений чисел зафиксированных в колонке «Номер сотрудника». Говорят, что первичный ключ сущности СОТРУДНИК мигрирует в эту же сущность. Но в сущности не может быть двух одинаковых атрибутов, поэтому имя мигрировавшего атрибута должно быть изменено на другое – имя роли, т.е. «Руководитель».
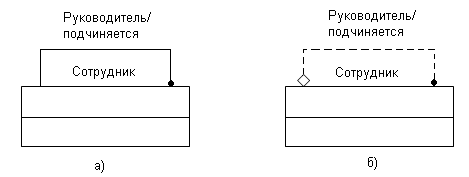
Рис.57. Изображение рекурсивного отношения:
а) – неправильное изображение
б) – правильное изображение
Следует обратить внимание на то, что отношение всегда должно быть необязательно. Если какая-либо из сторон отношения обязательная (Рис.57,а), то в результате получается бесконечная иерархия, это означает, что у сотрудника обязательно должен быть начальник. Если это верно, то кто является начальником самого высшего должностного лица организации? В равной степени недопустимо делать правую сторону обязательной (на рис. 57,а на это указывает символ Р) – в этом случае каждый сотрудник должен кем-то руководить. На рис. 57,б показан правильный вариант изображения рекурсивного отношения (пунктирная линия с символом необязательности связи слева – ромб, и отсутствием символа Р около точки справа).
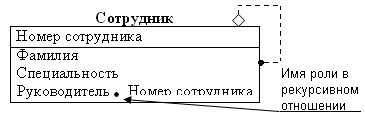
Рис.58. Рекурсивное отношение связи для сущности СОТРУДНИК
В рекурсивном отношении собственный ключ (например, номер сотрудника) определенным образом переходит во внешний ключ (Рис.58).
Впереди мигрировавшего атрибута указывается имя роли, т.е. «Руководитель». Если имя роли не использовать, то при миграции атрибута Номер сотрудника он должен появиться в сущности СОТРУДНИК еще один раз. Но известно, что двух одинаковых атрибутов в сущности не должно быть.
Имя роли – это синоним атрибута внешнего ключа, который показывает какую роль он играет в дочерней сущности (в рекурсивном отношении – в своей сущности).
Связь сущностей более чем через одно отношение.
Один и тот же атрибут сущности-родителя может порождать в сущности-потомке более одного внешнего ключа. Так происходит при миграции атрибута в сущность-потомок более чем через одно отношение. В этом случае атрибут появляется внутри сущности более одного раза, что приводит к необходимости отличать одно появление от другого. Для этого каждому вхождению атрибута в дочернюю сущность может быть присвоено имя роли, показывающее, чем одно появление отличается от другого. В примере, показанном на рис.59, атрибут «Номер валюты» получил имена ролей «Проданная» и «Купленная».
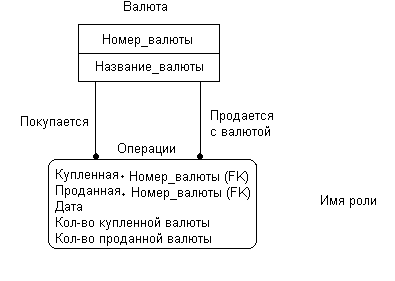
Рис.59. Связь сущностей более чем через одно отношение
На рис. 59 приведены данные хранящиеся в таблицах ВАЛЮТА и ОПЕРАЦИИ С ВАЛЮТОЙ. Необходимо обратить внимание на то, что запись с номером 4 не может быть введена в таблицу ОПЕРАЦИИ С ВАЛЮТОЙ потому, что делается попытка ввести в колонке «Проданная» значение 5, но такая валюта не указана в таблице ВАЛЮТА.
Таблица 13 Валюта
-
Номер валюты
Название валюты
1
Рубль
2
Доллар
3
Франк
4
Марка
---
---
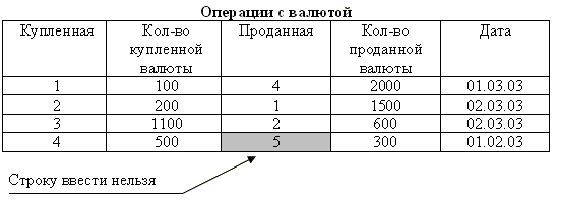
Рис.60. Особенности ввода данных в связанные таблицы
6. Примеры разработки информационных моделей
1. В функциональной модели есть функция с названием ОТПУСК ТОВАРОВ. Информационная модель информационной поддержки выполнения этой функции изображена на рис. 61. сведения о товарах хранятся в таблице ТОВАР, а сведения о фактах отпуска товаров – в таблице ОТПУСК ТОВАРОВ.
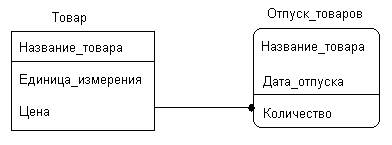
Рис.61. Информационная модель для функции ОТПУСК ТОВАРОВ
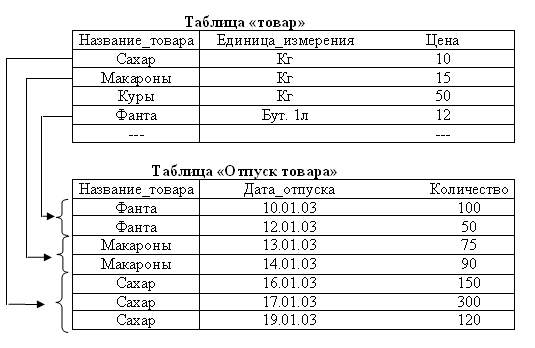
Рис.62. Данные хранящиеся в таблицах ТОВАР и ОТПУСК ТОВАРОВ
Таблица ТОВАР является справочником товаров хранящихся, например, на складе (Рис.62). Товар может быть отпущен со склада многократно. Для однозначной идентификации факта отпуска однотипных товаров в первичном ключе сущности ОТПУСК ТОВАРОВ используется дополнительный атрибут ДАТА ОТПУСКА.
Оформление заказа на товары (Рис.63).
Клиенты некоторой фирмы заказывают товары. На заказываемые товары сотрудники фирмы оформляют заказ. В заказе в общем случае содержится несколько строк в которых указываются сведения о заказанных товарах и их количестве. Другой сотрудник фирмы комплектует заказ и упаковывает его. Еще один выполняет операцию погрузки и доставки товаров клиенту. Каждый сотрудник занимает определенную должность.
