

18. Где содержится метаинформация в процессе проектирования эис?
Сведения о структуре БД сосредоточены в словаре-справочнике (репозитории) АБД, этот вид информации называется метаинформацией. В состав метаинформации входит семантическая информация, физические характеристики данных и информация об их использовании. С помощью словарей данных автоматизируется процесс использования метаинформации в ЭИС.
База данных содержит сведения о количественных и качественных характеристиках конкретных объектов. База знаний содержит сведения о закономерностях в ПО, позволяющие выводить новые факты из имеющихся в БД; метаинформацию; сведения о структуре предметной области; сведения, обеспечивающие понимание запроса и синтез ответа.
19. Элементы логической и физической er-диаграммы в case-средстве eRwin Data Modeler.
В ERwin существуют два уровня представления и моделирования - логический и физический . Логический уровень означает прямое отображение фактов из реальной жизни. Например, люди, столы, отделы, собаки и компьютеры являются реальными объектами. Они именуются на естественном языке, с любыми разделителями слов (пробелы, запятые и т.д.). На логическом уровне не рассматривается использование конкретной СУБД, не определяются типы данных (например, целое или вещественное число) и не определяются индексы для таблиц.
Целевая СУБД, имена объектов и типы данных, индексы составляют второй (физический) уровень модели ERwin.
ERwin предоставляет возможности создавать и управлять этими двумя различными уровнями представления одной диаграммы (модели), равно как и иметь много вариантов отображения на каждом уровне.
20. Виды систем классификации. Параметры систем классификации. Цель разработки классификаторов.
Разработаны три метода классификации объектов: иерархический, фасетный, дескрипторный.
Иерархическая система классификации
Иерархическая система классификации (рис. 3) строится следующим образом:
– исходное множество элементов составляет 0-й уровень и делится в зависимости от выбранного классификационного признака на классы (группировки), которые образуют 1-й уровень;
– каждый класс 1-го уровня в соответствии со своим, характерным для него классификационным признаком делится на подклассы, которые образуют 2-й уровень;
– каждый класс 2-го уровня аналогично делится на группы, которые образуют 3-й уровень и т.д.
Фасетная система классификации
Фасетная система классификации в отличие от иерархической позволяет выбирать признаки классификации независимо как друг от друга, так и от семантического содержания классифицируемого объекта. Признаки классификации называются фасетами (facet — рамка). Каждый фасет (Фi) содержит совокупность однородных значений данного классификационного признака. Причем значения в фасете могут располагаться в произвольном порядке, хотя предпочтительнее их упорядочение.
Дескрипторная система классификации
Дескрипторная (описательная) система классификации эффективно используется для организации поиска информации, для ведения тезаурусов (словарей). Язык данной системы классификации приближается к естественному языку описания информационных объектов. Особенно широко она используется в библиотечной системе поиска.
Суть дескрипторного метода классификации заключается в следующем:
1) отбирается совокупность ключевых слов или словосочетаний, описывающих определенную предметную область или совокупность однородных объектов. Причем среди ключевых слов могут находиться синонимы;
2) выбранные ключевые слова и словосочетания подвергаются нормализации, т.е. из совокупности синонимов выбирается один или несколько наиболее употребимых;
3) создается словарь дескрипторов, т.е. словарь ключевых слов и словосочетаний, отобранных в результате процедуры нормализации.
21. Структура классификаторов технико-экономической информации.
Любой классификатор состоит из двух частей:
-
(1)
(2)
1- реквизит-признак 2 - реквизит-основание
(1) - характеризует основную характеристику информации с позиции принадлежности информации какому-нибудь классу. Например, классификатор (класс) - территориальное деление государства, классификатор услуг, организация предприятия.
(2) - есть числовая характеристика классификатора, который иногда называется кодом конкретной информации. Например, код г. Москва - 095 (в территориальном делении РФ)
Структура экономического показателя.