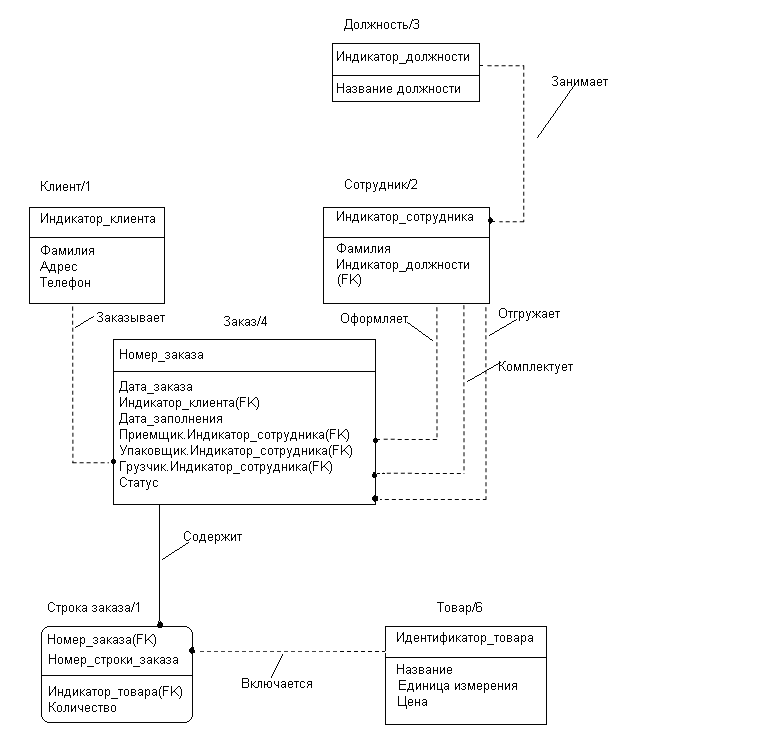
Рис.63. Пример разработки информационных моделей
Альтернативныe варианты изображения моделей. Сущность изображается в виде прямоугольников, а атрибуты в виде эллипсов «окружающих» прямоугольник сущности. Имя отношения записывается внутри ромба (Рис.64). Мощность отношения обозначается следующим образом:
0, 1 – мощность «ноль или один»;
1, 1 – мощность «один»;
1,* – мощность «один или много».
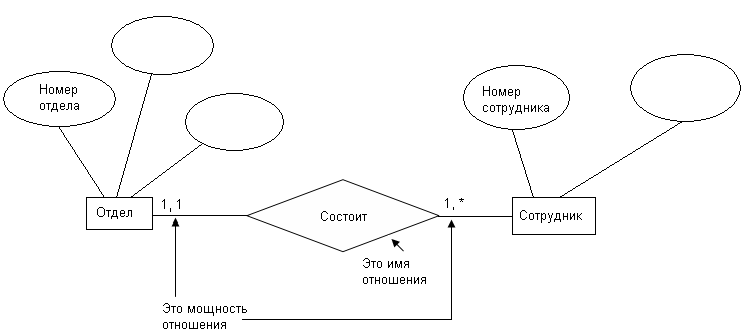
Рис.64. Альтернативный способ изображения сущностей, атрибутов и связей
1, * читается так «отдел состоит из одного или нескольких сотрудников».
Другой вариант.
Обязательность связи (класс принадлежности) иногда изображается в виде поля в прямоугольнике сущности
Например, на рис.65, а изображена модель, которую можно прочитать так: «Преподаватель читает 0, 1 или более лекций» и «Каждый курс читается 0 или 1 преподавателем», т. е. Отношение связи необязательное.
На рис.65, б у сущности ПРЕПОДАВАТЕЛЬ выделено поле (класс ее принадлежности обязателен), т. е. «Каждый преподаватель читает 1 или несколько курсов» или «Курс читается 0 или 1 преподавателем».
На рис.65, в показан вариант обязательного участия каждой из сущностей. Эту модель можно прочитать так: «Каждый преподаватель читает 1 или несколько курсов» или «Курс читает 1 преподаватель».
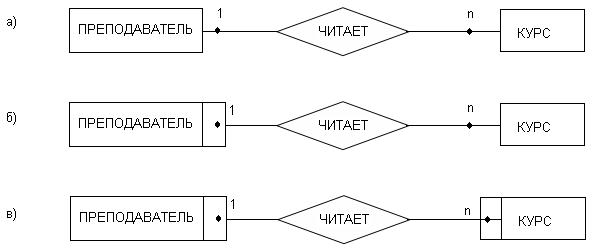
Рис.65. Варианты указания обязательности связи
а) Преподаватель читает 0, 1 или более курсов.
б) В сущности Преподаватель выделено поле, следовательно класс его принадлежности обязателен. Каждый преподаватель читает один или несколько курсов или курс читается 0, 1 преподавателем.
в) Показан вариант обязательного варианта каждой сущности.
Одной из нотаций (Рис.66) является нотация Баркера. Используется в технологии создания ИС фирмы ORACLE (CASE – средство Oracle Designer)
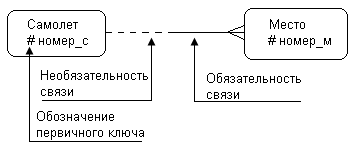
Рис.66. Нотация Баркера
* - обозначение обязательного атрибута;
0 - обозначение необязательного атрибута;
![]() -
аналог не идентифицирующего отношения
-
аналог не идентифицирующего отношения
![]() -
аналог идентифицирующего отношения
-
аналог идентифицирующего отношения
7. Работа с пакетом Design/idef
Создание новой страницы. Запустите Design/IDEF, выберите команду New в меню File. В диалоговом окне установки параметров выберите пункт IDEF1X в выпадающем списке Methodology. Выберите пункт None в выпадающем списке секции Startup Master Page Selection, чтобы указать, что вы не будете использовать мастер - страницу. Щелкните мышью на кнопке ОК. Будет создана новая страница.
Выбор целевой СУБД. Выберите команду Set options в меню Edit. Щелкните мышью на кнопке IDEF1X. Выберите в списке Target Database наименование целевой СУБД, на которой будет реализована ваша база данных.
Создание
сущности.
Сущность
создается командой Create/Entity
или с помощью кнопки
![]() ,
расположенной
в палитре инструментов. Поместите
указатель в то место экрана, в котором
вы хотите расположить сущность и щелкните
мышью.
,
расположенной
в палитре инструментов. Поместите
указатель в то место экрана, в котором
вы хотите расположить сущность и щелкните
мышью.
Откроется диалоговое окно Define Entity (Рис.67).
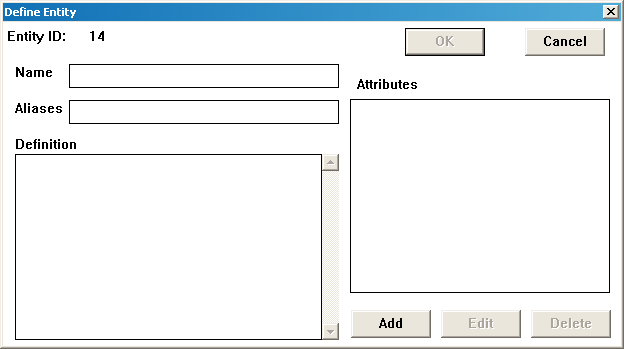
Рис.67. Диалоговое окно Define Entity
Определение сущности. Design/IDEF автоматически назначает сущности ее уникальный идентификатор (Entity ID). Напечатайте имя сущности в поле Name, a в поле Alias - необязательный параметр (псевдоним) этой сущности. В поле Definition записывается текстовое описание сущности.
Добавление и определение атрибутов. Щелкните мышью на кнопке ADD в диалоговом окне определения сущности. Откроется диалоговое окно определения атрибута (Рис.68).
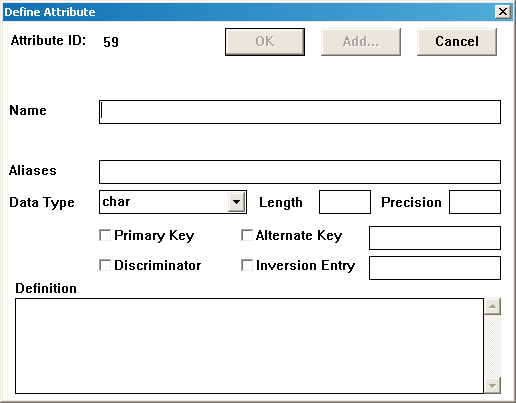
Рис.68. Диалоговое окно определения атрибута
Напечатайте имя атрибута в поле ввода Name. Поле Alias предназначено для необязательного параметра (псевдонима) атрибута. Далее необходимо выбрать тип данных (Data Type), указать длину поля (Length) и количество знаков после запятой. Если данный атрибут является первичным ключом (или его частью), отметьте поле Primary Key. Аналогично можно отметить поля альтернативных ключей (Alternate Key) или полей-дискриминаторов (Discriminator). Введите в поле ввода; справа от метки Alternate Key, номера всех альтернативных ключей, в которые входит данный атрибут. В поле Definition вводится текстовое описание атрибута.
После этого следует нажать кнопку ОК, если введены все атрибуты сущности, или кнопку ADD, если необходимо добавить атрибуты.
После нажатия на кнопку ОК становится активным окно определения сущности. В окне Attributes отображается список созданных атрибутов.
При завершении ввода информации о сущности необходимо нажать на кнопку ОК.
Создание и определение отношений. После того как вы создали в модели несколько сущностей, вы можете установить отношения между ними.
Выберите команду Create/Relationship или щелкните мышью на кнопке Relationship расположенной в палитре инструментов.
Протяните дугу отношения, соединив ею две сущности. Открывается диалоговое окно определения отношения (Рис.69). В нем в поле Relationship нужно ввести имя отношения с точки зрения родительской сущности. Вы можете также использовать поле Inverse, чтобы указать имя обратного отношения. Описание связи вводится в поле Definition.
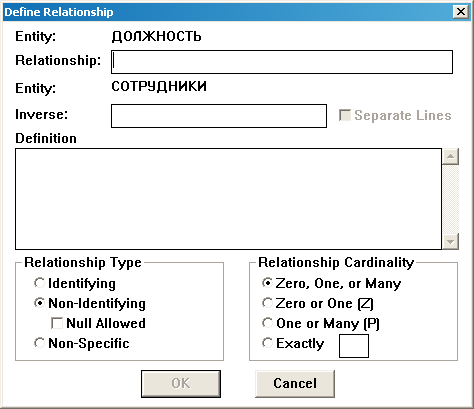
Рис.69. Диалоговое окно определения отношения
Имеются три возможных типа отношений: Identifying (идентифицирующее), Non_identifying (неидентифицирующее) и Non-specific (неспецифическое). Если поле Null Allowed (нуль разрешен) отмечено, это означает, что экземпляр сущности-потомка может быть не связан ни с одним из экземпляров сущности-родителя. В списке Relationship Cardinality выбирается один из вариантов указания мощности отношения.
Изменение
характеристик отношения.
Дважды
щелкните мышью на дуге отношения.
Design/IDEF
откроет диалоговое окно определения
отношения. Вы можете быстро изменить
отношение между двумя сущностями с
идентифицирующего на неидентифицируещее
и наоборот. Для этого, сначала, щелкните
мышью на дуге отношения, чтобы выделить
ее, а затем щелкните на![]() кнопке
расположенной в палитре инструментов.
Design/IDEF
внесет соответствующее изменение в
диаграмму
кнопке
расположенной в палитре инструментов.
Design/IDEF
внесет соответствующее изменение в
диаграмму
Удаление отношения. Щелкните мышью на дуге отношения, чтобы выделить ее. Выделите команду Delete в меню Edit, или нажмите клавишу Delete. Если вы удалите идентифицирующее отношение или неидентифицирующее отношение, Design/IDEF автоматически удаляет все атрибуты, мигрировавшие в сущности-потомки в качестве ключей.
Создание
дискриминатора.
Если
сущность имеет атрибут-дискриминатор,
Design/IDEF
вычерчивает объект-дискриминатор под
сущностью. Вы сможете изменить тип
дискриминатора с полного на неполный.
Для этого необходимо выделить дискриминатор
и щелкнуть мышью на кнопке
![]() расположенной
в палитре инструментов. После того, как
вы создадите сущности-категории для
этого дискриминатора, протяните дуги
отношений от дискриминатора к каждой
сущности-категории. Для этих дуг имя
определять не нужно.
расположенной
в палитре инструментов. После того, как
вы создадите сущности-категории для
этого дискриминатора, протяните дуги
отношений от дискриминатора к каждой
сущности-категории. Для этих дуг имя
определять не нужно.
Определение имени роли. Имя роли может быть определено для атрибута, являющиеся внешним ключом. Войдите в диалоговое окно редактирования атрибута (кнопка Edit), являющегося внешним ключом, для которого вы хотите определить имя роли. Введите имя роли в поле Role Name и щелкните мышью на кнопке ОК.
Порождение определения данных (DDL) на языке SQL. Design/IDEF позволяет автоматически сгенерировать операторы определения данных на языке SQL, соответствующие разработанной вами IDEF1X-модели. Выберите команду Export в меню File. Выберите пункт SQL Files (*.SQL) в списке выбора в разделе Format. Введите имя файла и укажите каталог, в котором будет сохранен файл. Щелкните мышью по кнопке О
7.1. Нормализация отношений
Разработчик БД должен обнаруживать потенциально опасные отношения и нормализовать их посредством разбиения отношений определенным способом.