Экономический показатель является составной единицей информации, отражающей количественную характеристику некоторого процесса предметной области-реквизит -основание вместе с однозначно определяющими его качествами реквизитами-признаками [51]. Структура показателя представлена на рис. 4.1.
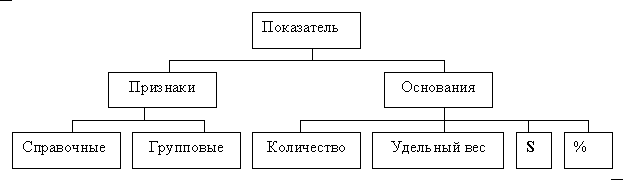
Реквизиты-основания подразделяются по типу алгоритмов их получения на количественные, стоимостные, проценты, удельные веса и др. Множество реквизитов -признаков по степени формализации делится на два подмножества:
- справочные реквизиты-признаки - как правило, наименования, предназначенные для понимания показателя пользователем - экономистом;
- группировочные реквизиты-признаки ─ как правило, закодированные аналоги справочных признаков, предназначены для логической обработки информации на ЭВМ.
Основными объектами классификации и кодирования являются справочные реквизиты -признаки, описывающие процессы, место, время выполнения процессов, субъекты и объекты действия, отражаемые в показателе.
23. Параметры кода информации.
24. Признаки классификации экономической документации.
25. Какие формы документов выделяют при проектировании унифицированной системы документации?
26. Требования к документам результатной информации.
27. Классификация диалогов информационных систем.
28. Состав технологической сети проектирования экранных форм.
29. Архитектура информационного хранилища.
30. Требования к организации базы данных.
Установление многосторонних связей.
Некоторые базы данных будут содержать сложные переплетения взаимосвязей. Метод организации данных должен быть таким, чтобы обеспечивалась возможность удобного представления этих взаимосвязей и быстрого согласования вносимых в них изменений.
Производительность.
Система баз данных должна обеспечивать соответствующую пропускную способность. Но в системах, рассчитанных на небольшой поток запросов, пропускная способность накладывает незначительные ограничения на структуру базы данных.
Минимальные затраты.
Для уменьшения затрат на создание и эксплуатацию базы данных выбираются такие методы организации, которые минимизируют требования к внешней памяти.
Минимальная избыточность.
Целью организации базы данных должно быть уничтожение избыточных данных там, где это выгодно, и контроль за теми противоречиями, которые вызываются наличием избыточных данных.
Возможности поиска.
Пользователь базы данных может обращаться к ней с самыми различными вопросами по поводу хранимых данных.
Целостность.
Если база данных содержит данные, используемые многими пользователями, очень важно, чтобы элементы данных и связи между ними не разрушались.
Связь с прошлым.
В том случае, когда фирма начинает использовать на вычислительной установке новое программное обеспечение управления базами данных, очень важно, чтобы при этом она могла работать с уже существующими на этой установке программами, обрабатываемые данные можно было бы соответствующим образом преобразовывать. Важно, однако, чтобы проблема связи с прошлым не сдерживала развитие средств управления базами данных.
Связь с будущим.
Особенно важной представляется связь с будущим. В будущем данные и среда их хранения изменятся по многим направлениям. Одна из самых важных задач при разработке баз данных – запланировать базу данных таким образом, чтобы изменения ее можно было выполнять без модификации прикладных программ.
Простота использования.
Средства, которые используются для представления общего логического описания данных, должны быть простыми и изящными.
Интерфейс программного обеспечения должен быть ориентирован на конечного пользователя и учитывать возможность того, что пользователь не имеет необходимой базы знаний по теории баз данных.