Нормализация – разбиение одного отношения на два или более, в соответствии со специальной процедурой.
Универсальное отношение.
Рассмотрим пример.
Необходимо разработать БД для библиотеки.
Обозначения:
СНОМ – номер сотрудника.
СФАМ – фамилия сотрудника.
ЛНОМ – номер лаборатории.
ТНОМ – номер телефона лаборатории.
ШКН – шифр книги.
ДАТА – дата сдачи книги в библиотеку.
СТКН – стоимость книги.
Замечания: одну фамилию могут иметь несколько сотрудников; сотрудник находится в одной лаборатории, а в одной лаборатории работает несколько сотрудников; в лаборатории имеется только один телефон.
Таблица 14 Читатель
СНОМ |
СФАМ |
ЛНОМ |
ТНОМ |
ШКН |
ДАТА |
СТКН |
3215
|
Иванов
|
120
|
2136
|
122 120 230 |
Д1 Д2 Д3 |
90,00 70,00 55,00 |
3462
|
Петров
|
238
|
2344
|
122 123 |
Д1 Д2 |
90,00 85,50 |
3567
|
Сидоров
|
120
|
2136
|
239 141 |
Д1 Д2 |
150,00 120,00 |
4735 |
Николаев |
345 |
3321 |
398 |
Д1 |
40,00 |
Данная таблица не является нормализованным отношением.
Выделим первую строку: СНОМ=3215. Значение четырех полей СНОМ, СФАМ, ЛНОМ, ТНОМ являются атомарными (неделимыми), в то время как значения в полях ШКН, ДАТА, СТКН множественные.
Преобразуем эту таблицу так, чтобы каждый элемент кортежа имел атомарное значение. Это достигается с помощью простого процесса вставки.
Таблица 14 Читатель
СНОМ |
СФАМ |
ЛНОМ |
ТНОМ |
ШКН |
ДАТА |
СТКН |
3215 3215 3215 |
Иванов Иванов Иванов |
120 120 120 |
2136 2136 2136 |
122 120 230 |
Д1 Д2 Д3 |
90,00 70,00 55,00 |
3462 3462 |
Петров Петров |
238 238 |
2344 2344 |
122 123 |
Д1 Д2 |
90,00 85,50 |
3567 3567 |
Сидоров Сидоров |
120 120 |
2136 2136 |
239 141 |
Д1 Д2 |
150,00 120,00 |
4735 |
Николаев |
345 |
3321 |
398 |
Д1 |
40,00 |
Эта таблица представляет собой экземпляр корректного отношения – универсальное отношение. В эту таблицу включены все нужные атрибуты.
Проблемы, вызванные использованием универсального отношения.
Вопрос: зачем необходимо разбивать отношение ЧИТАТЕЛЬ на более мелкие отношения, если оно содержит в себе все необходимые данные?
Проблема вставки. Если в библиотеку записался новый сотрудник, еще не взявший ни одной книги, то для него необходимо включить в табл. кортеж с пустыми значениями атрибутов ШКН, ДАТА, СТКН.
Таблица оказывается частично заполненной – лишний объем памяти.
Проблема обновления (модификации). В универсальном отношении ЧИТАТЕЛЬ присутствует большое число избыточных данных.
Явная избыточность. СФАМ, ЛНОМ, ТНОМ появляются в таблице многократно. Если Иванов перешел в другую лабораторию, то библиотекарь будет вынужден проследить изменение номера лаборатории во всех картежах для непротиворечивости данных.
Неявная избыточность. Один и тот же номер телефона имеют сотрудники в одной лаборатории: Иванов и Сидоров.
Пусть Иванов извещает библиотекарю о том, что его номер телефона изменился на 7777, забыв при этом сообщить, что у его соседа (Сидорова) так же изменился номер.
Если библиотекарь изменяет номер только у Иванова, то номеру лаборатории 120 будут соответствовать 2 телефона.
Проблема удаления. В отношении ЧИТАТЕЛЬ присутствует 1 кортеж СНОМ=4735.
Предположим, что библиотекарь узнает, что книга, которая числится за Николаевым, сдана и находится в библиотеке. Он удаляет этот кортеж. Ликвидируя задолженность, он удаляет данные о сотруднике.
8. Виды нормальных форм
8.1. Определение первой нормальной формы (1нф)
Отношение находится в 1НФ, если каждый его элемент имеет и будет иметь всегда атомарное значение, т.е. на пересечении столбца и строки таблицы может быть только одно значение. Существование повторяющихся групп значений не допускается.
Функциональные зависимости (ФЗ). При нормализации данных необходимо использовать концепцию функциональных зависимостей между атрибутами универсального отношения.
Если даны два атрибута X и Y, то говорят, что Y функционально зависит от X, если для каждого значения X существует ровно 1 связанное с ним значение Y в любой момент времени.
X и Y могут быть составными, т.е. они могут представлять не единичные атрибуты, а группы состоящие из двух или более атрибут.
Обозначения ФЗ:
X
Y
или
![]()
Н айдем
в отношении Читатель ФЗ.
айдем
в отношении Читатель ФЗ.
СНОМСФАМ
СНОМàЛНОМ
СНОМàТНОМ
ЛНОМàТНОМ
ТНОМàЛНОМ
ШКНàСТКН
ДАТА не имеет функциональной зависимости с другими атрибутами (в один день –несколько книг, одна книга – в разные дни).
Полная ФЗ. Атрибут Y находится в полной ФЗ от атрибута X, если он функционально зависит от X и не зависит функционально от любого подмножества X. Это определение применяется в том случае, если X – составной атрибут.
Для примера составим отношение «Поставщик_ Поставка».
Обозначения:
ПОСТ – поставщик;
СТ – статус поставщика;
ГОР – город;
ПКА – поставка;
КВО – количество.
Таблица 15. Поставщик_ Поставка
ПОСТ # |
СТ |
ГОР |
ПКА # |
КВО |
П1 П1 П1 П1 П1 П1 П2 П2 П3 П4 П4 П4 |
20 20 20 20 20 20 10 10 10 20 20 20 |
Лондон Лондон Лондон Лондон Лондон Лондон Париж Париж Париж Лондон Лондон Лондон |
ПО1 ПО2 ПО3 ПО4 ПО5 ПО6 ПО1 ПО2 ПО2 ПО2 ПО4 ПО5 |
300 200 400 200 100 100 500 400 400 150 120 110 |
Просматривая это отношение, выделим ФЗ:
1. ПОСТ àСТ ;
2. ПОСТ àГОР ;
3. ГОР àСТ ;
4. СТ àГОР ;
5. ПКА – не имеет ФЗ;
6. ПОСТ, ПКА àКВО это полная ФЗ.
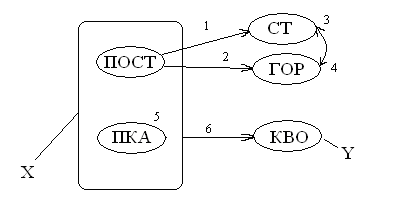
Рис.70. Пример полной функциональной зависимости
Рассмотрим проблемы универсального отношения.
Вставки.
Не можем включить поставщика П5 находящегося в г. Афины. Причина поле ПОСТ является частью первичного ключа не указав второй части, не можем вставить кортеж.
Удаления.
Если удаляем единственный кортеж П3 и ПО2, то теряем информацию о поставщике.
Обновления.
Если поставщик меняет адрес, то нужно менять этот адрес в нескольких записях.
Решить эти проблемы можно разбиением одного отношения на два: первое Поставщик, второе – Поставка.
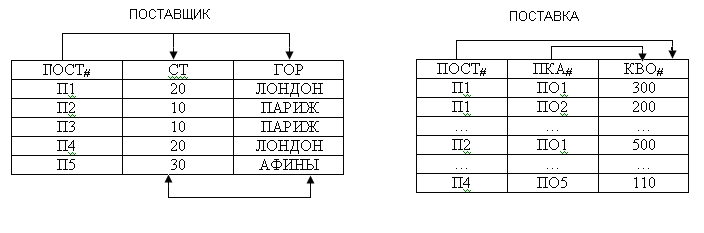
Рис.71. Пример проблемы универсального отношения
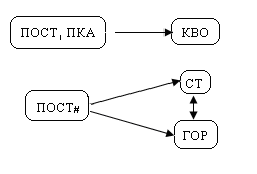
Рис.72. Связь между отношениями
Поясним преимущества разбиения на 2 отношения.
Вставка. Поставщик П5 добавлен отдельным кортежем, в отношение поставщик. Эта вставка может быть осуществлена и в том случае, если поставщик П5 не поставил поставок.
Обновление. Данные о поставщике появляются в отношении поставщик один раз.
Удаление. Мы можем удалить любую поставку, но сведения при этом о поставщике сохраняются.
8.2. Определение второй нормальной формы (2нф)
Отношение R находится во второй нормальной форме, если оно находится в 1НФ и каждый не ключевой атрибут функционально полно зависит от первичного ключа.
Отношение ПОСТАВЩИК_ПОСТАВКА не находится в 2НФ, потому что не ключевой атрибут КВО функционально полно зависит от составного первичного ключа ПОСТ ПКА. Однако атрибуты СТ и ГОР зависят только от части первичного ключа ПОСТ, следовательно имеет место не полная функциональная зависимость. Мы выделили некоторые атрибуты этой записи в отдельное отношение.
Недостатки:
Отношение Поставка считается удовлетворительным, а отношение Поставщик – неудовлетворительным. Это объясняется тем, что зависимость СТ от поставщика, хотя и функциональна, но с другой стороны является транзитивной через город (ГОР).
Определение:
Функциональная зависимость Х→Y называется транзитивной, если существует такой атрибут Z, что имеются функциональные зависимости Х→Z и Z→Y.
Наличие транзитивности приводит к ряду проблем:
Вставка. Нельзя зафиксировать тот факт, что с конкретным городом связано конкретное значение статуса. Нельзя прямо указать, что статус Рима равен 50, до тех пор, пока нет поставщика, размещенного в этом городе.
Удаление. Если удалить кортеж П5 из отношения Поставщик, то мы потеряем информацию о статусе города Афины.
Обновление. Величина статуса для данного города появляется в отношении Поставщик несколько раз. Если потребуется изменить статус Лондона, то нужно просматривать всю таблицу, и во многих местах изменить статус Лондона.
Заменим отношение ПОСТавщик двумя отношениями ПОСТ_ГОР и ГОР_СТ

Рис.73. Отношения ПОСТАВЩИК_ГОРОД и ГОР_СТ
Исходная
часть схемы преобразуется следующим
образом:
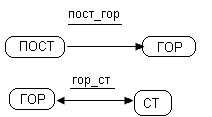
Рис.74. Связь между отношениями
Т. о. мы разорвали транзитивную зависимость.
В результате наших действий модель будет следующая:

Рис.75. Результирующая модель

Рис.76. Отношения
8.3. Определение третьей нормальной формы (3нф)
Отношение находится в 3НФ, если оно находится в 2НФ и каждый не ключевой атрибут не транзитивно зависит от первичного ключа, и между не ключевыми атрибутами нет функциональной зависимости.
Нормальная форма Бойса – Кодда (НФБК).
Возможный ключ – представляет собой атрибут или набор атрибутов, которые могут быть использованы в качестве первичного ключа (№ паспорта, № страховки и т. д.).
Определение детерминанта: если X→Y есть функциональная зависимость, и Y не зависит функционально от любого подмножества X, то говорят, что любое подмножество Х представляет собой детерминант Y.
Пример: ПОСТ_ПКА.
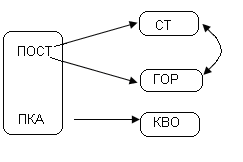
Рис.77. Связь между отношениями
Возможный ключ в данном отношении единственный.
Определенные детерминанты:
<ПОСТ, ПКА>
<ПОСТ>
<ГОР>
<СТ>
Не все детерминанты являются возможными ключами всего отношения.
Определение НФБК. Отношение находится в НФБК если детерминант является возможным ключом всего отношения.
Пример:
Дано отношение:
R(ПОСТ, ПКА, ГОР, СТ, КВО)
Следует проверить отношение и найти цепочку вида А→В→С. Из этой цепочки необходимо взять крайнюю правую зависимость. В рамках этого примера мы имеем:
ПОСТ→ГОР→СТ или ПОСТ→СТ→ГОР
Выберем первую цепочку. Крайней правой зависимостью является ГОР→СТ, в связи с этим определяем новое отношение:
R1(ГОР, СТ) оно находится в НФБК.
Составим новое отношение R2:
R2(ПОСТ,ПКА, ГОР, КВО)
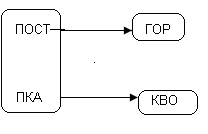
Рис.78. Связь между атрибутами
Оно не находится в НФБК. Причина в зависимости ПОСТ→ГОР.