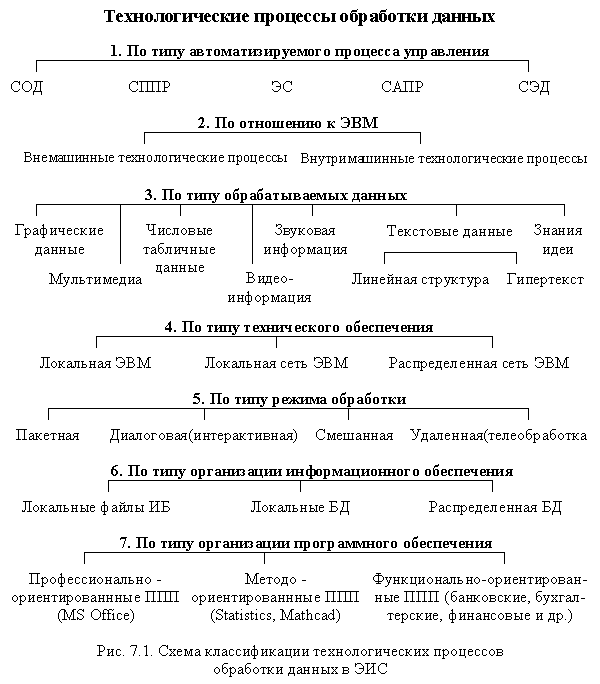
31. Классификация технологических процессов обработки данных в ИС.
32. Какие ситуации представляют угрозу безопасности информации?
Основными источниками угроз безопасности АС и информации (угроз интересам субъектов информационных отношений) являются:
• стихийные бедствия и аварии (наводнение, ураган, землетрясение, пожар и т.п.);
• сбои и отказы оборудования (технических средств) АС;
• ошибки проектирования и разработки компонентов АС (аппаратных средств, технологии обработки информации, программ, структур данных и т.п.);
• ошибки эксплуатации (пользователей, операторов и другого персонала);
• преднамеренные действия нарушителей и злоумышленников (обиженных лиц из числа персонала, преступников, шпионов, диверсантов и т.п.).
33. Методы обеспечения защиты хранимых данных.
Основные механизмы защиты ПК от НСД могут быть представлены следующим перечнем:
1) физическая защита ПК и носителей информации;
Содержание физической защиты общеизвестно, поэтому детально обсуждать ее здесь нет необходимости. Заметим только, что ПК лучше размещать в надежно запираемом помещении, причем, в рабочее время помещение должно быть закрыто или ПК должен быть под наблюдением законного пользователя. При обработке закрытой информации в помещении могут находиться только лица, допущенные к обрабатываемой информации. В целях повышения надежности физической защиты в нерабочее время ПК следует хранить в опечатанном сейфе.
2) опознавание (аутентификация) пользователей и используемых компонентов обработки информации;
В концептуальном плане решение данной задачи принципиально не отличается от аналогичной задачи, решаемой в любой АСОД:
система защиты должна надежно определять законность каждого обращения к ресурсам, а законный пользователь должен иметь возможность, убедиться, что ему предоставляются именно те компоненты (аппаратура, программы, массивы данных), которые ему необходимы.
Для опознавания пользователей к настоящему времени разработаны и нашли практическое применение следующие способы:
1) с использованием простого пароля;
2) в диалоговом режиме с использованием нескольких паролей и/или персональной информации пользователей;
3) по индивидуальным особенностям и физиологическим характеристикам человека (отпечатки пальцев, геометрия руки, голос, персональная роспись, структура сетчатки глаза, фотография и некоторые другие);
4) с использованием радиокодовых устройств;
5) с использованием электронных карточек.
3) разграничение доступа к элементам защищаемой информации;
Разграничение доступа к элементам защищаемой информации заключается в том, чтобы каждому зарегистрированному пользователю предоставить возможности беспрепятственного доступа к информации в пределах его полномочий и исключить возможности превышения своих полномочий. В этих целях разработаны и реализованы на практике методы и средства разграничения доступа к устройствам ЭВМ, к программам обработки информации, к полям (областям ЗУ) и к массивам (базам) данных. Само разграничение может осуществляться несколькими способами, а именно:
1) по уровням (кольцам) секретности;
2) по специальным спискам;
3) по так называемым матрицам полномочий;
4) по специальным мандатам.