Разделим его на 2 отношения:
R3(ПОСТ, ГОР)
R4(ПОСТ,ПКА,КВО)
Каждое из них находится в НФБК. Т. о. исходное отношение R(ПОСТ, ПКА, ГОР, СТ, КВО) разделено на ряд отношений:
R1(ГОР, СТ)
R3(ПОСТ, ГОР)
R4(ПОСТ,ПКА,КВО)
8.4. Определение 4нф
Дано отношение R(КУРС, ПРЕПОДАВАТЕЛЬ, УЧЕБНИКИ)
Это отношение:
Таблица 16
КУРС |
ПРЕПОДОВАТЕЛЬ |
УЧЕБНИКИ |
Физика |
Иванов |
Механика, оптика |
Физика |
Петров |
Механика, оптика |
Математика |
Иванов |
Мат. Анализ, диф. ур-я |
Из таблицы видно, что курс читают несколько преподавателей. По курсу используется много учебников. В данном отношении отсутствует функциональная зависимость, поэтому к нему не применима обычная теория декомпозиции. Принято считать, что в этом случае присутствует новый тип функциональной зависимости – многозначная зависимость (МЗ).
КУРС→ПРЕПОДАВАТЕЛЬ
КУР→УЧЕБНИКИ
В связи с этим, исходное отношение делится на два:

Рис.79. Два отношения после разделения
8.5. Определение 5нф
Предположим, что имеем 3 или более сущностей, связанных между собой отношениями многие ко многим:
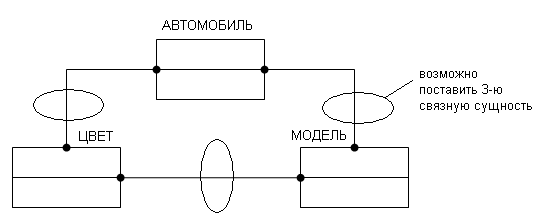
Рис.80. Сущности, имеющие между собой отношение многие ко многим
Дано отношение:
Таблица 17
-
ЦВЕТ
АВТОМОБИЛЬ
МОДЕЛЬ
Ц1
А1
М2
Ц1
А2
М1
Ц2
А1
М1
Ц1
А1
М1
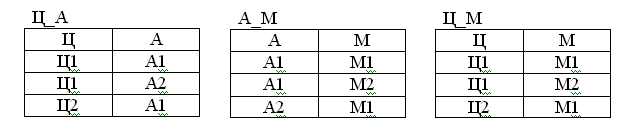
Рис.81. Три отношения после разделения одного исходного
Попытаемся соединить первые две таблицы по атрибуту А
Таблица 18
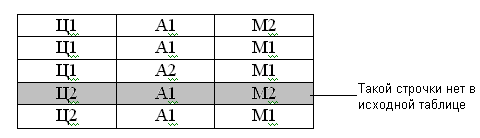
Проверяем соответствие строк таблиц. Появилась ложная строка, обусловленная попыткой получения результата, за счет соединения двух таблиц по общему атрибуту.
Соединим вторую и третью таблицы:
Таблица 19

Аналогично можно провести соединение таблиц первой и третьей.
Преобразование схем функциональных зависимостей
Пример: Даны атрибуты: А, В, С, D.
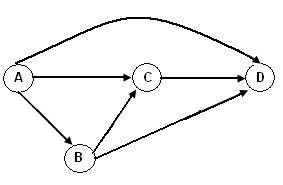
Рис.82. Схема функциональных зависимостей
В этом примере присутствует транзитивная зависимость, а она приносит больше вреда, чем пользы, и, следовательно, ее следует исключить. Удаляем A→D.
Рис.83.
Удаляем другую транзитивную зависимость В→ D.
Рис.84.
Удаляем следующую А→ С.
Рис.85. Упрощенная схема
Получили отношение R(А, В, С, D).
Берем правую крайнюю зависимость и отделяем:
R1(А,
В, С)
![]()
R2(С,
D)
![]()
В итоге имеем:
R2(С, D)
R3(А,
В)![]()
R2(В,
С)![]()
Процедуры, правила (триггеры) и события в базах данных

Рис. . Принцип механизма событий, правил и процедур в базах данных
1. В базе данных определяются так называемые события (database events), связанные с изменениями данных — добавление новой записи(ей) в определенную таблицу, изменение записи(ей), удаление записи(ей).
2. Для каждого события в базе данных определяются правила (triggers) no проверке определенных условий состояния данных.
3. В зависимости от результатов проверки правил в базе данных запускаются на выполнение предварительно определенные процедуры. Процедуры представляют собой последовательности команд по обработке дачных, имеющие отдельное смысловое значение.
Пример алгоритма контроля за прохождением входящих документов:
при появлении новых записей в таблице «документы» с категорией «входящие» сформировать набор записей входящих документов за определенный период времени, скажем за рабо чий день;
известить пользователей ИС, имеющих полномочия на принятие резолюций по входящим документам (руководители организации или их секретариаты), и предоставить им доступ к сформированному набору данных;
получить результаты резолюций на входящих документах, известить и предоставить соответствующие документы пользователям-исполнителям, включить контроль на исполнение документов;
получить от пользователей-исполнителей данные по исполнению документа и снять соответствующие документы с контроля либо известить пользователей, наложивших соответствующие резолюции, о не исполнении к установленному сроку их резолюций.
Суть идеи механизма событий, правил и процедур заключается в том, что они после определения хранятся вместе с данными. Ядро СУБД при любом изменении состояния базы данных проверяет, не произошли ли ранее «поставленные на учет» события, и, если они произошли, обеспечивает проверку соответствующих правил и запуск соответствующих процедур обработки.
SQL-инструкции, реализующие технику «событий-правил-процедур» в некоторых СУБД с развитым интерфейсом, могут быть созданы, так же как и сложные запросы, через специальные конструкторы и мастера, что дает возможность их освоения и использования пользователями-непрограммистами.
В настоящее время механизм событий, правил и процедур широко распространен и в той или иной мере реализован практически в любой современной СУБД.
Представление структур данных в памяти эвм
Мы познакомились с несколькими разновидностями модели данных (реляционными, иерархическими и сетевыми). В настоящее время необходимо знать способы отображения этих структур в памяти ЭВМ. Основное различие форм представления данных в памяти ЭВМ определяется способом адресации элементов структуры – по месту или по содержимому.
В первом случае размещение данных и их выборка определяется по известному значению ключа. В первом случае задаются адреса данных, определяющее месторасположения данных в памяти ЭВМ. Данные и их выборка определяются по известному значению ключа, т.е. определяется содержимое самих данных. Наиболее постой формой хранения данных является одномерный линейный список.
Линейный список – это множество объектов (узлов), которые можно представить в виде последовательности:
Х[1], Х[2], … ,Х[n].
Х[i-1] – предшествует узлу Х[i]
Х[i+1] – следует за Х[i].
Компоненты этой последовательности идентифицируются порядковым номером индекса i, 1 < i < n.
Одномерный линейный список иногда называется вектором данных.
Проблема отображения моделей данных, т.е. некоторых логических структур в памяти ЭВМ связаны с понятием адресной функции.
При реализации адресной функции, используется два основных способа:
Последовательное распределение памяти;
Связанное распределение памяти.
Последовательное распределение памяти, т. е. в виде линейного списка.
Пример. Необходимо отобразить двоичное дерево в памяти ЭВМ с помощью линейного списка (рис.7.1).
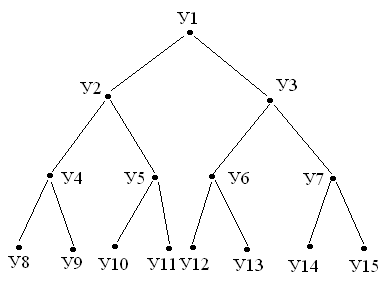
Рис.7.1. Иерархическая модель
Содержимое линейного списка:
У1 У2 У3 У4… У15.
Определение адреса:
α(1)=β;
α(2)=β+m;
α(3)=β+2m;
α(i)=β+(i-1)m;
α(15)=β+14m;
β – базовый адрес;
m – длина записи (фиксированная длина).
Перемещение от родителя к потомку и обратно:
От узла с номером K можно перейти к его потомкам. Для этого надо удвоить K и прибавить единицу.
От узла K можно перейти к его родителю. Для этого необходимо разделить K на 2 и отбросить дробную часть.
Аналогичным способом можно проектировать структуру троичного регулярного дерева.
Пример троичного регулярного дерева (рис.7.2).
Рис.7.2. Троичное регулярное дерево
От узла K можно перейти к родителям, разделив индекс на 3 и округлить результат до ближайшего целого числа.
Пример 2. Метод левосписковых структур (рис.7.3).

Рис.7.3. Левосписковая структура
Линейный список:
а |
б1 |
в1 |
г1 |
г2 |
г3 |
в2 |
г4 |
б2 |
в3 |
г5 |
г6 |
в4 |
г7 |
б3 |
в5 |
г8 |
Метод размещает последовательность узлов в списке, при обходе исходной древовидной структуры сверху-вниз и слева-направо:
идем от корневого узла вниз, до конца левой ветви, т. е. до г1;
поднимаемся вверх на один шаг, и опускаемся вниз, отмечем г2;
поднимаемся вверх на один шаг, и, снова, опускаемся вниз, отмечаем г3;
поднимаемся на два шага до б1 и, вновь, опускаемся вниз, отмечаем в2, г4 и т. д.
Этот метод применим для любой древовидной структуры. При реализации любой древовидной последовательности в памяти, можно использовать специальный разделитель в виде скобок:
а(б1(в1(г1 г2 г3)в2(г4))б2(в3(г5 г6)в4(г7))б3(в5(г8)))
Открывающая скобка – движение вниз по модели, закрывающая – вверх.
Скобка – переход с уровня на уровень.
8. Связанное распределение памяти
Отношения следования и предшествования элементов задаются с помощью указателей. Значение адресной функции можно получить только после просмотра указателей. Это удобно, так как список легко модифицируется. Для хранения указателей требуется дополнительная память. Элементы списка необязательно хранятся в последних ячейках памяти.
Каждый узел содержит следующий узел списка, т.е. адрес следующего узла.

Рис.8.1. Пример однонаправленного связанного списка
Двунаправленный связанный список
Рис.8.2. Пример двунаправленного связанного списка

Рис.8.3. Пример линейного списка с пропусками
Для упрощения доступа к узлам применяется линейный список с пропусками, в котором в начале осуществляется доступ по обратным указателям к группе, в которой находится требуемый элемент. А затем по прямым показателям перебираются узлы группы, пока не будет найден требуемый узел.
Количество просматриваемых элементов минимально, если
![]() ,
где m
– число групп, n
– число элементов.
,
где m
– число групп, n
– число элементов.
Циклический список с указателями на голову списка.
Голова списка

Рис.8.4. Пример циклического списка
Голова
списка хранится в специальной ячейке
памяти по адресу
![]() .
В этой ячейке можно хранить служебную
информацию, содержащую идентификатор
списка, количество узлов в списке и т.п.
.
В этой ячейке можно хранить служебную
информацию, содержащую идентификатор
списка, количество узлов в списке и т.п.
В голове списка содержится указатель на первый узел списка . Наличие циклов, т.е. обратных связей позволяет получить доступ к любому узлу отправляясь от любого заданного узла.
Пример таблицы с использованием связанных списков.
№ записи |
№ служащего |
Фамилия |
Специальность |
Указатель специальности |
1 |
012 |
Иванов |
Бухгалтер |
4 |
2 |
021 |
Петров |
Чертежник |
6 |
3 |
022 |
Сидоров |
Инженер |
5 |
4 |
024 |
Голубев |
Бухгалтер |
7 |
5 |
039 |
Воронин |
Инженер |
9 |
6 |
040 |
Волков |
Чертежник |
10 |
7 |
060 |
Быков |
Бухгалтер |
8 |
8 |
071 |
Козлов |
Бухгалтер |
0 |
9 |
090 |
Зайцев |
Инженер |
0 |
10 |
106 |
Чернов |
Чертежник |
0 |






0 – обозначение конца списка
Пояснение. В бюро по трудоустройству ведется приведенная выше таблица о сотрудниках.
Появляется свободная новая должность для инженера. Для того чтобы выбрать кандидатуру, необходимо выбрать всех кандидатов на эту должность. Головной список может указывать на 1-ую запись в БД, содержащую значение инженер в поле Специальность.
В данном примере это будет запись под №3 Сидоров. Эта запись указывает на Воронина, который в свою очередь указывает на Зайцева.
Другой вариант организации.
Разместим все записи об инженерах подряд. Извлекаются эти записи быстро. Однако, потом нам может потребоваться извлекать записи о сотрудниках по адресу проживания. В результате предыдущая схема перестает работать.
Применение указателей разрешает эту проблему, позволяя поддерживать любое число логических списков без переупорядочивания файла.
Если список велик , то проход по цепочке записей может занимать много времени. Поддержание с писка может быть обременительным, особенно если записи часто добавляются или удаляются. Рассмотрим другой способ.
Инвертированный список.