4) криптографическое закрытие защищаемой информации, хранимой на носителях (архивация данных);
Данный механизм, как следует из самого названия, предназначается для обеспечения защиты информации, которая подлежит продолжительному хранению на машинных носителях. Но при разработке методов его реализации имелась в виду и еще одна весьма важная цель — уменьшение объемов ЗУ, занимаемых хранимой информацией. Указанные цели и выступают в качестве основных критериев при поиске оптимальных вариантов решения задачи архивации данных.
Для предупреждения несанкционированного доступа к хранимой информации могут и должны использоваться все три рассмотренных выше механизма. Но особенно эффективными являются методы криптографического преобразования информации, поэтому они составляют основу практически всех известных механизмов архивации. Уменьшение объемов ЗУ достигается применением так называемых методов сжатия данных, сущность которых заключается в использовании таких систем кодирования архивируемых данных, которые при сохранении содержания информации требуют меньшего объема памяти носителя. Но тогда естественной представляется идея выбора такого способа кодирования, который удовлетворял бы обоим требованиям: обеспечивал бы уменьшение объема ЗУ и обладал бы требуемой надежностью криптографической защиты.
5) криптографическое закрытие защищаемой информации в процессе непосредственной ее обработки;
Назначение указанного метода очевидно, а целесообразность применения определяется возможностями несанкционированного доступа к защищаемой информации в процессе непосредственной обработки.
Если же обработка информации осуществляется в сетевой среде, то без применения криптографических средств надежное предотвращение несанкционированного доступа к ней практически не может быть обеспечено. Этим и обусловлено то достаточно большое внимание, которое уделяется разработке криптографических средств, ориентированных на применение в ПК.
6) регистрация всех обращений к защищаемой информации. Ниже излагаются общее содержание .и способы использования перечисленных механизмов.
Регистрация обращений к защищаемой информации ПК позволяет решать ряд важных задач, способствующих существенному повышению эффективности защиты, поэтому оно непременно присутствует во всех системах защиты информации.
Основные задачи, при решении которых заметную роль играет регистрация обращений, могут быть представлены следующим перечнем:
• контроль использования защищаемой информации;
• выявление попыток несанкционированного доступа к защищаемой информации;
• накопление статистических данных 6 функционировании систем защиты.
34. Принципы объектно-ориентированного подхода к проектированию ИС.
ООП держится на трех принципах: инкапсуляции, наследовании и полиморфизме.
Наблюдаемое в объектах объединение данных и операций в одно целое было обозначено термином инкапсуляция (первый принцип ООП). Применение инкапсуляции сделало объекты похожими на маленькие программные модули и обеспечило сокрытие их внутреннего устройства. Для объектов появилось понятие интерфейса, что значительно повысило их надежность и целостность.
Второй принцип ООП — наследование. Этот простой принцип означает, что если вы хотите создать новый класс, лишь немногим отличающийся от того, что уже существует, то нет необходимости в переписывании заново всех полей, методов и свойств. Вы объявляете, что новый класс является потомком (или дочерним классом) имеющегося класса, называемого предком (или родительским классом), и добавляете к нему новые поля, методы и свойства. Иными словами добавляется то, что нужно для перехода от общего к частному. Процесс порождения новых классов на основе других классов называется наследованием. Новые классы имеют как унаследованные признаки, так и, возможно, новые. Например, класс СОБАКИ унаследовал многие свойства своих предков - ВОЛКОВ
Третий принцип — это полиморфизм. Он означает, что в производных классах вы можете изменять работу уже существующих в базовом классе методов. При этом весь программный код, управляющий объектами родительского класса, пригоден для управления объектами дочернего класса без всякой модификации. Например, вы можете породить новый класс кнопок с рельефной надписью, переопределив метод отрисовки кнопки. Новую кнопку можно «подсунуть» вместо стандартной в какую-нибудь подпрограмму, вызывающую отрисовку кнопки. При этом подпрограмма «думает», что работает со стандартной кнопкой, но на самом деле кнопка принадлежит производному классу и отображается в новом стиле.