Приведенную табл. Можно представить:
Специальность |
Указатели |
|||
1 |
2 |
3 |
4 |
|
Бухгалтер |
1 |
4 |
7 |
8 |
Чертежник |
2 |
6 |
10 |
|
Инженер |
3 |
5 |
9 |
|
Строка Инженер включает все адреса записей, содержащие претендентов на занятие этой должности.
И так связанный список требует хранение указателей вместе с записями данных. Тогда инвертированный список избавляет нас от этой необходимости, сохраняя указатели отдельно от данных.
9. Индексирование
Рассмотрим в качестве примера таблицу данных о поставщиках.
Файл Городов Файл Поставщиков
Город |
Указатель |
|
||||
Владимир |
1 |
|
||||
Владимир |
5 |
|
||||
Рязань |
4 |
|
||||
Тамбов |
2 |
|
||||
Тамбов |
3 |
|
||||
|
|
|
||||
|
|
|
||||
|
|
|
||||
|
|
|
||||
|
|
|
||||
|
|
|
||||



Пост# |
Фамилия |
Город |
1 |
Иванов |
Владимир |
2 |
Алферов |
Тамбов |
3 |
Якушев |
Тамбов |
4 |
Быков |
Рязань |
5 |
Гусев |
Владимир |
Рис. 9.1. Индексирование файла поставок по полю Город
Предположим, что часто выполняется запрос Найти всех поставщиков из города С, где С – некоторый параметр. В этом случае администратор БД может выбрать способ хранения данных, основанный на двух хранимых файлах:
Файл с данными о поставщиках;
Файл с данными о городах.
Причем в файле городов применяется упорядочивание по алфавиту. Указанный запрос можно выполнить различными способами.
1. Найти в файле поставщиков все записи, для которых названием города является Владимир. В этом случае нужно просмотреть файл от начала до конца.
2. В файле городов необходимо найти строки, содержащие Владимир, а затем, согласно указателям, извлечь все соответствующие записи из файла поставщиков.
Файл городов называется индексом. Индекс – файл особого типа, в котором запись состоит из двух значений: данных и указателей.
Индекс можно сравнить с предметным указателем обычной книги, которая состоит из списка слов с указателями (№ страниц) для упрощения поиска связанной информации.
Если индекс основан на основе ключевого поля (создается автоматически), то он называется первичным индексом.
Если индекс основан на основе другого поля, то он называется вторичный индекс.
Можно использовать несколько индексов.
Пример. Хранимый файл может иметь индекс по полю город и статус поставщика. Эти индексы могут использоваться как раздельно, так и совместно для более эффективного поиска нужных данных.
Несколько индексов
Указатель |
Статус |
2 3 5 4 1 |
5 10 25 30 50 |
Город |
Указатель |
Владимир Владимир Рязань Т Т |
1 5 4 2 3
|
 амбов
амбов амбов
амбов

Файл поставок
Пост |
Фамилия |
Статус |
Город |
1 |
Иванов |
50 |
Владимир |
2 |
Алферов |
5 |
Тамбов |
3 |
Якушев |
10 |
Тамбов |
4 |
Быков |
30 |
Рязань |
5 |
Гусев |
25 |
Владимир |
Рассмотрим совместное использование индексов на примере.
Пример. Найти поставщиков из Тамбова со статусом 5.
Решение.По индексу Город находим записи Тамбова (2,3). По индексу Статус находим ссылку на статус 5 (2). Сопоставляя эти результаты видим, что нас интересует Алферов.
Можно использовать индексирование на основе комбинации полей.
-
Город / Статус
Указатель
Владимир / 25
5
Владимир / 50
1
Рязань / 30
4
Тамбов / 5
2
Тамбов / 10
3
До сих пор предполагалось, что в качестве указателей используются указатели записи. Однако, на практике указатели указывают не на запись, а на страницу, которая размещена на диске. Необходимая страница извлекается в оперативную память, а затем на этой странице ищется запись с нужными данными. Индекс такого типа называется неплотным индексом. Поскольку в нем не содержатся указатели на каждую запись индексированного файла.
9.2. Преимущество и недостатки индексирования
Основным преимуществом использования индексов является значительное ускорение операции выборки и извлечения данных.
Недостатки:
Замедление процесса обновления, добавления, вставки и т.д.
Индексы увеличивают объем БД, чем больше индексов, тем больше затрат на их сопровождение при обработке данных.
Если работу по вставке в таблицу принять за единицу, то для создания элемента индекса требуется три такие единицы. Следовательно, при вставке в таблицу строки с тремя индексами, нужно выполнить в 10 раз больше работы, чем при вставке строки в неиндексированную таблицу.
Преобразование иерархической структуры.
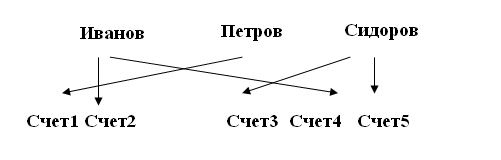
Можно использовать несколько указателей в записи предке. Однако, число указателей будет переменным. Затрудняется ввод и удаление данных. Использование указателей потомок-близнец упрощает эту проблему.
Отн. осит. адрес |
Запись данных |
Указатель потомка |
Указатель близнеца |
1 |
Иванов |
5 |
2 |
2 |
Петров |
4 |
3 |
3 |
Сидоров |
6 |
0 |
4 |
Счет1 |
0 |
0 |
5 |
Счет2 |
0 |
7 |
6 |
Счет3 |
0 |
8 |
7 |
Счет4 |
0 |
0 |
8 |
Счет5 |
0 |
0 |
На рисунке видно, что первый указатель каждой записи содержит адрес записи потомка, а второй – адрес записи близнеца. Указатели можно удалить из самих записей и поместить в инвертированный список.
9.3. Хеширование
Недостаток индексных схем состоит в том, что при обнаружении записи приходится обращаться к индексам. Использование хеширования позволяет исключить индексы.
Хеширование – процедура вычисления адреса, на основании поля записи (ключа).
Для определения адреса используется ХЕШ- функция. Существует много вариантов создания ХЕШ- функции.
Например, имеем записи с данными о поставщиках. Из 1000 ячеек с номерами 0-999 используется только 5 ячеек: 100, 200, 300, 400, 500.
Вычисляется ХЕШ- адрес. Находится остаток от деления на 13.
![]()
![]()
![]()
![]()
![]()
![]()
Значения, взятые из ряда:100, 200, 300, 400, 500 преобразовались в 1, 5, 6, 9,10. Три разряда десятичных 999 преобразовались практически в 1 разряд. Однако, при вычислении таким образом возможны коллизии. На один и тот же адрес претендуют несколько записей. Например,
![]()
Ищется ячейка пока незанятая.еем записи с данными о поставщиках. Ш функция.ертированный список.